



一. 线性回归
1. 一维变量
线性回归试图学的f(xi)=wxi+bf(x_i) = wx_i+bf(xi)=wxi+b, 使得f(xi)≃yif(x_i)\simeq y_if(xi)≃yi。
在线性回归中,我们用均方误差来衡量f(xi)f(x_i)f(xi)与yiy_iyi之间的差别,使其最小化,即:
min F(w,b)=∑in(f(xi)−yi)2min\ \ \ F(w,b)=\sum_i^n(f(x_i)-y_i)^2min F(w,b)=i∑n(f(xi)−yi)2
通常,我们用最小二乘法对基于均方误差优化的模型进行求解,对FFF求导得:
∂F∂w=∑in2xi(wxi+b−yi)\frac{\partial F}{\partial w}=\sum_i^n2x_i(wx_i+b-y_i)∂w∂F=i∑n2xi(wxi+b−yi)
∂F∂b=∑in2(wxi+b−yi)\frac{\partial F}{\partial b}=\sum_i^n2(wx_i+b-y_i)∂b∂F=i∑n2(wxi+b−yi)
令导数等于零,得
b=1n∑in(−wxi+yi)b=\frac{1}{n}\sum_i^n(-wx_i+y_i)b=n1i∑n(−wxi+yi)
w=∑inyi(xi−1n∑inxi)∑inxi2−1n(∑inxi)2w = \frac{\sum_i^ny_i(x_i-\frac{1}{n}\sum_i^nx_i)}{\sum_i^nx_i^2-\frac{1}{n}(\sum_i^nx_i)^2}w=∑inxi2−n1(∑inxi)2∑inyi(xi−n1∑inxi)
2. 多维变量
当数据有ddd个属性时,xxx(样本数据)是n×dn\times dn×d的矩阵,我们试图学到f(x)=wxT+bf(x) = wx^T+bf(x)=wxT+b。令X=(xT;1),w=(w;b)X = (x^T;1), w=(w;b)X=(xT;1),w=(w;b), (1为全1的列向量),其目标函数为:
min F(wT)=(wTXT−YT)T(wTXT−YT)min\ \ \ F(w^T)= (w^TX^T-Y^T)^T(w^TX^T-Y^T)min F(wT)=(wTXT−YT)T(wTXT−YT)
求导可得:
∂F∂w=2(wXT−YT)X\frac{\partial F}{\partial w}=2(wX^T-Y^T)X∂w∂F=2(wXT−YT)X
令导数为零向量,可得:
wT=YTX(XTX)−1w^T = Y^TX(X^TX)^{-1}wT=YTX(XTX)−1
3. 从MLE角度理解
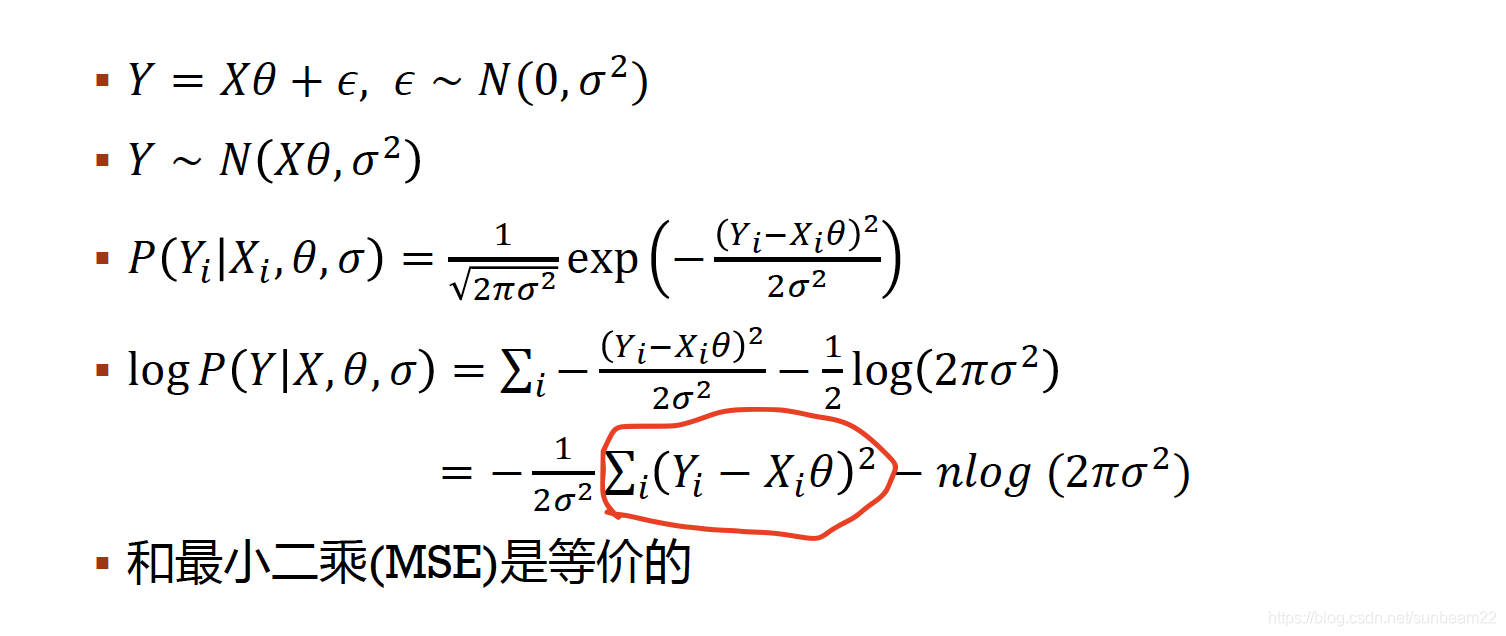
当样本数量很大时,ϵ\epsilonϵ(残差)服从标准正态分布。最大化likelihood,相当于最小化红圈部分,这与线性回归(一维)中的目标函数一致。
二、逻辑回归
逻辑回归其实是一个二分类模型。线性回归模型(f(xi)=wxi+bf(x_i) = wx_i+bf(xi)=wxi+b)产生的预测值是实数,我们希望将其转变成[0,1][0,1][0,1]区间上的数,使它代表样本为正的概率p(yi=1∣xi)p(y_i=1|x_i)p(yi=1∣xi)。对数几率函数是一种"Sigmoid 函数", 可以帮助实现这一想法:p(yi=1∣xi)=11+e−(wTxi+b)p(y_i=1|x_i)=\frac{1}{1+e^{-(w^Tx_i+b)}}p(yi=1∣xi)=1+e−(wTxi+b)1。于是,我们可以通过MLE来估计w,bw,bw,b,即最大化对数似然函数:
max ln(w,b)=∑inln(p(yi∣xi))max\ \ \ ln(w,b)=\sum_i^nln(p(y_i|x_i))max ln(w,b)=i∑nln(p(yi∣xi))
令w=(w;b)w=(w;b)w=(w;b),
p(yi∣xi;w)=yi⋅ewTxiewTxi+1+(1−yi)⋅1ewTxi+1=1+yi(ewTxi−1)ewTxi+1\begin{aligned}
p(y_i|x_i;w)=&y_i\cdot\frac{e^{w^Tx_i}}{e^{w^Tx_i}+1}+(1-y_i)\cdot\frac{1}{e^{w^Tx_i}+1}\\=&\frac{1+y_i(e^{w^Tx_i}-1)}{e^{w^Tx_i}+1}
\end{aligned}
p(yi∣xi;w)==yi⋅ewTxi+1ewTxi+(1−yi)⋅ewTxi+11ewTxi+11+yi(ewTxi−1)
ln(p(yi∣xi;w))=ln(1+yi(ewTxi−1))−ln(ewTxi+1)=yiwTxi−ln(ewTxi+1) (yi∈{0,1})\begin{aligned}
ln(p(y_i|x_i;w))=&ln(1+y_i(e^{w^Tx_i}-1))-ln(e^{w^Tx_i}+1)\\=&y_iw^Tx_i-ln(e^{w^Tx_i}+1)\ \ \ \ (y_i\in\{0,1\})
\end{aligned}
ln(p(yi∣xi;w))==ln(1+yi(ewTxi−1))−ln(ewTxi+1)yiwTxi−ln(ewTxi+1) (yi∈{0,1})
目标函数可变为:
min ln(w)=∑in−yiwTxi+ln(ewTxi+1)min\ \ \ ln(w)=\sum_i^n-y_iw^Tx_i+ln(e^{w^Tx_i}+1)min ln(w)=i∑n−yiwTxi+ln(ewTxi+1)
一阶导数为:
∂ln(w)∂w=∑inxi⋅[ewTxiewTxi+1−yi]\frac{\partial ln(w)}{\partial w}=\sum_i^nx_i\cdot[\frac{e^{w^Tx_i}}{e^{w^Tx_i}+1}-y
_i]∂w∂ln(w)=i∑nxi⋅[ewTxi+1ewTxi−yi]
二阶导数为:
∂2ln(w)∂w∂wT=∑inxixiT⋅ewTxiewTxi+1⋅1ewTxi+1\frac{\partial^2 ln(w)}{\partial w\partial w^T}=\sum_i^nx_ix_i^T\cdot\frac{e^{w^Tx_i}}{e^{w^Tx_i}+1}\cdot\frac{1}{e^{w^Tx_i}+1}∂w∂wT∂2ln(w)=i∑nxixiT⋅ewTxi+1ewTxi⋅ewTxi+11
可以计算得到二阶导数大于零,所以目标函数为凸函数;由于令导数为零无法得到闭式解,我们可用梯度下降法等其他的优化方法来求解。
总而言之,线性回归是拟合一条曲线,使得l2l_2l2损失最小;逻辑回归是找到一条决策边界,最大化样本分类正确的概率。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









