









Langchain是什么?
想象一下,如果你能让聊天机器人不仅仅回答通用问题,还能从你自己的数据库或文件中提取信息,并根据这些信息执行具体操作,比如发邮件,那会是什么情况?Langchain 正是为了实现这一目标而诞生的。
Langchain 是一个开源框架,它允许开发人员将像 GPT-4 这样的大型语言模型与外部的计算和数据源结合起来。
LangChain 是一个用于开发由语言模型驱动的应用程序的框架。
Langchain,这是一个用于提升大型语言模型(LLMs)功能的框架。
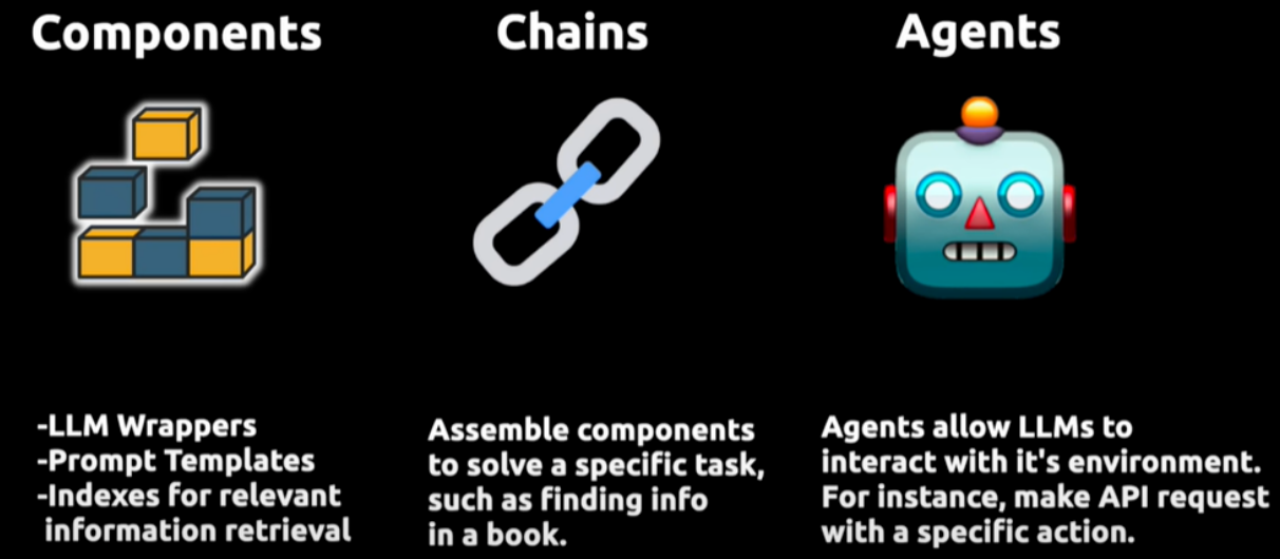
它通过三个核心组件实现增强:
首先是 Compents“组件”,为LLMs提供接口封装、模板提示和信息检索索引;
其次是 Chains“链”,它将不同的组件组合起来解决特定的任务,比如在大量文本中查找信息;
最后是 Agents“代理”,它们使得LLMs能够与外部环境进行交互,例如通过API请求执行操作。
LangChain库主要由以下几个不同的包组成:
langchain-core:基础抽象和LangChain表达语言;
langchain-community:第三方集成,主要包括langchain集成的第三方组件;
langchain:主要包括链(chain)、代理(agent)和检索策略;
为什么要用Langchain
数据连接:Langchain 允许你将大型语言模型连接到你自己的数据源,比如数据库、PDF文件或其他文档。这意味着你可以使模型从你的私有数据中提取信息。
行动执行:不仅可以提取信息,Langchain 还可以帮助你根据这些信息执行特定操作,如发送邮件。
Langchain的核心
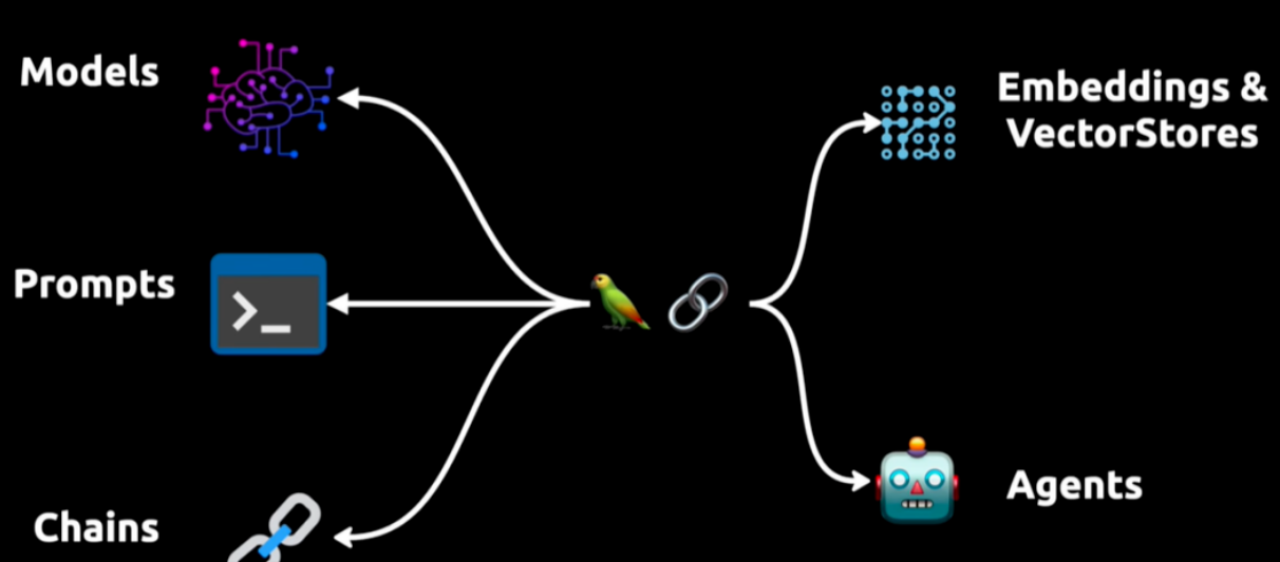
模型 Models:包装器允许你连接到大型语言模型,如 GPT-4 或 Hugging Face 也包括GLM 提供的模型。
Prompt Templates:这些模板让你避免硬编码文本输入。你可以动态地将用户输入插入到模板中,并发送给语言模型。
Chains:链允许你将多个组件组合在一起,解决特定的任务,并构建完整的语言模型应用程序。
Agents:代理允许语言模型与外部API交互。
Embedding 嵌入与向量存储 VectorStore 是数据表示和检索的手段,为模型提供必要的语言理解基础。
