



引入:
python爬虫中经常会用到的解析模块之一就是parsel了,在parsel中,我们可以将请求后的字符串格式解析成xpath,进行内容的匹配,为了熟悉这其中xpath的语法,我们准备对DATA.GOV.HK中有关environment的公开数据集标题进行爬取。
一、【准备】导入数据所在页面的html内容
明确我们的目标,在DATA.GOV.HK官网中,我们需要找到的是含有所有数据集标题的页面,刚好从它的顶栏中的data目录下面,我们可以点击进入datasets页面。
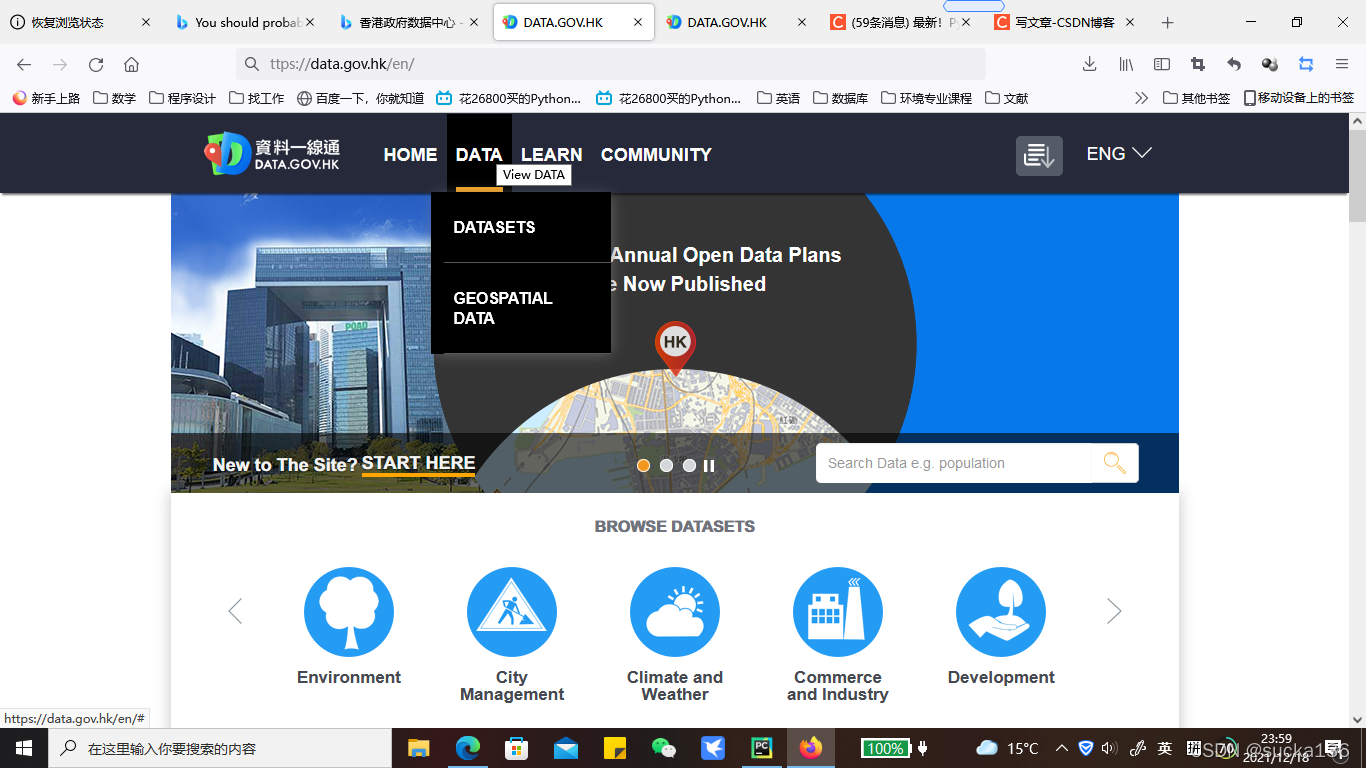
进入datasets页面后,可以直接看到所有的数据集标题,在左侧有关于数据种类的筛选栏【Data Categories】,我们选择目录下方的【environment】之后,页面会自动刷新,新加载的页面就是本次爬虫所需要的html内容啦!
