




文章目录
- 1. HDFS 概念
- 2. HFDS命令行操作
-
- 2.1 基本语法
- 2.2 参数大全
- 2.3 常用命令实操
-
- 2.3.1 -help:输出这个命令参数
- 2.3.2 -ls: 显示目录信息
- 2.3.3 -mkdir: 在hdfs上创建目录
- 2.3.4 -moveFromLocal: 从本地剪切粘贴到hdfs
- 2.3.5 -moveToLocal: 从hdfs剪切粘贴到本地
- 2.3.6 --appendToFile: 追加一个文件到已经存在的文件末尾
- 2.3.7 -cat: 显示文件内容
- 2.3.8 -tail: 显示一个文件的末尾
- 2.3.9 -text:以字符形式打印一个文件的内容
- 2.3.10 -chgrp 、-chmod、-chown: linux文件系统中的用法一样,修改文件所属权限
- 2.3.11 -copyFromLocal:从本地文件系统中拷贝文件到hdfs路径去
- 2.3.12 -copyToLocal: 从hdfs拷贝到本地
- 2.3.13 -cp: 从hdfs的一个路径拷贝到hdfs的另一个路径
- 2.3.14 -mv: 在hdfs目录中移动文件
- 2.3.15 -get: 等同于copyToLocal,就是从hdfs下载文件到本地
- 2.3.16 -getmerge: 合并下载多个文件,比如hdfs的目录 /aaa/下有多个文件:log.1, log.2,log.3,...
- 2.3.17 -put: 等同于copyFromLocal
- 2.3.18 -rm: 删除文件或文件夹
- 2.3.19 -rmdir: 删除空目录
- 2.3.20 -df: 统计文件系统的可用空间信息
- 2.3.21 -du: 统计文件夹的大小信息
- 2.3.22 -count: 统计一个指定目录下的文件节点数量
- 2.3.23 -setrep: 设置hdfs中文件的副本数量
- 3. HDFS 数据流
- 4. NameNode 工作机制
- 5. DataNode 工作机制
- 6. HDFS 其他功能
- 7. HDFS HA 高可用
1. HDFS 概念
1.1 概念
HDFS,它是一个文件系统,用于存储文件,通过目录树来定位文件
其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色
HDFS的设计适合一次写入,多次读出的场景,且不支持文件的修改,适合用来做数据分析,并不适合用来做网盘应用
1.2 组成
HDFS 集群包括,NameNode 和 DataNode 以及 Secondary Namenode
- NameNode 负责管理整个文件系统的元数据,以及每一个路径(文件)所对应的数据块信息
- DataNode 负责管理用户的文件数据块,每一个数据块都可以在多个 Datanode 上存储多个副本
- Secondary NameNode 用来监控 HDFS 状态的辅助后台程序,每隔一段时间获取 HDFS 元数据的快照
1.3 HDFS 文件块大小
HDFS 中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在 hadoop2.x 版本中是 128M,老版本中是 64M
HDFS 的块比磁盘的块大,其目的是为了最小化寻址开销
如果块设置得足够大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间
因而,传输一个由多个块组成的文件的时间取决于磁盘传输速率
如果寻址时间约为 10ms,而传输速率为 100MB/s,为了使寻址时间仅占传输时间的 1%,我们要将块大小设置约为100MB
块的大小:10ms100100M/s = 100M
2. HFDS命令行操作
2.1 基本语法
bin/hadoop fs 具体命令
2.2 参数大全
bin/hadoop fs
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] <path> ...]
[-cp [-f] [-p] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-expunge]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-usage [cmd ...]]
