




接上文:1 k-近邻算法
了解k-近邻算法的基础后,现在通过k-近邻算法预测约会对象
- 创建kNN.py和run.py文件
编辑kNN.py并导入常用库和实现分类方法
import numpy
import operator
import matplotlib.pyplot
def Classify(dataset, labels, input, k):
...
import kNN
- 导入约会数据
约会数据的第1~3列分别为:
每年获得的飞行常客里程数
玩视频游戏所耗时间百分比
每周消费的冰淇淋公升数
约会数据的第4列表示感兴趣程度:
不喜欢的人
魅力一般的人
极具魅力的人
编辑kNN.py
def DataSetForDatingWithFile(filepath):
# 读取文件
f = open(filepath)
# 将文件里的内容以行为单位存入数组
lines = f.readlines()
# 获取行数组的数量
linesLen = len(lines)
# 创建文件内容的矩阵
matrix = numpy.zeros((linesLen, 3))
# 创建标签数组
labels = []
# 创建索引
index = 0
# 遍历行数组的行字符串
for line in lines:
# 将行字符串的空格换行去除
line = line.strip()
# 将行字符串以制表符分割成数组
array = line.split('\t')
# 将行字符串的数组前3个数据放入文件内容的矩阵
matrix[index, :] = array[0:3]
# 将行字符串的数组最后一个数据放入标签数组
doseDictionary = {
'largeDoses': 3,
'smallDoses': 2,
'didntLike': 1
}
dose = array[-1]
if dose.isdigit():
labels.append(int(dose))
else:
labels.append(doseDictionary.get(dose))
# 索引指向下一个
index += 1
return matrix, labels
- 查看约会数据
编辑run.py
