






 本文深入解析BloomFilter的工作原理,包括其如何通过多个哈希函数减少冲突,以及在大数据量下如何平衡时间和空间效率。同时介绍了Guava库中BloomFilter的实现细节,以及在实际场景如监控数据收集、URL爬取和垃圾邮件过滤中的应用。
本文深入解析BloomFilter的工作原理,包括其如何通过多个哈希函数减少冲突,以及在大数据量下如何平衡时间和空间效率。同时介绍了Guava库中BloomFilter的实现细节,以及在实际场景如监控数据收集、URL爬取和垃圾邮件过滤中的应用。
算法背景
如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路,存储位置要么是磁盘,要么是内存。很多时候要么是以时间换空间,要么是以空间换时间。
在响应时间要求比较严格的情况下,如果我们存在内里,那么随着集合中元素的增加,我们需要的存储空间越来越大,以及检索的时间越来越长,导致内存开销太大、时间效率变低。
此时需要考虑解决的问题就是,在数据量比较大的情况下,既满足时间要求,又满足空间的要求。即我们需要一个时间和空间消耗都比较小的数据结构和算法。Bloom Filter就是一种解决方案。
Bloom Filter 概念
布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
Bloom Filter 原理
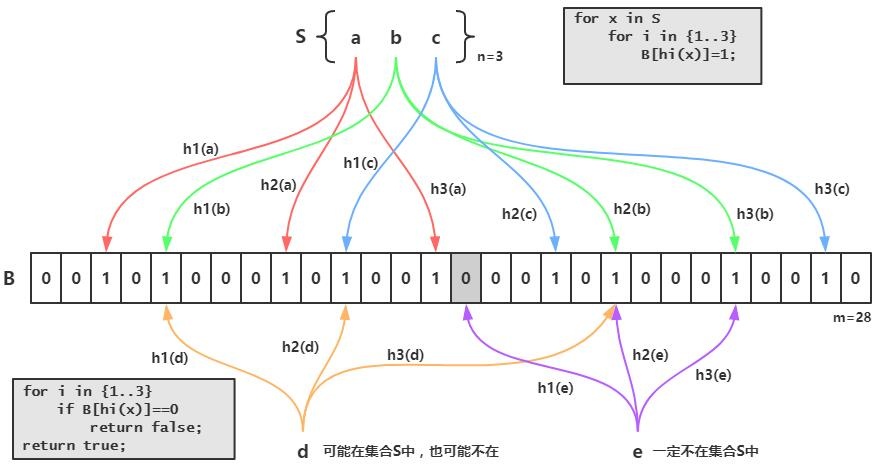
布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
Bloom Filter跟单哈希函数Bit-Map不同之处在于:Bloom Filter使用了k个哈希函数,每个字符串跟k个bit对应。从而降低了冲突的概率。
Bloom Filter的缺点
bloom filter之所以能做到在时间和空间上的效率比较高,是因为牺牲了判断的准确率、删除的便利性
- 存在误判,可能要查到的元素并没有在容器中,但是hash之后得到的k个位置上值都是1。如果bloom filter中存储的是黑名单,那么可以通过建立一个白名单来存储可能会误判的元素。
- 删除困难。一个放入容器的元素映射到bit数组的k个位置上是1,删除的时候不能简单的直接置为0,可能会影响其他元素的判断。可以采用Counting Bloom Filter
Bloom Filter 实现
布隆过滤器有许多实现与优化,Guava中就提供了一种Bloom Filter的实现。
在使用bloom filter时,绕不过的两点是预估数据量n以及期望的误判率fpp,
在实现bloom filter时,绕不过的两点就是hash函数的选取以及bit数组的大小。
对于一个确定的场景,我们预估要存的数据量为n,期望的误判率为fpp,然后需要计算我们需要的Bit数组的大小m,以及hash函数的个数k,并选择hash函数
(1)Bit数组大小选择
根据预估数据量n以及误判率fpp,bit数组大小的m的计算方式: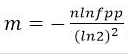
(2)哈希函数选择
由预估数据量n以及bit数组长度m,可以得到一个hash函数的个数k: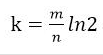
哈希函数的选择对性能的影响应该是很大的,一个好的哈希函数要能近似等概率的将字符串映射到各个Bit。选择k个不同的哈希函数比较麻烦,一种简单的方法是选择一个哈希函数,然后送入k个不同的参数。
哈希函数个数k、位数组大小m、加入的字符串数量n的关系可以参考Bloom Filters - the math,Bloom_filter-wikipedia
看看Guava中BloomFilter中对于m和k值计算的实现,在com.google.common.hash.BloomFilter类中:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
|
BloomFilter实现的另一个重点就是怎么利用hash函数把数据映射到bit数组中。Guava的实现是对元素通过MurmurHash3计算hash值,将得到的hash值取高8个字节以及低8个字节进行计算,以得当前元素在bit数组中对应的多个位置。MurmurHash3算法详见:Murmur哈希,于2008年被发明。这个算法hbase,redis,kafka都在使用。
这个过程的实现在两个地方:
- 将数据放入bloom filter中
- 判断数据是否已在bloom filter中
这两个地方的实现大同小异,区别只是,前者是put数据,后者是查数据。
这里看一下put的过程,hash策略以MURMUR128_MITZ_64为例:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
|
判断元素是否在bloom filter中的方法mightContain与上面的实现基本一致,不再赘述。
Bloom Filter的使用
简单写个demo,用法很简单,类似HashMap
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
|
Bloom Filter的应用
常见的几个应用场景:
- cerberus在收集监控数据的时候, 有的系统的监控项量会很大, 需要检查一个监控项的名字是否已经被记录到db过了, 如果没有的话就需要写入db.
- 爬虫过滤已抓到的url就不再抓,可用bloom filter过滤
- 垃圾邮件过滤。如果用哈希表,每存储一亿个 email地址,就需要 1.6GB的内存(用哈希表实现的具体办法是将每一个 email地址对应成一个八字节的信息指纹,然后将这些信息指纹存入哈希表,由于哈希表的存储效率一般只有 50%,因此一个 email地址需要占用十六个字节。一亿个地址大约要 1.6GB,即十六亿字节的内存)。因此存贮几十亿个邮件地址可能需要上百 GB的内存。而Bloom Filter只需要哈希表 1/8到 1/4 的大小就能解决同样的问题。

















 1628
1628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









