






 本文围绕Linux程序设计展开,介绍了Linux基础知识,如桌面环境、文件系统、逻辑卷管理等。还阐述了调试、进程和信号、POSIX线程、管道、IPC通讯等内容,涉及C语言在Linux系统中的应用,包括信号处理、线程操作等,同时提及了Linux标准。
本文围绕Linux程序设计展开,介绍了Linux基础知识,如桌面环境、文件系统、逻辑卷管理等。还阐述了调试、进程和信号、POSIX线程、管道、IPC通讯等内容,涉及C语言在Linux系统中的应用,包括信号处理、线程操作等,同时提及了Linux标准。
系列文章目录
0、Linux基础知识
linux 桌面环境
shell(bash / dash)
终端仿真器/终端仿真程序
虚拟控制台tty1(桌面环境 gnome等) | tty2 | tty3 …
Linux kernel
Linux系统拥有很高的灵活性和自由度,系统启动后首先进入桌面环境(例如Ubuntu默认进入gnome,用户可更换其他桌面)或者tty(虚拟终端)。当进入桌面环境后可启动终端仿真器(用户可自行更换),终端仿真器会启动默认的shell(Ubuntu默认bash,用户可自行更换)。
文件系统
linux支持多种文件系统
-
Linux文件系统的演进
-
ext文件系统
Linux最初的文件系统,限制较多,比如文件大小不能超过2G等 -
ext2文件系统
ext的升级。容易在系统崩溃或断电时损坏。 -
ext3文件系统
ext2的后续演进,支持最大2TB的文件,能够管理32TB大小的分区。默认采用有序式的日志方法,没有提供数据压缩功能 -
ext4文件系统
ext3的后续版本。最大支持16TB的文件,能够管理1EB大小的分区。默认采用有序日志方式。 -
JFS文件系统
一种比较老旧的文件系统 -
ZFS文件系统
一个稳定的文件系统,与Resier4、Btrfs和ext4势均力敌,拥有数据完整性验证和自动修复功能,最大支持16EB的文件,能能够管理256万亿ZB的存储空间。 -
XFS文件系统
-
NTFS文件系统
windows系统默认文件系统 -
fat文件系统
单个文件传输不能超过4G -
exfat文件系统
Windows U盘文件系统的改进,取消了单个文件不超4G的限制
使用文件系统
1. 首先,需要在存储设备上创建可容纳文件系统的分区
分区管理工具:
- fdisk
老而弥坚,可以在任何存储设备上创建和管理分区。但只能处理最大2TB的硬盘,再大就只能换工具
不允许调整现有分区大小,只能删除现有分区然后重新创建。 - gdisk
如果存储设备要使用GUID(GPT)分区表就用它
许多命令和fdisk很像 - GNU parted
允许调整现有分区大小
硬盘设备名称分配格式:
- SATA驱动器和SCSI驱动器:设备命名格式为 /dev/sdx(x = a, b, c, …)
- SSD NVMe驱动器:/dev/nvmeNn#(N = 0, 1, …; #=1,…,是分配给该驱动器的名称空间编号)
- IDE驱动器:/dev/hdx(x = a, b, c, …)
2. 创建文件系统(格式化):
将数据存储到分区之前,必须使用某种文件系统对其进行格式化,以便Linux能够使用分区。
3. 挂载分区
为分区创建好文件系统之后,是将其挂载到虚拟目录中的某个挂载点,以便在新分区中存储数据
mkdir /home/part
# 临时挂载分区。要在Linux启动时挂载需要添加在/etc/fstab文件中
sudo mount -t ext4 /dev/sdb1 /home/part
lsblk -f /dev/sdb
4. 文件系统的检查与修复
fsck options filesystem
逻辑卷管理
LVM(Logical Volume Manager)和文件管理系统是关于存储管理的两个不同的概念和技术。
LVM是一种逻辑卷卷管理技术,用于管理磁盘驱动器和存储设备,它实现了在物理存储设备上创建逻辑卷,并将它们合并成一个虚拟组卷组的功能。LVM可以在运行时动态地调整逻辑卷的大小,提供更高的灵活性和可扩展性,以满足存储需求的变化。
文件管理系统是用于组织和管理计算机体系中的文件的软件或子系统。它涵盖了对文件的创建、存储、访问、修改和删除等操作。文件管理系统负责将文件存储在物理存储设备上,并提供对文件的访问和保护等功能。
LVM和文件管理系统之间的联系在于,LVM可以为文件管理系统提供灵活的存储管理解决方案。通过使用LVM,文件管理系统可以更加灵活地管理磁盘空间,轻松地扩展或缩小文件系统的大小,而无需重新分区或复制数据。
