







 本文深入解析正则表达式的概念、语法与应用,涵盖匹配过程、模式选择、常用函数如re.compile、re.match、re.search及其返回的Match对象的属性与方法。适合初学者和进阶者参考。
本文深入解析正则表达式的概念、语法与应用,涵盖匹配过程、模式选择、常用函数如re.compile、re.match、re.search及其返回的Match对象的属性与方法。适合初学者和进阶者参考。
概念:
正则表达式对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑
正则表达式匹配过程:
- 依次拿出表达式和文本中的字符比较
- 如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败
- 如果表达式中有量词或边界,这个过程会稍微有一些不同
语法及相关注释:
- 一般字符
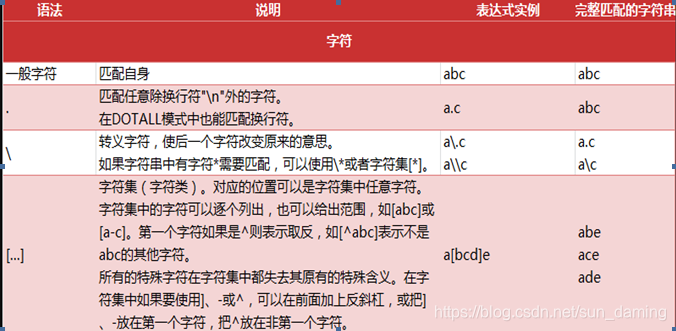
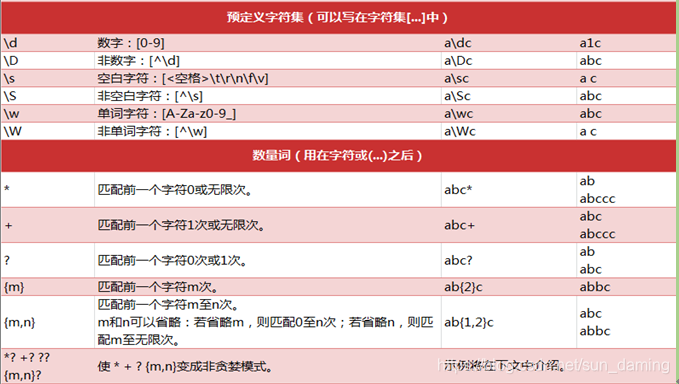
- 预定义字符集
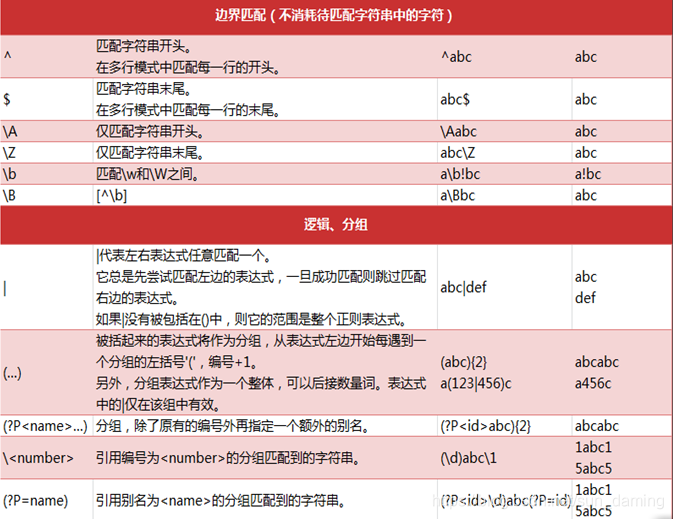
- 边界匹配
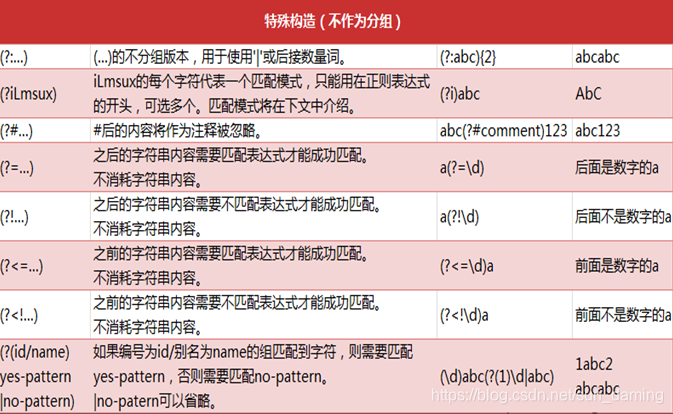
- 特殊构造
- 匹配模式
- 忽略大小写, re.I
- 多行匹配, re.M, 改变^ 和 $
- 匹配任意多行,包括换行符, re.S
- 冗余/详细模式,此模式忽略正则表达式中的空白和#号的注释,re.X
例子:email_regex = re.compile("[\w+\.]+@[a-zA-Z\d]+\.(com|cn)")
- 匹配函数
- re.compile()
Python通过re模块提供对正则表达式的支持。使用re的一般步骤是先将正则表达式的字符串形式编译为Pattern 实例,然后使用Pattern实例处理文本并获得匹配结果。我们可以通过re.compile()方法实现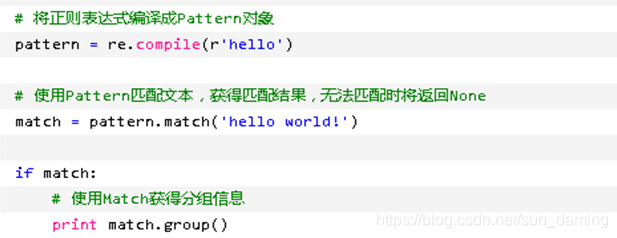
-
re.com;ile(strPattern[.flag]):
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。 第二个参数flag是匹 配模式,取值可以使用按位或运算符'|'表示同时生效,比如re.I | re.M。另外,你也可以在regex字符串中指定 模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的 - re.match(pattern, string[, flags])
这个方法将会从string(我们要匹配的字符串)的开头开始,尝试匹配pattern,一直向后匹配,如果遇到无法 匹配的字符,立即返回None,如果匹配未结束已经到达string的末尾,也会返回None。两个结果均表示匹配 失败,否则匹配pattern成功,同时匹配终止,不再对string向后匹配。 -
match()的属性和方法。
-
属性:
-
.string: 匹配时使用的文本
-
re: 匹配时使用的Pattern对象
-
pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同
-
endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同
-
lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None
-
lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
-
-
方法:
1.group([group1, …]):
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以 使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回 None;截获了多次的组返回最后一次截获的子串。2.groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的 组以这个值替代,默认为None。3.groupdict([default]):
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内default同上。4.start([group]):
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。5.end([group]):
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。6.span([group]):
返回(start(group), end(group))。7.expand(template):
-
将匹配到的分组代入template中然后返回。template中可以使用\id或\g<id>、\g<name>引用分组,但 不能使用编号0。\id与\g<id>是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符'0', 只能使用\g<1<0

