




前言
在介绍Transformer模型之前,先来回顾Encoder-Decoder中的Attention。其实质上就是Encoder中隐层输出的加权和,公式如下:
ci=∑i=1Txαijhjc_i=\sum^{T_x}_{i=1}\alpha_{ij}h_jci=i=1∑Txαijhj
将Attention机制从Encoder-Decoder框架中抽出,进一步抽象化,其本质上如下图:

以机器翻译为例,我们可以将图中的Key,Value看作是source中的数据,这里的Key和Value是对应的。将图中的Query看作是target中的数据。计算Attention的整个流程大致如下:
1)计算Query和source中各个Key的相似性,得到每个Key对应的Value的权重系数。在这里我认为Key的值是source的的隐层输出,Key是等于Value的,Query是target的word embedding(这种想法保留)。
2)利用计算出来的权重系数对各个Value的值加权求和,就得到了我们的Attention的结果。
具体的公式如下:
Attention(Query,source)=∑i=1LxSimilarity(Query,Keyi)∗ValueiAttention(Query, source) = \sum_{i=1}^{L_x} Similarity(Query, Key_i) * Value_iAttention(Query,source)=i=1∑LxSimilarity(Query,Keyi)∗Valuei
其中 LxL_xLx 代表source中句子的长度。
再详细化将Attention的计算分为三个阶段,如下图

1)计算相似性,在这里计算相似性的方法有多种:点积,Cosine相似性,MLP网络等。较常用的是点积和MLP网络。
2)将计算出的相似性用softmax归一化处理。
3)计算Value值的加权和。
在这里的Attention本质上是一种对齐的方法,也可以将Attention看作是一种软寻址的方法,以权重值将target中的词和source中的词对齐。相对应软寻址(soft-Attention),还有一种hard-Attention,顾名思义就是直接用权值最大的Value值作为Attention。
Transformer
Transformer模型来源于谷歌2017年的一篇文章(Attention is all you need)。在现有的Encoder-Decoder框架中,都是基于CNN或者RNN来实现的。而Transformer模型汇中抛弃了CNN和RNN,只使用了Attention来实现。因此Transformer是一个完全基于注意力机制的Encoder-Decoder模型。在Transformer模型中引入了self-Attention这一概念,Transformer的整个架构就是叠层的self-Attention和全连接层。具体的结构如下:



Encoder
编码器接收向量的list作输入。然后将其送入self-attention处理,再之后送入前向网络,最后将输入传入下一个编码器。

当模型处理单词“it”时,self-attention允许将“it”和“animal”联系起来。当模型处理每个位置的词时,self-attention允许模型看到句子的其他位置信息作辅助线索来更好地编码当前词。
Transformer使用self-attention来将相关词的理解编码到当前词中。

第一步,根据编码器的输入向量,生成三个向量,比如,对每个词向量,生成query-vec, key-vec, value-vec,生成方法为分别乘以三个矩阵,这些矩阵在训练过程中需要学习。【注意:不是每个词向量独享3个matrix,而是所有输入共享3个转换矩阵】
注意到这些新向量的维度比输入词向量的维度要小(512–>64),并不是必须要小的,是为了让多头attention的计算更稳定。

第二步,计算attention就是计算一个分值。对“Thinking Matchines”这句话,对“Thinking”(pos#1)计算attention 分值。我们需要计算每个词与“Thinking”的评估分,这个分决定着编码“Thinking”时(某个固定位置时),每个输入词需要集中多少关注度.这个分,通过“Thing”对应query-vector与所有词的key-vec依次做点积得到。所以当我们处理位置#1时,第一个分值是q1和k1的点积,第二个分值是q1和k2的点积。

第三步和第四步,除以dimkey\sqrt{dim_{key}}dimkey,这样梯度会更稳定。然后加上softmax操作,归一化分值使得全为正数且加和为1。

softmax分值决定着在这个位置,每个词的表达程度(关注度)。很明显,这个位置的词应该有最高的归一化分数,但大部分时候总是有助于关注该词的相关的词。第五步,将softmax分值与value-vec按位相乘。保留关注词的value值,削弱非相关词的value值。
第六步,将所有加权向量加和,产生该位置的self-attention的输出结果。

