






Linux安装kafka分为三步
第一步安装jdk
我用的是最新的版本
所以安装的jdk是1.8
第一步是检查自己的系统里面有没有jdk
1、检查一下系统中的jdk版本
[root@localhost software]# java -version
显示:
openjdk version "1.8.0_102"
OpenJDK Runtime Environment (build 1.8.0_102-b14)
OpenJDK 64-Bit Server VM (build 25.102-b14, mixed mode)
如果版本是1.8的就不用管了
如果不是1.8就需要先卸载老版本的 再安装新版本的
2、检测jdk安装包
rpm -qa|grep jdk
2 如果有,卸载预装jdk
rpm -e --nodeps jdk-1.7.0_79-fcs.x86_64
rpm -e --nodeps jdk-1.7.0_79-fcs.x86_64
rpm -e --nodeps java-1.7.0-openjdk-1.7.0.45-2.4.3.3.el6.x86_64
rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.x86_64
这里根据自己的情况卸载 我的环境里面有个1.6有个1.7 我就都卸载了
3.官网下载jdk1.8版本
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
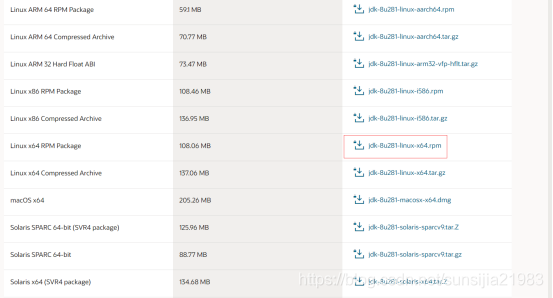
下载红框里面的
这个是我用的
链接:https://pan.baidu.com/s/1LOtlLUOoksEe8N7IbzUliA
提取码:59ci
4.将下载的tar包通过工具上传到你的linux服务器上
我是上传到home目录解压倒了/usr/local/java下
然后解压 tar -xvf jdk-8u181-linux-x64.tar.gz -C /usr/local/java/
-C的意思就是解压到哪里
5 更新/etc/profile
vim /etc/profile
修改成下面的配置:
可以在这个文件的最下面加上
export JAVA_HOME=/usr/local/java/jdk1.8.0_181
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib::$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export PATH=${JAVA_PATH}:$PATH
修改成功后让/etc/profile生效
source /etc/profile
6 查看java版本
java -version
问题
在升级jdk过程中,我碰到两个问题
1.没有预装jdk
解决方法:不用管,直接进行下面的步骤
2.更新完/etc/profile并且重新读取后还是显示1.7的java版本
解决方法:问题原因是配置文件中的一行
export PATH=${JAVA_PATH}:$PATH
之前写的方式是$PATH在前面,这样系统还是会读取前面的1.7环境变量。改成后面就可以了
解决办法:jdk的小版本没有写对
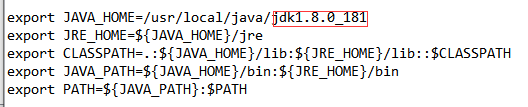
要注意这里的小版本
第二步安装zookeeper
参考
https://www.cnblogs.com/uncleyong/p/10737119.html#_label3
zookeeper下载
下载url:http://www.apache.org/dyn/closer.cgi/zookeeper/
这个是我的
链接:https://pan.baidu.com/s/18VEIQ2KQyjvoZ5nXXc0FNw
提取码:saie
注意这里要下载版本号后面带bin的 新装的3.1.0-bin 说是二进制的得用-bin的
上传安装包到linux服务器,rz
解压 我是上传到了home文件夹里面 解压到/usr/local/
tar -zxvf apache-zookeeper-3.7.0-bin.tar.gz -C /usr/local/
解压后

