




一.基础部分
Go 语言的设计哲学
简单、显式、组合、并发和面向工程。
go语言的值类型和引用类型?
值类型:int、float、bool、string 和 数组。
值类型的变量直接指向存在内存中的值,值类型的变量的值存储在栈中。
引用类型:切片(slice)、映射(map)、通道(chan)、接口(interface)和指针(pointer)。
引用类型的变量存储在堆上
调用函数传入结构体时,应该传值还是指针?
go 里面只存在只存在值传递(要么是该值的副本,要么是指针的副本),不存在引用传递。
之所以对于引用类型的传递可以修改原内容数据,是因为在底层默认使用该引用类型的指针进行传递,但是也是使用指针的副本,依旧是值传递。
Go 只有值传递
Go语言中所有函数参数传递都是值传递,这意味着:
- 当你传递一个变量给函数时,Go会创建该变量的一个副本传入函数
- 这个副本可能是:
• 原始值的副本(对于基本类型如int、float、struct等)
• 指针的副本(对于指针类型或引用类型)
在 Go 语言中只存在值传递,要么是值的副本,要么是指针的副本。无论是值类型的变量还是引用类型的变量亦或是指针类型的变量作为参数传递都会发生值拷贝,开辟新的内存空间。
值传递/引用传递 和 值类型/引用类型 是两个不同的概念,不要混淆了。引用类型作为变量传递可以影响到函数外部是因为发生值拷贝后新旧变量指向了相同的内存地址。
为什么能修改"引用类型"?
对于 slice、map、channel 等"引用类型",虽然看起来像是引用传递,但实际上:
- 这些类型在底层都是结构体,包含指向实际数据的指针
- 当你传递它们时,传递的是这个结构体的副本(值传递)
- 但由于副本中的指针指向相同的内存,所以通过副本也能修改原数据
指针也是值传递
即使你显式使用指针:
func modify(p *int) {
*p = 10
}
func main() {
x := 5
modify(&x)
}
这里传递的是指针&x的副本,而不是原始指针本身。但因为副本指针指向相同内存,所以能修改原变量。
与引用传递的区别
真正的引用传递(如C++的&参数)会:
• 直接操作原始变量,不创建副本
• 对参数的修改直接影响调用者
而 Go 的值传递(包括指针副本):
• 总是创建副本
• 只是通过副本中的指针间接访问原数据
副本复制时,是深拷贝还是浅拷贝?
在 Go 语言中,参数传递时的"复制"是浅拷贝(Shallow Copy),而不是深拷贝(Deep Copy)。具体区别如下:
-
基本类型(int, float, bool, string 等)
浅拷贝:直接复制值本身(等同于深拷贝,因为不涉及嵌套结构)
a := 10 b := a // 完全复制值,a 和 b 完全独立
-
引用类型(slice, map, channel)
浅拷贝:复制的是底层数据结构的引用(如 slice 的
ptr、len、cap),但不会复制底层数据s1 := []int{ 1, 2, 3} s2 := s1 // 复制的是 slice 的 header(ptr, len, cap),但底层数组仍然是同一个 s2[0] = 99 fmt.Println(s1) // [99 2 3],因为 s1 和 s2 共享底层数组
-
结构体(struct)
浅拷贝:复制结构体的所有字段,但如果字段是指针或引用类型,只会复制指针/引用,不会复制指向的数据
type Person struct { Name string Friends []string // 引用类型(slice) } p1 := Person{ Name: "Alice", Friends: []string{ "Bob"}} p2 := p1 // 浅拷贝,Friends 的底层数组仍然是同一个 p2.Friends[0] = "Charlie" fmt.Println(p1.Friends) // ["Charlie"],因为 p1 和 p2 共享 Friends 的底层数组
-
指针(
*T)浅拷贝:复制的是指针的值(内存地址),不会复制指针指向的数据
x := 10 p1 := &x p2 := p1 // 复制的是指针的值(地址),p1 和 p2 指向同一个 x *p2 = 20 fmt.Println(x) // 20,因为 p1 和 p2 都指向 x
总结
| 类型 | 复制方式 | 是否共享底层数据 | 示例 |
|---|---|---|---|
| 基本类型 | 直接复制值(等同于深拷贝) | ❌ 不共享 | a := 10; b := a |
| 引用类型(slice, map, channel) | 浅拷贝(复制引用) | ✅ 共享 | s1 := []int{1}; s2 := s1; s2[0] = 2 |
| 结构体 | 浅拷贝(字段逐值复制) | 如果字段是引用类型,则共享 | p2 := p1(p1.Friends 是 slice) |
| 指针 | 浅拷贝(复制地址) | ✅ 共享 | p2 := p1(p1 是指针) |
关键区别
- 浅拷贝:只复制最外层的值,不会递归复制嵌套的数据(如 slice 的底层数组、map 的哈希表、指针指向的数据)。
- 深拷贝:会递归复制所有数据,完全独立(Go 默认不提供,需要手动实现或使用
encoding/json、gob等方式)。
如何实现深拷贝?
-
切片:
如何实现切片的深拷贝,避免共享底层数组?
