




 博客围绕K-Means算法在机器学习中的应用展开,虽未给出具体内容,但可知聚焦该算法在机器学习领域的运用,K-Means算法是重要的聚类算法,在数据挖掘等方面有广泛应用。
博客围绕K-Means算法在机器学习中的应用展开,虽未给出具体内容,但可知聚焦该算法在机器学习领域的运用,K-Means算法是重要的聚类算法,在数据挖掘等方面有广泛应用。
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_blobs # 聚类数据测试工具
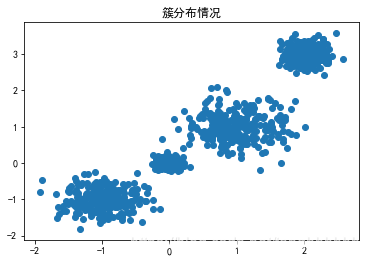
# 在sklearn中,随机生成1000个样本,每个样本2个特征,共4个簇,簇中心在[-1, -1], [0, 0], [1, 1], [2, 2],簇方差分别为[0.3,0.1,0.4,0.2]
X, y = make_blobs( n_samples=1000,
n_features=2,
centers=[[-1, -1], [0, 0], [1, 1], [2, 3]],
cluster_std=[0.3,0.1,0.4,0.2]
)
# 解决plt标题中文乱码-----
import matplotlib as mpl
mpl.rcParams['font.sans-serif']=['SimHei'] #指定默认字体 SimHei为黑体
mpl.rcParams['axes.unicode_minus']=False #用来正常显示负号
#------------------------
# 查看簇的分布情况
plt.scatter(X[:,0],X[:,1])
plt.title("簇分布情况")
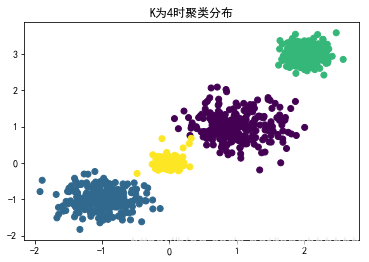
from sklearn.cluster import KMeans
y_pred = KMeans(n_clusters=4).fit_predict(X) # K为4时
plt.scatter(X[:,0],X[:,1],c=y_pred) # 绘图
plt.title("K为4时聚类分布")

















 4173
4173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