2.3 常用命令实操
2.3.1 -help:输出这个命令参数
bin/hdfs dfs -help rm
2.3.2 -ls: 显示目录信息
hadoop fs -ls /
2.3.3 -mkdir: 在hdfs上创建目录
hadoop fs -mkdir -p /aaa/bbb/cc/dd
2.3.4 -moveFromLocal: 从本地剪切粘贴到hdfs
hadoop fs - moveFromLocal /home/hadoop/a.txt /aaa/bbb/cc/dd
2.3.5 -moveToLocal: 从hdfs剪切粘贴到本地
hadoop fs - moveToLocal /aaa/bbb/cc/dd /home/hadoop/a.txt
2.3.6 --appendToFile: 追加一个文件到已经存在的文件末尾
hadoop fs -appendToFile ./hello.txt /hello.txt
2.3.7 -cat: 显示文件内容
2.3.8 -tail: 显示一个文件的末尾
hadoop fs -tail /weblog/access_log.1
2.3.9 -text:以字符形式打印一个文件的内容
hadoop fs -text /weblog/access_log.1
2.3.10 -chgrp 、-chmod、-chown: linux文件系统中的用法一样,修改文件所属权限
hadoop fs -chmod 666 /hello.txt
hadoop fs -chown someuser:somegrp /hello.txt
2.3.11 -copyFromLocal:从本地文件系统中拷贝文件到hdfs路径去
hadoop fs -copyFromLocal ./jdk.tar.gz /aaa/
2.3.12 -copyToLocal: 从hdfs拷贝到本地
hadoop fs -copyToLocal /aaa/jdk.tar.gz
2.3.13 -cp: 从hdfs的一个路径拷贝到hdfs的另一个路径
hadoop fs -cp /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
2.3.14 -mv: 在hdfs目录中移动文件
hadoop fs -mv /aaa/jdk.tar.gz /
2.3.15 -get: 等同于copyToLocal,就是从hdfs下载文件到本地
hadoop fs -get /aaa/jdk.tar.gz
2.3.16 -getmerge: 合并下载多个文件,比如hdfs的目录 /aaa/下有多个文件:log.1, log.2,log.3,…
hadoop fs -getmerge /aaa/log.* ./log.sum
2.3.17 -put: 等同于copyFromLocal
hadoop fs -put /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
2.3.18 -rm: 删除文件或文件夹
hadoop fs -rm -r /aaa/bbb/
2.3.19 -rmdir: 删除空目录
hadoop fs -rmdir /aaa/bbb/ccc
2.3.20 -df: 统计文件系统的可用空间信息
hadoop fs -df -h /
2.3.21 -du: 统计文件夹的大小信息
hadoop fs -du -s -h /aaa/*
2.3.22 -count: 统计一个指定目录下的文件节点数量
hadoop fs -count /aaa/
2.3.23 -setrep: 设置hdfs中文件的副本数量
hadoop fs -setrep 3 /aaa/jdk.tar.gz

这里设置的副本数只是记录在 Namenode 的元数据中,是否真的会有这么多副本,还得看 Datanode 的数量
因为目前只有3台设备,最多也就3个副本,只有节点数的增加到10台时,副本数才能达到10
3. HDFS 数据流
3.1 HDFS 写数据流程
3.1.1 剖析文件写入
-
Client 向 NameNode 通信请求上传文件,NameNode 检查目标文件是否已经存在,父目录是否已经存在
-
NameNode 返回是否可以上传
-
Client 先对文件进行切分,请求第一个 block 该传输到哪些 DataNode 服务器上
-
NameNode 返回3个 DataNode 服务器 DataNode 1,DataNode 2,DataNode 3
-
Client 请求3台中的一台 DataNode 1(网络拓扑上的就近原则,如果都一样,则随机挑选一台DataNode)上传数据(本质上是一个RPC调用,建立pipeline),DataNode 1 收到请求会继续调用 DataNode 2,然后 DataNode 2 调用 DataNode 3,将整个 pipeline 建立完成,然后逐级返回客户端
-
Client 开始往 DataNode 1 上传第一个 block (先从磁盘读取数据放到一个本地内存缓存),以 packet 为单位。写入的时候 DataNode 会进行数据校验,它并不是通过一个 packet 进行一次校验而是以 chunk 为单位进行校验(512byte)。DataNode 1 收到一个 packet 就会传给 DataNode 2,DataNode 2 传给 DataNode 3,DataNode 1 每传一个 packet 会放入一个应答队列等待应答
-
当一个 block 传输完成之后,Client 再次请求 NameNode 上传第二个block的服务器
3.1.2 网络拓扑概念
在本地网络中,两个节点被称为“彼此近邻”是什么意思?