方法 1:
copy()(推荐)s1 := []int{ 1, 2, 3} s2 := make([]int, len(s1)) // 先创建新 slice copy(s2, s1) // 复制元素(底层数组不同) s2[0] = 99 fmt.Println(s1) // [1, 2, 3](不受影响) fmt.Println(s2) // [99, 2, 3]方法 2:手动创建新 slice
s1 := []int{ 1, 2, 3} s2 := append([]int{ }, s1...) // 通过 append 创建新 slice s2[0] = 99 fmt.Println(s1) // [1, 2, 3](不受影响) fmt.Println(s2) // [99, 2, 3]方法 3: json 序列化/反序列化
// 使用 json 序列化/反序列化(适用于可序列化类型) func deepCopy(src, dest interface{ }) error { bytes, err := json.Marshal(src) if err != nil { return err } return json.Unmarshal(bytes, dest) } // 示例 var s1 = []int{ 1, 2, 3} var s2 []int deepCopy(s1, &s2) // s2 现在是完全独立的副本 -
结构体
方法 1. 手动实现深拷贝(推荐用于简单结构体)
type Person struct { Name string Age int Friends []string } func (p *Person) DeepCopy() *Person { // 创建新结构体 newPerson := &Person{ Name: p.Name, Age: p.Age, } // 对引用类型字段进行深拷贝 if p.Friends != nil { newPerson.Friends = make([]string, len(p.Friends)) copy(newPerson.Friends, p.Friends) } return newPerson } // 使用示例 p1 := &Person{ Name: "Alice", Age: 30, Friends: []string{ "Bob", "Charlie"}, } p2 := p1.DeepCopy() p2.Friends[0] = "David" fmt.Println(p1.Friends) // ["Bob", "Charlie"] fmt.Println(p2.Friends) // ["David", "Charlie"]方法 2. json 序列化/反序列化
适用于可JSON序列化的结构体:
import "encoding/json" func DeepCopyJSON(src, dst interface{ }) error { bytes, err := json.Marshal(src) if err != nil { return err } return json.Unmarshal(bytes, dst) } // 使用示例 p1 := &Person{ Name: "Alice", Age: 30, Friends: []string{ "Bob", "Charlie"}, } var p2 Person err := DeepCopyJSON(p1, &p2) if err != nil { panic(err) }
Go 中不可序列化的类型
| 类型 | 不可序列化的原因 | 替代方案 |
|---|---|---|
chan |
绑定运行时状态,跨进程无意义 | 传递数据而非通道对象 |
func |
依赖代码段和闭包环境,存在安全风险 | 传递函数标识符和参数 |
Go 的设计哲学强调明确性和安全性,因此禁止对这类具有运行时依赖的类型进行序列化。
struct 结构体能不能比较
- 如果 struct 中
含有不能被比较的字段类型,就不能被比较 - 如果 struct 中
所有的字段类型都支持比较,那么就可以被比较。
不可被比较的类型:
- slice,因为 slice 是引用类型,除非是和nil比较
- map,和 slice 同理,如果要比较两个 map 只能通过循环遍历实现
- 函数类型
为什么引用类型不能比较 ?
引用类型,是想去比较值还是地址?会有歧义,因此 Go 从语言层面上直接杜绝了引用类型的比较;
当然引用类型可以和 nil 进行比较。
golang 中 make 和 new 的区别?
共同点:
- 给变量分配内存;
- make 与 new 对堆栈分配处理是相同的,编译器优先进行逃逸分析,逃逸的才分配到堆上
不同点:
- 作用变量类型不同,new 给 string、int、数组 分配内存;make给 slice、map、channel 分配内存;
- 返回类型不一样,new 返回指向变量的指针,make 返回变量本身;
- new 分配的空间被清零。make 分配空间后,会进行初始化;
for range 的时候它的地址会发生变化么?
在 for a,b := range c 遍历中, a 和 b 在内存中只会存在一份,即之后每次循环时遍历到的数据都是以值覆盖的方式赋给 a 和 b,a,b 的内存地址始终不变。
由于有这个特性,for 循环里面如果开协程,不要直接把 a 或者 b 的地址传给协程。
解决办法:在每次循环时,创建一个临时变量。
rune 类型
rune 是类型 int32 的别名,在所有方面都等价于它,用来区分字符值跟整数值。
在 Go 语言中,字符可以被分成两种类型处理:
- 对占 1 个字节的英文类字符,可以使用 byte(或者unit8);
- 对占 1 ~ 4 个字节的其他字符,可以使用 rune(或者int32),如中文、特殊符号等。

s := "Go语言编程"
// byte
fmt.Println([]byte(s)) // 输出:[71 111 232 175 173 232 168 128]
// rune
fmt.Println([]rune(s)) // 输出:[71 111 35821 35328]
获取变量类型?
类型开关(Type Switch)是在运行时检查变量类型的最佳方式。
switch v := variable.(type) {
case Type1:
// 当 variable 的类型是 Type1 时执行的代码
case Type2:
// 当 variable 的类型是 Type2 时执行的代码
default:
// 当 variable 的类型不在上述 case 中时执行的代码
}
反射
Golang 的反射(reflection)机制允许程序在运行时获取和操作变量的类型和值。
比喻来说,反射就是程序在运行的时候能够"观察"并且修改自己的行为。

package main
import (
"fmt"
"reflect"
)
func main() {
author := "draven"
fmt.Println("TypeOf author:", reflect.TypeOf(author))
fmt.Println("ValueOf author:", reflect.ValueOf(author))
}
// 结果
// TypeOf author: string
// ValueOf author: draven
反射优点:
- 反射就是在程序运行的过程中,可以对一个未知类型的数据进行操作的过程
- 可以减少重复代码
缺点:
- 反射会消耗性能,使程序运行缓慢
context 结构是什么样的?context 使用场景和用途?
