




 本文详细介绍了MySQL数据库的基础知识,包括其历史背景、版本区分、数据类型、SQL语句分类,以及如何创建、修改和查询数据库。深入探讨了数据库范式、SQL查询技巧和表结构优化,适合初学者和进阶学习者。
本文详细介绍了MySQL数据库的基础知识,包括其历史背景、版本区分、数据类型、SQL语句分类,以及如何创建、修改和查询数据库。深入探讨了数据库范式、SQL查询技巧和表结构优化,适合初学者和进阶学习者。
1. MySQL基础
1.1. MySQL介绍
- MySQL目前属于Oracle甲骨文公司,大家熟悉的关系型数据库有微软的SQL Server,甲骨文的Oracle和MySQL
- MySQL分为企业版和社区版,其中社区版是完全免费并且开源的
- MySQL和其它关系型数据库有一个非常大的区别,就是支持可更换的插件式的存储引擎,其中InnoDB非常强大
- 目前goole、淘宝、百度、腾讯、新浪、facebook等大公司都在使用MySQL作为数据存储层方案
1.2. SQL基础
SQL是结构化查询语言的缩写(Structure Query Language),它是关系型数据库的通用语言,非常强大,可以非常高效的进行数据库的增删改查操作,SQL+索引更是可以实现带各种附加条件的高效率查询操作。
SQL 语句主要可以划分为以下 3 个类别:
DDL(Data Definition Languages)语句:数据定义语言,这些语句定义了不同的数据库、表、列、索引等数据库对象的定义。常用的语句关键字主要包括 create、drop、alter等。
DML(Data Manipulation Language)语句:数据操纵语句,用于添加、删除、更新和查询数据库记录,并检查数据完整性,常用的语句关键字主要包括 insert、delete、update 和select 等。
DCL(Data Control Language)语句:数据控制语句,用于控制不同数据段直接的许可和访问级别的语句。这些语句定义了数据库、表、字段、用户的访问权限和安全级别。主要的语句关键字包括 grant、revoke 等。
1.3. MySQL数据类型
MySQL作为关系型数据库,在二维表中存数据,肯定要规定数据的类型,类型规定了数据的大小,因此使用的时候选择合适的类型,不仅会降低表占用的磁盘空间,间接减少了磁盘I/O的次数,提高了表的访问效率,而且索引的效率也和数据的类型息息相关。
1.3.1. 数值类型
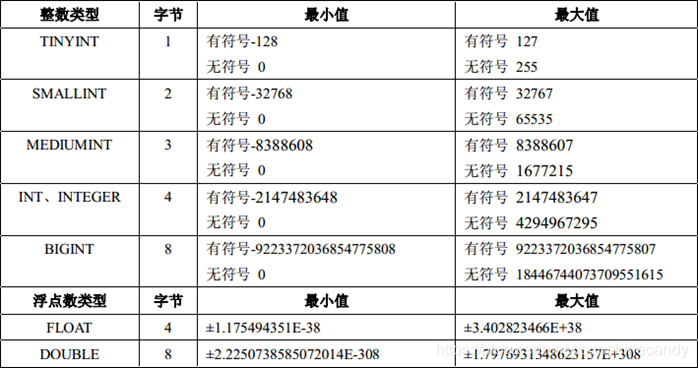
上图主要列出了整数类型和浮点数类型,在实际使用中,根据具体的场景选择合适的数据类型很重要!