当文件管理系统需要增加存储空间时,LVM可以添加新的物理卷(例如硬盘或磁盘分区)到现有的卷组中,然后将该卷组扩展到新的物理卷组上。这使得文件系统可以继续在增加的空间上存储文件,并无需重新安装操作系统。
总的来所,LVM为文件管理系统提供了更高的灵活性和可用性,使得存储空间管理更加方便和可靠。它们共同为计算机系统中的文件管理提供了更好的性能和扩展性。
LVM允许将多个分区组合在一起,作为单个分区(逻辑卷)进行格式化、在Linux虚拟目录结构上挂载、存储数据等。
- 物理卷 physical volume,PV
通过LVM的pvcreate命令创建。指定一个未使用的磁盘分区(或整个驱动器)由LVM使用。该过程中,LVM结构、卷标和元数据都会被添加到该分区。 - 卷组
volume group, VG 通过vgcreate创建。将PV加入存储池,存储池用于构建各种逻辑卷。即,多个PV集中在一起形成VG,由此形成了一个存储池,从中为逻辑卷(LV)分配存储空间。
可存在多个VG, vgcreate同时也会添加卷组的元数据。
一个磁盘可以有多个PV,一个PV同时只能属于某个VG - 逻辑卷
logical volume, LV, 由lvcreate创建。LV由VG的存储空间块(PE, physical extents)组成。可以使用文件系统格式化LV,然后将其挂载,然后像普通磁盘分区一样使用。
LV不能跨VG创建,可以通过相应的命令增减LV的大小。
linux LVM
- 创建物理卷
pvcreate /dev/sdc1 /dev/sdd1 /dev/sde1 - 创建VG
vgdisplay # 检查当前系统的的VG vgcreate vg00 /dev/sdc1 /dev/sdd1 # 创建VG # vgextend扩展VG - 创建LV
创建好LV之后就可以将其视为普通分区。它可以根据需要扩大或收缩该分区lvcreate -L 1g -v vg00 lvdisplay /dev/vg00/lvol0 # 显示系统LV信息 lvs lvscan - 格式化和挂载LV
mkfs.ext4 /dev/vg00/lvol0 insomedir mk my_LV mount -t ext4 /dev/vg00/lvol0 my_LV # 以上为临时挂在,开机自动挂载需在/etc/fstab中添加一条记录 - 扩大或收缩VG和LV
在lvextend扩展后只是扩展了LV的大小,而此时文件系统并未感知到,还需要使用vgextend vgreduce lvextend lvreduceresize2fs(ext4)等来扩展文件系统
十、调试
- 错误类型
- 常用调试技巧
- 使用GDB和其他工具进行调试
- 断言
- 内存调试
断言
#include <assert.h>
void assert(int expression);
assert宏对表达式进行求值,如果结果为零,它就往标准错误写一些诊断信息,然后调用abort结束程序的运行。
头文件assert.h定义的宏受到NDEBUG的影响。如果程序在处理这个头文件时已经定义了NDEBUG,就不定义assert宏。
十一、进程和信息号
- 进程结构、类型和调度
- 用不同的方法启动新进程
- 父进程、子进程和僵尸进程
- 什么是信号以及如何使用
进程定义:一个其中运行着一个或多个线程的地址空间和这些线程所需要的系统资源。可简单看作运行着的程序。
pid==1一般是init进程。
进程表
Linux进程表就像一个数据结构,它把当前加载在内存中的所有进程的有关信息保存在一个表中,其中包括进程的PID、进程的状态、命令字符串和其它一些ps命令输出的各类信息。操作系统通过进程的PID对它们进行管理,这些PID是进程表的索引。进程表的长度是有限制的,所以操作系统能够支持的同时运行的进程数也是有限制的,如今可同时运行的进程数可能只与用于建立进程表项的内存容量有关。
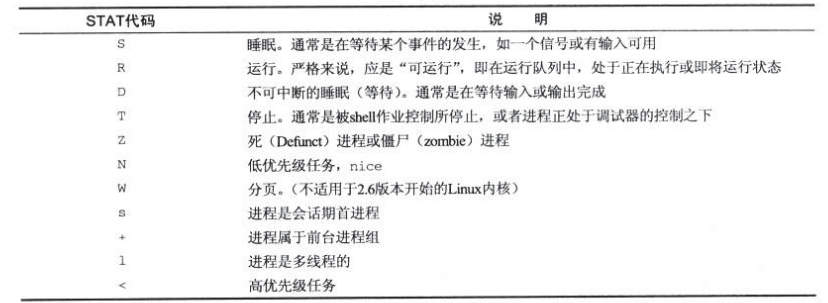
进程调度
一个进程的nice值默认为0,并将根据这个进程的表现而不断变化。
可以使用nice命令设置进程的nice值,使用renice命令调整它的值。
nice prog_name & #它将分配一个+10的nice值
renice 10 pid # Guess what will happen.
