




 本文全面介绍了Apache Spark的基础知识,包括Spark的定义、学习原因、体系结构与部署方式,并深入探讨了Spark Demo程序执行原理及核心算子功能。通过本文,读者可以了解到Spark如何基于内存提高大数据处理效率。
本文全面介绍了Apache Spark的基础知识,包括Spark的定义、学习原因、体系结构与部署方式,并深入探讨了Spark Demo程序执行原理及核心算子功能。通过本文,读者可以了解到Spark如何基于内存提高大数据处理效率。
我们先如下这张图的最底层开始学习:
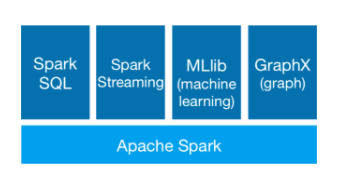
首先明确学习新技术之前,我们需要了解下学习的对象,学习的原因、学习的主要内容以及学习的过程等,按照这种思路,我进行了如下的描述:
一、什么是Spark
请查看官网的解释:http://spark.apache.org/
Apache Spark™ is a unified analytics engine for large-scale data processing.
为什么要学习Spark?
1、因为目前发现了MapReduce本身存在着许多的缺点和不足,其实最主要是MapReduce的核心Shuffle,在运行过程中会产生大量I/O,一般而言,一次MapReduce程序运算,一般会产生6-7次的IO操作,效率比较低。
2、Spark的特点:基于内存
(1)快
(2)易用
(3)通用
(4)兼容性
二、Spark的体系结构与部署(重点)
1、体系结构:主从结构(单点故障)
官网提供了一张图 http://spark.apache.org/docs/latest/cluster-overview.html
2、安装部署
(1)伪分布
(2)全分布
3、Spark HA:两种方式
(1)基于文件目录: 用于开发测试
(2)基于ZooKeeper:用于生产环境
三、执行Spark Demo程序
1、执行Spark任务的工具
(1)spark-submit: 相当于 hadoop jar 命令 —> 提交MapReduce任务(jar文件 ) 提交Spark的任务(jar文件 )
(2)spark-shell:类似Scala的REPL命令行,类似Oracle中的SQL*PLUS,Spark的交互式命令行。
2、使用IDEA或者Scala IDE开发程序:WordCount
(1)Java版本
(2)Scala版本
四、Spark执行原理分析
1、分析WordCount程序处理过程
2、Spark提交任务的流程:类似Yarn调度任务的过程
五、Spark的算子(函数)
1、重要:什么是RDD(类)
2、RDD的算子
(1)Transformation:不会触发计算
(2)Action:会触发计算
3、RDD的缓存机制
4、RDD的容错机制
5、RDD依赖关系
六、Spark Core编程案例
学习Spark Core 内容介绍
最新推荐文章于 2021-04-13 16:06:41 发布


















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











