




Pig到底是干什么的。
Pig最早是雅虎公司的一个基于Hadoop的并行处理架构,后来Yahoo将Pig捐献给Apache(一个开源软件的基金组织)的一个项目,由Apache来负责维护,Pig是一个基于 Hadoop的大规模数据分析平台,它提供的SQL-like语言叫Pig Latin,该语言的编译器会把类SQL的数据分析请求转换为一系列经过优化处理的MapReduce运算。Pig为复杂的海量数据并行计算提供了一个简 易的操作和编程接口,这一点和FaceBook开源的Hive(一个以SQL方式,操作hadoop的一个开源框架)一样简洁,清晰,易上手!
那么雅虎公司主要使用Pig来干什么呢?
1)吸收和分析用户的行为日志数据(点击流分析、搜索内容分析等),改进匹配和排名算法,以提高检索和广告业务的质量。
2)构建和更新search index。对于web-crawler抓取了的内容是一个流数据的形式,这包括去冗余、链接分析、内容分类、基于点击次数的受欢迎程度计算(PageRank)、最后建立倒排表。
3)处理半结构化数据订阅(data seeds)服务。包括:deduplcaitin(去冗余),geographic location resolution,以及 named entity recognition.
使用Pig来操作hadoop处理海量数据,是非常简单的,如果没有Pig,我们就得手写MapReduce代码,这可是一件非常繁琐的事,因为MapReduce的任务职责非常明确,清洗数据得一个job,处理得一个job,过滤得一个job,统计得一个job,排序得一个job,编写DAG(带先后顺序依赖的)作业很不方便,这还可以接受,但是每次只要改动很小的一个地方,就得重新编译整个job,然后打成jar提交到Hadoop集群上运行,是非常繁琐的,调试还很困难,所以,在现在的大互联网公司或者是电商公司里,很少有纯写MapReduce来处理各种任务的,基本上都会使用一些工具或开源框架来操作。
随着,数据海啸的来临,传统的DB(Oracle、DB2)已经不能满足海量数据处理的需求,MapReduce逐渐成为了数据处理的事实标准,被应用到各行各业中。所以,我们不再期望所有的客户都能快速开发应用相关代码,只能把客户的工作变得简单,就像使用SQL语言,经过简单培训就可以“云”上操作。
Pig就是为了屏蔽MapReduce开发的繁琐细节,为用户提供Pig Latin这样近SQL语言处理能力,让用户可以更方便地处理海量数据。Pig将SQL语句翻译成MR的作业的集合,并通过数据流的方式将其组合起来。
Pig的一个简单处理流程,如下所示:
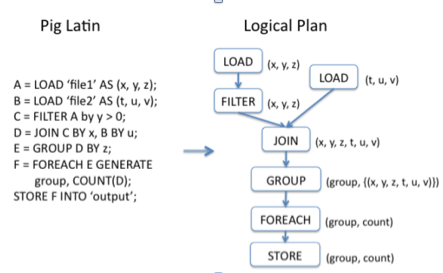
执行引擎如下所示: 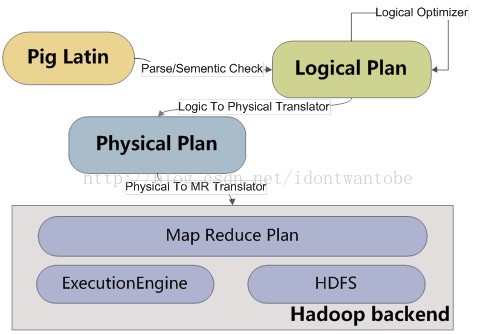
在Pig里面,每一步操作,都是一个数据流,非常容易理解,你想要什么,它就能得到什么,即使不能得到,我们也可以通过轻松扩展UDF来实现,比SQL更容易理解,每一步要做什么,非常容易上手和学习,在大数据时代,了解和使用Pig来分析海量数据是非常容易的。
最后告诉大家一个好消息,在最新的Pig(0.14)发行版里,有两个重要的特性:
(1)支持Pig运行在Tez上
(2)支持Orc格式的存储
Pig到底是干什么的
最新推荐文章于 2022-02-25 16:26:23 发布

















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