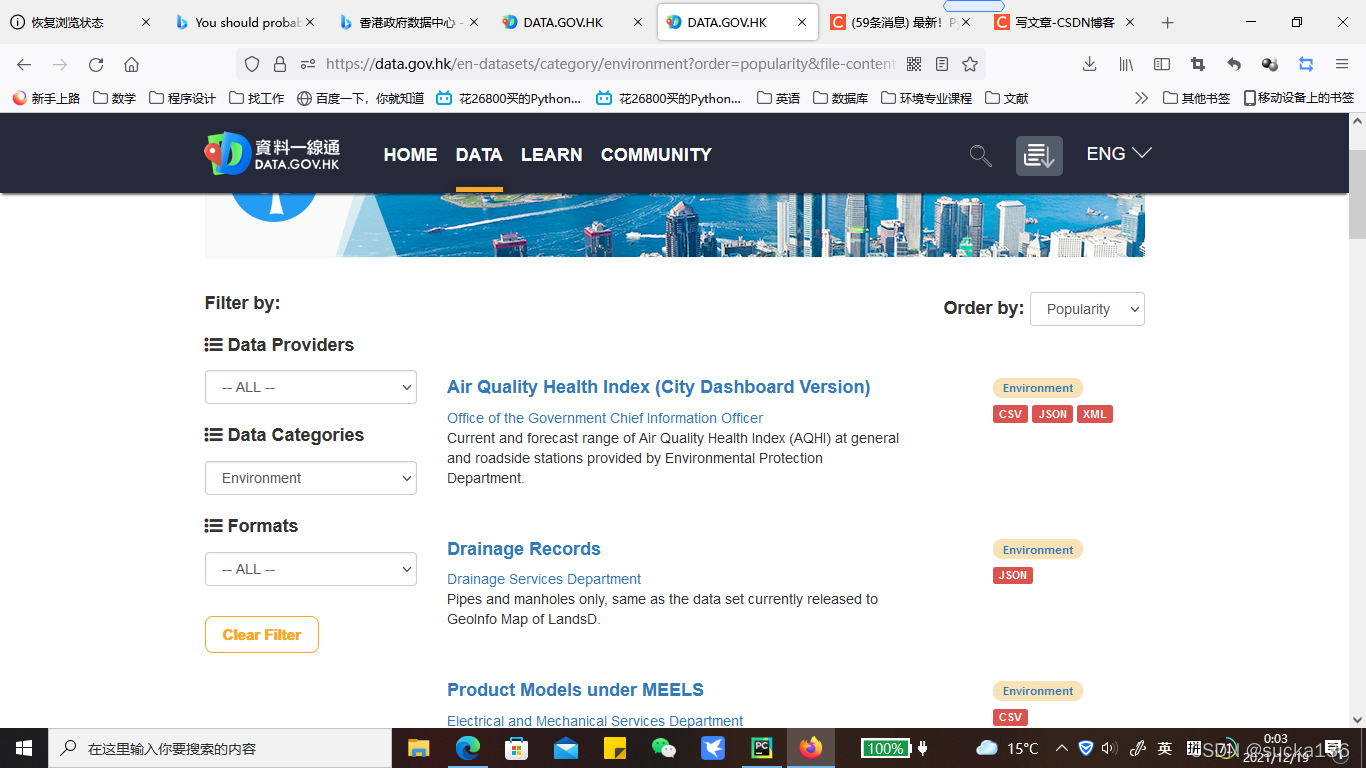
很显然,我们的url地址也变成了https://data.gov.hk/en-datasets/category/environment?order=popularity&file-content=no
悄咪咪说一句,这个链接也太友好了吧(dddd),想要别的种类数据的直接把category/后面的名称改掉就可以。
导入html内容
url = 'https://data.gov.hk/en-datasets/category/environment?order=name&file-content=no'
#接收请求页面的html内容
rp = requests.get(url)二、parsel模块的安装与使用
1、安装 (win10系统)
pip install parsel2、使用
import parsel
使用parsel解析html页面,创建一个parsel.Selector对象
sel = parsel.Selector(rp.text)三、xpath匹配
1、了解parsel中如何使用xpath匹配