在Linux系统中,PR值指的是进程的优先级。PR值越小,表示进程的优先级越高,而PR值越大,表示进程的优先级越低。这是因为Linux系统中采用了静态优先级和动态优先级相结合的调度算法。
静态优先级由nice值来表示,范围通常是-20到+19,其中-20是最高优先级,+19是最低优先级。而PR值则是通过将nice值进行转换得到的,具体的计算方式是:
PR = 20 + nice值
因此,当nice值越小时,PR值越大,进程的优先级就越高。
动态优先级则是根据进程的行为和运行状态实时调整的,使得系统更具响应性。这样,通过将静态优先级和动态优先级结合起来,Linux系统可以根据进程的行为和系统负载来合理地分配CPU资源,从而实现更好的性能和响应性。
启动新进程
int system(const char* string);
// 运行以字符串参数的形式传递给他的命令(并等待命令的完成,依命令而定)。命令的执行情况就如同在shell中执行
// system创建子进程,wait与否取决于 输入的命令
execve函数族
fork
wait, waitpid
- 在一个子进程终止前,wait使调用者阻塞
- waitpid有一个选项,可使调用者不阻塞
- waitpid等待一个指定的子进程;wait等待所有的子进程,返回任一终止子进程的状态
信号
术语生成(raise)表示一个信号的产生,捕获(catch)表示接收到一个信号。信号由shell和终端处理器生成来引起中断。
信号处理
-
老的signal函数
#include <signal.h> typedef void(*func)(int); func signal(int sig, func f); void ouch(int sig) { printf("OUCH! - I got signal %d\n", sig); signal(SIGINT, SIG_DFL); } int main() { signal(SIGINT, ouch); // 注册信号处理函数 while(1)sleep(1); }macro 行为 SIG_IGN 忽略信号 SIG_DFL 恢复默认行为 -
更新,更健壮的信号接口:sigaction
#include <signal.h> int sigaction(int sig, const struct sigaction* act, struct sigaction* oldact); /* struct sigaction { void (*sa_handler)(int); // 信号处理函数 void (*sa_sigaction)(int, siginfo_t *, void *); sigset_t sa_mask; // 信号集,将被阻塞且不会传递给该进程 int sa_flags; void (*sa_restorer)(void); }; */struct sigaction act; act.sa_handler = ouch; sigemptyset(&act.sa_mask); act.sa_flags = 0; sigaction(SIGINT, &act, NULL);
信号集
#include <signal.h>
int sigaddset(sigset_t* set, int signo);
int sigemptyset(sigset_t* set);
int sigfillset(sigset_t* set);
int sigdelset(sigset_t* set, int signo);
// signo是否在集合中。是:1; 否:0;给定信号无效:-1,并设置errno为EINVAL。
int sigismember(sigset_t* set, int signo);
// 进程的信号屏蔽字的设置或检查
/*
how: -SIG_BLOCK:把set中的信号添加到信号屏蔽字中
-SIG_SETMASK:把信号屏蔽字设置为参数set中的信号
-SIG_UNBLOCK:从信号屏蔽字中删除set中的信号
*/
int sigprocmask(int how, const sigset_t* set, sigset_t* oset);
// 将被阻塞的信号中停留在待处理状态的一组信号写到参数set指向的信号集中。
int sigpending(sigset_t* set);
// 使得进程挂起自己的执行,直到信号集中的一个信号到达为止
int sigsuspend(const sigset_t* sigmask);
- sigaction标志
| macro | description |
|---|---|
| SA_NOCLDSTOP | 子进程停止时不产生SIGCHLD信号 |
| SA_RESETHAND | 将对此信号的处理方式在信号处理函数的入口处重置为SIG_DFL |
| SA_RESTART | 重启可中断的函数而不是给出EINTR错误 |
| SA_NODEFER | 捕获到信号时不讲它添加到信号屏蔽字中 即,在执行信号处理函数时依然可以捕获信号 |
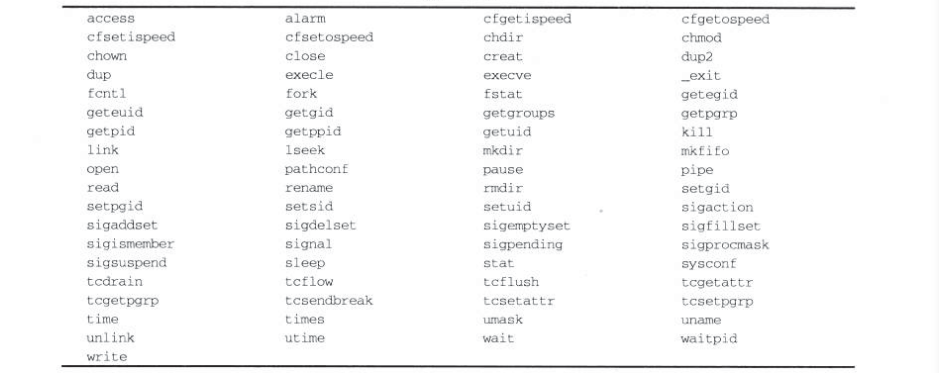
信号处理函数可以在其执行期间被中断并再次被调用。当返回到第一次调用时,它能否继续正确操作是很关键的。这不仅仅是递归(调用自身)的问题,而是可重入(可以安全地进入和再次执行)的问题。在信号处理函数中可以使用的可重入系统调用:
多线程下的信号处理
signal(SIGINT, ouch);
struct sigaction act;
act.sa_flags = 0;
