




 本文深入讲解了哈希表的基本概念,包括如何计算平均查找次数、再散列与冲突解决策略等,并提供了具体的代码实例。
本文深入讲解了哈希表的基本概念,包括如何计算平均查找次数、再散列与冲突解决策略等,并提供了具体的代码实例。

解析来自某大佬
分析: 区别概念平均成功查找次数和平均不成功查找次数。 平均成功查找次数=每个关键词比较次数之和÷关键词的个数
平均不成功查找次数=每个位置不成功时的比较次数之和÷表长(所谓每个位置不成功时的比较次数就是在除余位置内,每个位置到第一个为空的比较次数,比如此题表长为11,散列函数为Key%11,除余的是11,那么除余位置就是0—10;如果表长为15,但散列函数为Key%13,那么除余位置就是0—12)
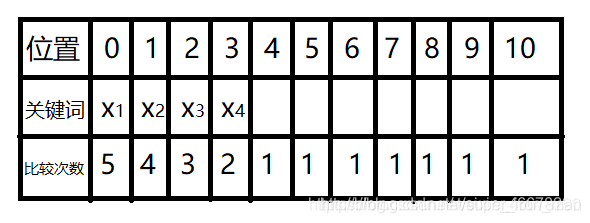
明确概念后做题: 连续插入散列值相同的4个元素,我们就假设它的散列值都为0,那么插入后的位置:
其中位置0到第一个为空的位置4的比较次数为5,其余的位置以此类推。 平均不成功查找次数=(5+4+3+2+1+1+1+1+1+1+1)÷
11 = 21/11 故选D



2-12
设数字 {4371, 1323, 6173, 4199, 4344, 9679, 1989} 在大小为10的散列表中根据散列函数 h(X)=X%10得到的下标对应为 {1, 3, 4, 9, 5, 0, 2}。那么继续用散列函数 “h(X)=X%表长”实施再散列并用线性探测法解决冲突后,它们的下标变为:
(3分)
A.1, 12, 17, 0, 13, 8, 14
B.11, 3, 13, 19, 4, 0, 9
C.1, 3, 4, 9, 5, 0, 2
D.1, 12, 9, 13, 20, 19, 11
再散列就是,把表长变为两倍即20,取最近的素数23。然后分别取余就可以了,其实到第三个就可以选出答案了。
6-1 分离链接法的删除操作函数 (20分)
试实现分离链接法的删除操作函数。
函数接口定义:
bool Delete( HashTable H, ElementType Key );
其中HashTable是分离链接散列表,定义如下:
typedef struct LNode *PtrToLNode;
struct LNode {
ElementType Data;
PtrToLNode Next;
};
typedef PtrToLNode Position;
typedef PtrToLNode List;
typedef struct TblNode *HashTable; /* 散列表类型 */
struct TblNode { /* 散列表结点定义 */
int TableSize; /* 表的最大长度 */
List Heads; /* 指向链表头结点的数组 */
};
函数Delete应根据裁判定义的散列函数Hash( Key, H->TableSize )从散列表H中查到Key的位置并删除之,然后输出一行文字:Key is deleted from list Heads[i],其中Key是传入的被删除的关键词,i是Key所在的链表的编号;最后返回true。如果Key不存在,则返回false。
裁判测试程序样例:
#include <stdio.h>
#include <string.h>
#define KEYLENGTH 15 /* 关键词字符串的最大长度 */
typedef char ElementType[KEYLENGTH+1]; /* 关键词类型用字符串 */
typedef int Index; /* 散列地址类型 */
typedef enum {false, true} bool;
typedef struct LNode *PtrToLNode;
struct LNode {
ElementType Data;
PtrToLNode Next;
};
typedef PtrToLNode Position;
typedef PtrToLNode List;
typedef struct TblNode *HashTable; /* 散列表类型 */
struct TblNode { /* 散列表结点定义 */
int TableSize; /* 表的最大长度 */
List Heads; /* 指向链表头结点的数组 */
};
Index Hash( ElementType Key, int TableSize )
{
return (Key[0]-'a')%TableSize;
}
HashTable BuildTable(); /* 裁判实现,细节不表 */
bool Delete( HashTable H, ElementType Key );
int main()
{
HashTable H;
ElementType Key;
H = BuildTable();
scanf("%s", Key);
if (Delete(H, Key) == false)
printf("ERROR: %s is not found\n", Key);
if (Delete(H, Key) == true)
printf("Are you kidding me?\n");
return 0;
}
/* 你的代码将被嵌在这里 */
输入样例1:散列表如下图
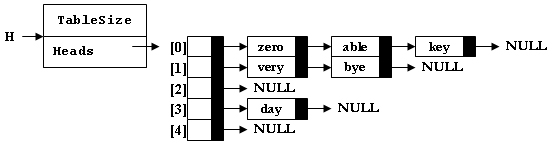
able
输出样例1:
able is deleted from list Heads[0]
输入样例2:散列表如样例1图
date
输出样例2:
ERROR: date is not found
bool Delete(HashTable H,ElementType Key)
{
Index i;
i=Hash(Key,H->TableSize);
if(H->Heads[i].Next==NULL) return false;
Position p,temp;
p=H->Heads[i].Next;
//当未到达表尾,且未找到时
while(strcmp(p->Data,Key)!=0&&p)//需要匹配的关键字为字符串
{
temp=p;
p=p->Next;
}
if(strcmp(p->Data,Key)==0)
{
printf("%s is deleted from list Heads[%d]\n",Key,i);
temp=p->Next;
free(p);
return true;
}
else return false;
}
6-2 哈希表的创建及查找(线性探查法) (10分)
实现哈希表创建及查找算法,哈希函数使用除余法,用线性探测法处理冲突。
函数接口定义:
void CreateHash(HashTable HT[],int n); //输入不大于m的n个不为0(0表示空值)的数,用线性探查法解决冲突构造散列表
int SearchHash(HashTable HT[],int key); //输入一个值key,在散列表中查找key位置
其中 HT 表示哈希表, n表示记录数,key要查找的关键字
裁判测试程序样例:
#include<iostream>
using namespace std;
#define m 16
#define NULLKEY 0 //单元为空的标记
struct HashTable{
int key;
};
void CreateHash(HashTable HT[],int n);
int SearchHash(HashTable HT[],int key);
int main()
{ int value,key;
int result;
int i,j,n;
HashTable HT[m];
for(i=0;i<m;i++)
HT[i].key=0;
cin >> n;
if(n>m) return 0;
CreateHash(HT,n);
cin >> key;
result=SearchHash(HT,key);
if(result!=-1)
cout << "search success,The key is located in "<< result+1;
else
cout << "search failed";
return 0;
}
/* 请在这里填写答案 */
输入样例:
12
19 14 23 1 68 20 84 27 55 11 10 79
55
输出样例:
输出拓扑序列。
search success,The key is located in 6
void CreateHash(HashTable HT[],int n)//输入不大于m的n个不为0(0表示空值)的数,用线性探查法解决冲突构造散列表
{
int i,e,t;
for(i=0;i<n;i++)
{
cin>>e;
t=e%13;
while(1)
{
if(HT[t].key==0)
{
HT[t].key=e;break;
}
else
{
t++;
}
}
}
}
int SearchHash(HashTable HT[],int key) //输入一个值key,在散列表中查找key位置
{
int i,t;
for(i=0;i<=m;i++)
{
t=key%13;
while(HT[t].key!=0)
{
if(HT[t].key==key)
{
return t;
}
else
{
t++;
}
}
}
return -1;
}

















 6181
6181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