在海量数据处理中,其主要限制因素是节点之间数据的传输速率——带宽很稀缺
这里的想法是将两个节点间的带宽作为距离的衡量标准
节点距离:两个节点到达最近的共同祖先的距离总和
例如,假设有 数据中心d1 机架r1 中的节点 n1,该节点可以表示为/d1/r1/n1,利用这种标记,这里给出四种距离描述:
Distance(/d1/r1/n1, /d1/r1/n1)=0(同一节点上的进程)
Distance(/d1/r1/n1, /d1/r1/n2)=2(同一机架上的不同节点)
Distance(/d1/r1/n1, /d1/r3/n2)=4(同一数据中心不同机架上的节点)
Distance(/d1/r1/n1, /d2/r4/n2)=6(不同数据中心的节点)

3.1.3 机架感知(副本节点选择)
官方介绍:
http://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-common/RackAwareness.html
http://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#Data_Replication
3.1.3.1 低版 本Hadoop 副本节点选择
第一个副本在 Client 所处的节点上,如果客户端在集群外,随机选一个
第二个副本和第一个副本位于不相同机架的随机节点上
第三个副本和第二个副本位于相同机架,节点随机

3.1.3.2 Hadoop 2.9.2 副本节点选择
第一个副本在 Client 所处的节点上,如果客户端在集群外,随机选一个。
第二个副本和第一个副本位于相同机架,随机节点
第三个副本位于不同机架,随机节点

3.2 HDFS 读数据流程
-
与 NameNode 通信查询元数据,找到文件块所在的 DataNode 服务器
-
挑选一台 DataNode(网络拓扑上的就近原则,如果都一样,则随机挑选一台 DataNode)服务器,请求建立 socket 流
-
DataNode 开始发送数据(从磁盘里面读取数据放入流, packet(一个 packet 为64kb)为单位来做校验)
-
客户端以 packet 为单位接收,先在本地缓存,然后写入目标文件

4. NameNode 工作机制
4.1 NameNode、Fsimage 、Edits 和 SecondaryNameNode 概述
NameNode:在内存中储存 HDFS 文件的元数据信息(目录)
如果节点故障或断电,存在内存中的数据会丢失,显然只在内存中保存是不可靠的
实际在磁盘当中也有保存:Fsimage 和 Edits,一个 NameNode 节点在重启后会根据这磁盘上的这两个文件来恢复到之前的状态
Fsimage(镜像文件) 和 Edits(编辑日志):记录内存中的元数据
如果每次对 HDFS 的操作都实时的把内存中的元数据信息往磁盘上传输,这样显然效率不够高,也不稳定
这时就出现了 Edits 文件,用来记录每次对 HDFS 的操作,这样在磁盘上每次就只用做很小改动(只进行追加操作)
当 Edits 文件达到了一定大小或过了一定的时间,就需要把 Edits 文件转化 Fsimage 文件,然后清空 Edits
这样的 Fsimage 文件不会和内存中的元数据实时同步,需要加上 Edits 文件才相等
SecondaryNameNode:负责 Edits 转化成 Fsimage
SecondaryNameNode 不是 NameNode 的备份
SecondaryNameNode 会定时定量的把集群中的 Edits 文件转化为 Fsimage 文件,来保证 NameNode 中数据的可靠性
4.2 NameNode & Secondary NameNode 工作机制
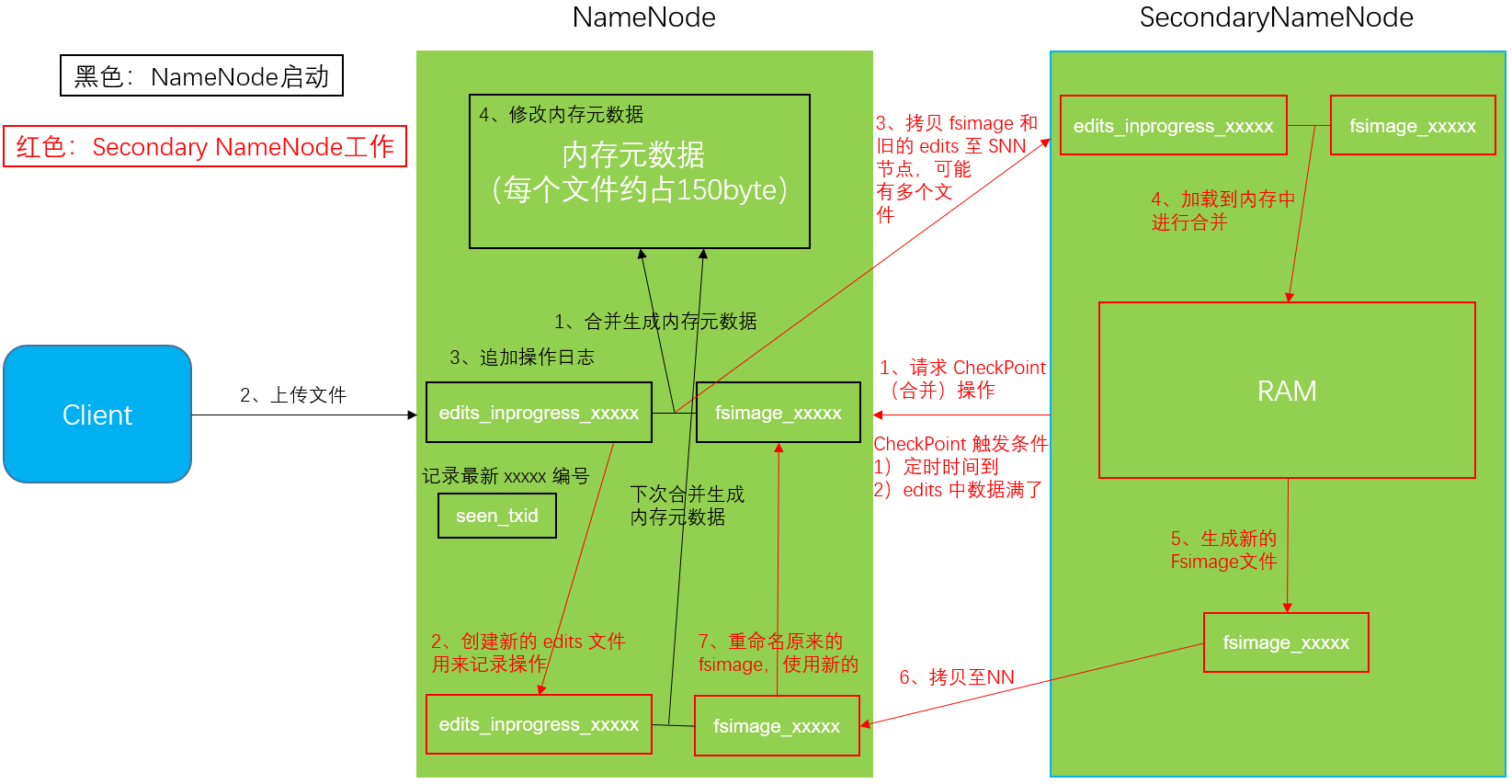
4.2.1 第一阶段:Namenode 启动
-
第一次启动 Namenode 格式化后,创建 fsimage 和 edits 文件,如果不是第一次启动,直接加载编辑日志和镜像文件到内存
-
客户端对元数据进行增删改的请求
-
Namenode 记录操作日志,追加滚动日志
-
Namenode 在内存中对数据进行增删改查
4.2.2 第二阶段:Secondary NameNode 工作
-
Secondary NameNode 询问 Namenode 是否需要checkpoint,直接带回 Namenode 是否检查结果
