



 本文介绍了Scrapy框架的常用命令,包括查看帮助、版本信息、创建项目和蜘蛛、运行蜘蛛、交互式终端、打印HTML、查看本地网页、配置文件节点、项目命令等,帮助开发者更好地理解和使用Scrapy进行爬虫开发。
本文介绍了Scrapy框架的常用命令,包括查看帮助、版本信息、创建项目和蜘蛛、运行蜘蛛、交互式终端、打印HTML、查看本地网页、配置文件节点、项目命令等,帮助开发者更好地理解和使用Scrapy进行爬虫开发。
1.查看帮助命令
scrapy -h
scrapy –help
2.查看版本信息
scrapy version
scrapy version -v
3.全局命令和项目命令文档截图

4.全局命令
a)创建项目(startproject)
scrapy startproject testproject

b)创建蜘蛛,默认模板basic,一个项目可以创建多个蜘蛛(genspider)
cd testpeoject
scrapy genspider testspider baidu.com
scrapy list
所有模板:
basic 基础
crawl自动爬虫
csvfeed用来处理csv文件
xmlfeed用来处理xml文件
模板命令:scrapy genspider -t basic testspider www.baidu.com,创建了一个带模板的testspider蜘蛛

c)运行蜘蛛(runspider)
命令行切换到spiders文件夹下,然后runspider
scrapy runspider testspider.py
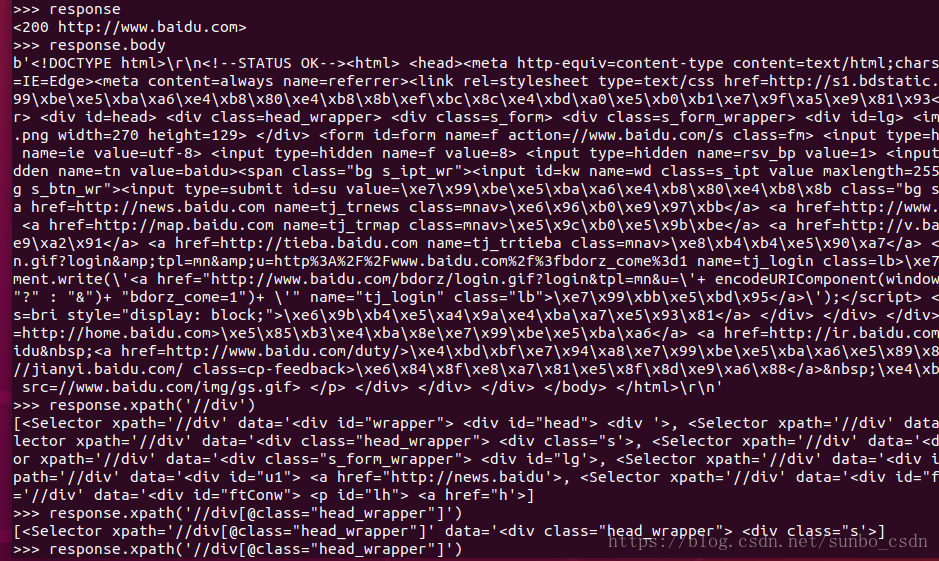
d)交互式终端(shell)
进入终端:scrapy shell ‘www.baidu.com’
查看状态: response
显示网页html:response.text
xpath匹配数据:response.xpath(‘//div[@class=”head_wrapper”]’)
退出终端:exit()
e)打印heml(fetch)
scrapy fetch –nolog http://www.example.com/some/page.html
f)本地查看网页(view)
查看本地豆瓣主页,文件保存在本地,可加载动态js,提供网页动态数加载分析:scrapy view https://www.douban.com
g)查看版本信息(version)
scrapy version -v
i)查看配置文件节点(settings)
scrapy settings –get BOT_NAME
5.项目命令(目录切换到项目目录下)
a).运行蜘蛛(crawl)
scrapy crawl testspider
b).测试爬虫,编译是否由错误(check)
scrapy check testspider

c).显示所有蜘蛛
scrapy list
d).编辑器打开爬虫(edit)
scrapy edit testspider
e).执行请求后,回调函数,yield到Item(parse)
scrapy parse http://www.example.com/ -c TestprojectItem

f).测试本地硬件性能(bench)
scrapy bench

















 389
389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