Indexes:索引帮助你从语言模型中提取相关信息。
Langchain的底层原理
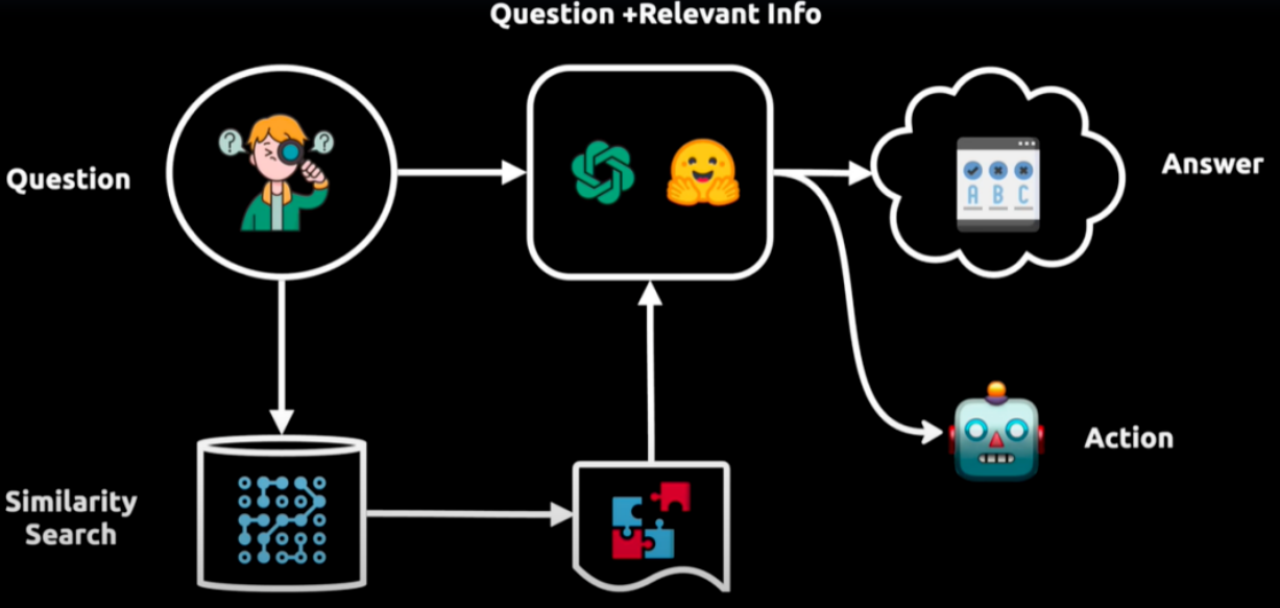
举例:如上图所示展示了一个智能问答系统的工作流程。
从用户提出的问题(Question)开始,然后通过相似性搜索(Similarity Search)在一个大型数据库或向量空间中找到与之相关的信息。
得到的信息与原始问题结合后,由一个处理模型分析,以产生一个答案(Answer)。
这个答案接着被用来指导一个代理采取行动(Action),这个代理可能会执行一个API调用或与外部系统交互以完成任务。
整个流程反映了数据驱动的决策过程,其中包含了从信息检索到处理,再到最终行动的自动化步骤。
Langchain的应用场景
Langchain 的应用场景非常广泛,包括但不限于:
个人助手:可以帮助预订航班、转账、缴税等。
学习辅助:可以参考整个课程大纲,帮助你更快地学习材料。
数据分析和数据科学:连接到公司的客户数据或市场数据,极大地促进数据分析的进展。
LangSmith是什么?
是一个用于构建生产级 LLM 应用程序的平台,它提供了调试、测试、评估和监控基于任何 LLM 框架构建的链和智能代理的功能,并能与 LangChain 无缝集成。其主要作用包括
调试与测试:通过记录langchain构建的大模型应用的中间过程,开发者可以更好地调整提示词等中间过程,优化模型响应。
评估应用效果:langsmith可以量化评估基于大模型的系统的效果,帮助开发者发现潜在问题并进行优化。
监控应用性能:实时监控应用程序的运行情况,及时发现异常和错误,确保其稳定性和可靠性。
数据管理与分析:对大语言模型此次的运行的输入与输出进行存储和分析,以便开发者更好地理解模型行为和优化应用。
团队协作:支持团队成员之间的协作,方便共享和讨论提示模板等。
可扩展性与维护性:设计时考虑了应用程序的可扩展性和长期维护,允许开发者构建可成长的系统。
LangSmith是LangChain的一个子产品,是一个大模型应用开发平台。它提供了从原型到生产的全流程工具和服务,帮助开发者构建、测试、评估和监控基于LangChain或其他 LLM 框架的应用程序。
注册🔗:https://smith.langchain.com/
确保设置环境变量以开始记录跟踪:
