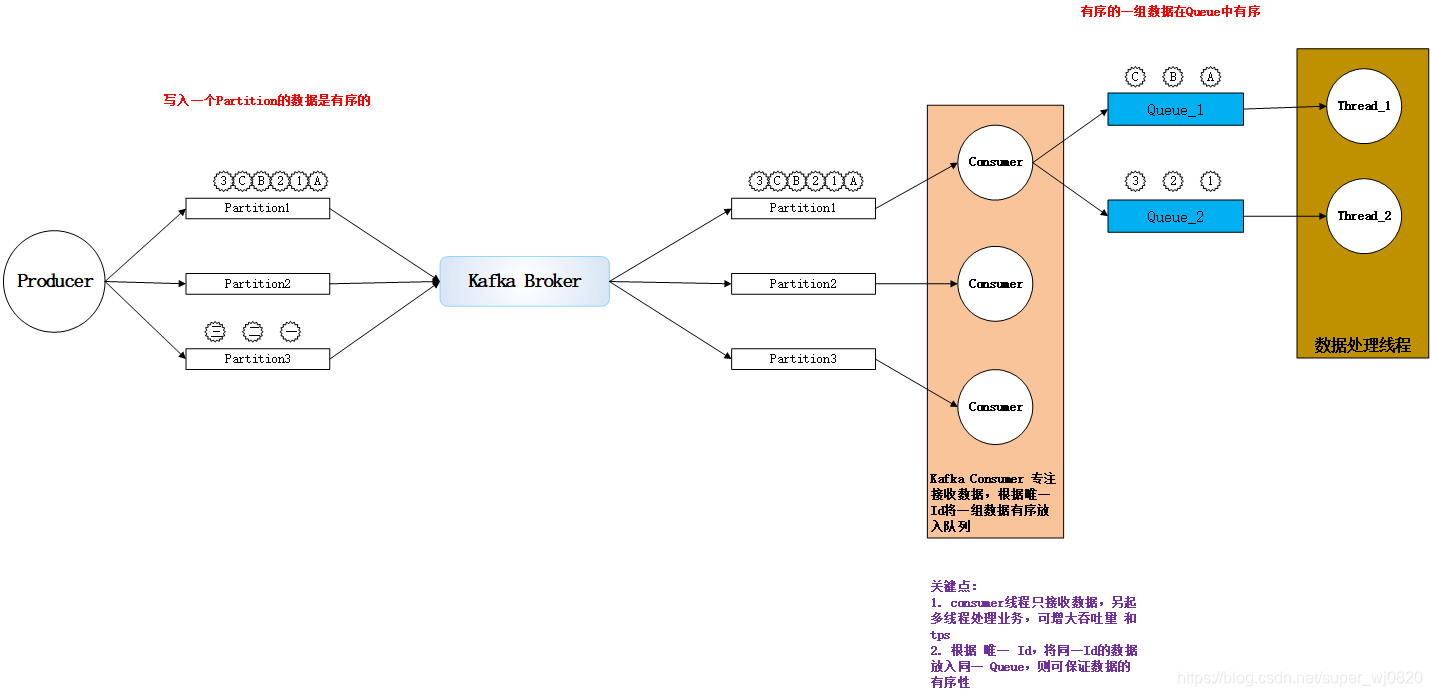
项目背景 数据交换系统,从 Kafka 中拉取数据(数据按 Id 分组,并在 同一 Partition 中有序排列),系统需要 针对 同一组数据,按序处理。(如 Mysql 的 binlog 日志) 要求尽可能做到 提高 tps 和 吞吐量 设计思路 Kafka Consumer线程 只负责接收数据,不再处理数据和业务逻辑;另起多线程处理 接收到的数据 Kafka Consumer线程 从 对应 Partition 接收消息,根据 ID 将同组数据 放到同一 队列Queue 中(如 图中的 Queue1 和 Queue2),数据处理线程 一对一 处理 Queue 中的数据





 针对Kafka中有序分组数据的高效处理方案,通过独立线程接收与处理机制,提升系统吞吐量与tps,适用于高并发场景如Mysql binlog日志处理。
针对Kafka中有序分组数据的高效处理方案,通过独立线程接收与处理机制,提升系统吞吐量与tps,适用于高并发场景如Mysql binlog日志处理。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