sigemptyset(&act.sa_mask);
act.sa_handler = ouch;
sigaction(SIGINT, &act, nullptr);
此时上面两种信号处理方式是等价的
系统会随机选择一个线程处理信号,将捕获的信号添加入线程的屏蔽信号集合中,当该线程在进入ouch函数中时默认会屏蔽正在处理的信号
假设某个进程有两个线程,当向该进程发送连续的SIGINT信号时,第1个SIGINT会被捕获并让某个线程处理(然后该线程在处理过程中屏蔽该信号),第2个SIGINT会被其它线程捕获并处理(然后该线程在处理过程中屏蔽该信号),
第3个SIGINT由于没有多余的线程处理,所以它处于pending的状态(当有线程调用完ouch后会处理这个信号),实验证明后续的信号会被忽略掉(就像从来没过一样)
signal不能对信号处理进行更多控制,sigaction则对信号处理有更高的灵活性. 线程进入ouch中对信号的屏蔽是线程级别的,如果有其它线程没有屏蔽发来的信号还是会让其他线程处理.
通过sigfillset(&act.sa_mask)函数让信号处理线程屏蔽所有的可屏蔽信号,而signal函数则只能让信号处理线程屏蔽一个sig信号
多线程与信号处理
该线程屏蔽集合中的信号. A new thread inherits a copy of its creator’s signal mask.
pthread_sigmask(SIG_BLOCK, &set, NULL);
发送信号
想要发送一个信号,发送进程 必须拥有相应的权限。这通常意味着两个进程必须拥有相同的用户ID
unsigned int alarm(unsigned int seconds);

子进程给父进程发送SIGALARM信号
#include <sys/types.h>
#include <signal.h>
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
static int alarm_fired = 0;
void sigchild(int sig)
{
printf("sigchild\n");
}
void ding(int sig)
{
alarm_fired = 1;
}
int main()
{
pid_t pid;
printf("alarm application starting\n");
pid = fork();
switch (pid)
{
case -1:
perror("fork");
exit(EXIT_FAILURE);
break;
case 0:
// sleep(1);
pid = getppid();
// kill(pid, SIGCHLD);
sleep(5);
kill(pid, SIGALRM);
exit(EXIT_SUCCESS);
break;
}
printf("waiting for alarm to go off\n");
signal(SIGCHLD, sigchild);
signal(SIGALRM, ding);
pause();
if (alarm_fired)
printf("Ding!\n");
else
printf("not ding\n");
printf("done\n");
exit(0);
}
闹钟模拟程序通过fork调用启动新的进程。这个子进程休眠5秒后向其父进程发送一个SIGALRM信号。父进程在安排好捕获SIGALRM信号后暂停运行,直到接收到一个信号为止。此程序并未在信号处理函数中直接调用printf,而是通过在该函数中设置标志,然后在main函数中检查该标志来完成消息的输出。
使用信号并挂起程序的执行是Linux程序设计中的一个重要部分。这意味着程序不需要总是在执行着。程序不必在一个循环中无休止地检查某个事件是否已发生,相反,它可以等待事件的发生。这在只有一个CPU的多用户环境中尤其重要,进程共享着一个处理器,繁忙的等待将会对系统的性能造成极大的影响。程序中信号的使用将带来一个特殊的问题:“如果信号出现在系统调用的执行过程中会发生什么情况?”答:“视情况而定”。一般来说,你只需要考虑慢系统调用,如从终端读数据,如果在这个系统调用等待数据时出现一个信号,它就会返回一个错误。如果在程序中使用信号,需要注意一些系统调用会因为接收到了一个信号而失败,而这种错误情况可能是你在添加信号处理函数之前没有考虑到的。
在编写程序中处理信号部分的代码时必须非常小心,因为在使用信号的程序中会出现各种各样的“竞态条件”。如,如果想调用pause等待一个信号,可信号却出现在pause之前,就会使程序无限期的等待一个不会发生的事情。这些竞态条件都是一些对时间要求很苛刻的问题。所以在检查和信号相关的代码时总是要非常小心。
利用信号“goto”到之前的位置
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <setjmp.h>
#include <unistd.h>
sigjmp_buf env;
void signal_handler(int sig) {
printf("Caught signal %d\n", sig);
siglongjmp(env, 1); // 执行该函数相当于goto到sigsetjmp
// 相比goto可夸函数,所以还是非常危险的!!!
}
int main() {
int t = 0;
if (sigsetjmp(env, 1) == 0) {
// 初次调用 sigsetjmp 时执行这里
printf("Setting up signal handler...\n");
