




 本文解析了前后端分离的概念,探讨了前端与后端的区别及作用,并对比了前后端不分离的开发模式。介绍了前后端分离如何提升开发效率及用户体验。
本文解析了前后端分离的概念,探讨了前端与后端的区别及作用,并对比了前后端不分离的开发模式。介绍了前后端分离如何提升开发效率及用户体验。
今天这篇文章来分析一下什么是前后端分离的相关知识,很多小伙伴不清楚到底什么是前端,什么是后端,什么是前后端分离。在说前后端分离之前,我们先要弄清楚这几个概念,大家可能经常听到前端,后端或者是大前端的一些概念,这些概念是怎么产生的呢?什么是前端,什么是后端,什么是前后端不分离?只有了解了这些,那么前后端分离你就懂了。
首先我讲一下什么是前端,在讲前端之前我先问大家一个问题,我们经常提到的JavaScript是前端吗?用JS写的程序是前端吗?还是说只有前端工程师写的程序才叫前端?我常提到HTML,CSS这是前端吗?或者是我们常用的一些APP,或者是一些小程序,这些是前端吗?那么大前端又是什么呢?这些问题抛出来以后,刚开始学习编程的同学估计都有想放弃学习编程的这种想法了。
没有关系,也没有你想的那么复杂。在通常的情况下,我们说的这个前端都是指浏览器这一端,而浏览器这一端通常是用JS来实现的,所以用JS写大部分的程序都是前端,包括APP,包括小程序和H5等。而当nodeJS出现以后,用nodeJS写的后台部分,也会被人归为前端,为了区分之前的前端,给他起了一个名字叫做大前端。但是呢我们想一下,用这种语言来区分前后端他真的合适吗?我其实是持有保留态度的。
对于前后端的定义,我认为他不应该是以语言来定义,而是应该以他的运行环境去定义,如果是在服务器端的话,应该被称为后端,因为什么呢?因为你既看不到也摸不着。而运行在客户端,就应该被称为前端,因为你能够看得到。
我们再看一下什么是前后端不分离,在移动互联出现之前,有一种流行的说法叫做B/S和C/S架构,C/S架构指的就是Client Server,意思就是说在桌面程序上有一个客户端,然后连接远程的这个服务器端,用socket或者是http来传输数据。而B/S架构是什么呢,就是指的是用通过浏览器进行访问,不需要装一个客户端,B/S架构曾经一度被认为是C/S的替代者,好处是什么呢?就是它不需要安装,简单方便。所以那个时候的写法就是后端是控制一切的,所以在早期的Web开发过程中,我们大家都听说过什么PHP程序员啊,Java程序员啊或者是asp程序员,大家要干的活就是“全栈”,也就是说前后端通吃。那么当时的技术是怎样的呢?看一下这张图:
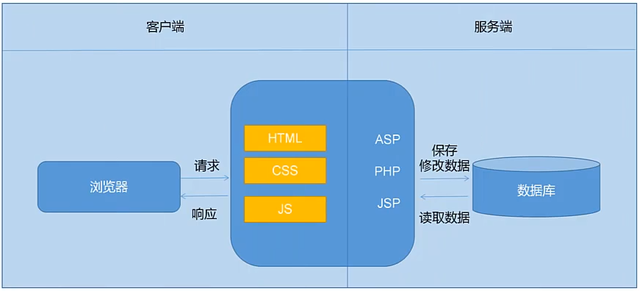
通常开发一个web的这种应用程序,多是以asp,php或者jsp这样的语言来编写,项目通常是由多个这种文件构成的,每个文件当中同时包含了HTML,CSS,JS这样混编的,系统整体负责处理业务逻辑,控制业面跳转和向用户展示业面等。
而这个浏览器是什么呢?浏览器他是一个翻译官,他是翻译程序员写的代码给用户看的,翻译的过程其实有一个高大上的词,很多人把他称之为渲染。也就是说我们在平常看到的一些漂亮的这个网页就是浏览器渲染出来的。这个架构的好处是什么呢?就是简单便捷。但是这么做其实有一个明显的弊端,如果这个页面复杂一点的话,那这个单页的代码就比较恐怖了,少则上千,多则上万。
所以说在以前的开发过程中,前端设计师一般只扮演一个切图的工作,只是简单地将UI设计师设计出来的原型图把它编程静态的HTML业面,比如说业面的交互逻辑,比如说后台的数据交互,这些工作都是由后台开发人员来实现的,而且更有可能的是什么呢,是后端的开发人员直接兼顾前端的对口工作,一边实现API的接口一边要开发网页,两个相互切换着做。这导致了后台程序员开发的工作压力特别大,这样不仅开发效率比较缓慢,而且代码难以维护。而我们讲的前后端分离的话下面来看一下这张图片:
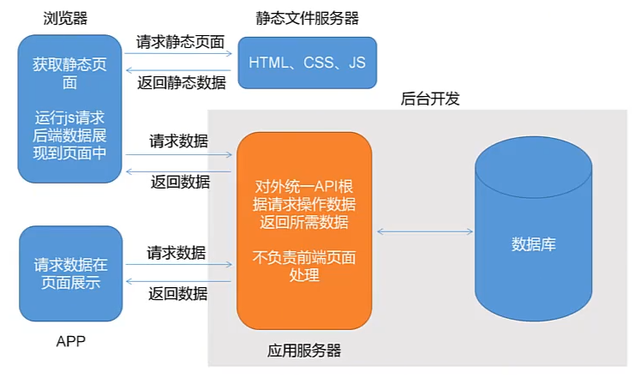
前后端分离除了解决分工不均的这个问题之外,主要是将更多的交互的这个逻辑分配给前端来处理,而后端可以专注于本职的工作,比如说API接口,或者是进行权限控制,或者是进行运算这些都交给后端。那么前端就可以独立完成与用户交互的这样一个过程,在前后端分离的这个应用模式当中,后端仅返回前端所需要的这样的一个过程,不需要渲染HTML业面和控制前端的这样一个效果。
至于说用户看到什么样的效果呢,从后端请求的数据展现都是后端通过异步接口,不如说通过AJAX/JSON这种方式提供的,前端只管展现,但是呢你不要以为只是在敲代码的这个时候把前端和后端进行分开就是前后端分离了。它彻底是解放了前端,前端不需要在向后台提供模板,或者是后台无需再前端HTML中嵌入后台的代码,两者可以同时开工,不需要相互依赖,使得这样的开发效率大大的提高。
写在最后:
对于前后端分离,目前比较认同的概念是SPA(Single Page Application),所有用到的展现数据都是后端通过异步接口(ajax.json)的方式实现的,前端直管展现。
从某种意义上来说,SPA确实做到了前后端分离,但这种方式存在两个问题:
(1) WEB 服务中,SPA 类占的比例很少。很多场景下还有同步/同步+异步混合的模式,SPA 不能作为一种通用的解决方案;现阶段的SPA开发模式,接口通常是按照展现逻辑来提供的,有时候为了提高效率,后端会帮我们处理一些展现逻辑,这就意味着后端还是涉足了View层的工作,不是真正的前后端分离。
(2) SPA 式的前后端分离,是从物理层做区分(认为只要是客户端的就是前端,服务器端的就是后端),这种分法已经无法满足我们前后端分离的需求,我们认为从职责上划分才能满足目前我们的使用场景:前端:负责View 和Controller 层;后端只负责Model 层,业务处理/数据等。


















 1916
1916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









