




 本文详细介绍在Windows环境下搭建Spark应用程序的开发环境,包括配置JDK、SuperMapiObjectsforSpark、IDEA等,并介绍如何使用SuperMapiObjectsforSpark进行GIS数据处理的入门程序开发。
本文详细介绍在Windows环境下搭建Spark应用程序的开发环境,包括配置JDK、SuperMapiObjectsforSpark、IDEA等,并介绍如何使用SuperMapiObjectsforSpark进行GIS数据处理的入门程序开发。
作者: Neshoir
SuperMap iObjects for Spark是超图空间大数据GIS组件包,是基于Spark大数据技术基础之上,将GIS技术及其能力与大数据技术进行深度融合,作为连接大数据与GIS行业应用的中间桥梁。该GIS组件包提供了丰富的分布式空间GIS分析功能的SDK,便于开发者开发业务系统 。本文主要介绍在Windows下开发spark应用程序的依赖环境的搭建,其次也会针对supermap iobjects for spark产品的入门程序开发介绍。
一、环境准备
- Windows 10 64位系统
- jdk-8u181-windows-x64.exe
- SuperMap iObjects Java 9D(2019) SP2 for Windows(64位)(Bin包)
- SuperMap iObjects Java 9D(2019) SP2 for Spark
- spark-2.1.1-bin-hadoop2.7.rar,hadoop-2.7.3.rar,ideaIU-2017.3.3.exe
- scala 2.11.8
二、软件配置
-
配置JDK,下载,安装。将JDK目录配置到系统环境变量JAVA_HOME及PATH。
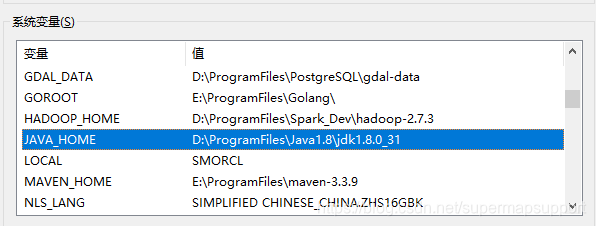
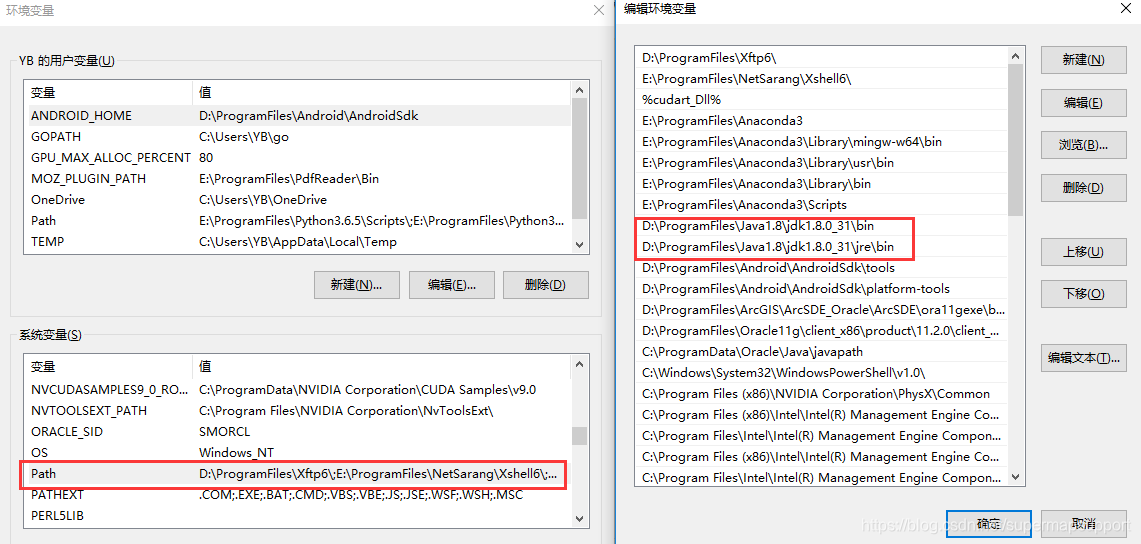
-
验证jdk是否正确配置,用java -version命令
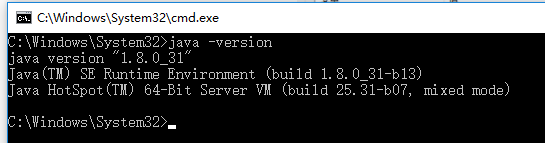
-
配置supermap java组件,下载,解压,将其bin目录添加到系统环境变量中。
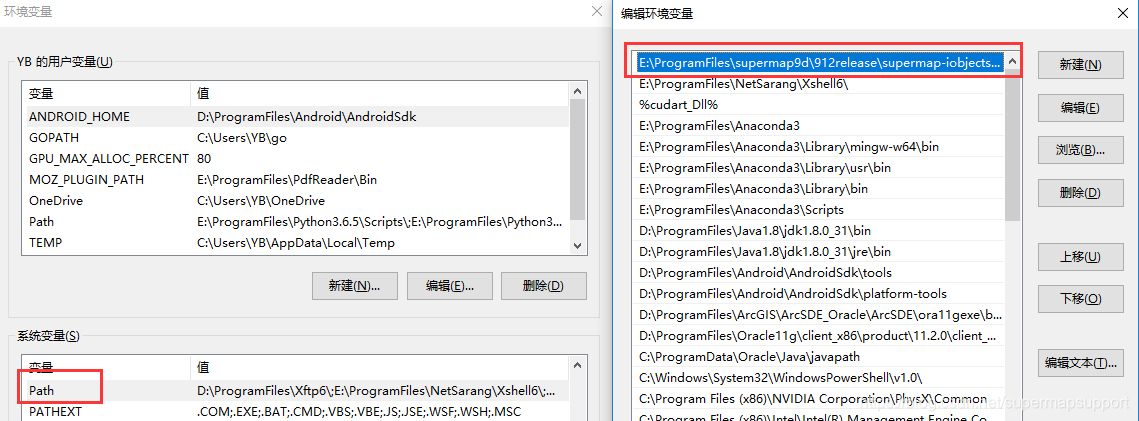
-
配置超图产品试用许可,根据机器名称,申请许可 ,将许可文件拷贝到C:\Program Files\Common Files\SuperMap\License目录,用命令java -jar com.supermap.license.jar -s验证许可是否有效。

-
配置spark组件,下载,解压。配置SPARK_HOME,PATH环境变量并赋值。
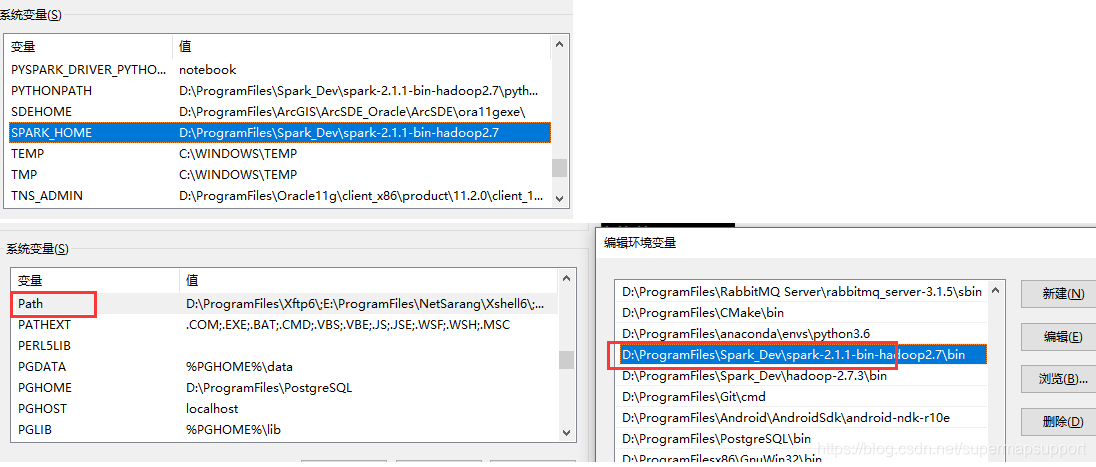
-
配置hadoop组件,下载,解压。配置HADOOP_HOME,PATH环境变量并赋值。
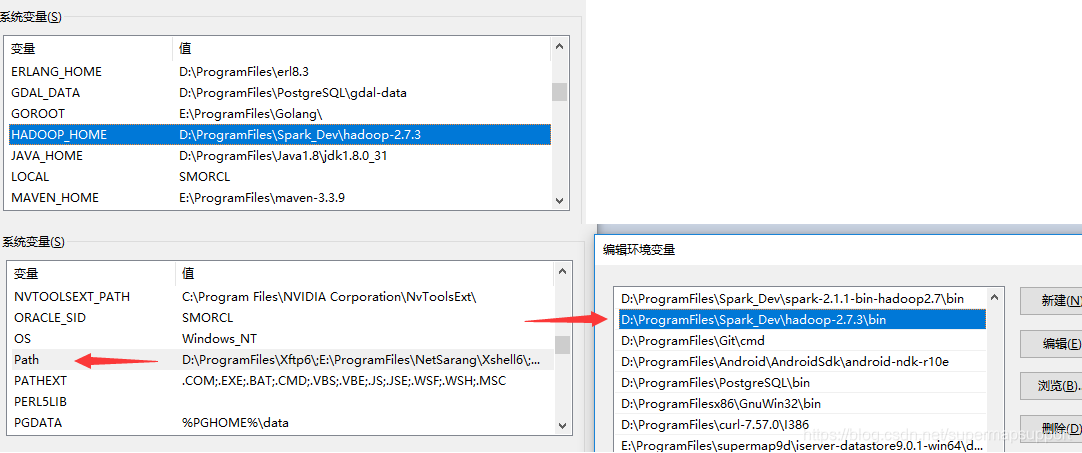
-
配置hadoop组件的hadoop-env.cmd文件(添加jdk路径),hdfs-site.xml文件(配置节点目录,需预先创建)。