创建目录data
mkdir data

修改配置文件名,最好是cp一份
cp zoo_sample.cfg zoo.cfg

编辑配置文件
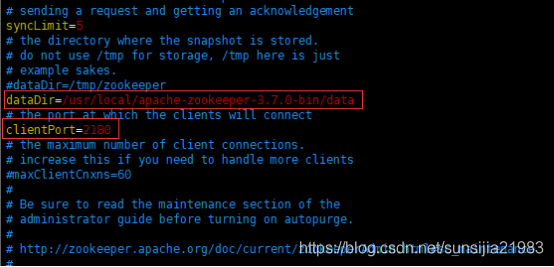
vim zoo.cfg

配置dataDir,最好写为相对路径:…/data
默认端口2181改为2180
启动服务
./zkServer.sh start

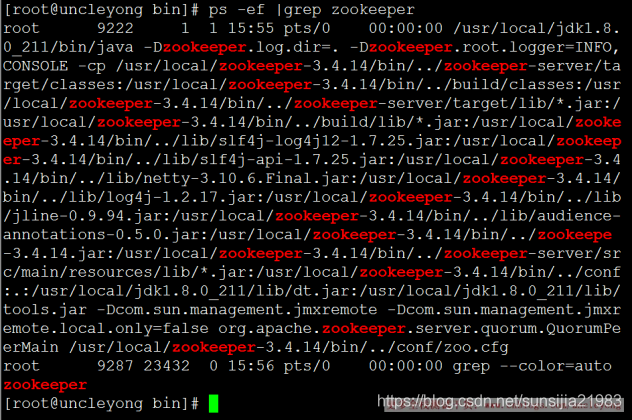
查看进程
ps -ef | grep zookeeper
或者
netstat -anp | grep 2180
第三步安装kafka
参考
https://www.cnblogs.com/uncleyong/p/13338077.html
简介
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。
相关术语(参考百度百科)
Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker
Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
Partition
Partition是物理上的概念,每个Topic包含一个或多个Partition
Producer
负责发布消息到Kafka broker
Consumer
消息消费者,向Kafka broker读取消息的客户端
Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)
下载
http://kafka.apache.org/

https://archive.apache.org/dist/kafka/2.3.0/kafka_2.12-2.3.0.tgz
这里是我的
链接:https://pan.baidu.com/s/1doOIIQrJM82Eq4NY4xsRQA
提取码:ebor
安装
解压
tar -zxvf kafka_2.12-2.3.0.tgz -C /usr/local/
修改配置文件
创建存放数据的文件夹


查看zk的配置
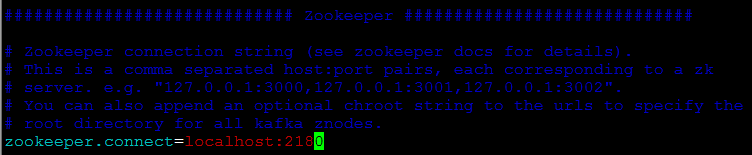
vim zoo.cfg,zk的端口是2180

kafka中对应修改为2180
另外,zookeeper安装,请参考:https://www.cnblogs.com/uncleyong/p/10737119.html
启动服务
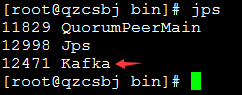
启动zookeeper

启动kafka
./kafka-server-start.sh ../config/server.properties &


测试
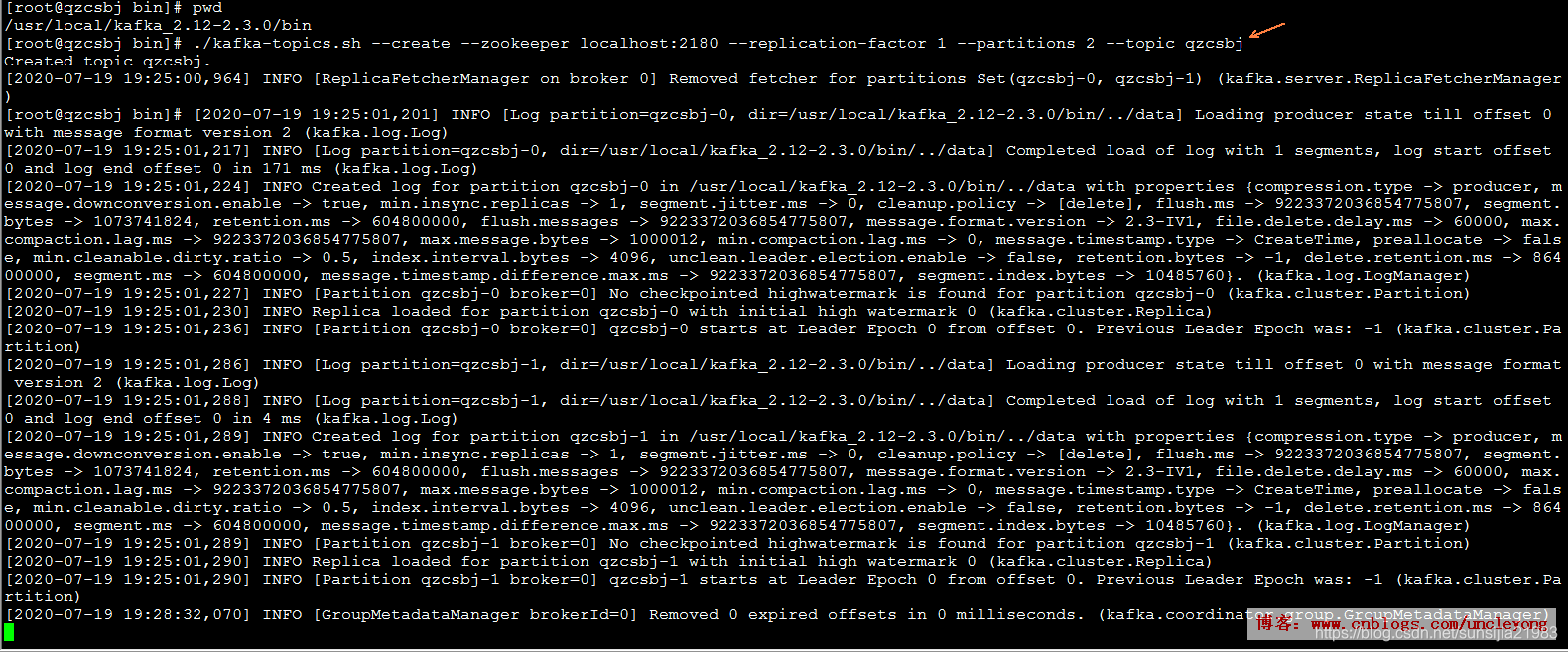
创建Topic
./kafka-topics.sh --create --zookeeper localhost:2180 --replication-factor 1 --partitions 2 --topic qzcsbj
查看Topic列表
./kafka-topics.sh --list --zookeeper localhost:2180