export LANGCHAIN_TRACING_V2="true"
export LANGCHAIN_API_KEY="..."或者代码里设置
import os
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_API_KEY'] = ''deepseek注册获取apikey
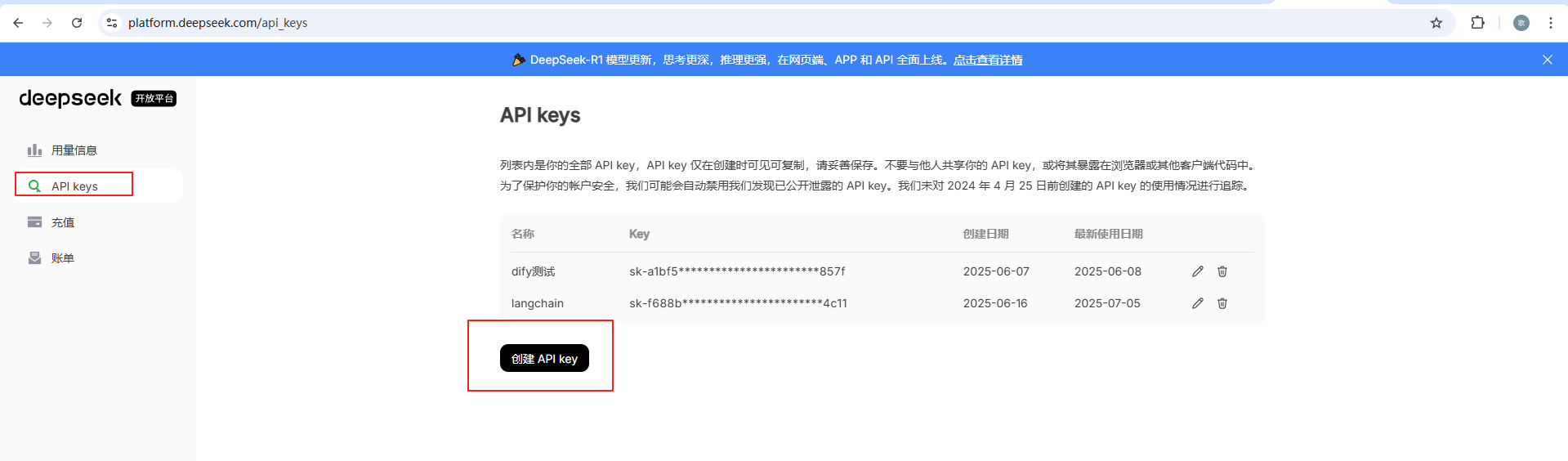
DeepSeek | 深度求索 进入deepseek官网,注册并登陆

进入api开放平台,点击API keys进入api keys管理页面,点击创建 API key,既可以创建api key了,deepseek是收费的,需要充值才可使用,不过很便宜冲10块钱可以用很久
连接AI⼤模型
安装openai和langchain
pip install openai
pip install langchain-openai
pip install langchainlangchain对于调用大模型的封装
OpenAI:
from langchain_openai import OpenAI
chat = OpenAI(
api_key="",
base_url="https://api.deepseek.com",
model="deepseek-chat"
)
ChatOpenAI 聊天模型集成:
from langchain_openai import ChatOpenAI
deepseek_llm = ChatOpenAI(
model="deepseek-reasoner",
api_key="", #app_key可以从官方注册获得
base_url="https://api.deepseek.com", #
)在langchain_openai库中,OpenAI和ChatOpenAI存在以下方面的区别:
OpenAI:这个类主要对应OpenAI的基于完成(completion)方式的模型,例如早期的GPT - 3系列模型(像text - davinci - 003 )。这类模型的工作方式是接收一段文本输入,然后根据输入内容生成后续的文本,以完成给定的任务。
ChatOpenAI:它对应的是OpenAI的聊天模型,比如GPT - 3.5 Turbo、GPT - 4等。这些聊天模型以对话的形式进行交互,更适合处理多轮对话场景,能更好地理解上下文信息。