上述就是self-attention的计算过程,生成的向量流入前向网络。在实际应用中,上述计算是以速度更快的矩阵形式进行的。下面我们看下在单词级别的矩阵计算。
上述的计算在计算机中实际是以矩阵的形式计算
多头机制
论文进一步增加了multi-headed的机制到self-attention上,在如下两个方面提高了attention层的效果:
- 多头机制扩展了模型集中于不同位置的能力。在上面的例子中,z1只包含了其他词的很少信息,仅由实际自己词决定。在其他情况下,比如翻译 “The animal didn’t cross the street because it was too tired”时,我们想知道单词"it"指的是什么。
- 多头机制赋予attention多种子表达方式。像下面的例子所示,在多头下有多组query/key/value-matrix,而非仅仅一组(论文中使用8-heads)。每一组都是随机初始化,经过训练之后,输入向量可以被映射到不同的子表达空间中。

如果我们计算multi-headed self-attention的,分别有八组不同的Q/K/V matrix,我们得到八个不同的矩阵。

这会带来点麻烦,前向网络并不能接收八个矩阵,而是希望输入是一个矩阵,所以要有种方式处理下八个矩阵合并成一个矩阵。

上述就是多头自注意机制的内容,我认为还仅是一部分矩阵,下面尝试着将它们放到一个图上可视化如下。

Position Embedding
为解决词序的利用问题,Transformer新增了一个向量对每个词,这些向量遵循模型学习的指定模式,来决定词的位置,或者序列中不同词的举例。对其理解,增加这些值来提供词向量间的距离,当其映射到Q/K/V向量以及点乘的attention时。

一般position embedding矩阵的形状是 (max_sequence_len * embedding_dim) 跟token embedding 的结合方式是 add。
Add&Normalize
self-attention层上是残差连接后的LayerNormalize层。LayerNorm中每个样本都有不同的均值和方差,不像BatchNormalization是整个batch共享均值和方差。

在解码器中也是如此,假设两层编码器+两层解码器组成Transformer,其结构如下:

Feed Forward
Feed Forward 层采用了全连接层加Relu函数实现,用公式可以表示为:
FFN(x)=Relu(xW1+b1)W2+b2FFN(x) = Relu(xW_1 + b_1) W_2 + b_2FFN(x)=Relu(xW1+b1)W2+b2

该层就是两个权重矩阵和两个偏置需要学习。
Decoder
Decoder 同样是N=6个layers层组成的,但是这里的layer和Encoder不一样,这里的layer包含了三个sub-layers。第一个sub-layer就是多头自注意力层,也是计算输入的self-Attention,但是因为这是一个生成过程,因此在时刻 t ,大于 t 的时刻都没有结果,只有小于 t 的时刻有结果,因此需要做masking,masking的作用就是防止在训练的时候使用未来的输出的单词。第二个sub-layer是对encoder的输入进行attention计算的,从这里可以看出Decoder的每一层都会对Encoder的输出做Multi Attention(这里的Attention就是普通的Attention,非self-Attention)。第三个sub-layer是全连接层。
从上面的分析来看Attention在模型中的应用有三个方面:
1)Encoder-Decoder Attention
在这里就和普通的Attention一样运用,query来自Decoder,key和value来自Encoder。
2)Encoder Attention
这里是self-Attention,在这里query,key,value都是来自于同一个地方
3)Decoder Attention
这里也是self-Attention,在这里的query,key,value也都是来自于同一个地方。但是在这里会引入masking。
masked self-attention的细节。
Masked Self Attention 和 Self Attention 是相同的,除了第 2 个步骤。假设模型只有 2 个 token 作为输入,我们正在观察(处理)第二个 token。在这种情况下,最后 2 个 token 是被屏蔽(masked)的。所以模型会干扰评分的步骤。它基本上总是把未来的 token 评分为 0,因此模型不能看到未来的词:

这个屏蔽(masking)经常用一个矩阵来实现,称为 attention mask。想象一下有 4 个单词的序列(例如, 机器人必须遵守命令 )。在一个语言建模场景中,这个序列会分为 4 个步骤处理–每个步骤处理一个词(假设现在每个词是一个 token)。由于这些模型是以 batch size 的形式工作的,我们可以假设这个玩具模型的 batch size 为 4,它会将整个序列作(包括 4 个步骤)为一个 batch 处理。