-
Secondary NameNode 请求执行 checkpoint
-
Namenode 滚动正在写的 edits 日志
-
将滚动前的编辑日志和镜像文件拷贝到 Secondary NameNode
-
Secondary NameNode 加载编辑日志和镜像文件到内存,并合并
-
生成新的镜像文件 fsimage.chkpoint
-
拷贝 fsimage.chkpoint 到 Namenode
-
Namenode 将 fsimage.chkpoint 重新命名成 fsimage
4.2.3 web 端访问 SecondaryNameNode
-
启动集群
-
浏览器中输入:http://slave1:50090/status.html
-
查看 SecondaryNameNode 信息
4.2.4 chkpoint检查时间参数设置
[hdfs-default.xml]
- 通常情况下,SecondaryNameNode 每隔一小时执行一次
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
- 一分钟检查一次操作次数,当操作次数达到一百万时,SecondaryNameNode执行一次。
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分钟检查一次操作次数</description>
</property>
4.3 镜像文件和编辑日志文件
4.3.1 概念
Namenode 被格式化之后,将在 /usr/local/hadoop/tmp/dfs/name/current 目录中产生如下文件:
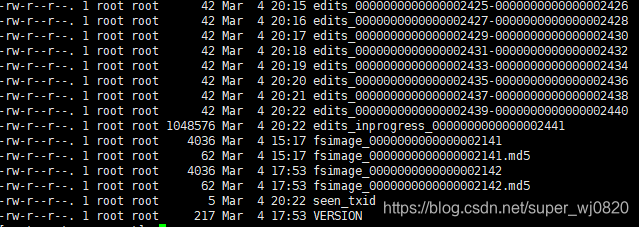
edits_0000000000000000000
fsimage_0000000000000000000.md5
seen_txid
VERSION
-
Fsimage文件:HDFS 文件系统元数据的一个永久性的检查点,其中包含 HDFS 文件系统的所有目录和文件 idnode 的序列化信息
-
Edits文件:存放 HDFS 文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到 edits 文件中
-
seen_txid 文件:保存的是一个数字,就是最后一个 edits_ 的数字
-
每次 Namenode 启动的时候都会将 fsimage 文件读入内存,并从 00001 开始到 seen_txid 中记录的数字依次执行每个 edit s里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成Namenode启动的时候就将 fsimage 和 edits 文件进行了合并
4.3.2 oiv 查看 fsimage 文件
- 查看 oiv 和 oev 命令
[root@master current]$ hdfs
oiv apply the offline fsimage viewer to an fsimage
oev apply the offline edits viewer to an edits file
- 基本语法
hdfs oiv -p 文件类型 -i 镜像文件 -o 转换后文件输出路径
- 案例实操
[root@master current]# pwd
/usr/local/hadoop/tmp/dfs/name/current
[root@master current]# hdfs oiv -p XML -i fsimage_0000000000000002141 -o /usr/hadoop/fsimage.xml
20/03/04 20:44:45 INFO offlineImageViewer.FSImageHandler: Loading 5 strings
[root@master current]# cat /usr/hadoop/fsimage.xml
将显示的 xml 文件内容格式化 查看 (可看到 Hdfs 上各个文件目录信息)
4.3.3 oev 查看 edits 文件
- 基本语法
hdfs oev -p 文件类型 -i 编辑日志 -o 转换后文件输出路径
- 案例实操