set JAVA_HOME=D:\ProgramFiles\Java1.8\jdk1.8.0_31<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permission</name> <value>false</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/D:/ProgramFiles/Spark_Dev/hadoop-2.7.3/data/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/D:/ProgramFiles/Spark_Dev/hadoop-2.7.3/data/datanode</value> </property> </configuration> -
安装idealIU开发工具,在插件管理plugins里安装scala插件。
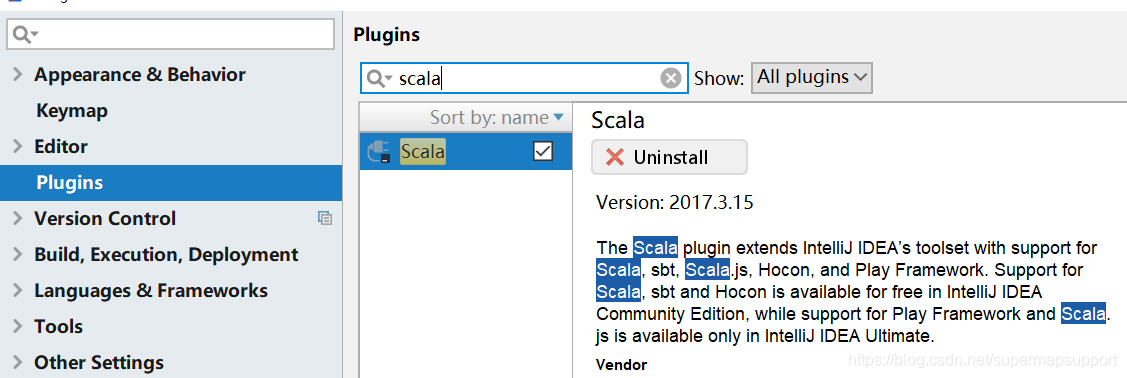
-
安装scala,配置环境变量PATH,验证scala版本;

三、启动spark和hadoop
- 启动spark,打开cmd,进入spark的bin目录,执行
spark-shell.cmd
- 启动hadoop,打开cmd,进入hadoop的sbin目录,执行
start-all.cmd
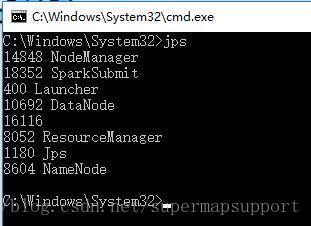
