



摘要
为了更深入且更准确地学习卷积神经网络,可以将密集块融入卷积网络中以缩短层之间的连接。在本文中,我们提出了一种基于密集块深度卷积神经网络的服装品牌预测方法,用于标志检测与识别。设计了多个密集块以提高对服装品牌标志的预测准确率。我们还构建了一个包含品牌和标志信息的新服装数据集,以促进该任务的实现。在实验中,我们展示了该方法相比一些最先进的方法能够取得更好的性能。
I. 引言
近年来,服装检索和服装类型分类[5]在计算机视觉和模式识别领域引起了广泛关注。然而,目前尚无关于服装品牌分析的相关研究,这促使我们开展这一课题的研究。
有许多因素,例如品牌、价格、风格、颜色、材料和图案,会影响人们选择服装。在这些因素中,品牌是一个非常重要的因素,而服装品牌预测也是一项实际且极具挑战性的任务。
基于深度卷积神经网络(DCNN)的许多方法在服装类型识别、服装检索、目标检测与识别、年龄估计 [11, 13]和视觉质量评估[12, 15]方面取得了显著突破。由于YOLOv3[6]在目标检测中取得了令人满意的结果,我们通过在YOLOv3中引入密集块[14] ,设计了一种新的DCNN模型用于服装品牌预测。
目前,尚不存在包含品牌信息的服装数据集。据我们所知,我们是首个构建包含品牌信息的大规模服装数据集的团队。
我们的实验表明,我们提出的密集块YOLOv3在构建的服装品牌数据集上能够比原始YOLOv3实现更高的品牌预测准确率。我们还表明,在该新的服装数据集上,我们提出的方法在服装品牌预测任务中优于几种最先进的方法。
II. 数据集构建
首先,我们在互联网上搜索服装品牌,并访问它们的官方网站(如果有的话)。此外,我们还会访问一些服装在线购物网站,这些网站包含其他服装品牌。通过这种方式,我们可以尽可能多地收集品牌。
其次,我们开始从找到的每个网站抓取图片,包括官方网站:H&M、Superdry、Forever21、ROOTS、MANGO等,以及在线购物网站:亚马逊、Zappos、雅虎等。
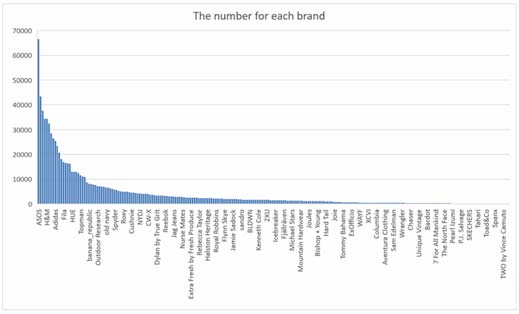
在图像采集过程中,每件服装可能包含4到8张对应不同观察角度的图像。同一件服装的所有图像被视为一个配对。不同品牌的图像数量和分辨率各不相同。224个品牌各自的图像数量如图1所示。我们在收集服装属性时遇到的一个困难是不一致性,即不同网站显示属性的格式不同。
在此阶段结束时,我们的基准数据集——服装品牌(CB)数据集——已收集了一百万张以上的图像,并包含多个属性,例如品牌、类型、颜色、材料、价格、配对等。图2展示了4个服装品牌的一些样本图像。可以看出,一些品牌有标志,而另一些则没有标志。
最后,我们手动标注了从选定的25个服装品牌中提取的25万张图像中的品牌标志,从而构建了一个数据集子集:服装品牌标志(CBL)数据集。然而,许多图像中将没有标志。例如,某些服装单品在正面视角可见标志,但在同一服装单品的其他观察角度中则无法找到标志。经过标注过程后,保留了包含清晰标志的5.7万张图像,且所有图像均包含品牌和边界框信息。