signal(SIGINT, signal_handler); // 注册信号处理程序
} else {
// 从 siglongjmp 返回时执行这里
printf("Returned from signal handler\n");
++t;
if (t > 10)
exit(0);
}
while (1) {
printf("Running...%d\n", t);
sleep(1);
}
return 0;
}
防止长时间阻塞操作
static void
hungtty(int i GCC_UNUSED)
{
siglongjmp(env, 1);
}
// --------------------------------------------------------
signal(SIGALRM, hungtty);
alarm(2); /* alarm(1) might return too soon */
if (!sigsetjmp(env, 1)) {
ttyfd = open("/dev/tty", O_RDWR);
alarm(0);
tty_got_hung = False;
} else {
tty_got_hung = True;
ttyfd = -1;
errno = ENXIO;
}
十二、POSIX线程
- 在进程中创建一个线程
- 在一个进程中同步线程之间的数据访问
- 修改线程的属性
- 在同一个进程中,从一个线程中控制另一个线程
线程创建
#include <pthread.h>
// 创建线程
int pthread_create(pthread_t* thid, pthread_attr_t* attr, void *(*start_routine)(void*), void* arg);
// 终止线程
void pthread_exit(void *retval);
// join or detach
int pthread_join(pthread_t thid, void **thread_retval);
int pthread_detach (pthread_t __th);
线程同步
#include <semaphore.h>
int sem_init(sem_t *sem, int pshared, unsigned int value);
int sem_wait(sem_t *sem); // 当sem为0时则无法-1而阻塞
int sem_post(sem_t *sem); // +1无上限
int sem_destroy(sem_t *sem); // 销毁信号量
#include <pthread.h>
// pthread_mutex_init(&mutex, NULL);
int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t *mutexattr);
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);
int pthread_mutex_destroy(pthread_mutex_t *mutex);
线程属性
#include <pthread.h>
int pthread_attr_init(pthread_attr_t *attr);
int pthread_attr_destroy (pthread_attr_t *__attr);
/*
* detachstate: PTHREAD_CREATE_JOINABLE/PTHREAD_CREATE_DETACHED
*/
int pthread_attr_setdetachstate(pthread_attr_t *attr, int detachstate);
int pthread_attr_getdetachstate(const pthread_attr_t *attr, int *detachstate);
/*
* schedpolicy:控制线程的调度方式。它的取值可以是SCHED_OTHER(默认)\SCHED_RP\SCHED_FIFO,
* 其他两种方式只能用于超级用户
*/
int pthread_attr_setschedpolicy(pthread_attr_t *attr, int policy);
int pthread_attr_getschedpolicy(const pthread_attr_t *attr, int *policy);
/*
* 与schedpolicy结合使用,它可以对SCHED_OTHER策略运行的线程的调度进行控制
*/
int pthread_attr_setschedparam(pthread_attr_t *attr, const struct sched_param *param);
int pthread_attr_getschedparam(const pthread_attr_t *attr, struct sched_param *param);
/*
* PTHREAD_EXPLICIT_SCHED(default, 调度由属性明确设置)/PTHREAD_INHERIT_SCHED(继承创建者的属性)
*/
int pthread_attr_setinheritsched(pthread_attr_t *attr, int inherit);
int pthread_attr_getinheritsched(const pthread_attr_t *attr, int *inherit);
/*