Go 1.7 标准库引入 context,它是 goroutine 的上下文,包含 goroutine 的运行状态、环境等信息。
Go 的 Context 的数据结构包含 Deadline,Done,Err,Value
// Conetext 包介绍 : 通常context携带截止时间,**和取消信号**,以及其他跨越API边界的值,Context的方法可以被多个协程同时调用。
package context
type Context interface {
// 返回截止的日期,如果无截止日期,ok返回false
Deadline() (deadline time.Time, ok bool)
// 返回一个channel,当工作已完成或者上下文被取消时关闭。如果是一个不会被取消的上下文,Done会返回nil
// WithCancel方法,会在被调用cancel时,关闭Done
// WithDeadline方法,会在过截止时间时,关闭Done
// WithTimeout方法,会在超时结束时,关闭Done
Done() <-chan struct{
}
// Done没有被关闭时,会返回nil
// 如果Done关闭了,将会返回关闭的原因(取消、超时)
Err() error
// 返回与当前上下文关联的键值或nil。如果没有值与键关联,使用相同键连续调用 Value 会返回相同的结果
Value(key interface{
}) interface{
}
}
context 主要用来:
- 在 goroutine 之间传递上下文信息,包括:取消信号、超时时间(context.WithTimeout )、截止时间、k-v 等
- 上下文控制
- 多个 goroutine 之间的数据交互等
- 超时控制:到某个时间点超时,过多久超时

Go语言中的单引号、双引号和反引号
- 单引号
单引号表示 rune(int32) 类型,单引号里面是单个字符,对应的值为改字符的ASCII值。
func main() {
a := 'A'
fmt.Println(a)
}
// 输出:
// 65
- 双引号
双引号里面可以是字符串和转义字符,如\n、\r等,对应 go 语言中的 string 类型。
func main() {
a := "Hello golang\nI am random_wz."
fmt.Println(a)
}
// 输出:
// Hello golang
// I am random_wz.
- 反引号
多行内容,不支持转义。
func main() {
a := `Hello golang\n:
I am random_wz.
Good.`
fmt.Println(a)
}
// 输出:
// Hello golang\n:
// I am random_wz.
// Good.
// 可以看到 `\n` 并没有被转义,而是被直接作为字符串输出。
Go 语言触发 panic 的情况?
在 Go 语言中,panic 是一种用于处理程序无法继续执行的严重错误的机制。
当程序遇到无法恢复的错误时,会触发 panic,导致程序立即停止当前函数的执行,并开始逐层向上回溯调用栈,执行每个函数的 defer 语句,最后退出程序。
以下是 Go 中常见的触发 panic 的情况:
- 数组或切片越界访问
- 当访问数组或切片的索引超出其范围时,会触发
panic。
arr := [3]int{ 1, 2, 3} fmt.Println(arr[5]) // panic: runtime error: index out of range [5] with length 3 - 当访问数组或切片的索引超出其范围时,会触发
- 空指针解引用
- 当解引用一个
nil指针时,会触发panic。
var ptr *int fmt.Println(*ptr) // panic: runtime error: invalid memory address or nil pointer dereference - 当解引用一个
- 向已关闭的通道发送数据
- 当向一个已关闭的通道发送数据时,会触发
panic。
ch := make(chan int) close(ch) ch <- 1 // panic: send on closed channel - 当向一个已关闭的通道发送数据时,会触发
- 类型断言失败
- 当类型断言失败且未使用
ok接收返回值时,会触发panic。