- 检测启动情况,是否能打开管理页面http://localhost:4040/jobs/和http://localhost:8088/cluster/cluster,或者打开cmd,执行jps命令查看是否有如下节点,如截图三
四、supermap iobjects for spark入门程序
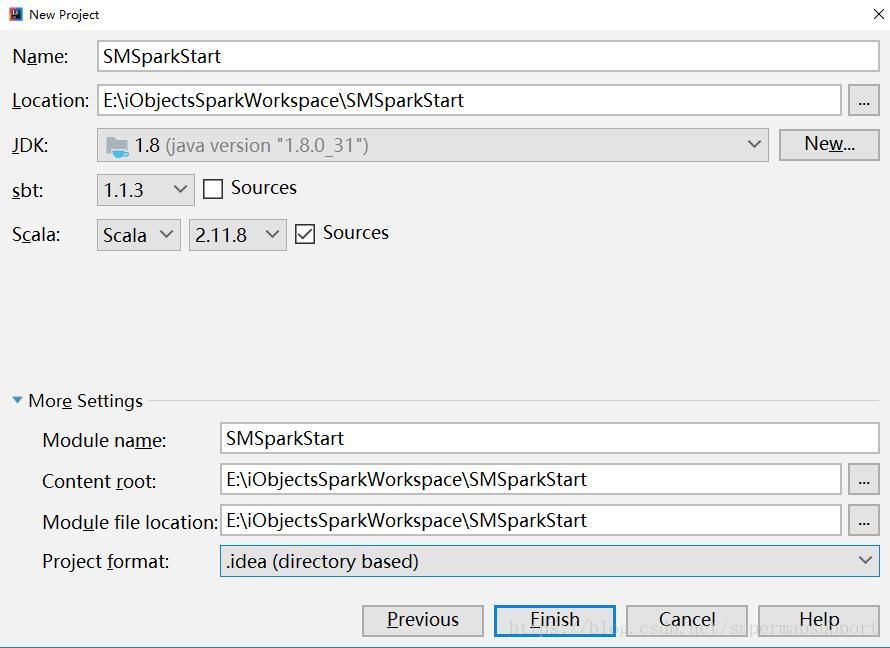
- 新建project,选择scala项目,选择sbt构建方式,选择scala2.11.8版本(如果没有,可在project settings里点击"+",选择scala sdk,可在线下载2.11.8版本),保持与spark内部使用的scala版本一致,如截图四
- F12打开open library setting配置界面,在libraries节点处,添加spark的jars,以及iobjects for spark的jar包,应用即可。
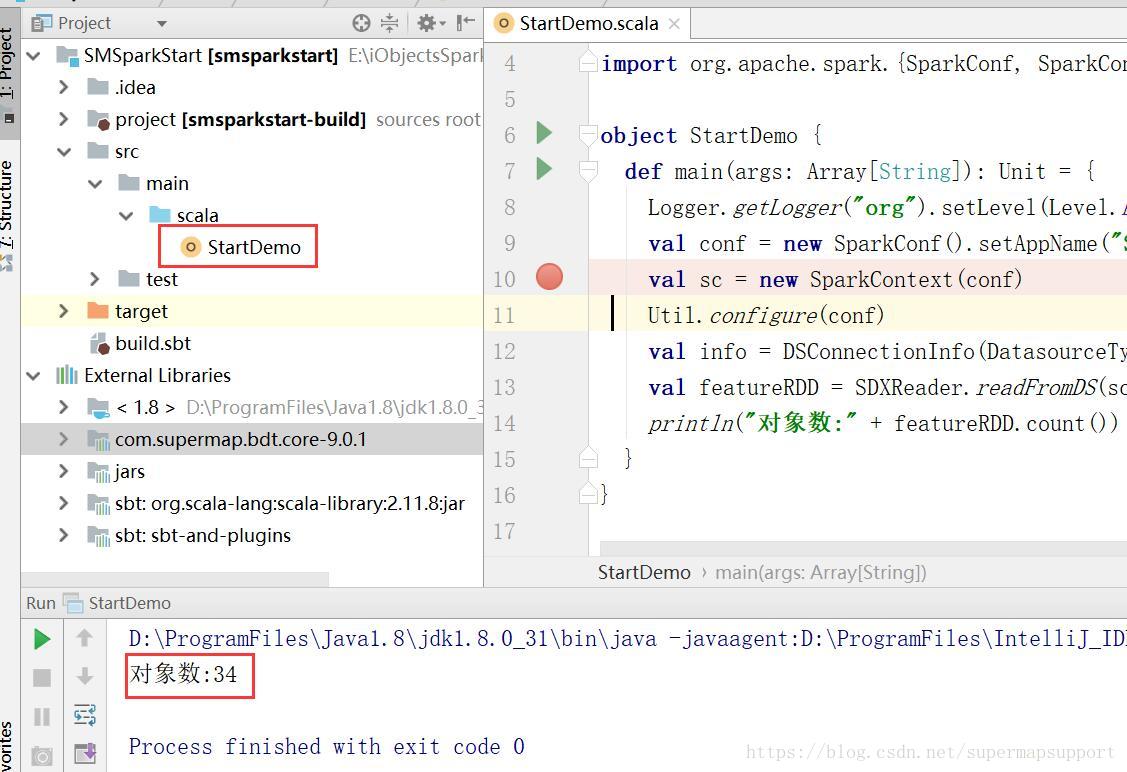
- 创建一个scala单例文件进行编码,本示例代码读取postgresql下的数据集,当然也可以读写hdfs上的数据。如截图五
import com.supermap.bdt.base.Util
import com.supermap.bdt.io.sdx.{DSConnectionInfo, DatasourceType, SDXReader}
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkConf, SparkContext}
