



 本文介绍了机器学习的主要分类,包括监督学习、非监督学习、半监督学习和增强学习。通过实例说明了每种学习方式的应用场景,并列举了监督学习中的典型算法。
本文介绍了机器学习的主要分类,包括监督学习、非监督学习、半监督学习和增强学习。通过实例说明了每种学习方式的应用场景,并列举了监督学习中的典型算法。
Python3玩转儿 机器学习(3)
机器学习算法可以分为:
- 监督学习
- 非监督学习
- 半监督学习
- 增强学习
监督学习:给机器的训练数据拥有“标记”或者“答案”,例如:

我们需要告诉机器左边的画面是一只狗,而右边的照片是一只猫。同理对于MNIST数据集,给机器图像信息后还应该附上标记信息,如图所示:

运用监督学习的场景举例:
- 图像已经拥有了标定信息
- 银行已经积累了一定的客户信息和他们信用卡的实用信息
- 医院已经积累了一定的病人信息和他们最终确诊是否患病的情况
- 市场积累了房屋的基本信息和最终成交的金额
- ......
此课程中学习的大部分算法属于监督学习算法
- K近邻
- 线性回归和多项式回归
- 逻辑回归
- SVM
- 决策树和随机森林
非监督学习:给机器训练数据没有任何“标记”或者“答案”
聚类分析:对没有“标记”的数据进行分类
非监督学习一个非常重要的作用就是对数据进行降维处理。
- 特征提取:信用卡的信用评级和人的胖瘦无关?无关的特征丢掉
- 特征压缩:PCA
降维处理的意义:方便可视化
非监督学习还可以进行异常检测
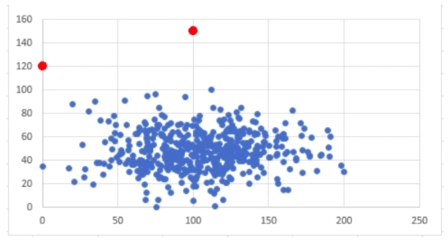
如图所示:图中两个红点明显与其他点脱离,如果它们同属与一种数据,我们可以将这两个点归类为异常,将其去除。当突然图中为二维点,在高维中我们会使用相应的算法剔除异常数据。
半监督学习:一部分数据有“标记”或者“答案”,另一部分没有
相对监督学习,更常见的是各种原因产生的标记缺失的半监督学习。
通常都先使用无监督学习手段对数据做处理,之后使用监督学习手段作模型的训练和预测。
增强学习:根据周围环境的情况,采取行动,根据采取行动的结果,学习行动方式。
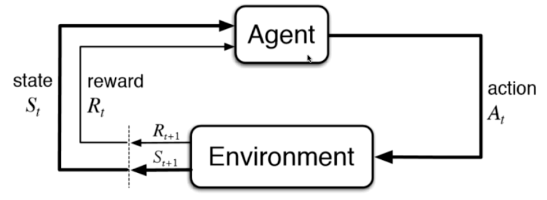
监督学习和半监督学习是基础。

















 5451
5451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