1.3.2. 日期和时间类型

日期类型也是做项目过程中,经常使用的类型信息,尤其是TIMESTAMP和DATETIME两个类型,但是注意TIMESTAMP会自动更新时间,非常适合那些需要记录最新更新时间的场景,而DATETIME需要手动更新。
1.3.3. 字符串类型
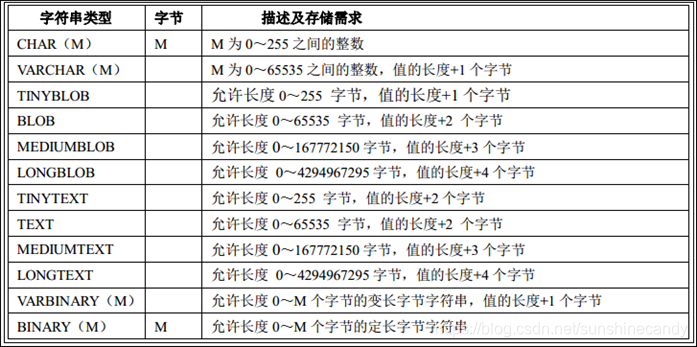
字符串类型应该是使用最多的了,首先注意char和varchar的区别,然后注意TEXT和BLOB的区别,一般的字符串类型,我们选择varchar类型就可以了,如像博客之类,数据量比较大的类型就选择TEXT或者BLOB,但是TEXT只能存文本,而BLOB还可以存储二进制文件,比如图片等。
1.3.4. enum枚举类型和set集合类型
注意,这两个类型,都是限制该字段只能取固定的值,但是枚举字段只能取一个唯一的值,而集合字段可以取任意个值。
1.4. MySQL运算符
MySQL的运算符和Java语言很多运算符的含义是一样的,但也有区别,运算符多用在SQL语句当中,对SQL查询做各种条件过滤的。
-
算数运算符
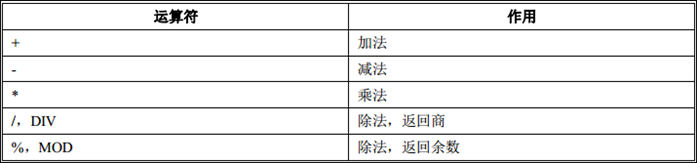
-
逻辑运算符
NOT逻辑非 AND逻辑与 OR逻辑或 -
比较运算符
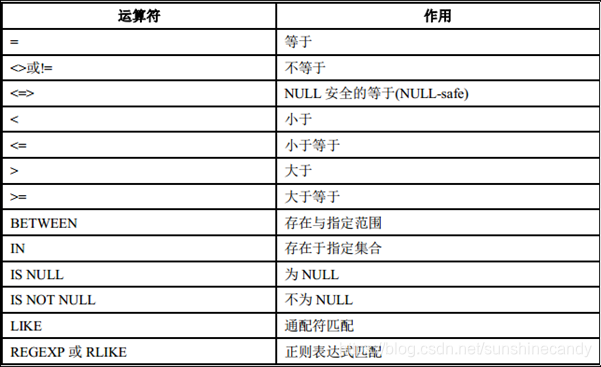
举几个SQL示例,使用以上种类的运算符,如下:
//使用算数运算符,把tcount_tbl表中所有记录的runoob_count字段更新,在原来的值上加1
update tcount_tbl set runoob_count=runoob_count+1;
//使用逻辑运算符and和关系运算符>=,把成绩及格的学生信息获取出来
select a.id a.name a.age a.sex from runoob_user a inner join runoob_score b on a.id = b.id and b.average>60.0;
1.5. 数据库范式
应用数据库范式可以带来许多好处,但是最重要的好处归结为三点:
1)减少数据冗余(这是最主要的好处,其他好处都是由此而附带的)
2)消除异常(插入异常,更新异常,删除异常)
3)让数据组织的更加和谐…
但是数据库范式绝对不是越高越好,范式越高,意味着表越多,多表联合查询的机率就越大,SQL的效率就变低。
-
第一范式(1NF) 每一列保持原子特性
