




 本文介绍如何利用Python的Selenium库结合CSS选择器来精确地定位网页上的各种元素,包括基本用法及进阶技巧,如属性选择器等。
本文介绍如何利用Python的Selenium库结合CSS选择器来精确地定位网页上的各种元素,包括基本用法及进阶技巧,如属性选择器等。
以一个小说网站为例
d = webdriver.Chrome()
d.get("https://www.yangguiweihuo.com/")例 1.
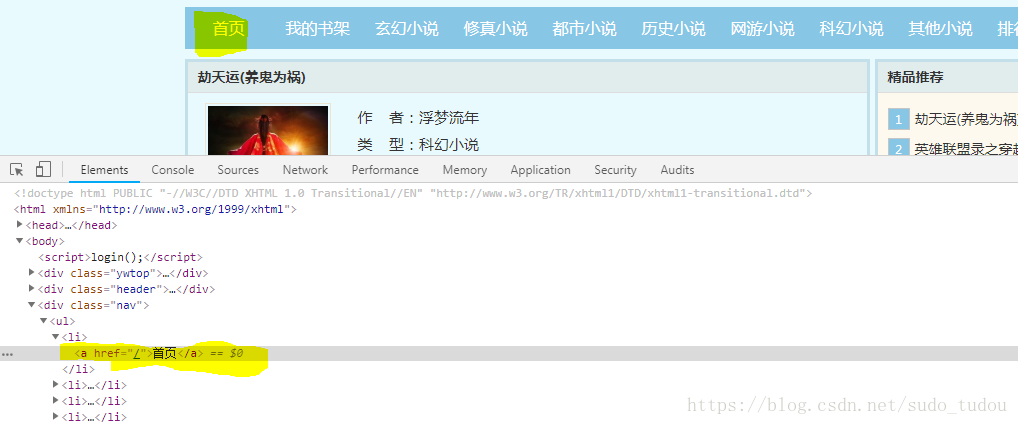
d.find_element_by_css_selector('a[href="/"]').texta[href="/"] a是一个元素,现在取了a元素的href属性,href赋的值是"/"
例 2.
d.find_element_by_css_selector('a[href="/xuanhuanxiaoshuo/"]').text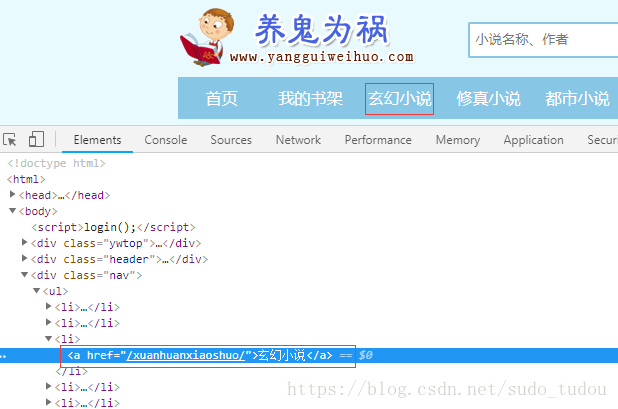
总结
<a href="/xuanhuanxiaoshuo/">玄幻小说</a>
1、E(element)代表是一个元素,att(attribute)代表一个元素的属性,val(value)代表一个值
2、att^ 匹配以val值开头的元素
d.find_element_by_css_selector('a[href^="/xuanhuan"]').text3、att$ 匹配以val值结尾的元素
d.find_element_by_css_selector('a[href$="xiaoshuo/"]').text4、att* 匹配包含val值的元素
d.find_element_by_css_selector('a[href*="huanxiao"]').text5、E[att1='v1'][att2*='v2'] 匹配一个元素的2个值
<input type="submit" class="int" value="登 陆">
d.find_element_by_css_selector('input[type="submit"][class="int"]').click()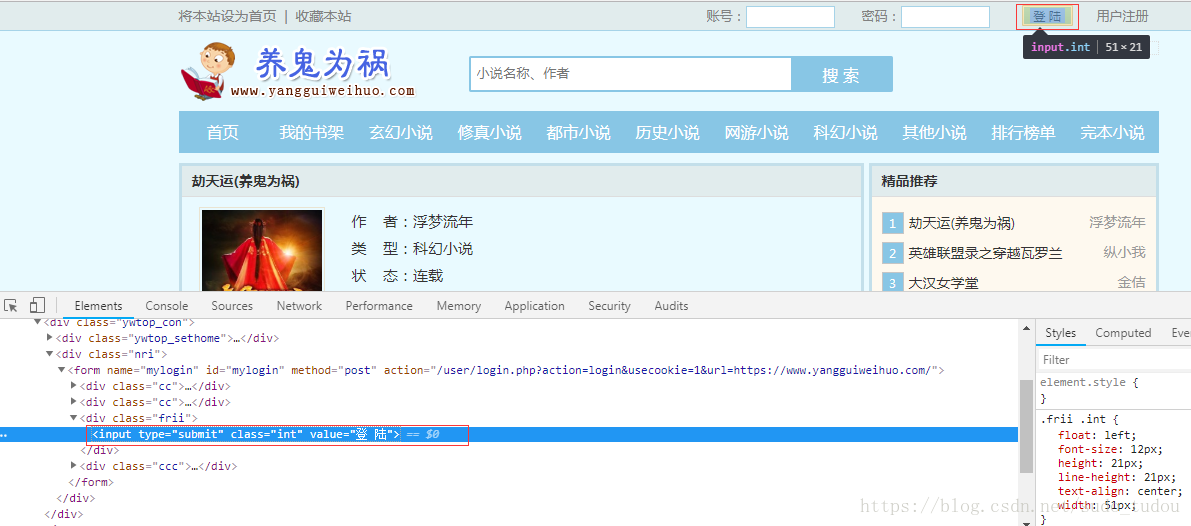
规则(转载其他文档)
| E[att='val'] | 属性att 的值为val 的E 元素(区分大小写) |
| E[att^='val'] | 属性att 的值以val 开头的E 元素(区分大小写) |
| E[att$='val'] | 属性att 的值以val 结尾的E 元素(区分大小写) |
| E[att*='val'] | 属性att 的值包含val 的E 元素(区分大小写) |
| E[att1='v1'][att2*='v2'] | 属性att1 的值为v1,att2 的值包含v2 (区分大小写) |

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









