




 本文详细解析Hadoop文件上传过程中的关键概念,包括block、packet和chunk的作用及大小,阐述了client如何向namenode请求写文件,以及datanode间的pipeline数据传输流程。
本文详细解析Hadoop文件上传过程中的关键概念,包括block、packet和chunk的作用及大小,阐述了client如何向namenode请求写文件,以及datanode间的pipeline数据传输流程。
相关概念:
block:文件上传之前要分块,这个块就是block,一般为128M,是最大的一个单位。
packet:packet是第二大单位,它是client向datanode或者datanode之间经过pipline传输数据的基本单位,默认为64kb。
chunk:chunk是最小的单位,它是client向datanode或者datanode之间经过pipline传输数据时进行校验的基本单位,默认为512b,因为chunk用做校验,所以带有4b的校验位,所以实际上每个chunk写入packet的大小为516b。
流程分析:
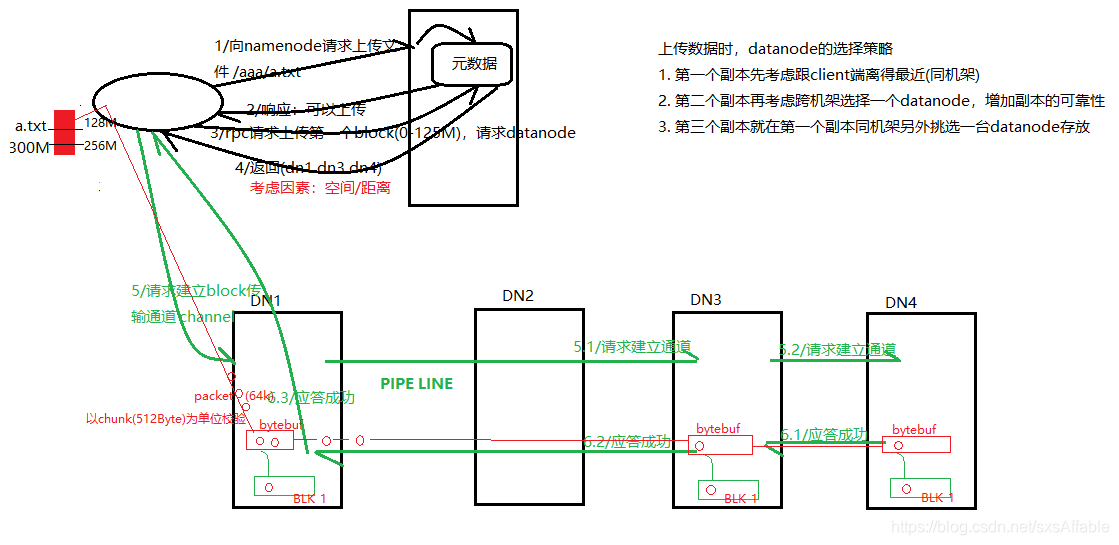
1、client向namenode发出写文件请求。
2、namenode检查是否可以写,若通过检查,会将操作记录到edits中(edits会在下一个博客详细介绍)。
3、client将文件按照128M一个block进行切分,,通过rpc请求上传第一个block到datanode。
4、namenode根据选择策略,返回多个datanode节点,若设置三个副本,则返回三个datanode。
5、client请求第一个datanode简历传输通道channel,第一个datanode向第二个datanode请求建立channel,第二个向第三个请求建立channel。
6、应答成功,构成一系列pipline。
7、client向输出流对象中写入数据,client向第一个datanode写入一个packet,在写的时候输出流会有一个chunk buff,写满一个chunk以后,会计算并写入当前的chunk,之后再把带有校验位的chunk写入packet,当一个packet写满后,packet会进入dataQueue,其他的datanode从dataQueue队列中获取packet,通过pipline传输过去。同时,每个datanode成功存储一个packet之后,会返回一个ack packet,放入ackQueue中。
8、写完第一个block,继续写第二个block、第三个..
9、写完以后,关闭输出流,向namenode汇报情况。.
10、如果传输过程中失败,并且不是全部失败,有一个已经传输成功,就认为已经传输成功了,之后namenode会做异步同步。

















 3176
3176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