列都是基本数据项,不能够再进行分割,否则设计成一对多的实体关系。例如表中的地址字段,可以再细分为省,市,区等不可再分割(即原子特性)的字段,如下:
(图1)
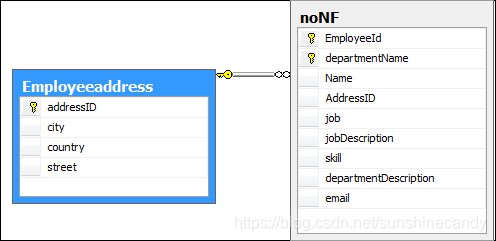
上图的表就是把地址字段分成更详细的city,country,street三个字段,注意,不符合第一范式不能称作关系型数据库。 -
第二范式(2NF) 属性完全依赖于主键(主要针对联合主键)
非主属性完全依赖于主关键字,如果不是完全依赖主键,应该拆分成新的实体,设计成一对多的实体关系。
示例:选课关系表为SelectCourse(学号, 姓名, 年龄, 课程名称, 成绩, 学分),(学号,课程名称)是联合主键,但是学分字段只和课程名称有关,和学号无关,相当于只依赖联合主键的其中一个字段,不符合第二范式。
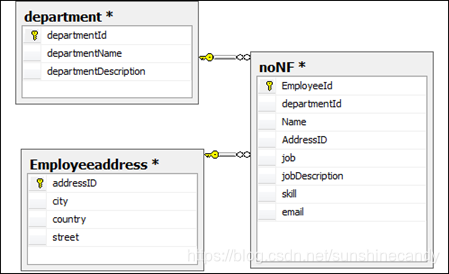
图(2) 《= 图(1) -
第三范式(3NF) 属性不依赖于其它非主属性
要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。
示例:学生关系表为Student(学号, 姓名, 年龄, 所在学院, 学院地点, 学院电话),学号是主键,但是学院电话只依赖于所在学院,并不依赖于主键学号,因此该设计不符合第三范式,应该把学院专门设计成一张表,学生表和学院表,两个是一对多的关系。
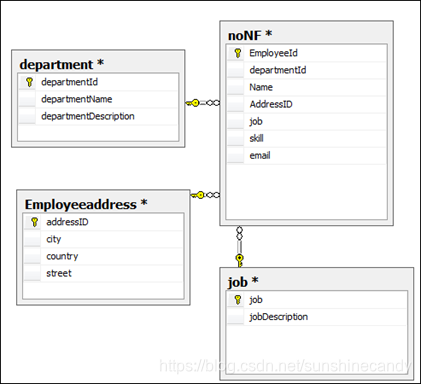
图(3) 《= 图(2)
注意:一般关系型数据库满足第三范式就可以了! -
BC范式(BCNF) 每个表中只有一个候选键
简单的说,BC范式是在第三范式的基础上的一种特殊情况,即每个表中只有一个候选键(在一个数据库中每行的值都不相同,则可称为候选键),在上面第三范式的noNF表(上面图3)中可以看出,每一个员工的email都是唯一的(不可能两个人用同一个email),则此表不符合BC范式,对其进行BC范式化后的关系图为:
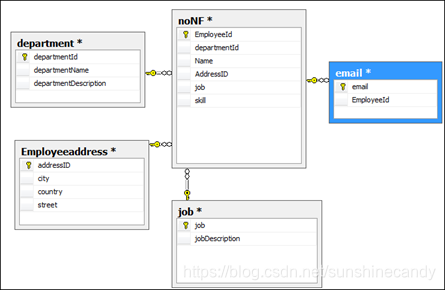
图(4) 《= 图(3) -
第四范式(4NF) 消除表中的多值依赖
简单来说,第四范式就是要消除表中的多值依赖,也就是说可以减少维护数据一致性的工作。比如图4中的noNF表中的skill技能这个字段,有的人是“java,mysql”,有的人描述的是“Java,MySQL”,这样数据就不一致了,解决办法就是将多值属性放入一个新表,所以满足第四范式的关系图如下:
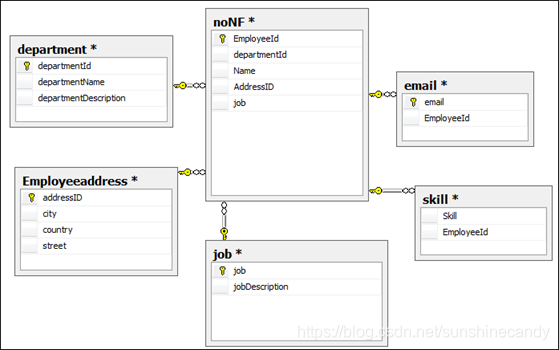