在构建ChatOpenAI|OpenAI时,我们有⼀些标准化参数:
-
model : 模型名称
-
temperature : 采样温度
-
timeout : 请求超时
-
max_tokens : ⽣成的最⼤令牌数
-
stop : 默认停⽌序列
-
max_retries : 请求重试的最⼤次数
-
api_key : ⼤模型供应商的API密钥
-
base_url : 发送请求的端点
⼀些重要事项需要注意:
• 标准参数仅适⽤于公开具有预期功能的参数的⼤模型供应商。例如,⼀些⼤模型供应商不公开最⼤输出令牌的配置,因此在这些⼤模型供应商上⽆法⽀持max_tokens。
• 标准参数⽬前仅在具有⾃⼰集成包的集成上强制执⾏(例如 langchain-openai 、 langchain-anthropic 等),在 langchain-community 中的模型上不强制执⾏。
ChatOpenAI|OpenAI有一些标准事件:
Invoke: 模型主要调用方法,输入list输出list
stream: 流式输出方法
batch: 批量模型请求方法
bind_tools: 在模型执行的时候绑定工具
with_structured_output: 基于invoke的结构 化输出其他有用事件
ainvoke: 异步调用模型方法
astream: 异步流式输出
abatch: 异步的批量处理
astream_events: 异步流事件
with_retry: 调用失败时重试
with_fallback:失败恢复事件
configurble_fields:模型运行时的运行参数
OpenAI示例:
我这里使用deepseek,其它大模型类似
from langchain_openai import OpenAI
from model.deepseek import deepseek_llm
chat = OpenAI(
api_key="",
base_url="https://api.deepseek.com",
model="deepseek-chat"
)
resp = deepseek_llm.invoke("请将我爱吃苹果翻译成英文")
print(resp.content)"I love eating apples."