var i interface{ } = "hello" num := i.(int) // panic: interface conversion: interface {} is string, not int - 当类型断言失败且未使用
- 除零操作
- 当进行整数除零操作时,会触发
panic。
a := 10 b := 0 fmt.Println(a / b) // panic: runtime error: integer divide by zero - 当进行整数除零操作时,会触发
- 递归调用栈溢出
- 当递归调用过深,导致调用栈溢出时,会触发
panic。
func infiniteRecursion() { infiniteRecursion() } infiniteRecursion() // panic: runtime error: stack overflow - 当递归调用过深,导致调用栈溢出时,会触发
- 手动调用
panic- 开发者可以手动调用
panic来中止程序执行。
panic("something went wrong") // panic: something went wrong - 开发者可以手动调用
- 使用未初始化的 map
- 当向一个未初始化的
map插入数据时,会触发panic。
var m map[string]int m["key"] = 1 // panic: assignment to entry in nil map - 当向一个未初始化的
- 调用
sync.WaitGroup的Done方法次数过多- 当调用
sync.WaitGroup的Done方法次数超过Add方法设置的值时,会触发panic。
var wg sync.WaitGroup wg.Add(1) wg.Done() wg.Done() // panic: sync: negative WaitGroup counter - 当调用
- 并发读写
map
- 当多个 goroutine 并发读写
map时,会触发panic。
m := make(map[string]int)
go func() {
m["key"] = 1
}()
fmt.Println(m["key"]) // 可能触发 panic: concurrent map read and map write
- 调用
close关闭nil通道
- 当尝试关闭一个
nil通道时,会触发panic。
var ch chan int
close(ch) // panic: close of nil channel
- 使用
sync.Mutex未正确加锁
- 当尝试解锁一个未加锁的
sync.Mutex时,会触发panic。
var mu sync.Mutex
mu.Unlock() // panic: sync: unlock of unlocked mutex
Go 语言中字符串拼接的方法
Go 语言中有多种字符串拼接方式,各有优缺点和适用场景。以下是主要的字符串拼接方法:
-
使用
+运算符最简单的拼接方式:
str1 := "Hello" str2 := "World" result := str1 + " " + str2特点:
• 简单直观
• 适合少量字符串拼接
• 每次拼接都会创建新字符串,性能较差(频繁拼接时不推荐) -
使用
fmt.Sprintf格式化拼接:
name := "Alice" age := 25 result := fmt.Sprintf("Name: %s, Age: %d", name, age)特点:
• 支持格式化输出
• 可读性好
• 性能比+稍好,但仍不适合高频拼接 -
使用
strings.Join连接字符串切片:
words := []string{ "Hello", "World", "!"} result := strings.Join(words, " ")特点:
• 适合拼接已知数量的字符串
• 性能较好
• 需要预先准备好所有字符串 -
使用
bytes.Buffer(高效方式)var buffer bytes.Buffer buffer.WriteString("Hello") buffer.WriteString(" ") buffer.WriteString("World") result := buffer.String()特点:
• 高性能,适合大量字符串拼接
• 内存分配次数少
• 线程不安全 -
使用