图(5) 《= 图4
从上面对于数据库范式进行分解的过程中不难看出,应用的范式越高,表越多。表多会带来很多问题:
1 查询时需要连接多个表,增加了SQL查询的复杂度
2 查询时需要连接多个表,降低了数据库查询性能
因此,并不是应用的范式越高越好,要看实际情况而定。第三范式已经很大程度上减少了数据冗余,并且基本预防了数据插入异常,更新异常,和删除异常了。
2.基本操作
2.1. 创建表(数据库)
2.1.1创建数据库
create database <数据库名>
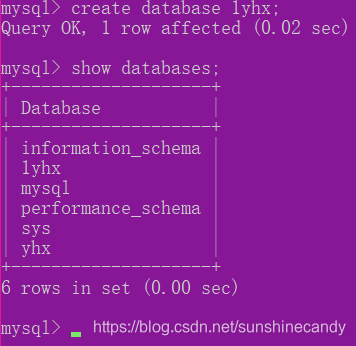
2.1.2删除数据库
drop database <数据库名>
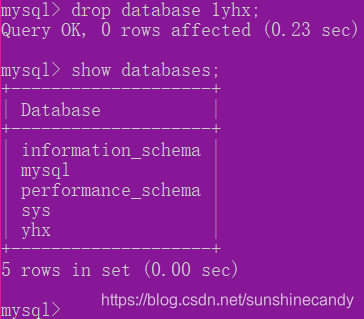
2.1.3打开并使用数据库
use <数据库名字>;
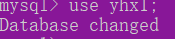
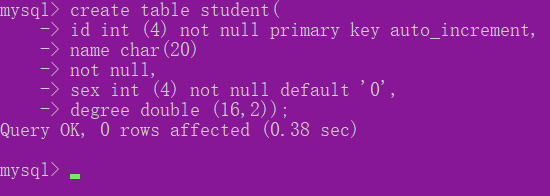
2.1.4创建表的SQL语句格式如下:
CREATE TABLE 表名(属性名 数据类型 [完整性约束条件],
属性名 数据类型 [完整性约束条件],
…
属性名 数据类型 [完整性约束条件]
);
注意,创建表结构的时候,要选择合适的数据类型,而且还可以给字段添加完整性约束条件,比如主键,非空键,唯一键等。完整性约束条件都有哪些呢,如下所示:
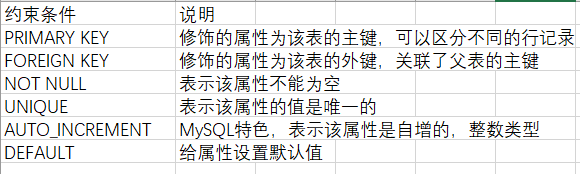
2.2. 查看表(数据库)
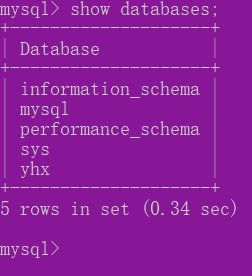
2.2.1查看数据库
show databases;
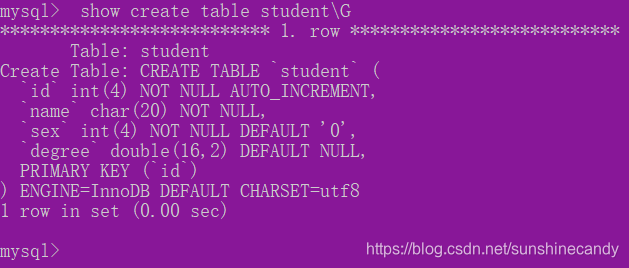
2.2.2查看表
desc Table_name;

2. show create table Table_name\G (SQL语句可以用;号或者\G结尾,\G结尾打印的格式更清晰)
2.3. 修改表
如果表在使用的过程中,逐渐发现表的字段不满足设计要求,而且表中已添加大量数据,此时想添加新的字段或者删除已有的字段,可以通过alter命令操作,如下是常用的alter命令(但是最好还是设计之初,分析好应用场景,一次性设计好表的结构):
2.3.1修改表名:
ALTER TABLE 旧表名 RENAME [TO] 新表名;
没有to;