* 控制线程调度的计算方式,取值:PTHREAD_SCOPE_SYSTEM
*/
int pthread_attr_setscope(pthread_attr_t *attr, int scope);
int pthread_attr_getscope(const pthread_attr_t *attr, int *scope);
/*
* 控制栈大小
*/
int pthread_attr_setstacksize(pthread_attr_t *attr, int stacksize);
int pthread_attr_getstacksize(const pthread_attr_t *attr, int *stacksize);
通过线程属性设置线程分离
// ignore header
int thread_finished = 0;
void* thread_function(void* arg)
{
printf("thread_function is running. Argument was %s\n", (char*)arg);
sleep(4);
printf("Second thread setting finished flag, and exiting now\n");
thread_finished = 1;
pthread_exit(NULL); // 这里等价于return NULL;
}
int main()
{
int res;
pthread_t a_thread;
pthread_attr_t thread_attr;
int max_priority, min_priority;
struct sched_param scheduling_value;
// init thread_attr
res = pthread_attr_init(&thread_attr);
if (res != 0)
{
perror("Attribute creation failed");
exit(EXIT_FAILURE);
}
// 设置线程分离
res = pthread_attr_setdetachstate(&thread_attr, PTHREAD_CREATE_DETACHED);
if (res != 0)
{
perror("Setting detached attribute failed");
pthread_attr_destroy(&thread_attr);
exit(EXIT_FAILURE);
}
// 设置调度策略
res = pthread_attr_setschedpolicy(&thread_attr, SCHED_OTHER);
if (res != 0)
{
perror("Setting scheduling policy failed");
pthread_attr_destroy(&thread_attr);
exit(EXIT_FAILURE);
}
// 查看优先级策略
max_priority = sched_get_priority_max(SCHED_OTHER);
min_priority = sched_get_priority_min(SCHED_OTHER);
// 设置优先级
scheduling_value.sched_priority = min_priority;
res = pthread_attr_setschedparam(&thread_attr, &scheduling_value);
if (res != 0)
{
perror("Setting scheduling priority failed");
pthread_attr_destroy(&thread_attr);
exit(EXIT_FAILURE);
}
// 创建线程
res = pthread_create(&a_thread, &thread_attr, thread_function, (void*)"Hello");
if (res != 0)
{
perror("Thread creation failed");
pthread_attr_destroy(&thread_attr);
exit(EXIT_FAILURE);
}
// 函数完成后,线程已经被创建,并且线程的属性已经被传递给了新创建的线程。因此,可以安全地销毁线程属性对象。
pthread_attr_destroy(&thread_attr);
while (!thread_finished)
{
printf("Waiting for thread to say it's finished...\n");
sleep(1);
}
printf("Other thread finished, bye!\n");
exit(EXIT_SUCCESS);
}
取消一个线程
让一个线程令另一个线程终止。
#include <pthread.h>
// 请求另一个线程终止
int pthread_cancel(pthread_t thread);
// 第一层控制是否接收请求 PTHREAD_CANCEL_ENABLE(默认状态)/PTHREAD_CANCEL_DISABLE
int pthread_setcancelstate(int state, int *oldstate);
// 第二层控制,PTHREAD_CANCEL_ASYNCHRONOUS(立即行动)/PTHREAD_CANCEL_DEFERRED(执行到取消点处,默认状态)
