




 本文介绍了Kafka如何使用时间轮算法实现延时操作,对比了JDK的Timer和DelayQueue,以及ScheduledThreadPoolExecutor。Kafka的时间轮是O(1)复杂度的高效实现,支持大跨度定时任务,并通过DelayQueue避免空推进导致的性能损耗。文章还讨论了多层时间轮的设计和时间推进策略。
本文介绍了Kafka如何使用时间轮算法实现延时操作,对比了JDK的Timer和DelayQueue,以及ScheduledThreadPoolExecutor。Kafka的时间轮是O(1)复杂度的高效实现,支持大跨度定时任务,并通过DelayQueue避免空推进导致的性能损耗。文章还讨论了多层时间轮的设计和时间推进策略。
前言
Kafka 中有很多延时操作,比如对于耗时的网络请求(比如 Produce 是等待 ISR 副本复制成功)会被封装成 DelayOperation 进行延迟处理操作,防止阻塞 Kafka请求处理线程。
Kafka 没有使用 JDK 自带的 Timer 和 DelayQueue 实现。因为时间复杂度上这两者插入和删除操作都是 O(logn),不能满足 Kafka 的高性能要求。
冷知识:JDK Timer 和 DelayQueue 底层都是个优先队列,即采用了 minHeap 的数据结构,最快需要执行的任务排在队列第一个,不一样的是 Timer 中有个线程去拉取任务执行,DelayQueue 其实就是个容器,需要配合其他线程工作。
ScheduledThreadPoolExecutor 是 JDK 的定时任务实现的一种方式,其实也就是 DelayQueue + 池化是线程的一个实现。
Kafka 基于时间轮实现了延时操作,时间轮算法的插入删除操作都是 O(1) 的时间复杂度,满足了 Kafka 对于性能的要求。除了 Kafka 以外,像 Netty 、ZooKeepr、Dubbo 这样的开源项目都有使用到时间轮的实现。
那么时间轮回算法是怎么样的,算法思想是什么?Kafka 中又是怎么实现它的。
Kafka 时间轮算法
时间轮回的算法思想可以通过我们日常生活中的钟表来理解。
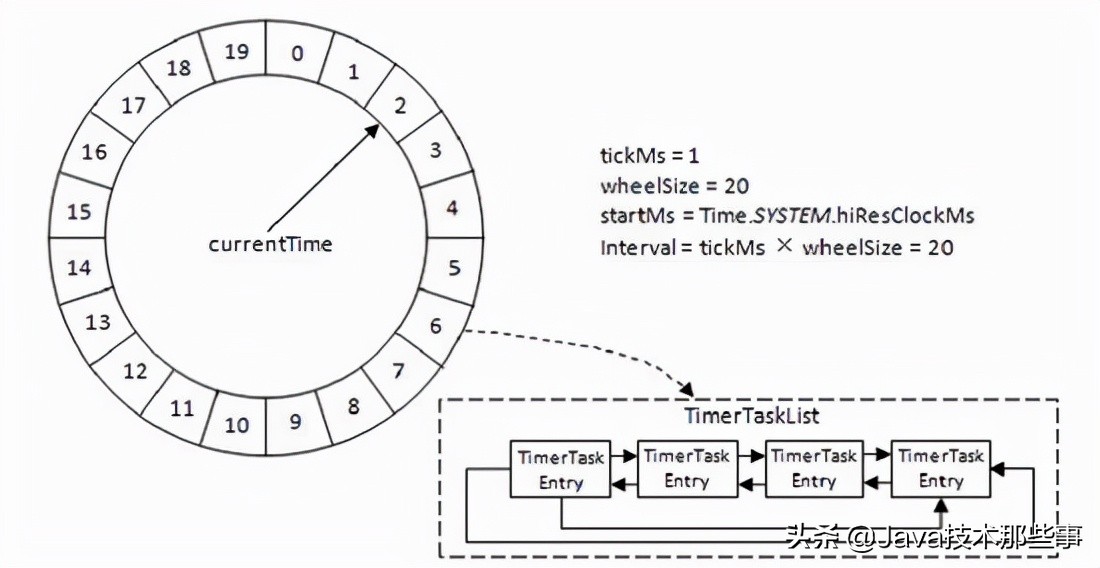
Kafka 中的时间轮(TimingWheel)是一个存储定时任务的环形队列,底层采用数组实现,数组中的每个元素可以存放一个定时任务列表(TimerTaskList)。TimerTaskList是一个环形的双向链表,链表中的每一项表示的都是定时任务项(TimerTaskEntry),其中封装了真正的定时任务(TimerTask)。
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1033
1033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