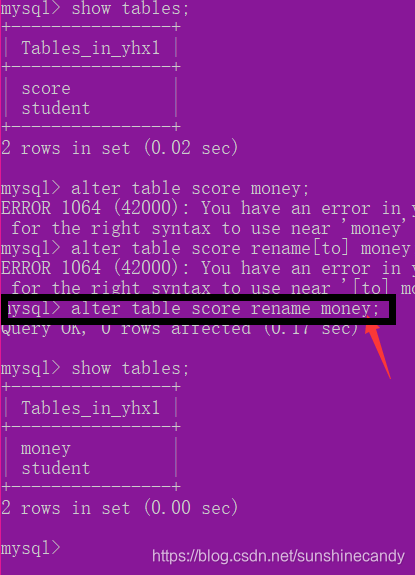
2.3.2修改字段的数据类型:
ALTER TABLE 表名 MODIFY 属性名 数据类型;
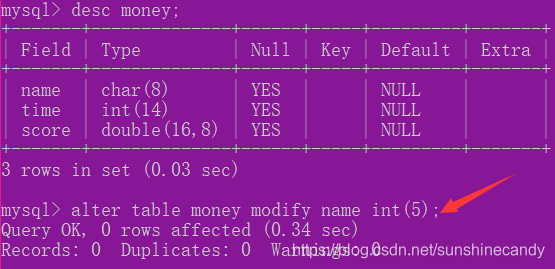

2.3.3修改字段名:
ALTER TABLE 表名 CHANGE 旧属性名 新属性名 新数据类型;
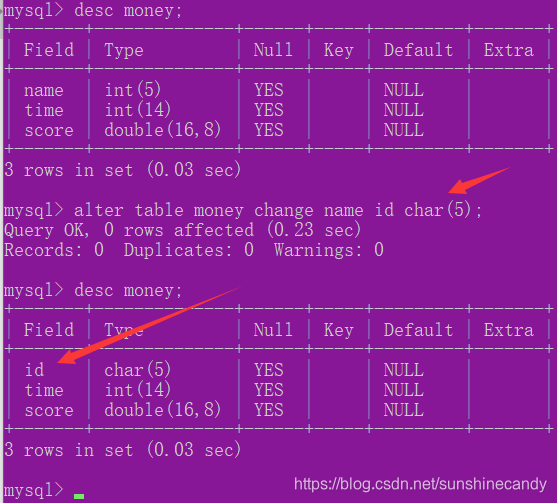
2.3.4增加字段:
ALTER TABLE 表名 ADD 属性名1 数据类型 [完整性约束条件] [FIRST | AFTER 属性名2];
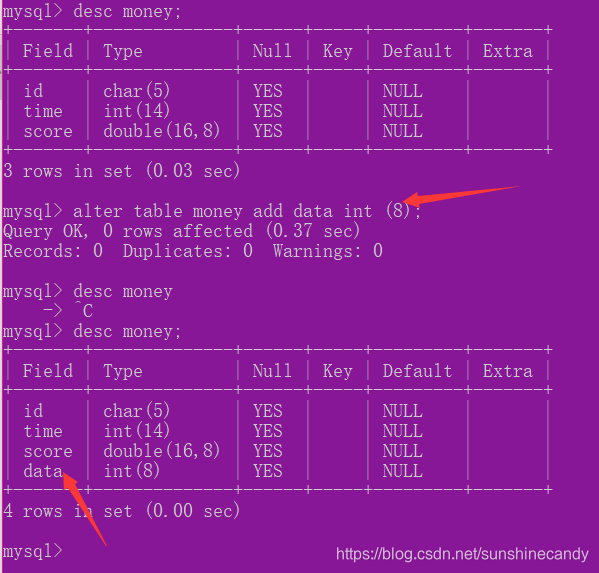
2.3.5删除字段:
ALTER TABLE 表名 DROP 属性名;
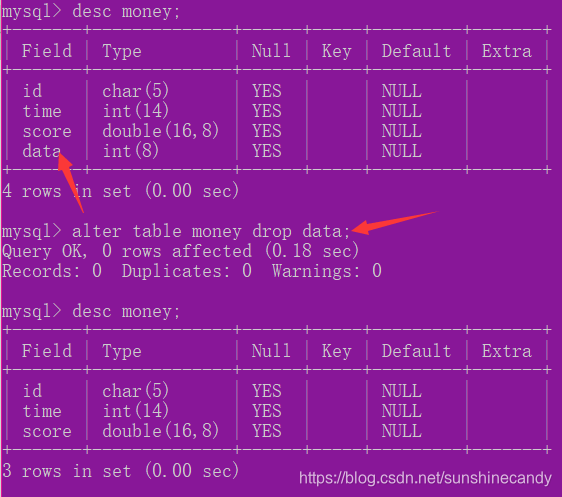
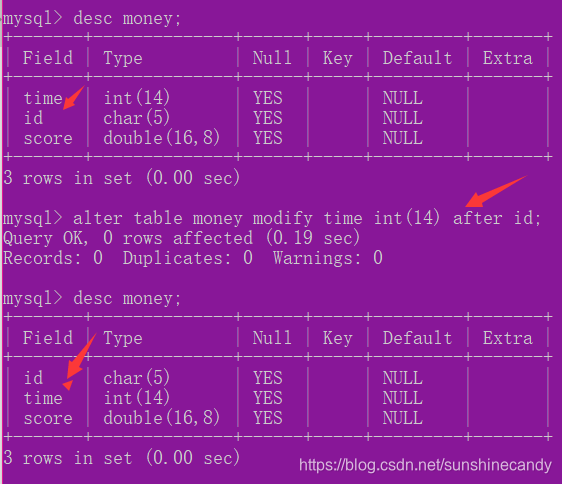
2.3.6修改字段排列位置:
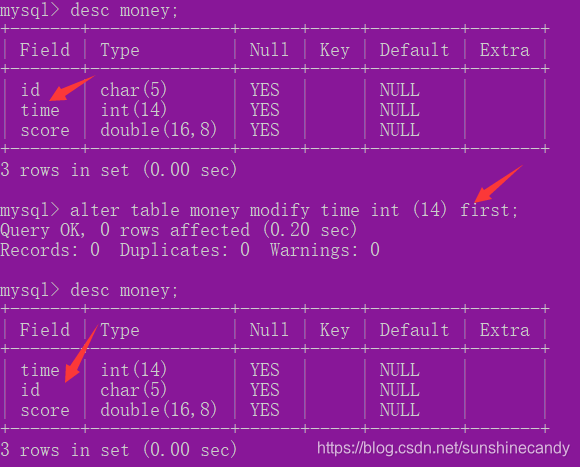
ALTER TABLE 表名 MODIFY 属性名1 数据类型 FIRST //将属性1放到表的第一个位置
ALTER TABLE 表名 MODIFY 属性名1 数据类型 AFTER 属性名2;//将1放到2的后面;
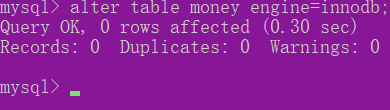
2.3.7修改表的存储引擎:
ALTER TABLE 表名 ENGINE=InnoDB | MyISAM;
查看存储引擎;
2.4. 查询表
SQL的基本查询结构如下:
SELECT 属性列表
FROM 表名
[WHERE 条件表达式1]
[GROUP BY 属性名1 [HAVING 条件表达式2]]
[ORDER BY 属性名2 [ASC | DESC]]
着重常用的SQL查询
不同的查询是怎么使用索引的
-
带in的子查询
[NOT] IN (元素1,元素2,…,元素n)
如:select * from user where id in (select stu_id from grade where average>=60.0);
问题:多表联合查询选择子查询好还是连接查询好? -
带BETWEEN AND的范围查询
[NOT] BETWEEN 取值1 AND 取值2
如:select * from user inner join grade on user.id = grade.id where average between 80.0 and 100.0; -