// 取消点:pthread_join, pthread_cond_wait, pthread_cond_timedwait, pthread_testcancel, sem_wait, sigwait
// 某些阻塞函数也可能是潜在的取消点
int pthread_setcanceltype(int type, int *oldtype);
pthread_exit, exit, _exit
- exit函数:
- 头文件: #include <stdlib.h>
- exit函数是C标准库函数,用于正常终止程序的执行。
- 在调用exit时,会执行程序中注册的所有终止处理程序(通过atexit函数注册的函数)。
- exit函数会关闭所有已打开的流(文件流、标准输入、标准输出等)。
- _exit函数:
- 头文件: #include <unistd.h>
- _exit是系统调用,用于立即终止进程,不执行任何清理操作,也不会调用终止处理程序。
- 不会关闭已打开的文件描述符,因此需要手动关闭。
- pthread_exit函数:
- 头文件: #include <pthread.h>
- pthread_exit用于终止调用它的线程。
- 不同于exit和_exit,pthread_exit只终止调用它的线程,而不会终止整个进程。
- 可以向pthread_exit传递一个指针,这个指针会成为线程的退出状态,其他线程可以通过pthread_join来获取。
十三、管道
popen, pipe
通过管道与命令行进行交互,system只能调用命令而不能与其通讯,popen通过管道与调用的命令进行数据传递
#include <stdio.h>
FILE* popen(const char* command, const char* open_mode);
int pclose(FILE* stream_to_close);
#include <unistd.h>
// 1写入,0读取
// 管道内有缓存区
int pipe(int file_descriptor[2]);
父子进程
在子进程中运行一个与其父进程完全不同的另外一个程序,而不仅仅运行一个相同程序,通过exec调用完成该工作。这里的一个难点是,通过exec调用的进程需要知道应该访问哪个文件描述符。如果子进程本身有file_pipes数据的一份副本,所以不成问题。但经过exec调用后,原先的进程被新的替换了。为了解决该问题,可以将文件描述符作为一个参数传递给用exec启动的程序。
当管道的写端被关闭时,read将返回0,而不是阻塞。read无效文件会返回-1。
只有把父子进程中针对管道的写fd都关闭,管道才会被认为是关闭。
注:
fork会复制调用进程,包括文件描述符的指向,即父进程的文件描述符指向一个操作系统对象,则子进程的描述符与父进程相同。
在调用exec函数族时,管道(pipe)通常不会被自动关闭。因此在之后的进程中文件描述符依然可用。
在调用exec后文件描述符是否可用取决于该文件描述符的状态,若通过fcntl函数将fd设置为了FD_CLOEXEC,则新程序关闭该描述符。
当进程退出后大部分操作系统对象都会被关闭,但有一些资源除外。
将管道用作标准输入和标准输出
命名管道:FIFO
# Ubuntu实测权限不会受到umask影响
mkfifo [-m mode] filename
#include <sys/types.h>
#include <sys/stat.h>
// Ubuntu实测权限会受到umask影响
int mkfifo(const char* filename, mode_t mode);
- 使用open打开FIFO文件
如果没有进程以读方式打开管道,非阻塞写方式的open调用将失败,但非阻塞读open总是成功open(const char* path, O_RDONLY); open(const char* path, O_RDONLY | O_NONBLOCK); open(const char* path, O_WRONLY); open(const char* path, O_WRONLY | O_NONBLOCK);
十四、IPC通讯
信号量
semaphore.h 和 sys/sem.h 都是在C语言中用于处理信号量的头文件,但它们在功能上有一些区别。
-
semaphore.h:- 标准库头文件:
semaphore.h是POSIX标准库的一部分,定义了一组函数和宏,用于操作和管理信号量。 - 跨平台性: 由于它是POSIX标准的一部分,因此具有较好的跨平台性。可以在不同的Unix-like系统(如Linux)上使用。
- 标准库头文件:
-
sys/sem.h:- 系统头文件:
sys/sem.h是特定于Linux系统的头文件,用于在Linux中进行信号量操作。 - 较低级别的API: 与
semaphore.h不同,sys/sem.h提供了更底层的信号量API。它使用semget、semop等系统调用来创建和操作信号量。
- 系统头文件:
总的来说,如果你的目标是编写跨平台的代码,最好使用 semaphore.h。如果你在Linux平台上编写代码,需要更底层的控制,可能会选择使用 sys/sem.h。然而,考虑到 sys/sem.h 是Linux特定的,使用它可能使你的代码在其他Unix-like系统上不可移植。
| 操作 | 说明 |
|---|---|
| P(sv) | 如果sv的值大于零,就给它减去1;如果它的值等于零,就挂起该进程的执行 |
| V(sv) | 如果有其它进程因等待sv而被挂起,就它恢复运行;如果没有进程等待sv,就给他加1 |
#include <sys/sem.h>