[root@master current]# hdfs oev -p XML -i edits_0000000000000002491-0000000000000002492 -o /usr/hadoop/edits.xml
[root@master current]# cat /usr/hadoop/edits.xml
将显示的 xml 文件内容格式化 查看
4.4 滚动编辑日志
正常情况 HDFS 文件系统有更新操作时,就会滚动编辑日志,也可以用命令强制滚动编辑日志
- 滚动编辑日志(前提必须启动集群)
[root@master current]# hdfs dfsadmin -rollEdits
Successfully rolled edit logs.
New segment starts at txid 2507
- 镜像文件什么时候产生
Namenode 启动时加载镜像文件和编辑日志
4.5 Namenode 版本号
4.5.1 查看 Namenode 版本号
在 /usr/local/hadoop/tmp/dfs/name/current 这个目录下查看 VERSION
[root@master current]# cat VERSION
#Wed Mar 04 17:53:02 CST 2020
namespaceID=866472014
clusterID=CID-f383d6c4-da30-47c7-beb6-02c589c47f27
cTime=1582684942545
storageType=NAME_NODE
blockpoolID=BP-116957957-192.168.27.101-1582684942545
layoutVersion=-63
4.5.2 Namenode 版本号具体解释
-
NamespaceID 在 HDFS 上,会有多个 Namenode,所以不同 Namenode 的 namespaceID 是不同的,分别管理一组 blockpoolID
-
clusterID 集群id,全局唯一
-
cTime 属性标记了 Namenode 存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为0;但是在文件系统升级之后,该值会更新到新的时间戳
-
storageType 属性说明该存储目录包含的是 Namenode 的数据结构
-
blockpoolID:一个 blockpoolid 标识一个 block pool,并且是跨集群的全局唯一。当一个新的 Namespace 被创建的时候(format过程的一部分)会创建并持久化一个唯一ID。在创建过程构建全局唯一的 BlockPoolID 比人为的配置更可靠一些。NN 将 BlockPoolID 持久化到磁盘中,在后续的启动过程中,会再次load并使用
-
layoutVersion 是一个负整数,通常只有 HDFS 增加新特性时才会更新这个版本号
4.6 SecondaryNameNode 目录结构
Secondary NameNode 用来监控 HDFS 状态的辅助后台程序,每隔一段时间获取 HDFS 元数据的快照
在 slave2 机器上的 /usr/local/hadoop/tmp/dfs/namesecondary/current 这个目录中查看 SecondaryNameNode 目录结构
[root@slave1 current]# pwd
/usr/local/hadoop/tmp/dfs/namesecondary/current
[root@slave1 current]# ll
total 1060
-rw-r--r--. 1 root root 1048576 Mar 4 23:05 edits_0000000000000002749-0000000000000002749
-rw-r--r--. 1 root root 42 Mar 4 23:05 edits_0000000000000002750-0000000000000002751
-rw-r--r--. 1 root root 42 Mar 5 15:21 edits_0000000000000002781-0000000000000002782
-rw-r--r--. 1 root root 4115 Mar 5 15:21 fsimage_0000000000000002780
-rw-r--r--. 1 root root 62 Mar 5 15:21 fsimage_0000000000000002780.md5