strings.Builder(Go 1.10+ 推荐)var builder strings.Builder builder.WriteString("Hello") builder.WriteString(" ") builder.WriteString("World") result := builder.String()特点:
• 性能最优(比 bytes.Buffer 更好)
• 专为字符串拼接设计
• 线程不安全
• 推荐在 Go 1.10+ 使用 -
使用
[]byte和类型转换var b []byte b = append(b, "Hello"...) b = append(b, " "...) b = append(b, "World"...) result := string(b)特点:
• 性能接近 bytes.Buffer
• 需要手动管理
性能比较
从高到低排序:
strings.Builder(Go 1.10+)bytes.Buffer[]byte转换strings.Joinfmt.Sprintf+运算符
选择建议
- 少量简单拼接:使用
+或fmt.Sprintf - 已知字符串列表:使用
strings.Join - 循环或大量拼接:使用
strings.Builder或bytes.Buffer - 需要格式化:使用
fmt.Sprintf
示例:高效拼接大量字符串
func concatStrings(strs ...string) string {
var builder strings.Builder
// 预先计算总长度,减少内存分配
total := 0
for _, s := range strs {
total += len(s)
}
builder.Grow(total)
for _, s := range strs {
builder.WriteString(s)
}
return builder.String()
}
在 Go 1.10 及以上版本,strings.Builder 是最推荐的字符串拼接方式,它提供了最佳的性能和易用性平衡。
二. 数组和切片
数组和切片的区别
数组(Array)和切片(Slice)都是用于存储同类型元素的集合。
区别:
- 数组是定长; 切片可以自动扩容
数组是值类型,切片是引用类型。
数组是值类型,传递时复制整个数组。
切片是引用类型,传递时只复制切片的描述符。
在 Go 语言中,描述符(Descriptor) 是一种用于描述和管理数据结构内部状态的结构体或数据结构。
// 数组
var arr [3]int = [3]int{
1, 2, 3}
//切片
slice := []int{
1, 2, 3}
slice 底层数据结构?
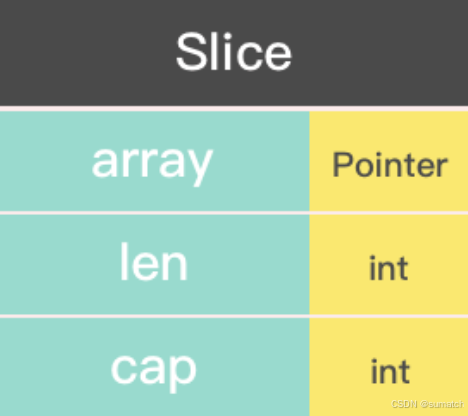
切片(slice)是对数组一个连续片段的引用,所以切片是一个引用类型。
type slice struct {
array unsafe.Pointer
len int
cap int
}
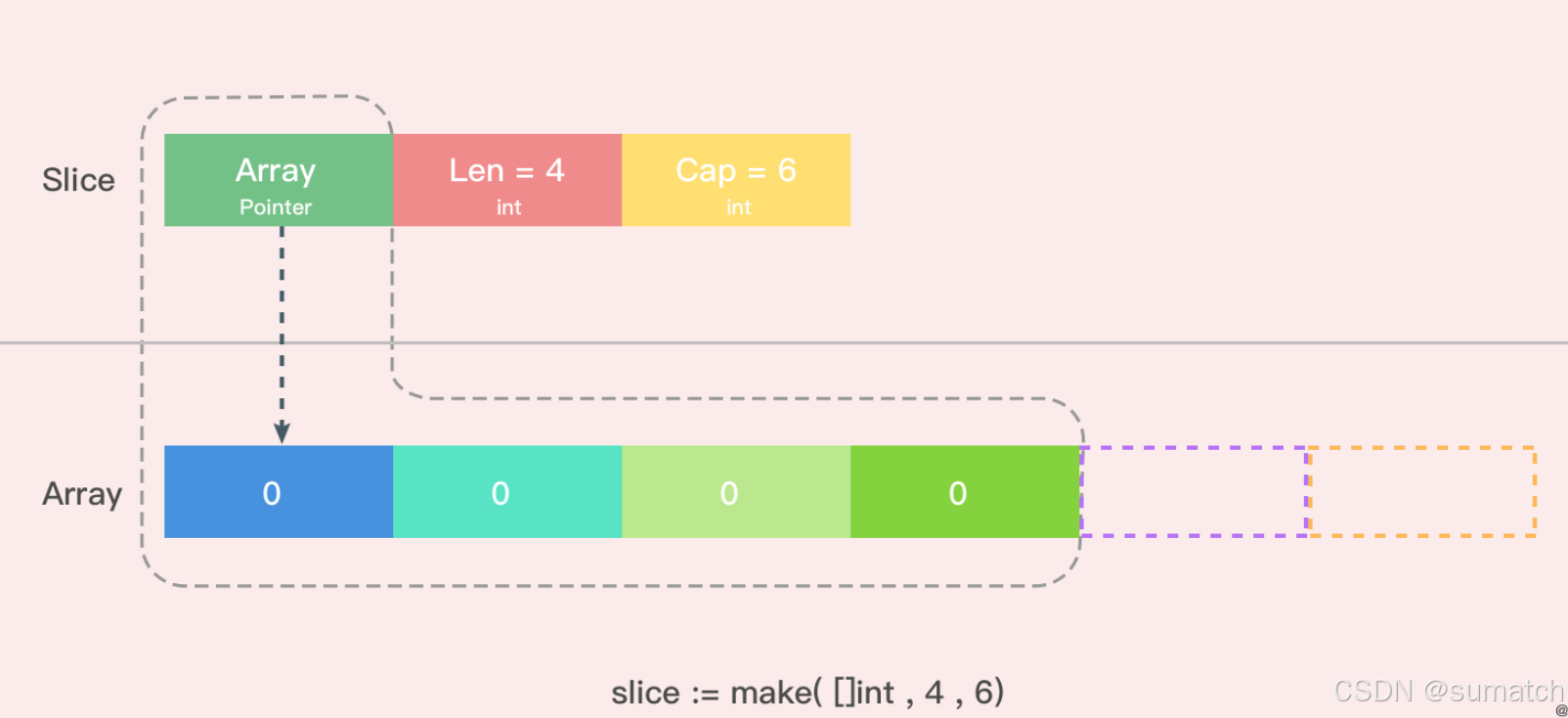
创建 slice:
slice := make([]int, 4, 6)
slice 扩容
切片的扩容规则
- 当切片容量 < 256(go 1.18 之前是 1024),扩容 2 倍,避免频繁扩容,从而减少内存分配的次数和数据拷贝的代价。
- 当切片容量 >= 256(go 1.18 之前是 1024),扩容 1.25 倍,主要避免空间浪费。
// go 1.21
newcap := oldCap
doublecap := newcap + newcap
if newLen > doublecap {
newcap = newLen
} else {
const threshold = 256
if oldCap < threshold {
// 小容量扩容
newcap = doublecap
} else {
// 大容量扩容
for 0 < newcap && newcap < newLen {
// 每次增长大约是当前容量的1.25倍
newcap += (newcap + 3*threshold) / 4
}
// 如果发生溢出(newcap <= 0),则将新容量设置为新长度
if newcap <= 0 {
newcap = newLen
}
}
}
数组是如何实现用下标访问任意元素的
- 连续内存
- 固定长度和类型
- 寻址公式来计算存储的内存地址
三. map
map 的底层实现 ?