如果需要更简洁的表达,也可以说:
"I like apples." (我喜欢苹果。)
根据具体语境选择合适的翻译即可。
ChatOpenAI案例
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_openai import ChatOpenAI
chat = ChatOpenAI(
api_key="", #使用自己的apikey即可
base_url="https://api.deepseek.com",
model="deepseek-chat"
)
messages = [
SystemMessage(content="你是一个翻译助手,请将用户的输入翻译成英文"),
HumanMessage(content="{input}")
]
while True:
input_text = input("请输入要翻译的文本:")
if input_text == "exit":
break
messages.append(HumanMessage(content=input_text))
resp = chat.invoke(messages)
print("翻译后的文本:", resp.content)
请输入要翻译的文本:我爱吃苹果
翻译后的文本: I love eating apples.
请输入要翻译的文本:exit
Process finished with exit code 0OpenAI 和 ChatOpenAI区别
langchain_openai 中的 OpenAI 和 ChatOpenAI 有以下几方面的区别:
对应模型及交互机制
对应模型
OpenAI:主要对应 OpenAI 传统的基于文本完成(text completion)的模型,像 text - davinci - 003。这类模型接收一个文本提示,然后生成一段连续的文本以完成提示所要求的内容。
ChatOpenAI:对应 OpenAI 的聊天模型,如 gpt - 3.5 - turbo、gpt - 4 等。这些模型专为对话场景设计,能更好地处理多轮交互中的上下文信息。
交互机制
OpenAI:交互是基于单一提示的文本生成。开发者提供一个提示字符串,模型基于此生成文本。例如,给出一段文章开头,让模型续写。
ChatOpenAI:采用消息列表进行交互,列表中包含不同角色(如用户、AI 助手)的消息,能模拟真实对话流程,更自然地处理多轮对话。
代码调用与参数设置
代码调用形式
OpenAI:调用时传入提示字符串,返回生成的文本。
ChatOpenAI:需要传入消息列表,返回消息对象,可通过访问其 content 属性获取文本。
参数侧重点
OpenAI:除常见的 API 密钥、模型名称外,可能更关注与文本生成长度、温度(随机性)等影响文本完成的参数。
ChatOpenAI:在基础参数外,可能更关注如何管理对话上下文、消息角色等与对话相关的设置。
适用场景
OpenAI
适用于需要生成连续、完整文本的场景,如文章撰写、文案创作、故事生成等,不需要过多上下文交互的任务。
ChatOpenAI
非常适合构建聊天机器人、智能客服系统、交互式问答平台等需要处理多轮对话和上下文理解的应用。
性能与成本
性能
OpenAI:基于文本完成的模型在某些长文本生成和特定领域知识输出上可能表现较好,但对于多轮对话的上下文管理能力较弱。
ChatOpenAI:聊天模型在对话场景中性能更优,能理解和保持对话上下文,提供更连贯、自然的回复。
成本
OpenAI:传统完成模型的使用成本可能因模型大小和生成文本长度而异,对于长文本生成可能成本较高。
ChatOpenAI:聊天模型通常按令牌(token)计费,在多轮对话中,如果能有效控制令牌使用,成本可能更可控。
使用stream流式示例:
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI, OpenAI
from model.config import BAILIAN_API_KEY, BAILIAN_BASE_URL
from langchain_core.output_parsers import BaseOutputParser
llm = ChatOpenAI(
model="qwen-max",
temperature=0.9,
base_url=BAILIAN_BASE_URL,
api_key=BAILIAN_API_KEY
)
prompt = PromptTemplate.from_template("""
你是一个起名大师,请模仿示例起三个{country}名字,比如男孩被叫做{boy_name},女孩被叫做{girl_name}。请返回以逗号分隔的名字列表。仅返回名字列表,不要返回其他任何内容。""")
msg = prompt.format(country="中国", boy_name="小明", girl_name="小红")
#stream
for chunk in llm.stream(msg):
print(chunk.content, end="")小刚,小丽,小华
Process finished with exit code 0batch示例:
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI, OpenAI
from model.config import BAILIAN_API_KEY, BAILIAN_BASE_URL
from langchain_core.output_parsers import BaseOutputParser
class CommaSeparatedListOutputParser(BaseOutputParser):
def parse(self, text: str):
return text.strip().split(",")
llm = ChatOpenAI(
model="qwen-max",
temperature=0.9,
base_url=BAILIAN_BASE_URL,
api_key=BAILIAN_API_KEY
)
prompt = PromptTemplate.from_template("""
你是一个起名大师,请模仿示例起三个{country}名字,比如男孩被叫做{boy_name},女孩被叫做{girl_name}。请返回以逗号分隔的名字列表。仅返回名字列表,不要返回其他任何内容。""")