-rw-r--r--. 1 root root 4115 Mar 5 15:21 fsimage_0000000000000002782
-rw-r--r--. 1 root root 62 Mar 5 15:21 fsimage_0000000000000002782.md5
-rw-r--r--. 1 root root 217 Mar 5 15:21 VERSION
SecondaryNameNode 的 namesecondary/current 目录和主 Namenode 的 current 目录的布局相同
好处:在主 Namenode 发生故障时(假设没有及时备份数据),可以从 SecondaryNameNode 恢复数据
4.6.1 Namenode 故障恢复方法一
将 SecondaryNameNode 中数据拷贝到 Namenode 存储数据的目录
案例实操:模拟 Namenode 故障,并采用方法一,恢复 Namenode 数据
-
kill -9 namenode 进程 (-9 表示无条件终止)
-
删除 Namenode 存储的数据 (/usr/local/hadoop/tmp/dfs/name)
rm -rf /usr/local/hadoop/tmp/dfs/name/*打开 http://master:50070/ 无法访问
-
拷贝 SecondaryNameNode 中数据到原 Namenode 存储数据目录
[root@slave1 dfs]# scp -r /usr/local/hadoop/tmp/dfs/namesecondary/* master:/usr/local/hadoop/tmp/dfs/name/ edits_0000000000000002749-0000000000000002749 100% 1024KB 1.0MB/s 00:00 edits_0000000000000002750-0000000000000002751 100% 42 0.0KB/s 00:00 VERSION 100% 217 0.2KB/s 00:00 fsimage_0000000000000002780.md5 100% 62 0.1KB/s 00:00 fsimage_0000000000000002780 100% 4115 4.0KB/s 00:00 edits_0000000000000002781-0000000000000002782 100% 42 0.0KB/s 00:00 fsimage_0000000000000002782.md5 100% 62 0.1KB/s 00:00 fsimage_0000000000000002782 100% 4115 4.0KB/s 00:00 in_use.lock -
重新启动 Namenode
sbin/hadoop-daemon.sh start namenode打开 http://master:50070/ 可以访问,并可操作 Hdfs
4.6.2 Namenode 故障恢复方法二
使用 -importCheckpoint 选项启动 Namenode 守护进程,从而将 SecondaryNameNode 用作新的主 Namenode
案例实操:模拟 Namenode 故障,并采用方法二,恢复 Namenode 数据
-
修改 hdfs-site.xml 中的
<property> <name>dfs.namenode.checkpoint.period</name> <value>120</value> </property> -
kill -9 namenode进程
-
删除 Namenode 存储的数据(/usr/local/hadoop/tmp/dfs/name)
rm -rf /usr/local/hadoop/tmp/dfs/name/*打开 http://master:50070/ 无法访问
-
如果 SecondaryNameNode 不和 Namenode 在一个主机节点上,需要将 SecondaryNameNode 存储数据的目录拷贝到 Namenode 存储数据的平级目录
[root@master dfs]# pwd /usr/local/hadoop/tmp/dfs [root@master dfs]# ls name namesecondary -
导入检查点数据(等待一会 ctrl+c 结束掉)