在源码中,表示 map 的结构体是 hmap,它是 hashmap 的缩写 :
type hmap struct {
// map的大小. len()函数就取的这个值
count int
// map 状态标识
flags uint8
// B可以理解为buckets已扩容的次数
B uint8
// 溢出buckets的数量
noverflow uint16
// 计算 key 的哈希的时候会传入哈希函数
hash0 uint32
// 指向 buckets 数组,大小为 2^B
// 如果元素个数为 0,就为 nil
buckets unsafe.Pointer
// 等量扩容的时候,buckets 长度和 oldbuckets 相等
// 双倍扩容的时候,buckets 长度会是 oldbuckets 的两倍
oldbuckets unsafe.Pointer
nevacuate uintptr // 搬迁进度,小于nevacuate的已经搬迁
extra *mapextra // 可选字段,额外信息
}
桶的定义:
- 主桶:直接通过
hmap.buckets访问的桶数组,数量为2^B(B 是 hmap.B 的值)。 - 溢出桶:通过链式方式挂在主桶后面的额外桶(由
bmap.overflow指针连接)。
buckets 中包含了哈希中最小细粒度单元 bucket 桶,数据通过 hash 函数均匀的分布在各个bucket (bmap)中。
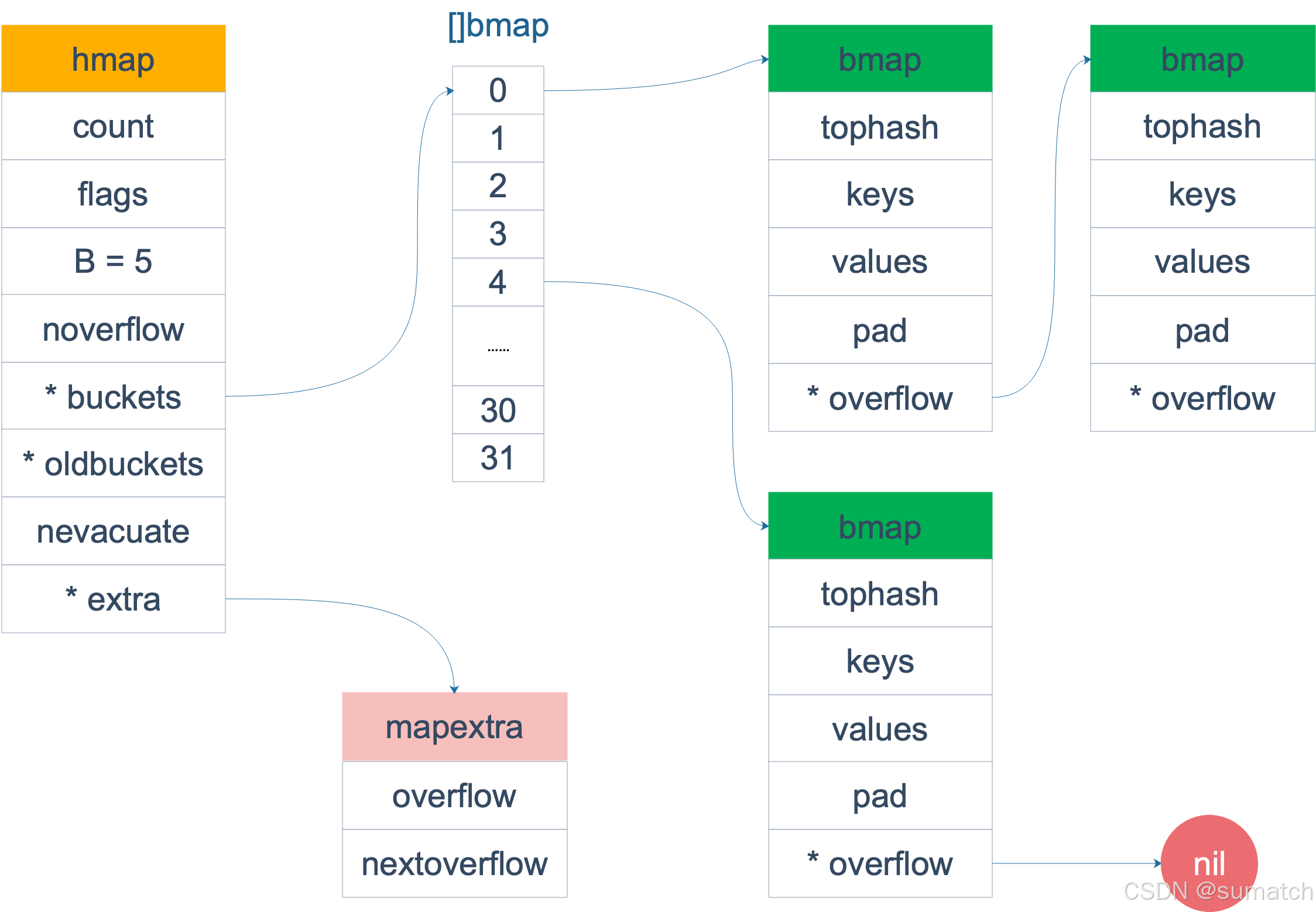
bmap 桶里面会最多装 8 个 key。这些 key 之所以会落入同一个桶,是因为它们经过哈希计算后,哈希结果一致。
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}

bmap(bucket)
- topbits 高八位哈希存储 key 在 bucket 中的顺序位置。
- keys/values 存储字典的 key 和value。key 和 value 分别放在一起。
当 key > 128 字节时,bucket 的 key 字段存储的是指针,指向key的实际内容;value 同理。
这样排列好处是在key和value的长度不同的时候,可以消除padding带来的空间浪费。并且每个 bucket最多存放8个键值对。 - overflow 存储的是当 bucket 中的 kv 数量大于 8 时,指向的下一个 bucket 的指针。
哈希函数
memhash是 Go map 的默认哈希函数,适用于大多数场景,提供良好的性能和合理的碰撞率。- aeshash 是一种基于 AES 的加密哈希函数,适用于需要更高安全性的特定场景,但性能较低。
hash 函数,有加密型和非加密型。
加密型的一般用于加密数据、数字摘要等,典型代表就是 md5、sha1、sha256、aes256 ;
非加密型的一般就是查找。在 map 的应用场景中,用的是查找。
选择 hash 函数主要考察的是两点:性能、碰撞概率。
map 查找 和 插入
了解查找和插入过程,必须要先知道高位hash和低位hash值
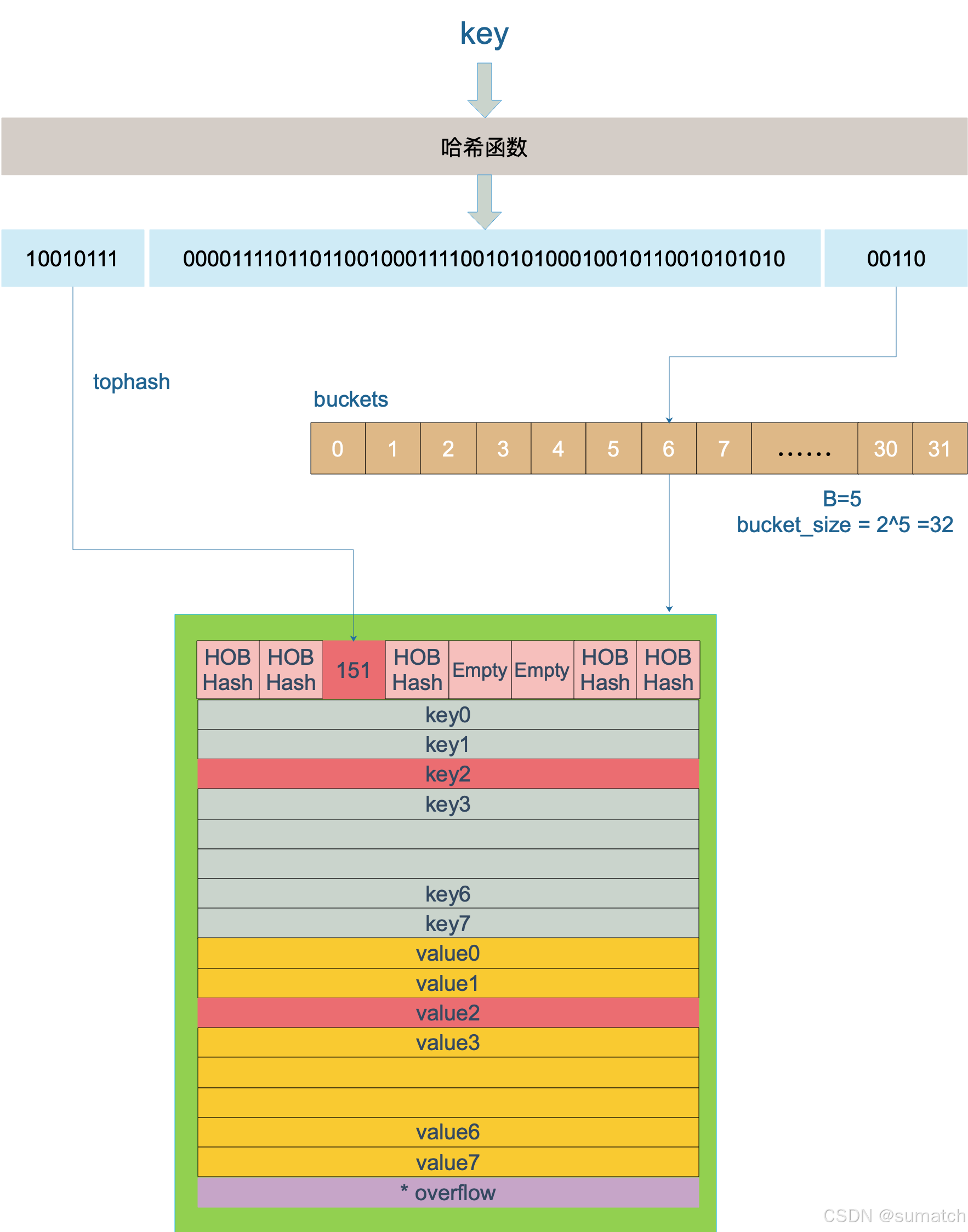
低位哈希值:01010,是用来确定,当前的数据存在了哪个 bucket(桶)。
高位哈希值:10010111 是用来确定当前的 bucket(桶)有没有所存储的数据的。
上图中,假定 B = 5,所以 bucket 总数就是 2^5 = 32。首先计算出待查找 key 的哈希,使用低 5 位 00110,找到对应的 6 号 bucket,使用高 8 位 10010111,对应十进制 151,在 6 号 bucket 中寻找 tophash 值(HOB hash)为 151 的 key,找到了 2 号槽位,这样整个查找过程就结束了。
如果在 bucket 中没找到,并且 overflow 不为空,还要继续去 overflow bucket 中寻找,直到找到或是所有的 key 槽位都找遍了,包括所有的 overflow bucket。
如果查找不到,也不会返回空值,而是返回相应类型的0值。
新元素插入过程如下:
- 根据 key 值算出哈希值
- 取哈希值 低位 确定 bucket 位置
- 查找该 key 是否已经存在,如果存在则直接更新值
- 如果没找到将key,将 key 插入
如图:

通过低位 hash 找到对应 bucket 桶,再通过高位 hash 找到对应 key 值(此处可能有hash冲突和扩容)
