




好记忆不如烂笔头,能记下点东西,就记下点,有时间拿出来看看,也会发觉不一样的感受.
目录
Phoenix是构建在HBase上的一个SQL层,能让我们用标准的JDBC APIs对HBase数据进行增删改查,构建二级索引。当然,开源产品嘛,自然需要注意“避坑”啦,阿丸会把使用方式和最佳实践都告诉你。
1.什么是Phoenix

Phoenix完全使用Java编写,将SQL查询转换为一个或多个HBase扫描,并编排执行以生成标准的JDBC结果集。Phoenix主要能做以下这些事情:
- 将SQL查询编译为HBase扫描scan
- 确定scan的开始和停止位置
- 将scan并行执行
- 将where子句中的谓词推送到服务器端进行过滤
- 通过服务器端挂钩(称为协处理器co-processors)执行聚合查询
除了这些之外,phoenix还进行了一些有趣的增强,以进一步优化性能:
- 二级索引,以提高非行键查询的性能(这也是我们引入phoenix的主要原因)
- 跳过扫描过滤器来优化IN,LIKE和OR查询
- 可选的对行键进行加盐以实现负载均衡,避免热点
2.Phoniex架构
Phoenix结构上划分为客户端和服务端两部分:
- 客户端包括应用程序开发,将SQL进行解析优化生成QueryPlan,进而转化为HBase Scans,调用HBase API下发查询计算请求,并接收返回结果;
- 服务端主要是利用HBase的协处理器,处理二级索引、聚合及JOIN计算等。
Phoiex的旧版架构采用重客户端的模式,在客户端执行一系列的parser、query plan的过程,如下图所示。
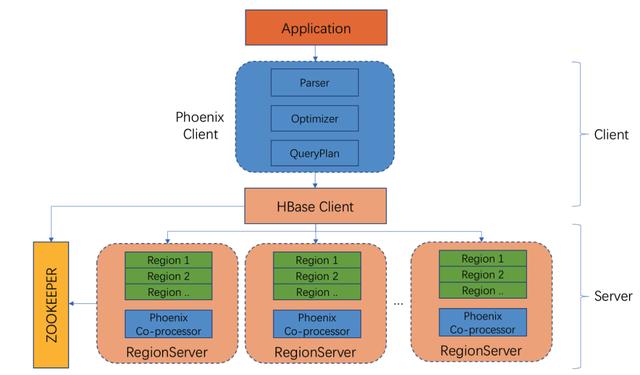
这种架构存在使用上的缺陷:
- 应用程序与Phoenix core绑定使用,需要引入Phoenix内核依赖,一个单独Phoenix重客户端集成包已达120多M;
- 运维不便,Phoenix仍在不断优化和发展,一旦Phoenix版本更新,那么应用程序也需要对应升级版本并重新发布;
- 仅支持Java API,其他语言开发者不能使用Phoenix。
因此,社区进行改造,引入了新的“轻客户端”模式。
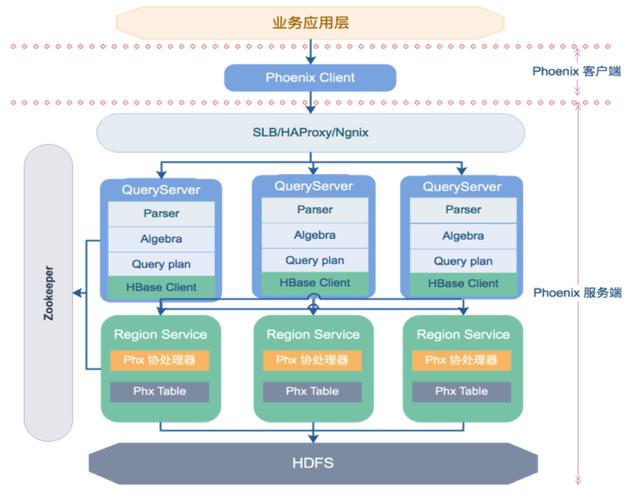
轻客户端架构将Phoenix分为两部分:
- 客户端是用户最小依赖的JDBC驱动程序,与Phoenix依赖进行解耦,支持Java、Python、Go等多种语言客户端;
- 将QueryServer部署为一个独立的的HTTP服务,接收轻客户端的请求,对SQL进行解析、优化、产生执行计划;
3.基本使用
传送门:https://phoenix.apache.org/language/index.html(平时多参考官方的语法)
3.1 建表
在phoenix shell上建的表默认只有一个region,建表时要注意预分区
// step1 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1685
1685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









