




在人工智能的发展浪潮中,推理能力一直是衡量大模型实力的重要标准之一。最近,Deepseek 推出了其最新的推理模型 Deepseek R1,业内反响强烈。测试表明,这款大模型的表现已达到与 OpenAI o1 相当的水平,并在一些场景下超越了同类产品。为了验证这一点,我们通过一个经典的数学推理游戏——24点游戏,来对 Deepseek R1 与其他主流大模型的推理能力进行对比评测。
1. Deepseek R1 介绍
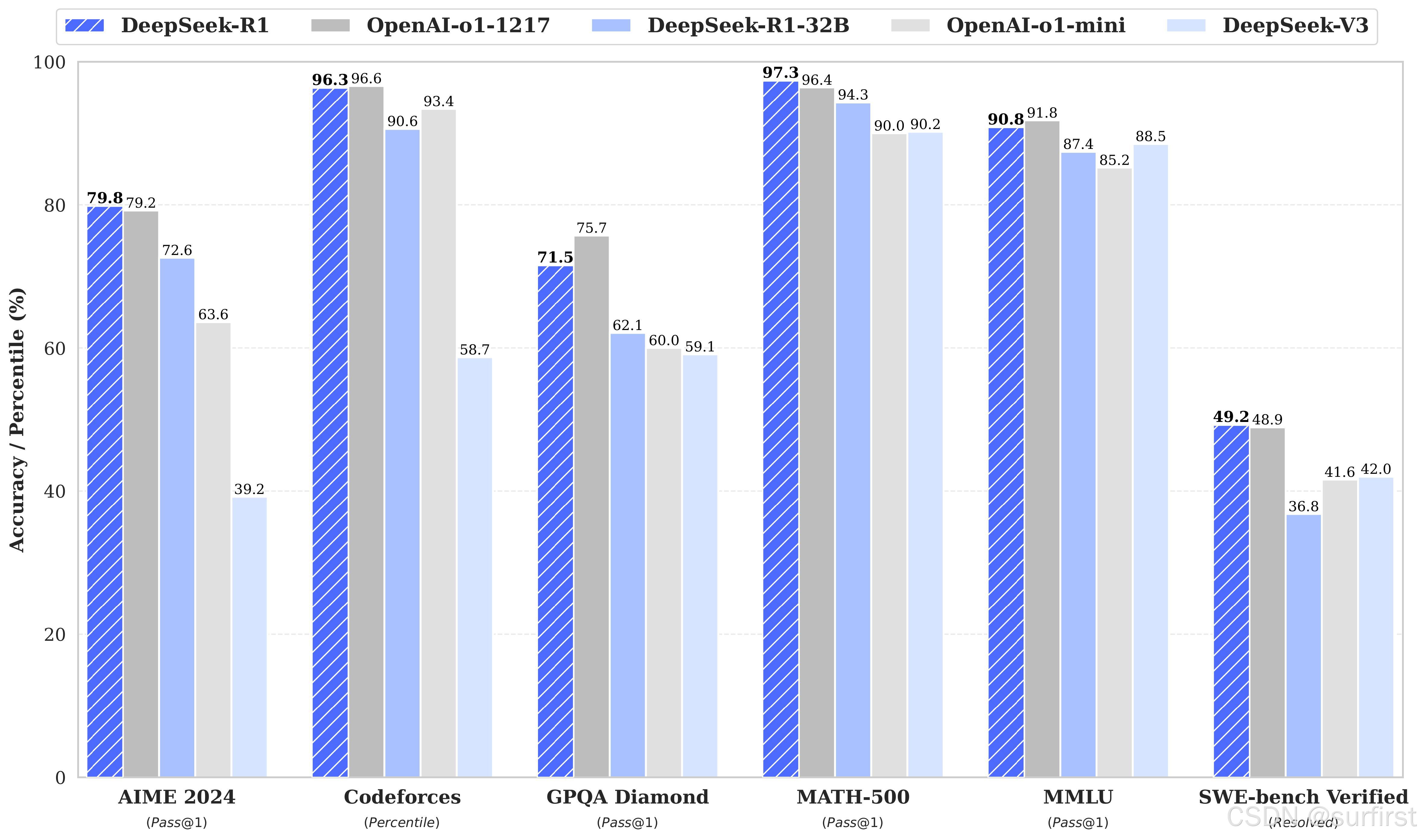
Deepseek R1 是 Deepseek 推出的第二代推理模型,基于大量强化学习(RL)训练并加入冷启动数据(Cold-start data)进行优化,解决了其前代模型 Deepseek R1-Zero 的一些问题,如无监督的强化学习可能导致的语言混合和可读性差等缺陷。Deepseek R1 在数学、编程及推理任务上展示了卓越的能力,与 OpenAI 的 o1 系列模型比肩,甚至在一些基准测试中超越了 OpenAI o1-mini。值得注意的是,Deepseek R1 还开源了多种不同大小的模型,包括从 Deepseek R1 精简的 Qwen 32B 模型,这一版本在多个基准测试中表现出色,达到了业界领先的水平。
2. 评测方法
为了全面评估 Deepseek R1 的逻辑推理能力,我们选择了一个经典的推理任务——24点游戏。这是一个纯粹依赖逻辑推理的数学游戏,不依赖于搜索或枚举解决方案,适合测试模型的推理思维能力。游戏的规则如下:
- 每局随机抽取四张扑克牌,可以重复使用。
- 仅允许使用加法(+)、减法(-)、乘法(×)、除法(÷)四种运算符。
- 每张牌必须使用且只能使用一次。
- 目标是通过这些运算使四张牌的计算结果等于24。
题目设置了两组数字进行测试:</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1089
1089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