bin/hdfs namenode -importCheckpoint -
启动 Namenode
sbin/hadoop-daemon.sh start namenode -
如果提示文件锁了,可以删除 in_use.lock
rm -rf /usr/local/hadoop/tmp/dfs/namesecondary/in_use.lock
4.7 集群安全模式操作
4.7.1 概述
Namenode 启动时,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作
一旦在内存中成功建立文件系统元数据的映像,则创建一个新的 fsimage 文件和一个空的编辑日志,此时 Namenode 开始监听 Datanode 请求
但是此刻,Namenode 运行在安全模式,即 Namenode 的文件系统对于客户端来说是只读的
系统中的数据块的位置并不是由 Namenode 维护的,而是以块列表的形式存储在 Datanode 中
在系统的正常操作期间,Namenode 会在内存中保留所有块位置的映射信息
在安全模式下,各个 Datanode 会向 Namenode 发送最新的块列表信息,Namenode 了解到足够多的块位置信息之后,即可高效运行文件系统
如果满足“最小副本条件”,Namenode 会在30秒钟之后就退出安全模式
所谓的最小副本条件指的是在整个文件系统中99.9%的块满足最小副本级别(默认值:dfs.replication.min=1)
在启动一个刚刚格式化的 HDFS 集群时,因为系统中还没有任何块,所以 Namenode 不会进入安全模式
4.7.2 基本语法
集群处于安全模式,不能执行重要操作(写操作),集群启动完成后,自动退出安全模式。
- bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
- bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
- bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
- bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态)
4.7.3 案例
模拟等待安全模式
-
先进入安全模式
bin/hdfs dfsadmin -safemode enter安全模式下只可查看 Hdfs 文件,无法新增、删除
-
执行下面的脚本
编辑一个脚本
#!/bin/bash bin/hdfs dfsadmin -safemode wait bin/hdfs dfs -put ~/hello.txt /root/hello.txt -
再打开一个窗口,执行
bin/hdfs dfsadmin -safemode leave
4.8 Namenode 多目录配置
Namenode 的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性
具体配置如下:
[hdfs-site.xml]
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2</value>
</property>
5. DataNode 工作机制
5.1 DataNode工作机制
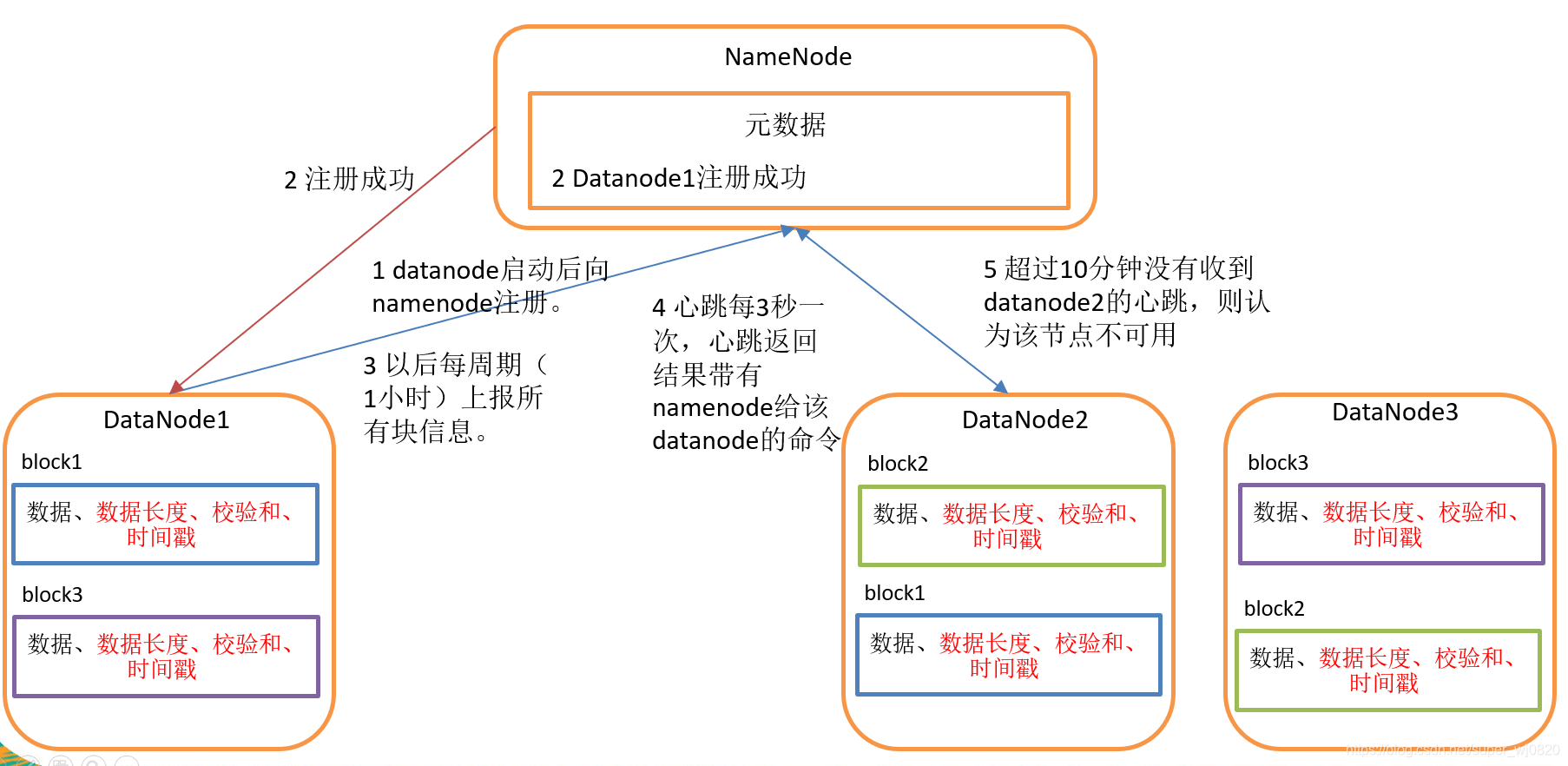
-
一个数据块在 Datanode 上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳
-
DataNode 启动后向 Namenode 注册,通过后,周期性(1小时)的向 Namenode 上报所有的块信息
-
心跳是每 3 秒一次,心跳返回结果带有 Namenode 给该 DataNode 的命令如复制块数据到另一台机器,或删除某个数据块。如果超过 10 分钟没有收到某个 DataNode 的心跳,则认为该节点不可用
-
集群运行中可以安全加入和退出一些机器
5.2 数据完整性
-
当 DataNode 读取 block 的时候,它会计算 checksum
-
如果计算后的 checksum,与 block 创建时值不一样,说明 block 已经损坏
-
client 读取其他 DataNode 上的 block.