msg = prompt.format(country="中国", boy_name="小明", girl_name="小红")
#batch
batch_result = llm.batch(['你是谁?', msg])
for result in batch_result:
print(result.content)我是Qwen,由阿里云开发的超大规模语言模型。我的目标是成为一款能够帮助用户提高效率、激发创意并解决问题的AI助手。无论是生成文本、解答问题还是提供灵感,我都在不断努力提升自己的能力。有什么我可以帮到你的吗?
小亮,小花,小斌使用stream_evebts
import asyncio
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI, OpenAI
from model.config import BAILIAN_API_KEY, BAILIAN_BASE_URL
from langchain_core.output_parsers import BaseOutputParser
class CommaSeparatedListOutputParser(BaseOutputParser):
def parse(self, text: str):
return text.strip().split(",")
llm = ChatOpenAI(
model="qwen-max",
temperature=0.9,
base_url=BAILIAN_BASE_URL,
api_key=BAILIAN_API_KEY
)
prompt = PromptTemplate.from_template("""
你是一个起名大师,请模仿示例起三个{country}名字,比如男孩被叫做{boy_name},女孩被叫做{girl_name}。请返回以逗号分隔的名字列表。仅返回名字列表,不要返回其他任何内容。""")
msg = prompt.format(country="中国", boy_name="小明", girl_name="小红")
# stream_events
async def test():
async for chunk in llm.astream_events(msg, version="v2"):
print(chunk)
if chunk["event"] == "on_chat_model_end":
print(chunk["data"]["output"].content, end="")
if __name__ == '__main__':
asyncio.run(test())C:\Users\sunqz\AppData\Local\Microsoft\WindowsApps\python3.11.exe D:\ai_workspace\ai-learning-python-repository\langchain-demo\lianxi\api\起名大师.py
{'event': 'on_chat_model_start', 'data': {'input': '\n你是一个起名大师,请模仿示例起三个中国名字,比如男孩被叫做小明,女孩被叫做小红。请返回以逗号分隔的名字列表。仅返回名字列表,不要返回其他任何内容。'}, 'name': 'ChatOpenAI', 'tags': [], 'run_id': 'd7235afa-fc7c-42ed-b887-1240f2b289eb', 'metadata': {'ls_provider': 'openai', 'ls_model_name': 'qwen-max', 'ls_model_type': 'chat', 'ls_temperature': 0.9}, 'parent_ids': []}
{'event': 'on_chat_model_stream', 'run_id': 'd7235afa-fc7c-42ed-b887-1240f2b289eb', 'name': 'ChatOpenAI', 'tags': [], 'metadata': {'ls_provider': 'openai', 'ls_model_name': 'qwen-max', 'ls_model_type': 'chat', 'ls_temperature': 0.9}, 'data': {'chunk': AIMessageChunk(content='', additional_kwargs={}, response_metadata={}, id='run--d7235afa-fc7c-42ed-b887-1240f2b289eb')}, 'parent_ids': []}
{'event': 'on_chat_model_stream', 'run_id': 'd7235afa-fc7c-42ed-b887-1240f2b289eb', 'name': 'ChatOpenAI', 'tags': [], 'metadata': {'ls_provider': 'openai', 'ls_model_name': 'qwen-max', 'ls_model_type': 'chat', 'ls_temperature': 0.9}, 'data': {'chunk': AIMessageChunk(content='小', additional_kwargs={}, response_metadata={}, id='run--d7235afa-fc7c-42ed-b887-1240f2b289eb')}, 'parent_ids': []}
{'event': 'on_chat_model_stream', 'run_id': 'd7235afa-fc7c-42ed-b887-1240f2b289eb', 'name': 'ChatOpenAI', 'tags': [], 'metadata': {'ls_provider': 'openai', 'ls_model_name': 'qwen-max', 'ls_model_type': 'chat', 'ls_temperature': 0.9}, 'data': {'chunk': AIMessageChunk(content='亮', additional_kwargs={}, response_metadata={}, id='run--d7235afa-fc7c-42ed-b887-1240f2b289eb')}, 'parent_ids': []}