带like的通配符匹配查询
[NOT] LIKE ‘字符串’
注意此处LIKE后面的字符串可以携带通配符
% : 表示0个或任意长度的字符串
_ :只能表示单个字符
如:select * from news where content like “%亚运会%”; -
空值查询
IS [NOT] NULL;
如:select * from user a left join grade b on a.id = b.userid where b.id is NULL; -
带AND的多条件查询
条件表达式1 AND 条件表达式2 [… AND 条件表达式n]
如:select * from user inner join grade on user.id = grade.id where average between 80.0 and 100.0 and user.sex=’男’; -
带OR的多条件查询
条件表达式1 OR 条件表达式2 [… OR 条件表达式n]
如:select * from user inner join grade on user.id = grade.id where grade.math>80.0 or grade.english>80.0; -
去重复查询
SELECT DISTINCT 属性名
如:select distinct name from user ;
问题:DISTINCT和GROUP BY都能够用来去重,有什么区别呢? -
对结果排序
ORDER BY 属性名 [ASC | DESC]
如:select * from user inner join grade on user.id = grade.id where average between 80.0 and 100.0 order by average desc; -
分组查询
GROUP BY 属性名 [HAVING 条件表达式]
如:select name, count(*) from record group by id; -
union合并查询
SELECT expression1, expression2, … expression_n
FROM tables[WHERE conditions]
UNION [ALL | DISTINCT] 注意:union默认去重,不用修饰distinct,all表示显示所有重复值
SELECT expression1, expression2, … expression_n