object StartDemo {
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.ERROR)
// 也可以远程连接spark集群
val conf = new SparkConf().setAppName("StartDemo").setMaster("local[*]")
val sc = new SparkContext(conf)
Util.configure(conf)
val info = DSConnectionInfo(DatasourceType.PostgreSQL, "127.0.0.1:5432", "mapdata", "postgresql", Some("maptest"), Some("supermap"))
val featureRDD = SDXReader.readFromDS(sc, info, "province", 360)
println("对象数:" + featureRDD.count())
}
}
五、spark批处理模式运行程序
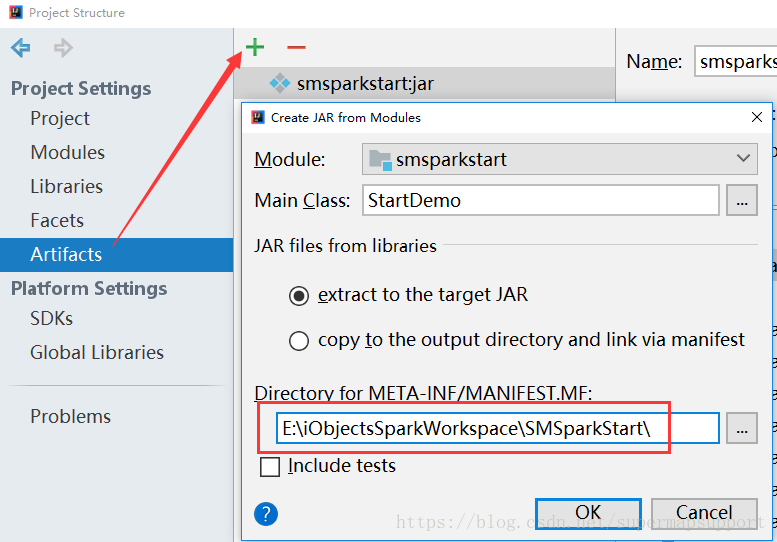
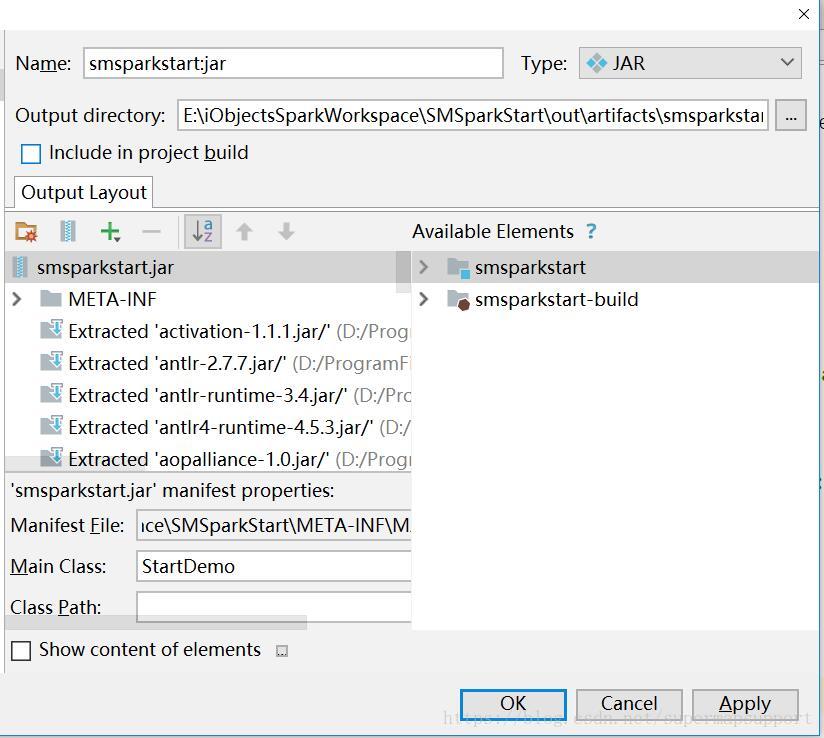
- artifacts方式打包jar,设置主函数文件以及签名文件,然后应用即可,如截图六七。注:本例默认将第三方包也打入jar,如不需要,请参考artifacts的使用。
- build已配置的jar,工具栏"Build"-“Build Artifact”-“Build”,即可在上一步里配置的output dictionary目录下生成对应的jar包。
- cmd里提交spark程序,该jar包也可以在Linux生产环境下使用。
spark-submit.cmd --master local[4] --class StartDemo E:\\iObjectsSparkWorkspace\\SMSparkStart\\out\\artifacts\\smsparkstart_jar\\smsparkstart.jar

如果提交时报错"invalid signature file digest for manifest main attributes"签名无效,这是因为sbt或maven构建的工程在打包时都有这个常见错误,Windows下用压缩工具打开jar,删除meta-inf文件夹下的* .SF,* .DSA,* .RSA文件即可,Linux下采用命令删除即可。
zip -d smsparkstart.jar META-INF/*.RSA META-INF/*.DSA META-INF/*.SF
注:本博文提供的spark包和hadoop包已经做了适配于Windows开发的相关文件修改。spark本身具备交互式命令行工具,所以也可以在spark-shell中进行简单的空间数据处理和分析代码的编写。

















 2392
2392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