-
查找 hash 冲突:若找到对应高位 hash 值,但 key 值不一致,则线性向下或通过扩展指针,查找key值。
-
插入 hash 冲突:先查找,若存在重复高位 hash 值,则线性向下寻空位插入。若当前 kv 数组已满,则扩展bucket,插入。

map 的扩容原理
Go 语言中的 map 是基于哈希表实现的,当元素数量增加导致哈希冲突增多时,map 会自动进行扩容以维持高效的查找性能。
-
底层数据结构
Go 的 map 底层是一个
hmap结构体,包含多个bmap桶(buckets):type hmap struct { count int // 当前元素数量 B uint8 // 当前桶数量的对数(桶数量 = 2^B) buckets unsafe.Pointer // 指向桶数组的指针 oldbuckets unsafe.Pointer // 扩容时指向旧桶数组的指针 // ... 其他字段 } type bmap struct { tophash [8]uint8 // 每个键的哈希值高8位 keys [8]keytype values [8]valuetype overflow *bmap // 溢出桶链表 } -
触发扩容的条件
map 会在以下两种情况下触发扩容:
-
装载因子过高:
当元素数量 / 桶数量 > 6.5(默认装载因子阈值)
• 计算公式:count/(2^B) > 6.5 -
溢出桶过多:当
溢出桶数量 ≥ 2^B(即常规桶数量)
• 这种情况即使装载因子不高也会触发扩容
-
-
扩容过程
扩容分为两个阶段:
第一阶段:分配新桶
-
计算新桶数量:
• 如果是装载因子过高触发的扩容:新桶数量 = 旧桶数量 * 2(B+1)
• 如果是溢出桶过多触发的扩容:新桶数量 = 旧桶数量(B不变,只是重新整理) -
分配新桶数组,将
hmap.buckets指向新桶 -
将旧桶指针保存在
hmap.oldbuckets -
设置扩容标记
hmap.nevacuate = 0
第二阶段:渐进式迁移
Go 采用渐进式扩容策略,不是一次性迁移所有数据,而是在每次写操作(插入、删除)时迁移 1-2 个旧桶到新桶:
- 每次写操作时检查是否处于扩容状态
- 如果是,则迁移当前操作涉及的旧桶及其溢出桶
- 迁移完成后,旧桶中的数据不会被删除,但会被标记为已迁移
- 当所有旧桶迁移完成后,释放
oldbuckets
-
-
数据迁移规则
迁移时,每个键值对会根据新桶数量重新计算位置:
newBucket := hash & (newNumBuckets - 1)由于桶数量总是 2 的幂次方,迁移时可以高效地确定键值对的新位置:
当桶数量翻倍时(B+1),键值对要么留在原位置,要么移动到
原位置+旧桶数量的位置 -
扩容期间的访问
在扩容期间:
• 读操作:优先从新桶查找,如果没找到再到旧桶查找
• 写操作:先触发迁移,后写入新桶 -
设计优势
- 渐进式扩容:避免一次性迁移导致的性能抖动
- 内存高效:旧桶可以逐步释放,不会瞬间占用双倍内存
- 并发安全:通过状态标记实现无锁并发检测
示例演示
m := make(map[int]string)
// 初始状态:B=0,桶数量=1
// 插入元素直到触发扩容
for i := 0; i < 7; i++ {
m[i] = fmt.Sprintf("value%d", i)
// 当插入第7个元素时,count=7 > 6.5*1,触发扩容
// 新桶数量=2,开始渐进式迁移
}
// 继续插入会触发迁移
m[8] = "value8" // 此操作会迁移一个旧桶到新桶
常规桶扩容 和 溢出桶扩容
-
扩容的两种类型
类型 触发条件 操作内容 目的 常规桶扩容 装载因子 > 6.5 ( count/(2^B) > 6.5)常规桶数量翻倍( B += 1)降低哈希冲突概率 溢出桶整理 溢出桶数量 ≥ 常规桶数量 ( 2^B)桶数量不变,数据重新散列到原数量桶 解决哈希分布不均问题
-
核心区别
常规桶扩容
- 桶数量变化:
2^B→2^(B+1)(翻倍) - 数据迁移:键值对根据新桶数量重新分布(部分留在原位置,部分迁移到新位置)
- 示例:
m := make(map[int]int, 8) // 初始 B=1,常规桶=2 // 插入13个元素后:count/(2^B)=13/2=6.5 > 6.5 → 触发扩容 // 新桶数量=4(B=2)
溢出桶整理(等量扩容)
- 桶数量不变:
2^B保持不变 - 数据迁移:所有键值对重新散列到原有数量的桶中,减少溢出链长度