FROM tables[WHERE conditions];
如:SELECT country FROM Websites UNION ALL SELECT country FROM apps ORDER BY country; -
Limit分页查询
不指定初始位置是LIMIT 记录数;指定初始位置是LIMIT 初始位置, 记录数。
如:select * from user limit 10, 20; -
内连接和外连接查询
内连接查询:
SELECT a.属性名1,a.属性名2,…,b,属性名1,b.属性名2… FROM table_name1 a, table_name2 b on a.id = b.id where a.属性名 满足某些条件;
SELECT a.属性名1,a.属性名2,…,b,属性名1,b.属性名2… FROM table_name1 a inner join table_name2 b on a.id = b.id where a.属性名 满足某些条件;
如:select a.id,b.average,c.address from user a inner join grade b on a.id = b.userid
inner join info c on a.id = c.userid
where b.average>=60.0;
外连接查询
[左连接查询]
SELECT a.属性名列表, b.属性名列表 FROM table_name1 a [OUTER] LEFT JOIN table_name2 b on a.id = b.id;
[右连接查询]
SELECT a.属性名列表, b.属性名列表 FROM table_name1 a [OUTER] RIGHT JOIN table_name2 b on a.id = b.id;
我们一般都会用连接查询代替in子查询进行多表联合查询,子查询的效率远不及连接查询效率高!
以上基本包含了所有常用到的SQL查询相关语句,尤其是连接查询,一定要熟练应用!
2.5. 设置表的字符编码
1.查看字符编码格式
mysql> show variables like ‘charac%’;
2.设置编码方式为utf8
mysql> set character_set_server=utf8;


















 8691
8691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