- re.search(pattern, string[, flags])
search方法与match方法极其类似,区别在于match()函数只检测re是不是在string的开始位置匹配,search()会扫描整个string查找匹配,match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回None。同样,search方法的返回对象同match()返回对象的方法和属性一样。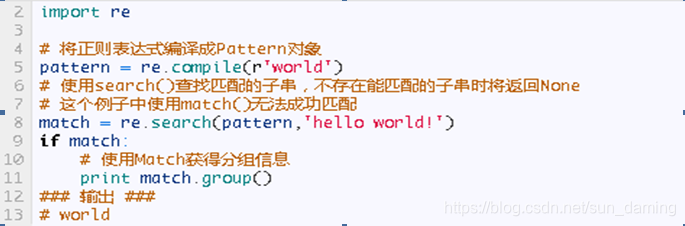
- re.split(pattern, string[, maxsplit])
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。
- re.findall(pattern, string[, flags])
搜索string,以列表形式返回全部能匹配的子串。
- re.finditer(pattern, string[, flags])
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器
- sub(repl, string[, count]) | re.sub(pattern, repl, string[, count]
使用repl替换string中每一个匹配的子串后返回替换后的字符串。
当repl是一个字符串时,可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。
当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)
count用于指定最多替换次数,不指定时全部替换。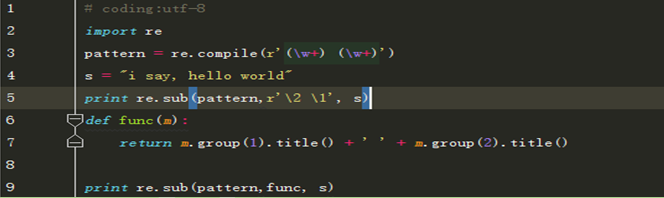
-
-
- re.compile()
re的大部分的技术点都总结了,有不足之处,欢迎来电。。。——————>电话号码是:
不告诉你


















 3214
3214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