{'event': 'on_chat_model_stream', 'run_id': 'd7235afa-fc7c-42ed-b887-1240f2b289eb', 'name': 'ChatOpenAI', 'tags': [], 'metadata': {'ls_provider': 'openai', 'ls_model_name': 'qwen-max', 'ls_model_type': 'chat', 'ls_temperature': 0.9}, 'data': {'chunk': AIMessageChunk(content=',', additional_kwargs={}, response_metadata={}, id='run--d7235afa-fc7c-42ed-b887-1240f2b289eb')}, 'parent_ids': []}
{'event': 'on_chat_model_stream', 'run_id': 'd7235afa-fc7c-42ed-b887-1240f2b289eb', 'name': 'ChatOpenAI', 'tags': [], 'metadata': {'ls_provider': 'openai', 'ls_model_name': 'qwen-max', 'ls_model_type': 'chat', 'ls_temperature': 0.9}, 'data': {'chunk': AIMessageChunk(content='小', additional_kwargs={}, response_metadata={}, id='run--d7235afa-fc7c-42ed-b887-1240f2b289eb')}, 'parent_ids': []}
{'event': 'on_chat_model_stream', 'run_id': 'd7235afa-fc7c-42ed-b887-1240f2b289eb', 'name': 'ChatOpenAI', 'tags': [], 'metadata': {'ls_provider': 'openai', 'ls_model_name': 'qwen-max', 'ls_model_type': 'chat', 'ls_temperature': 0.9}, 'data': {'chunk': AIMessageChunk(content='丽,小杰', additional_kwargs={}, response_metadata={}, id='run--d7235afa-fc7c-42ed-b887-1240f2b289eb')}, 'parent_ids': []}
{'event': 'on_chat_model_stream', 'run_id': 'd7235afa-fc7c-42ed-b887-1240f2b289eb', 'name': 'ChatOpenAI', 'tags': [], 'metadata': {'ls_provider': 'openai', 'ls_model_name': 'qwen-max', 'ls_model_type': 'chat', 'ls_temperature': 0.9}, 'data': {'chunk': AIMessageChunk(content='', additional_kwargs={}, response_metadata={'finish_reason': 'stop', 'model_name': 'qwen-max'}, id='run--d7235afa-fc7c-42ed-b887-1240f2b289eb')}, 'parent_ids': []}
{'event': 'on_chat_model_end', 'data': {'output': AIMessageChunk(content='小亮,小丽,小杰', additional_kwargs={}, response_metadata={'finish_reason': 'stop', 'model_name': 'qwen-max'}, id='run--d7235afa-fc7c-42ed-b887-1240f2b289eb')}, 'run_id': 'd7235afa-fc7c-42ed-b887-1240f2b289eb', 'name': 'ChatOpenAI', 'tags': [], 'metadata': {'ls_provider': 'openai', 'ls_model_name': 'qwen-max', 'ls_model_type': 'chat', 'ls_temperature': 0.9}, 'parent_ids': []}
小亮,小丽,小杰
Process finished with exit code 0查看每次使用了多少token:
response = llm.invoke(msg)
# 查看使用token
print(response.usage_metadata){'input_tokens': 56, 'output_tokens': 8, 'total_tokens': 64, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}
增加stream_usage=True
for chunk in llm.stream(msg, stream_usage=True):
print(chunk.content, end="")
print(chunk.usage_metadata)小辉,小丽,小杰
{'input_tokens': 56, 'output_tokens': 8, 'total_tokens': 64, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}
















 2314
2314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









