



1.PIDS:Prior Image Double Semantic Similarity
先验图像语义相似性。
论文:Prior Image Guided Snapshot Compressive Spectral Imaging

1.1前沿知识-全变分正则化 (Total Variation Regularization,简称 TV 正则化)
TV 正则化是一种让图像“变平滑”以去除噪声,但又能神奇地“保留边缘”不被磨损的方法。
1.1.1理解变分
想象把一张图看作地图,像素高的地方是山峰,低的地方是山谷。定义变分和全变分:
-
变分 (Variation):指的是相邻两个像素之间的“高度差”(梯度)。
-
全变分 (Total Variation):就是把整张图里所有相邻像素的“高度差的绝对值”加起来。
举个例子:

1.1.2为什么要用TV做正则化
图像重建中,我们希望告诉计算机“自然图像不应该长得像噪点,而应该是干净平滑的。”于是我们在优化目标中加入TV正则化项:

这意味着我们寻找的图像x,既要能解释测量数据,又要让它的 TV 值尽可能小。“最小化 TV 值” 本质上就是在压制噪声。
1.1.3为什么TV能保边
传统的去噪(如 L2 正则化或高斯滤波)是把所有突变都抹平,导致图像边缘模糊。
而 TV 正则化使用的是 L1 范数(梯度的绝对值和)。在数学上,L1 范数具有“稀疏诱导性”。
-
效果:它倾向于让图像的梯度在大部分地方为 0(也就是完全平滑),但允许在少数地方保留较大的值(也就是边缘)。
-
结果:它把图像变成了**“分片平滑” (Piecewise Smooth)** 的样子——像剪纸画一样,色块内部很干净,边缘很锐利。
1.1.4数学公式

1.2PIDS--PIDS是一种照着RGB画高光谱图的数学约束机制
PIDS 试图最小化“恢复图像的 TV 值”与“先验图像的 TV 值”之间的差异。直观地说,就是要求恢复出来的光谱图像在纹理复杂度上要逼近高清 RGB 图像。

直接优化PIDS公式是很困难的,因为||TV(x)-TV(y)||这种形式在数学上处理起来很复杂(非凸或难以直接求导求解)。因此该论文作者在lemma1和公式(15)-(20)中推导出一个关键的不等式:

作者并没有直接去解原始的 PIDS 公式,而是通过最小化其上界来代替。最终的优化目标变成了:
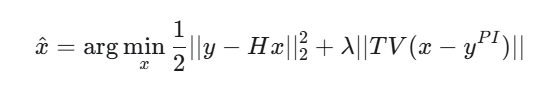
这隐含了一个假设:光谱图像和 RGB 图像的边缘应该在相同的位置对齐:
-
如果在某处 RGB 图像有一个边缘,光谱图像也应该有一个边缘。
-
如果两者结构一致,它们相减后,边缘会被抵消,差值图就会变得很平滑(TV 值很小)。
-
如果重建出的光谱图像出现了伪影或错位,差值图就会很乱,TV 值就会变大,算法就会惩罚这种情况。

2.PIE:Prior images guided generative autoEncoder
先验图像引导的生成式自编码器。
论文:Prior Images Guided Generative Autoencoder Model for Dual-Camera Compressive Spectral Imaging
2.1
-
应用场景:双相机压缩光谱成像 (DC-CASSI)。这类系统同时包含两个相机:
-
CASSI 相机:拍摄压缩后的光谱测量值(只有一张 2D 图,丢失了很多光谱信息)。
-
RGB/全色相机:拍摄场景的高清 RGB 或灰度图(有丰富的空间细节,但光谱信息不准)。
-
-
核心目标:利用 RGB 图像作为“先验”(Prior),帮助从模糊的 CASSI 测量值中恢复出高质量的 3D 高光谱图像(HSIs)。
PIDS模型存在两个问题:
-
空间信息利用不足:虽然利用了 RGB 图的空间纹理,但并没有充分挖掘其深层语义信息。
-
光谱一致性差:RGB 图像虽然清晰,但它的光谱曲线和真实的高光谱曲线是不一样的(例如 RGB 只有 3 个波段,而高光谱有 30+ 个)。如果直接照搬 RGB 的信息,会导致恢复出来的光谱曲线失真(Spectral Distortion)。
应对以上两个问题,PiE 的解决方案:设计一个生成式自编码器(Generative Autoencoder),专门用来生成“光谱平滑”且“空间清晰”的图像,弥补 RGB 图在光谱上的缺陷。
2.2 PIE的核心组件
PIE模型并非单纯的深度学习网络,而是结合了传统优化(ADMM)和深度学习(自编码器)的混合框架。PiE 模型就像一个聪明的画师,它手里拿着一张黑白的草图(CASSI 测量值)和一张彩色的照片(RGB先验图)。它利用 RGB 照片的轮廓(PIDS),并通过一个自学的神经网络(SAE)脑补出颜色的细节变化(光谱生成),最终画出了一幅既清晰又色彩准确的 3D 高光谱图像。
2.2.1优化目标函数

2.2.2生成式自编码器(SAE)

2.3 PIE流程(ADMM优化)
为了解决上述问题,作者使用了ADMM算法,将其拆解为三个子问题交替求解:

2.4 PIE优势
-
无需预训练:不需要像其他深度学习方法那样依赖大规模数据集(如 CAVE, KAIST)训练几天几夜,它是针对单张图即插即用的。
-
双重引导:
-
空间上:PIDS 正则项利用 RGB 图的边缘。
-
光谱上:SAE 网络 + STV 正则项利用 RGB 图的语义并平滑光谱。
-
-
速度与质量的平衡:
-
比纯传统方法(如 DeSCI)快几十倍。
-
比纯深度学习方法(泛化性差)更稳定,重建质量(PSNR/SSIM)更高,达到了 State-of-the-art。
-


















 9003
9003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