dataset, labels = kNN.DataSetForDatingWithFile('./data/dating/datingTestSet.txt')
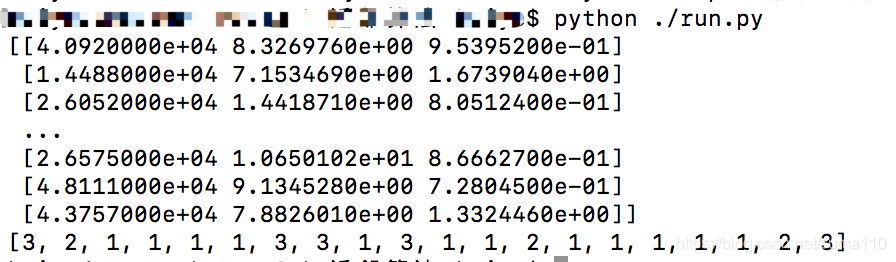
print(dataset)
print(labels[0:20])
运行run.py
显示数据
- 约会数据归一化
从数据中可看出,第一列的数据明显比其他列的数据大得多,若直接分类,必然使预测结果出现偏差(第一列的权重太大)
所以需要将数据归一化处理
编辑kNN.py
def NormalizeDataSetForDating(dataset):
# 获取数据各列的最小值
minVals = dataset.min(0)
# 获取数据各列的最大值
maxVals = dataset.max(0)
# 最大值和最小值的差值
diffVals = maxVals - minVals
# 获取数据行数
rowLength = dataset.shape[0]
# 最小值矩阵化
minMatrix = numpy.tile(minVals, (rowLength, 1))
# 差值矩阵化
diffMatrix = numpy.tile(diffVals, (rowLength, 1))
# 数据归一化
matrix = dataset - minMatrix
matrix = matrix / diffMatrix
return matrix, maxVals, minVals, diffVals
- 查看归一化数据
编辑run.py
dataset, labels = kNN.DataSetForDatingWithFile('./data/dating/datingTestSet.txt')
dataset, maxVals, minVals, diffVals = kNN.NormalizeDataSetForDating(dataset)
print(dataset)
运行run.py

从图中可看出,所有数据都在0到1之间,数据的每个列的权重都一样
- 查看图形化的归一化数据
编辑kNN.py
