



测试函数ce🍨 本文为🔗365天深度学习训练营中的学习记录博客
●🍖 原作者:K同学啊
0.前期准备
开发及运行环境
● 语言环境:Python3.9.13
● 编译器:Jupyter Lab
● torch-1.9.1 Cuda 11.2 torchvision-0.10.1
● 涉及的库包括:torch、torch.nn、matplotlib.pyplot 、torchvision、numpy、torch.nn.functional
————————————————
版权声明:本文为优快云博主「swtee」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.youkuaiyun.com/swtee/article/details/149547849
数据依旧来自K同学
————————————————
版权声明:本文为优快云博主「swtee」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.youkuaiyun.com/swtee/article/details/149814018
VGG-16(Visual Geometry Group-16)是由牛津大学视觉几何组(Visual Geometry Group)提出的一种深度卷积神经网络架构,用于图像分类和对象识别任务。VGG-16在2014年被提出,是VGG系列中的一种。VGG-16之所以备受关注,是因为它在ImageNet图像识别竞赛中取得了很好的成绩,展示了其在大规模图像识别任务中的有效性。
from torchvision.models import vgg16
model = vgg16(pretrained = True).to(device) # 加载预训练的vgg16模型
for param in model.parameters():
param.requires_grad = False # 冻结模型的参数,这样子在训练的时候只训练最后一层的参数
model.classifier._modules['6'] = nn.Linear(4096,len(classeNames)) # 修改vgg16模型中最后一层
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
测试函数
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
结果:
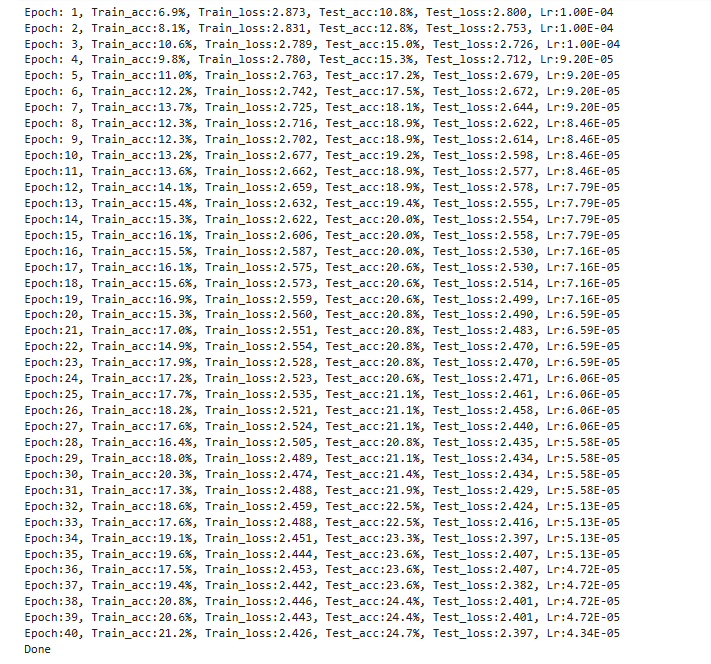
可视化输出:
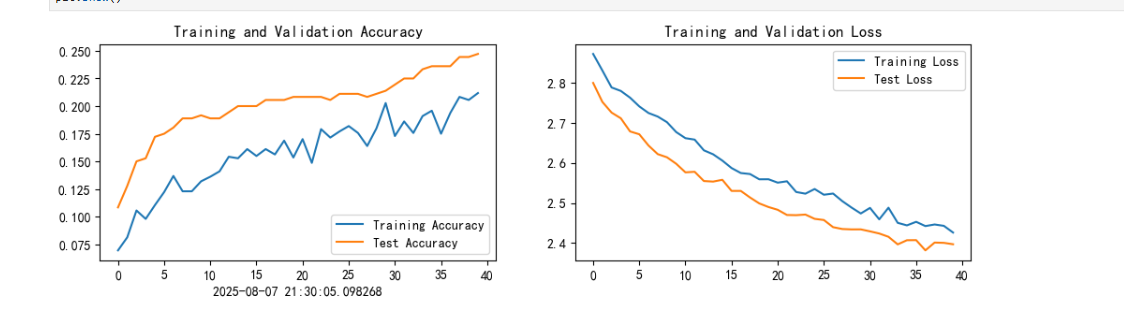
调参:
待续
本次使用pytorch深度学习环境对官方的VGG-16模型进行调用,并且保存最佳模型权重。VGG-16模型的最大特点是深度。除此之外,其卷积层都采用3x3的卷积核和步长为1的卷积操作,同时卷积层后都有ReLU激活函数,从而降低过拟合风险。
2.训练过程中发现训练和测试的acc都过低(约为20%),通过调整动态学习率予以调整,初始学习率增大一个数量级之后,此问题得到一定的解决。


















 1572
1572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