在矩阵的形式中,我们把 Query 矩阵和 Key 矩阵相乘来计算分数。让我们将其可视化如下,不同的是,我们不使用单词,而是使用与格子中单词对应的 Query 矩阵(或者 Key 矩阵)。

在做完乘法之后,我们加上三角形的 attention mask。它将我们想要屏蔽的单元格设置为负无穷大或者一个非常大的负数(例如 GPT-2 中的 负十亿):

然后对每一行应用 softmax,会产生实际的分数,我们会将这些分数用于 Self Attention。

下面来两张图表示encoder-decoder工作过程。
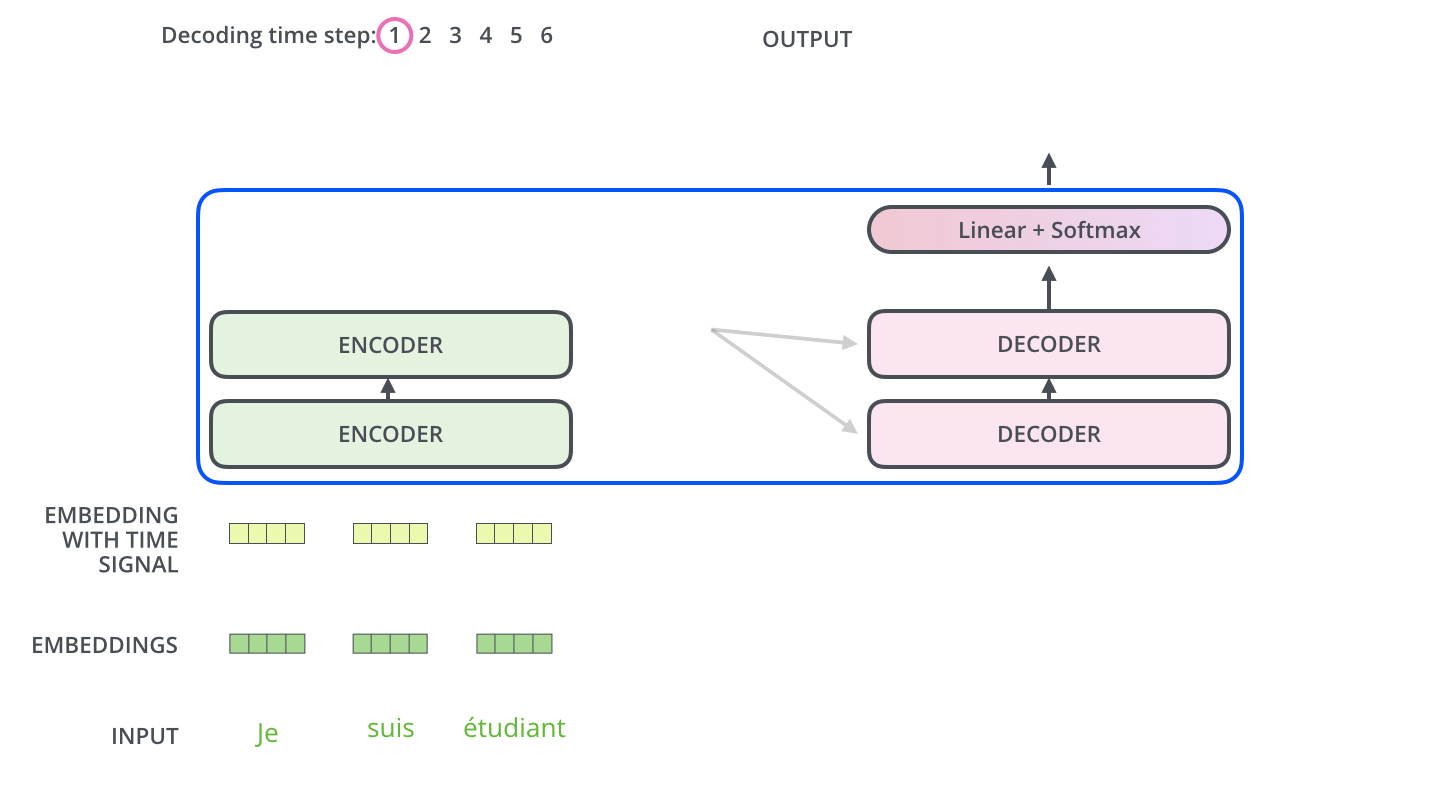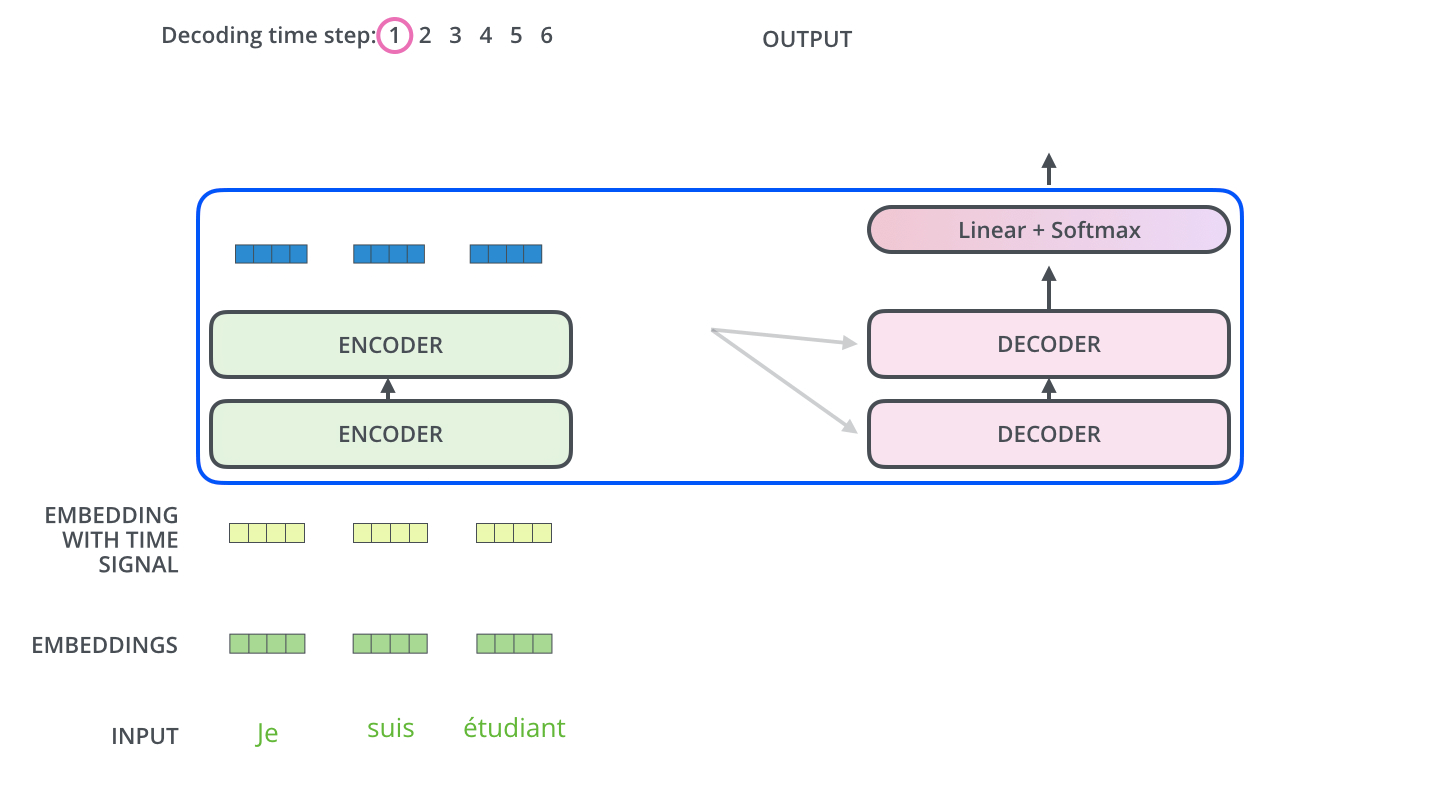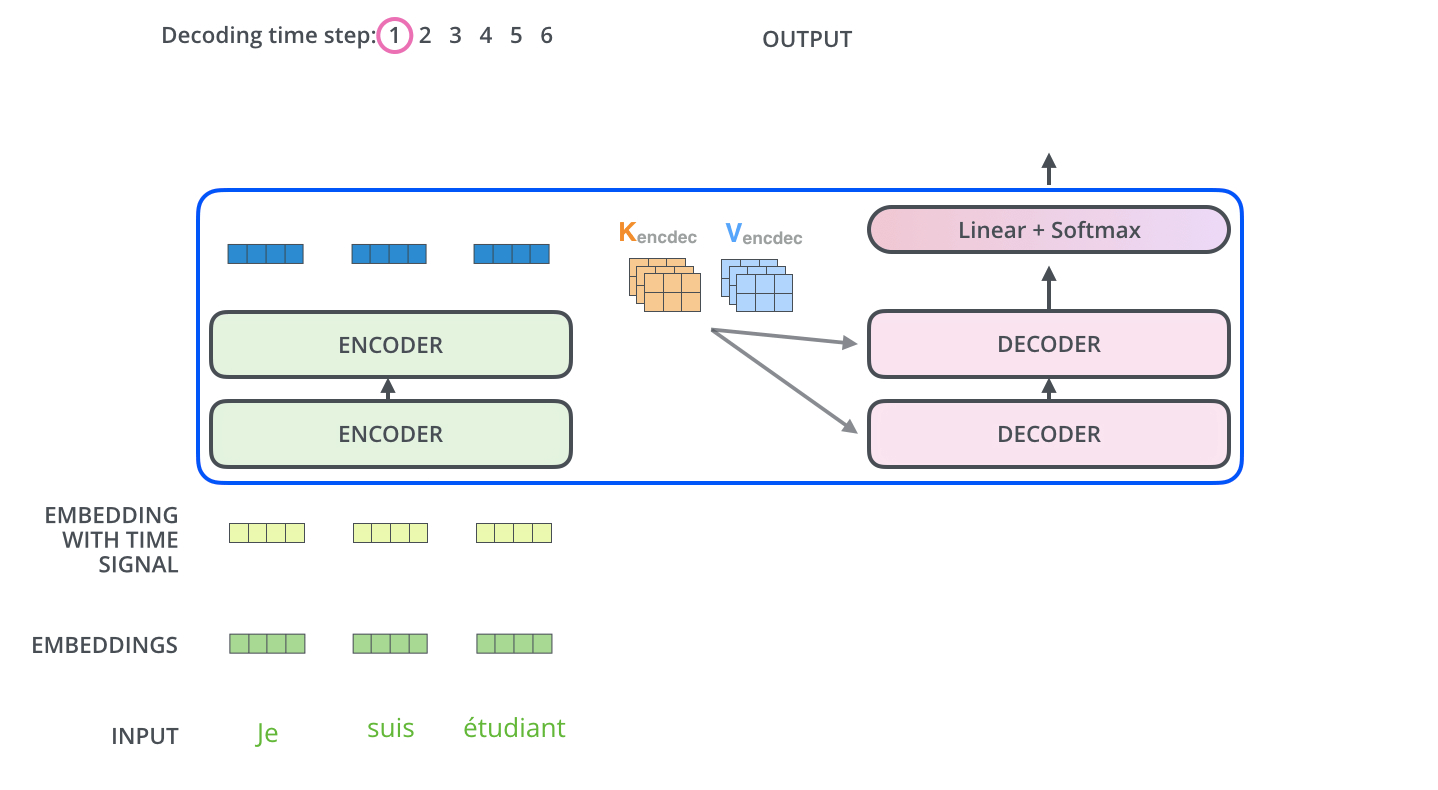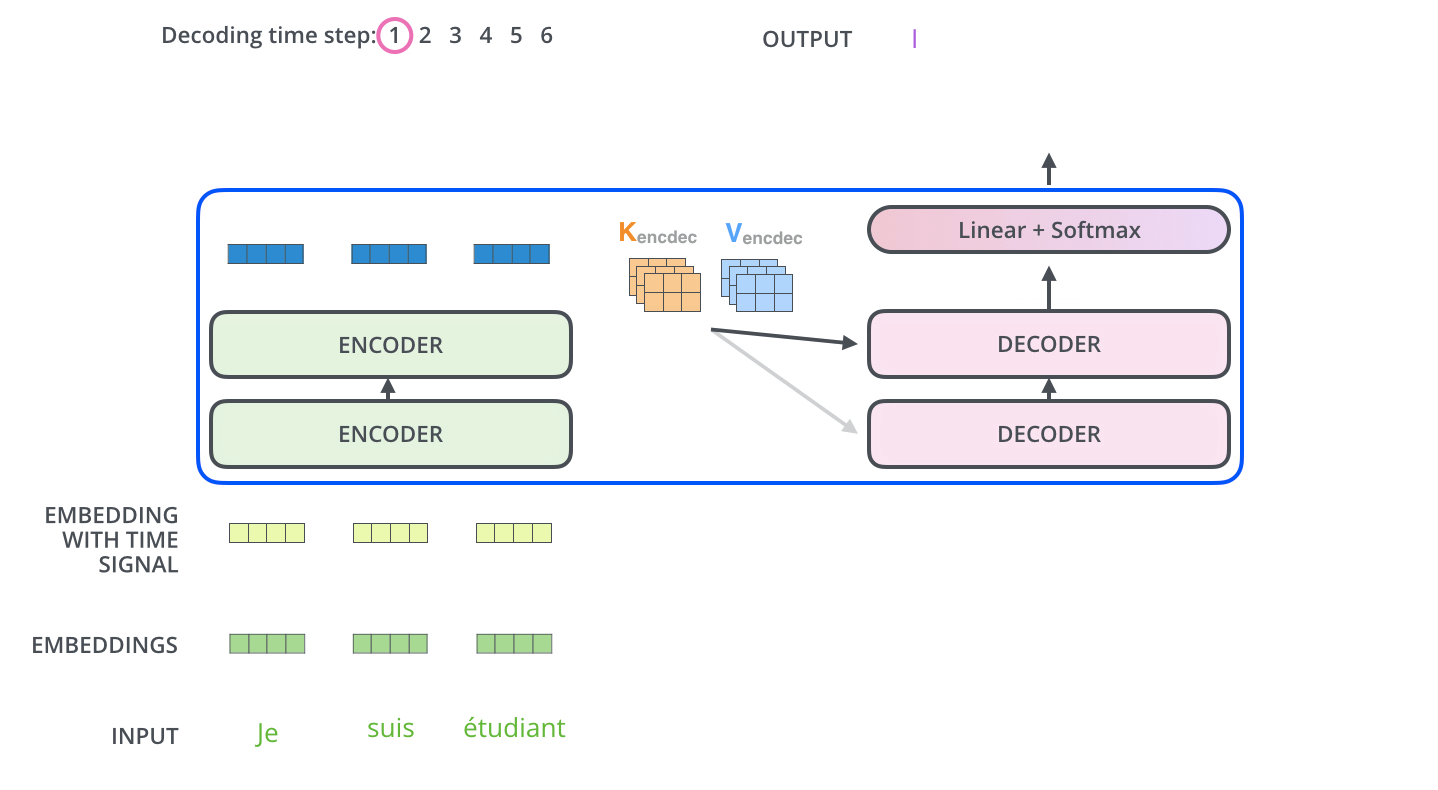

Linear and Softmax Layer 最后输出
解码器最后输出浮点向量,如何将它转成词?这是最后的线性层和softmax层的主要工作。
线性层是个简单的全连接层,将解码器的最后输出映射到一个非常大的logits向量上。假设模型已知有1万个单词(输出的词表)从训练集中学习得到。那么,logits向量就有1万维,每个值表示是某个词的可能倾向值。
softmax层将这些分数转换成概率值(都是正值,且加和为1),最高值对应的维上的词就是这一步的输出单词。

总结
Transformer模型是一个比较大的模型,理解该模型有助于理解Bert,GPT等模型。
参考
https://blog.youkuaiyun.com/yujianmin1990/article/details/85221271
http://nlp.seas.harvard.edu/2018/04/03/attention.html#position-wise-feed-forward-networks
https://www.cnblogs.com/jiangxinyang/p/10069330.html
https://www.sohu.com/a/431163642_100008678

















 1045
1045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