我们还将我们的数据集与一些现有的数据集进行了比较:服装属性(CA)[2],具有风格的服装分类(ACS)[3],多彩时尚(CF)[4],多视角服装(MVC)[5],和 DeepFashion(DF)[1]。比较结果总结在表1中。可以看出,我们的数据集具有最高的分辨率,并且是唯一包含品牌和价格信息的数据集。
| 数据集 | 图像数量 | 类型 | 颜色 | 材料 | 配对 | 品牌 | 最高分辨率 | 价格 |
|---|---|---|---|---|---|---|---|---|
| ACS [3] | 89,484 | Y | N | /A | N/A | N/A | 224*192 | N/A |
| CA [2] | 1,856 | Y | Y | N/A | N/A | N/A | 864*1296 | N/A |
| CF [4] | 2,628 | Y | Y | N/A | N/A | N/A | 400*600 | N/A |
| MVC [5] | 161,260 | Y | Y | Y | Y | N/A | 1920*2240 | N/A |
| DF [1] | 800k up | Y | Y | Y | Y | N/A | 750*1101 | N/A |
| CB [ours] | 57,000 | Y | Y | Y | Y | Y | 1900*2375 | Y |
| CBL[ours] | 1,000k up | Y | Y | Y | Y | Y(带标志) | 1900*2375 | Y |
III. 提出的方法
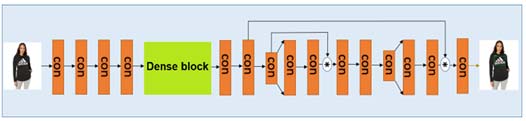
由于YOLOv3在目标检测与识别方面表现出色,我们提出的方法基于YOLOv3,通过用密集块替代残差块来实现。用于品牌标志预测的整体密集块YOLOv3框架如图3所示。我们使用密集块的原因是为了更高效地训练深度卷积神经网络,并使其结构更深。显然,各层之间的连接更短,每一层都以前馈方式与其他所有层相连。
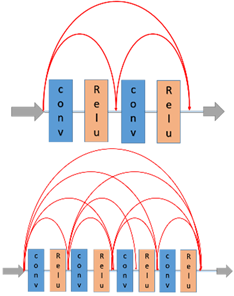
在本文中,我们设计了4种不同的密集块,如图4所示,其中密集块(如图3中的绿色框所示)分别包含2、3、4、5个卷积层。每个卷积层的大小为3×3,并后接一个ReLU激活。所有其他参数均设置为与YOLOv3模型相同。
IV. 实验
在实验中,我们使用57,000件衣物使用带有品牌和标志信息的图像来验证我们提出的框架。在实验设置中,分别使用70%、10%和20%的图像进行训练、验证和测试。
我们测试了四种密集块设计:2层、3层、4层和5层密集块。结果如表2所示。我们还将我们的框架与一些最先进的方法进行了比较,结果也列在表2中。结果显示,我们的方法能够显著提升性能,并达到最高准确率62.59%。这证明了基于密集块的YOLOv3是高效的。
| 方法 | 准确率 |
|---|---|
| YOLOv2[7] | 45.83% |
| YOLOv3[6] | 51.22% |
| RCNN [8] | 45.59% |
| Fast‐RCNN [9] | 47.38% |
| Faster‐RCNN [10] | 48.97% |
| 2‐密集YOLOv3[ours] | 57.59% |
| 3‐密集YOLOv3[ours] | 58.20% |
| 4‐密集型YOLOv3[ours] | 62.28% |
| 5‐密集YOLOv3[ours] | 62.59% |
V. 结论
我们构建了一个新的大规模服装品牌数据集。它是唯一包含品牌(标志)和价格信息的服装数据集。本文提出了一种基于密集块的YOLOv3框架,用于解决服装品牌标志预测问题,并在性能上优于几种最先进的方法。未来,我们将考虑在整个数据集中进行服装品牌预测,其中大多数图像没有可用的标志信息。


















 874
874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