-
DataNode 在其文件创建后周期验证 checksum
5.3 掉线时限参数设置
Datanode 进程死亡或者网络故障造成 Datanode 无法与 Namenode 通信,Namenode 不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长
HDFS 默认的超时时长为 10分钟 + 30秒
如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval。
而默认的 dfs.namenode.heartbeat.recheck-interval 大小为5分钟,dfs.heartbeat.interval默认为3秒
需要注意的是 hdfs-site.xml 配置文件中的 heartbeat.recheck.interval 的单位为毫秒,dfs.heartbeat.interval 的单位为秒
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name> dfs.heartbeat.interval </name>
<value>3</value>
</property>
5.4 DataNode 的目录结构
和 Namenode 不同的是,Datanode 的存储目录是初始阶段自动创建的,不需要额外格式化
5.4.1 查看 DataNode 的版本号
在 /usr/local/hadoop/tmp/dfs/data/current 这个目录下查看版本号
[root@slave1 current]# cat VERSION
#Fri Mar 06 16:58:36 CST 2020
storageID=DS-7908c807-e3ec-4b85-952a-922ba8d3a24f
clusterID=CID-f383d6c4-da30-47c7-beb6-02c589c47f27
cTime=0
datanodeUuid=f230ca32-5797-4949-b996-95bf66a25a0d
storageType=DATA_NODE
layoutVersion=-57
5.4.2 DataNode 版本号具体解释
-
storageID:存储id号
-
clusterID:集群id,全局唯一
-
cTime:标记了 Datanode 存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为0;但是在文件系统升级之后,该值会更新到新的时间戳
-
datanodeUuid:Datanode 的唯一识别码
-
storageType:存储类型
-
layoutVersion: 是一个负整数,通常只有HDFS增加新特性时才会更新这个版本号
5.4.3 DataNode 数据块版本号
在 /usr/local/hadoop/tmp/dfs/data/current/BP-116957957-192.168.27.101-1582684942545/current 这个目录下查看该数据块的版本号
[root@slave1 current]# pwd
/usr/local/hadoop/tmp/dfs/data/current/BP-116957957-192.168.27.101-1582684942545/current
[root@slave1 current]# cat VERSION
#Fri Mar 06 16:58:36 CST 2020
namespaceID=866472014
cTime=1582684942545
blockpoolID=BP-116957957-192.168.27.101-1582684942545
layoutVersion=-57
5.4.4 DataNode 数据块版本号的具体解释
-
namespaceID:是 Datanode 首次访问 Namenode 的时候从 Namenode 处获取的 storageID; 对每个 Datanode 来说是唯一的(但对于单个 Datanode 中所有存储目录来说则是相同的),Namenode 可用这个属性来区分不同 Datanode
-
cTime:标记了 Datanode 存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为0;但是在文件系统升级之后,该值会更新到新的时间戳
-
blockpoolID:一个 block pool id 标识一个block pool,并且是跨集群的全局唯一;当一个新的 Namespace 被创建的时候(format过程的一部分)会创建并持久化一个唯一ID;在创建过程构建全局唯一的 lockPoolID 比人为的配置更可靠一些。Namenode 将 BlockPoolID 持久化到磁盘中,在后续的启动过程中,会再次 load 并使用
-
layoutVersion:一个负整数,通常只有 HDFS 增加新特性时才会更新这个版本号
5.5 服役新数据节点
5.5.1 需求
随着公司业务的增长,数据量越来越大,原有的数据节点的容量已经不能满足存储数据的需求,需要在原有集群基础上动态添加新的数据节点
5.5.2 环境准备
-
克隆一台虚拟机(master -> slave3),并启动
从 master 上克隆可节省文件同步的时间,否则需要重新安装、配置 JDK、Hadoop
-
修改 ip 地址为 192.168.27.104
-
修改 ip 映射(/etc/hosts),并在 master、slave1、slave2 上同步修改
在 master、slave1、slave2 基础上新增 192.168.27.104 slave3
192.168.27.101 master 192.168.27.102 slave1 192.168.27.103 slave2 192.168.27.104 slave3 -
修改主机名
hostnamectl set-hostname slave3 -
建立 master、slave1、slave2 和 slave3 之间的免密
删除 slave3 下的 .ssh,重新生成公钥进行
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 932
932

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