- 示例:
// 假设 B=2(4个常规桶),但所有数据都哈希到同一个桶 // 导致溢出桶数量≥4 → 触发等量扩容 // 桶数量仍为4,但数据分布更均匀
- 桶数量变化:
- 底层实现逻辑
在 Go 的runtime/map.go中,扩容判断如下:
• 若func hashGrow(t *maptype, h *hmap) { // 判断是否因溢出桶过多触发 bigger := !overLoadFactor(h.count+1, h.B) // overLoadFactor = count/(2^B) > 6.5 if bigger { h.B++ // 常规桶数量翻倍 } // 迁移旧数据到新桶(渐进式) }bigger=true:常规桶扩容(B++)
• 若bigger=false:仅整理溢出桶(桶数量不变)
-
直观对比
场景 常规桶扩容 溢出桶整理 触发条件 元素太多,装载因子高 哈希冲突严重,溢出链过长 桶数量变化 翻倍( B += 1)不变 内存占用 增加 可能减少(释放多余溢出桶) 典型case 持续插入大量元素 键的哈希分布极度不均匀
- 设计意图
- 常规桶扩容:通过增加桶数量直接降低装载因子,提升查询效率(时间复杂度接近 O(1))。
- 溢出桶整理:解决因哈希函数缺陷或数据特性导致的局部堆积问题,避免长链表退化(时间复杂度趋近 O(n))。
map 是否并发安全?
map 默认是并发不安全的,同时对 map 进行并发读写时,程序会 panic。
实现map线程安全,有两种方式:
- 使用读写锁 map + sync.RWMutex
- 使用 sync.Map
sync.Map 的底层原理
sync.Map 是 Go 语言标准库中提供的一种线程安全的映射结构,适用于读多写少的场景。其设计通过 空间换时间 (同时维护两个 Map:read map 和 dirty map)的方式减少锁竞争,提高并发性能。
数据结构
sync.Map 的核心由两个字段构成:
read:一个原子指针,指向readOnly结构,包含一个非线程安全的map和一个标记位amended(表示是否有新数据写入dirty)。dirty:一个非线程安全的map,存储新写入的数据,并在需要时提升为read。
type Map struct {
mu Mutex // 用于保护dirty字段的锁
read atomic.Value // 存储 readOnly
dirty map[interface{
}]*entry // 需要加锁才能读取
misses int // 计数器,记录在从read中读取数据的时候,没有命中的次数,
// 当misses值等于dirty长度时,dirty提升为read、
type readOnly struct {
m map[interface{
}]*entry
amended bool // 标记 dirty 中是否有新数据
}
// read 和 dirty 中的 entry
type entry struct {
p atomic.Pointer[any]
}
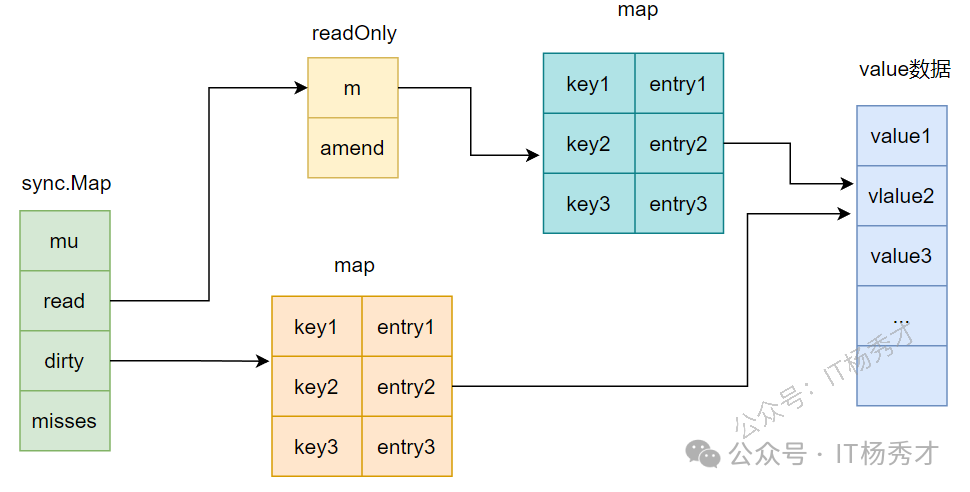
读写分离机制
读操作:
直接访问 read 中的 map,无需加锁。如果 read 中不存在且 amended 为 true,则加锁后尝试从 dirty 中读取,并递增 misses 计数。
写操作:
- 若
read中存在该键,直接更新entry的指针(原子操作)。 - 若不存在,加锁后操作
dirtymap。首次写入时会从read拷贝未被删除的键到dirty。
动态调整
当 misses 超过 dirty 的大小时,触发 dirty 提升为 read:
dirty替换read.m,新的dirty置为nil。misses重置为 0。
删除处理
删除操作通过原子标记 entry.p 为 nil 实现逻辑删除。物理删除在 dirty 提升时统一处理。
性能优势
- 读多:无锁访问
read,性能接近原生map。 - 写少:通过
dirty隔离写操作,减少锁竞争。
适用场景
- 高频读、低频写的并发场景。
- 需要保证线程安全且对性能敏感的场景
我们期望将更多的流量在 read map
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1780
1780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