def ShowPlotForDating(dataset, labels, col1, col2):
figure = matplotlib.pyplot.figure()
subplot = figure.add_subplot(111)
subplot.scatter(dataset[:, col1], dataset[:, col2], 15.0 * numpy.array(labels), 15.0 * numpy.array(labels))
matplotlib.pyplot.show()
编辑run.py并运行
dataset, labels = kNN.DataSetForDatingWithFile('./data/dating/datingTestSet.txt')
dataset, maxVals, minVals, diffVals = kNN.NormalizeDataSetForDating(dataset)
kNN.ShowPlotForDating(dataset, labels, 0, 1)
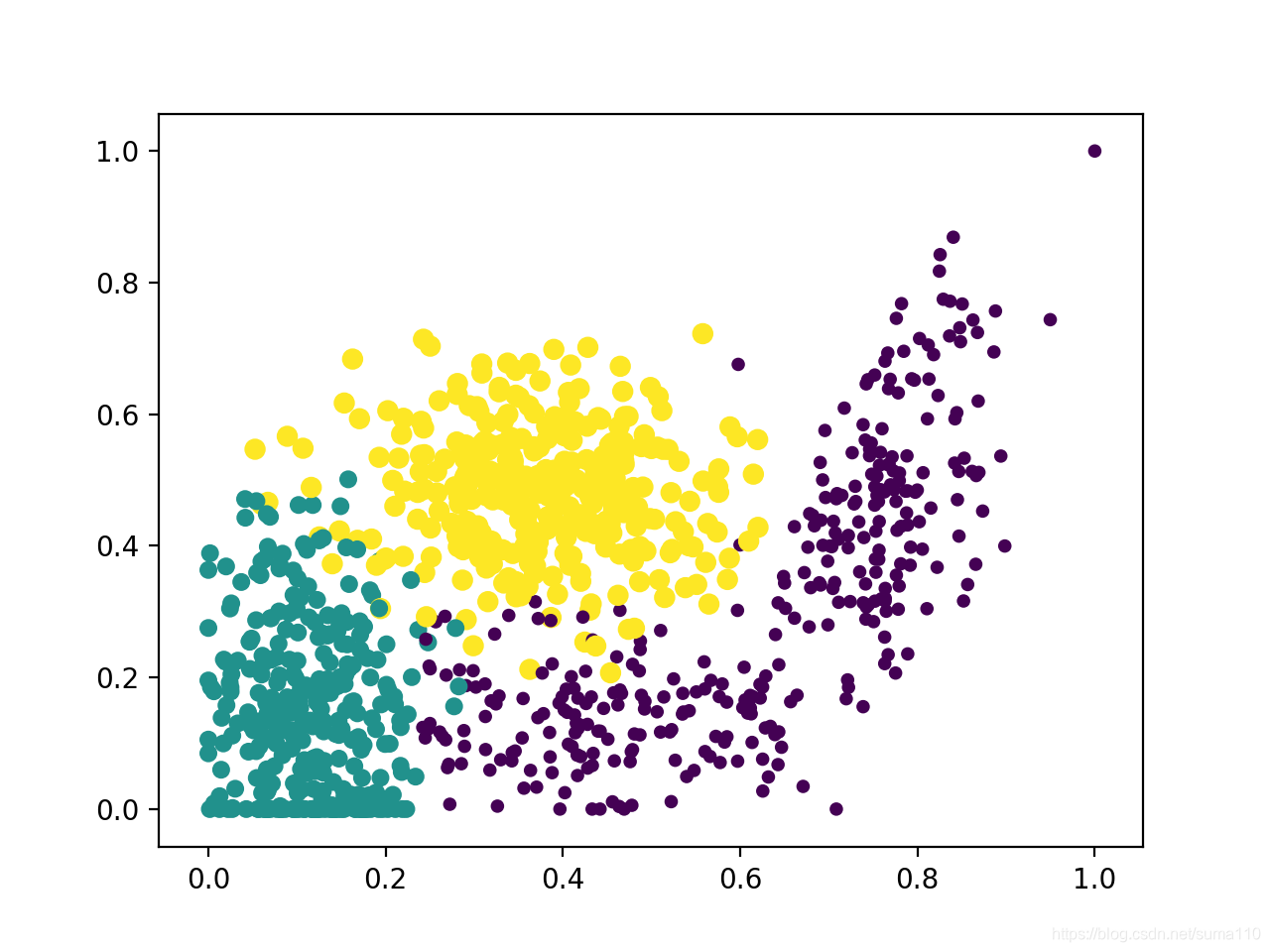
dataset, labels = kNN.DataSetForDatingWithFile('./data/dating/datingTestSet.txt')
dataset, maxVals, minVals, diffVals = kNN.NormalizeDataSetForDating(dataset)
kNN.ShowPlotForDating(dataset, labels, 1, 2)
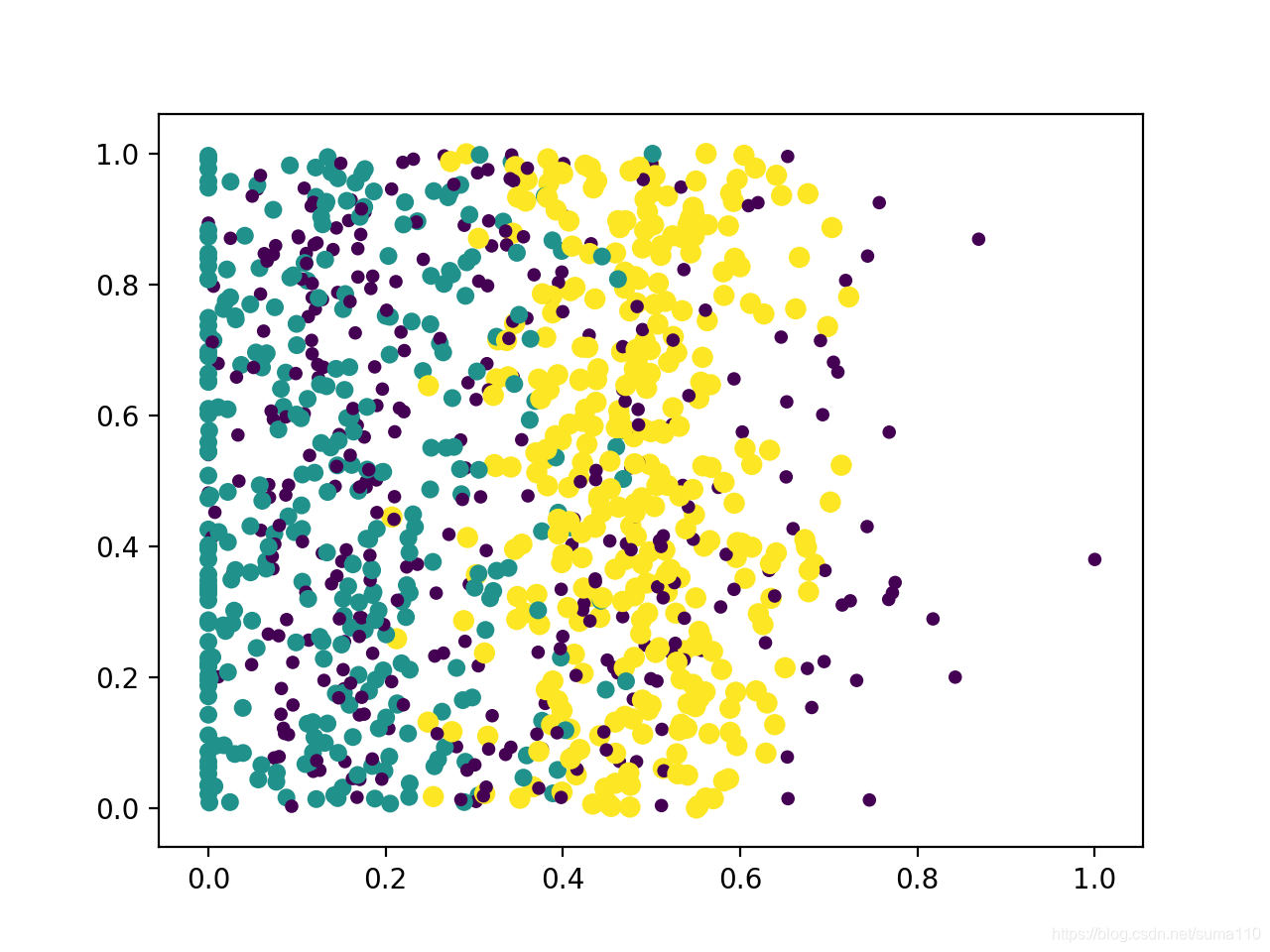
dataset, labels = kNN.DataSetForDatingWithFile('./data/dating/datingTestSet.txt')
dataset, maxVals, minVals, diffVals = kNN.NormalizeDataSetForDating(dataset)
kNN.ShowPlotForDating(dataset, labels, 0, 2)
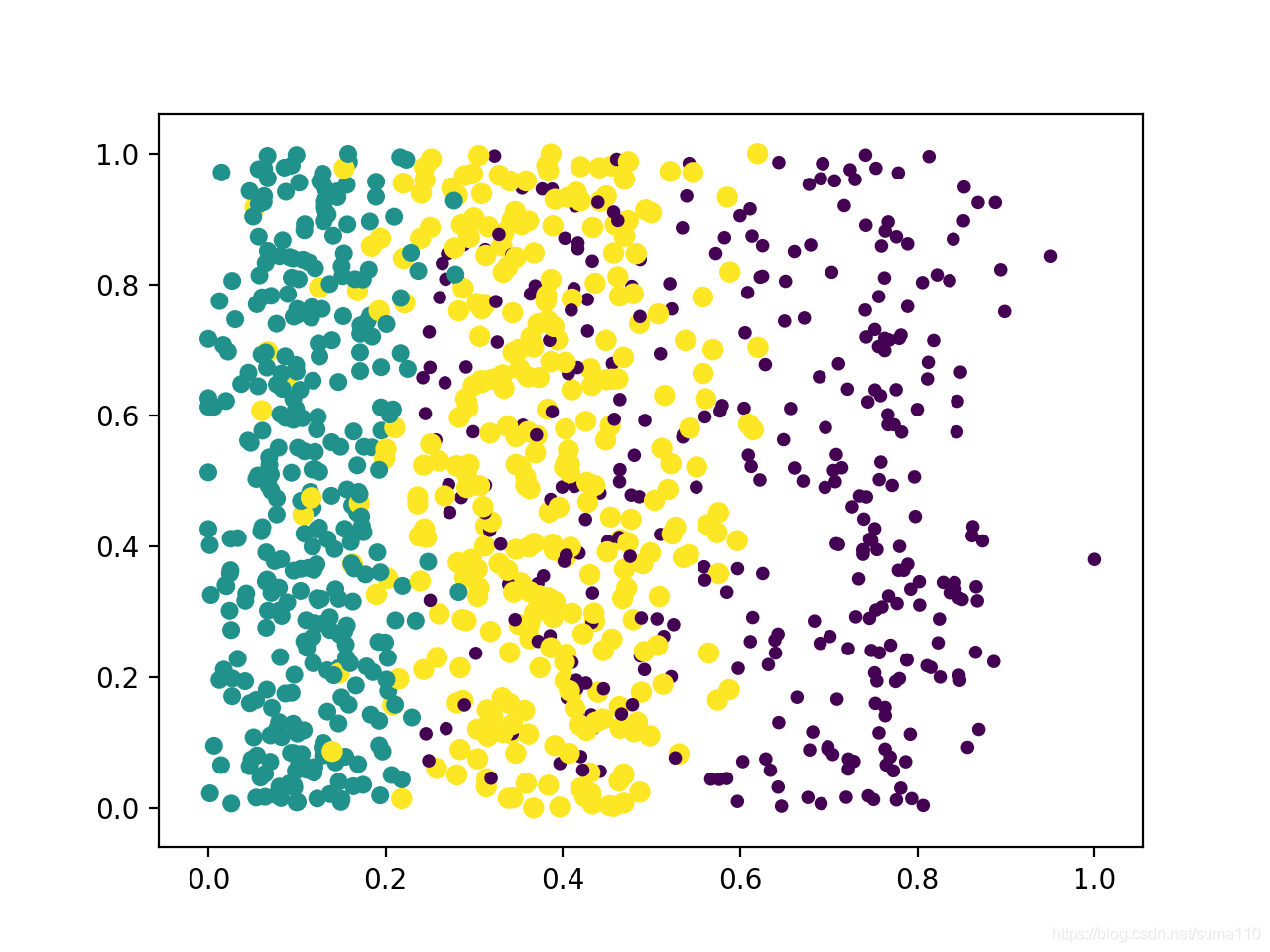