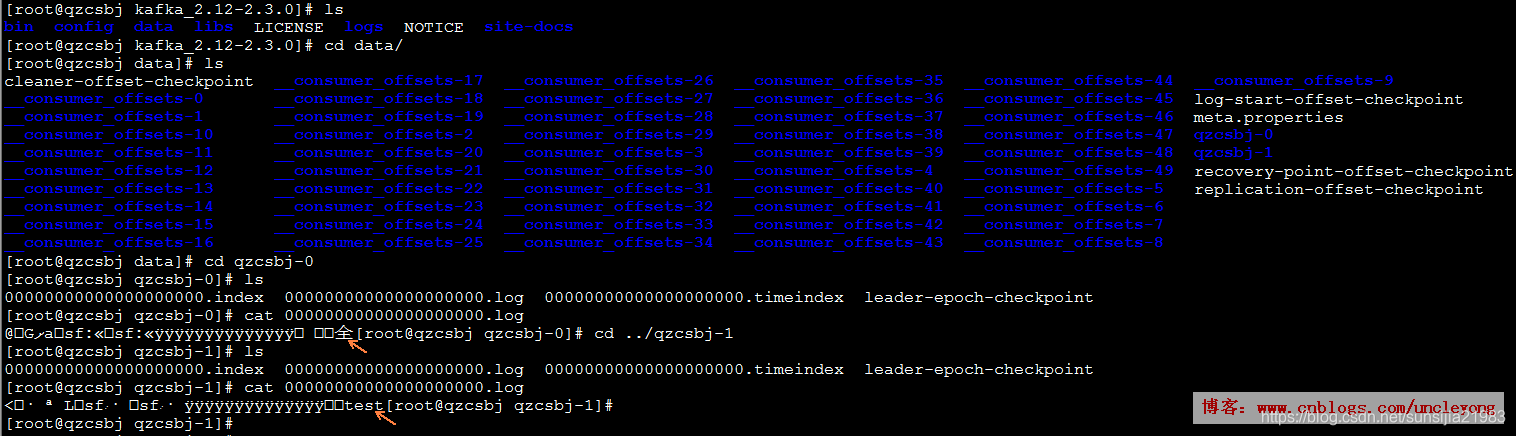
查看分区
/usr/local/kafka_2.13-2.7.0/data

启动kafka的生产者,发送消息:全栈
./kafka-console-producer.sh --broker-list localhost:9092 --topic qzcsbj

启动kafka的消费者
消费者1
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic qzcsbj --from-beginning

消费者2
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic qzcsbj

生产者再次发送消息:test

消费者1取消息

消费者2取消息

消息存在分区里面了



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