//
int semctl(int sem_id, int sem_num, int command, ...);
// 创建一个新信号量或取的一个已有信号量
int setmget(key_t key, int num_sems, int semflags);
//
int semop(int sem_id, struct sembuf *sem_ops, size_t num_sem_ops);
共享内存
#include <sys/shm.h>
// 将共享内存连接到进程地址空间
void* shmat(int shm_id, const void* shm_addr, int shmflg);
// 控制共享内存
int shmctl(int shm_id, int cmd, struct shmid_ds *buf);
// 将共享内存从当前地址空间中分离
int shmdt(const void* shm_addr);
// 返回shm_id, 传入key,大小和权限
int shmget(key_t key, size_t size, int shmflg);
消息队列

#include <sys/msg.h>
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
// 创建消息队列
int msgget(key_t key, int msgflg);
// 接收消息
int msgrcv(int msqid, void *msg_ptr, size_t msg_sz, long int msgtype, int msgflg);
- msgtype: 如果只想按照消息发送的顺序接收则将其设为0,如果只想获取某一特定类型的消息就将其设为相应类型,如果想接收类型等于或小于n的消息,就将其设为-n
- msgflg: 用于设置当队列中没有相应类型的消息可以接收时将发生的事情
// 把消息添加进消息队列中
int msgsnd(int msqid, const void *msg_ptr, size_t msg_sz, int msgflg);
- msg_ptr: 最好定义成以下形式 struct my_message{long int message_type; /*data*/};
- msg_sz: data部分的长度
- msgflg: 控制在当前消息队列满或超限时的行为
IPC状态命令
ipcs
十八、Linux标准
LSB标准
LSB系统初始化
Linux系统运行级别:
| 运行级别 | description |
|---|---|
| 0 | 停止。用作一种可以在系统关闭时切换到的逻辑状态 |
| 1 | 单用户模式。非目录的其他目录可能不会在这种模式下被装载,网络功能也将被禁用。该模式通常用于系统维护 |
| 2 | 多用户模式,但未启用网络功能 |
| 3 | 正常的带网络功能的多用户模式,使用文本模式的登录界面 |
| 4 | 保留 |
| 5 | 正常的带网络功能的多用户模式,使用图形登录界面 |
| 6 | 用于重启系统的伪运行级别 |
与运行级别相伴的一组用于启动、关闭和重启服务的初始化脚本位置:/etc/init.d/
用于控制初始化脚本行为的控制参数:
| 参数 | description |
|---|---|
| start | 启动(或重启)服务 |
| stop | 停止服务 |
| restart | 重启服务 ,它一般是通过先停止服务再重启服务的方式来实现的 |
| reload | 重置服务,在不停止服务的情况下重新装载所有的参数。 |
| force-reload | 如果服务支持这个选项,就重载服务,否则,就重启服务 |
| status | 以文本方式打印服务的状态信息,并返回一个可以用来确定服务状态的状态码 |
文件系统层次结构标准
Filesystem Hierarchy Standard
https://www.pathname.com/fhs/
- 对运行Linux的某一特定系统唯一的文件和目录,如启动脚本和配置文件
- 可以运行在Linux的不同系统之间共享的只读文件和目录,如可执行应用程序
- 可以在运行Linux或其他操作系统的不同系统之间共享的可读可写目录,如用户家目录
| 目录 | 是否需要 | 用户 |
|---|---|---|
| /bin | Y | 重要的系统二进制文件 |
| /boot | Y | 启动系统所需要的文件 |
| /dev | Y | 设备文件 |
| /etc | Y | 系统配置文件 |
| /lib | Y | 标准函数库 |
| /media | Y | 用于装载可移动媒体的位置 |
| /mnt | Y | 方便临时装载如CD-ROM和内存棒等设备的目录 |
| /opt | Y | 其他应用程序软件 |
| /sbin | Y | 在系统启动时需要的重要的系统二进制文件 |
| /srv | Y | 用于系统提供的服务的只读数据 |
| /tmp | Y | 临时文件 |
| /usr | Y | |
| /var | Y | 可变数据,如日志文件 |
–
GNU 构建系统
Autoconf解决了系统特使构建和运行时信息的难题,但在软件开发时还有更多的难题,GNU构建系统是为了更好的开发软件而开发的一套完整的公益事业。
主要组成部分有Autoconf、Automake和Libtool。

















 1111
1111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