- 测试预测效果
先用伪代码了解执行逻辑
1 将约会数据分为两个部分:0~n行数据作为测试数据,n+1行以后的数据作为训练数据
2 遍历0~n行数据,并预测每行数据,获取预测结果
3 将预测结果与对应数据的真实结果对比,看看是否一致
4 统计错误数量
编辑kNN.py并实现测试方法
def DatingClassifyTest():
# 读取约会数据
dataset, labels = DataSetForDatingWithFile('./data/dating/datingTestSet.txt')
# 归一化约会数据
dataset, maxVals, minVals, diffVals = NormalizeDataSetForDating(dataset)
# 定义测试数据的数量
rowLength = dataset.shape[0]
radio = 0.1
count = int(rowLength * radio)
# 统计错误预测的数量
errorCount = 0.0
# 遍历测试数据并预测
for i in range(count):
# 对测试数据分类并预测分类结果
label = Classify(dataset[count:rowLength, :], labels[count:rowLength], dataset[i, :], 5)
print('the classifier came back with: %d, the real answer is: %d'%(label, labels[i]))
# 如果预测结果与真实结果不一致,统计错误数量
if (label != labels[i]):
errorCount += 1.0
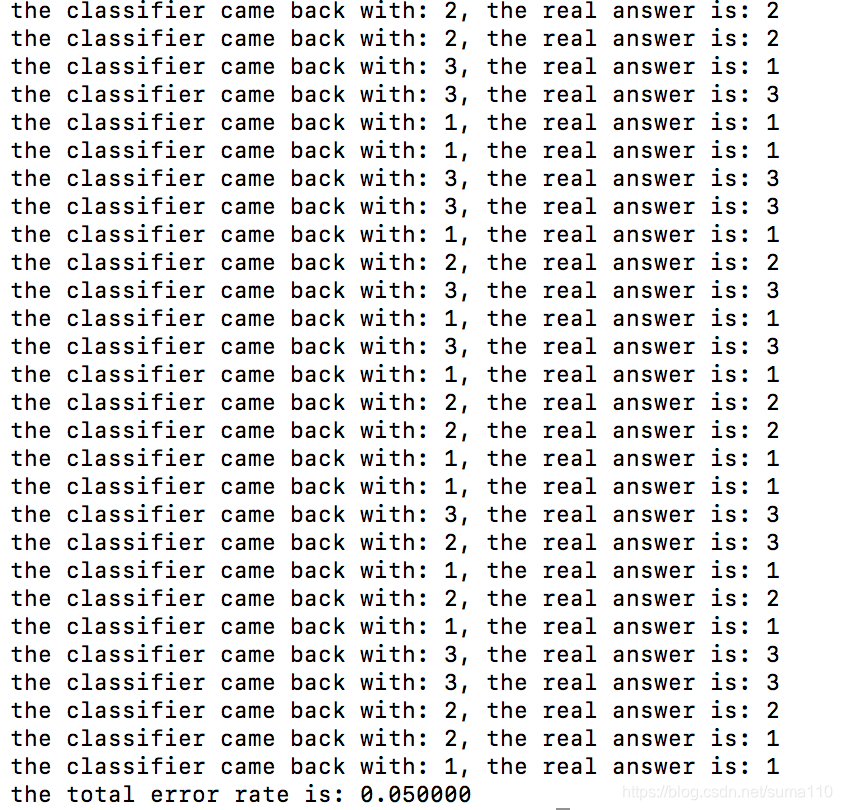
print('the total error rate is: %f'%(errorCount / count))
编辑kNN.py并运行
kNN.DatingClassifyTest()
- 输入信息并预测好感
编辑kNN.py
归一化输入数据:
def NormalizeInputForDating(input, minVals, diffVals):
return (input - minVals) / diffVals
输入信息并预测好感:
def DatingClassifyWithInput():
doseDictionary = ['not at all', 'in small doses', 'in large doses']
# 获取输入数据
ffMiles = float(input('frequent flier miles earned per year? '))
percentTats = float(input('percent of time spent playing video game? '))
iceCream = float(input('liters of ice cream consumed per year? '))
inputData = numpy.array([ffMiles, percentTats, iceCream])
# 获取训练数据
dataset, labels = DataSetForDatingWithFile('./data/dating/datingTestSet2.txt')
dataset, maxVals, minVals, diffVals = NormalizeDataSetForDating(dataset)
# 将输入数据归一化
inputData = NormalizeInputForDating(inputData, minVals, diffVals)
# 预测输入数据
label = Classify(dataset, labels, inputData, 5)
print('you will probably like this person: ', doseDictionary[label - 1])
编辑run.py并运行
kNN.DatingClassifyWithInput()
运行结果

附上代码:k-近邻预测约会对象

















 240
240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