sel.xpath('xpath语法/text()').getall() #text()-获取节点下的文本内容,getall()-获取所有2、xpath语法 (xpath路径的写法)
| 表达式 | 描述 |
| nodename | 选取此节点的所有子节点 |
| / | 从根节点选取 |
| // | 可越多级,从当前节点匹配html中的所有符合的节点 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
为了搞清楚表格中的表达式如何写出定位到所需的xpath路径,我们先来分析一下页面源代码。
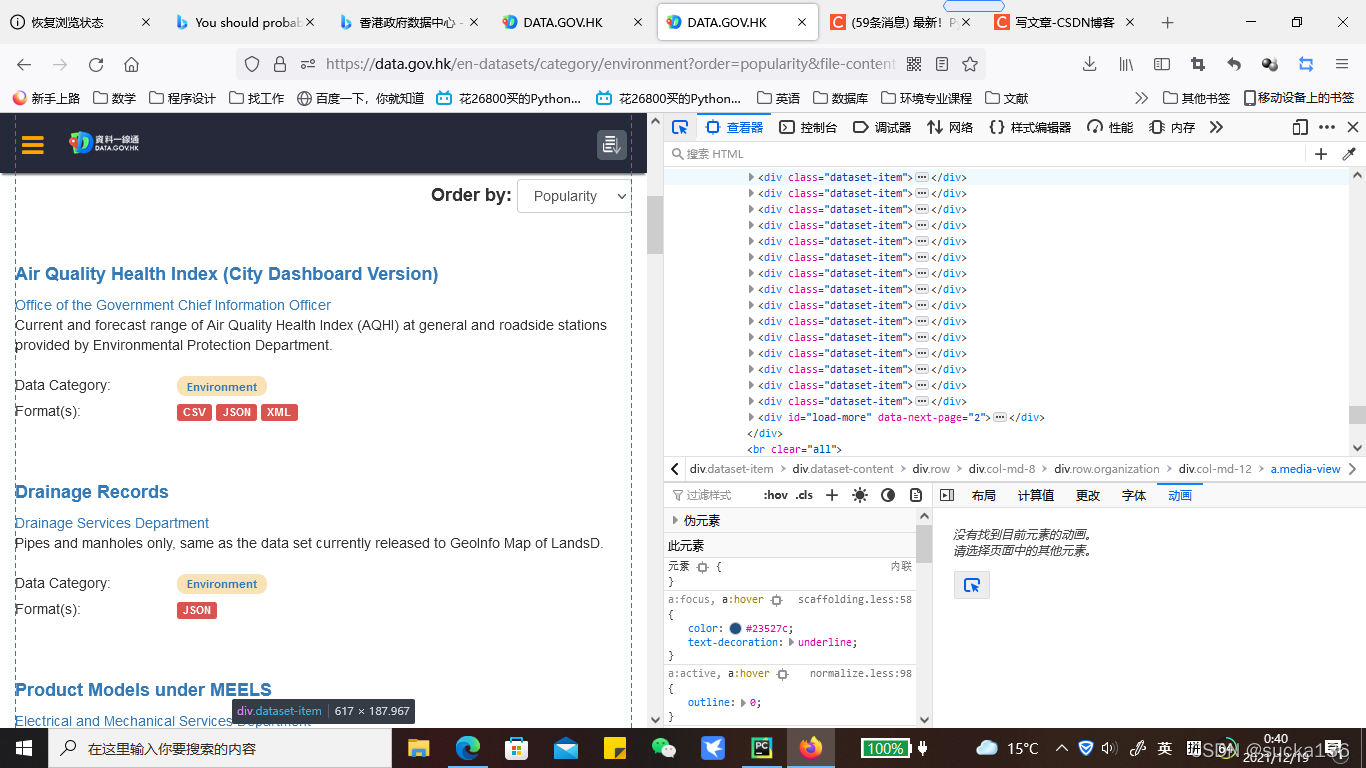
清楚看到,所有的datasets的简介,都被每一个div[@class='dataset-item']所生成,我们观察其中一个中它的子孙节点可以发现,在/h3[@class='dataset-heading']这里有一个子节点:<a>节点,恰好里面的文本就是了我们想要的标题名称,只要利用xpath定位到所有属性为的<a>节点即可。(小技巧:页面中h3节点只存在于属性为class='dataset-item'中时,我们便可以直接把根节点设置为h3)
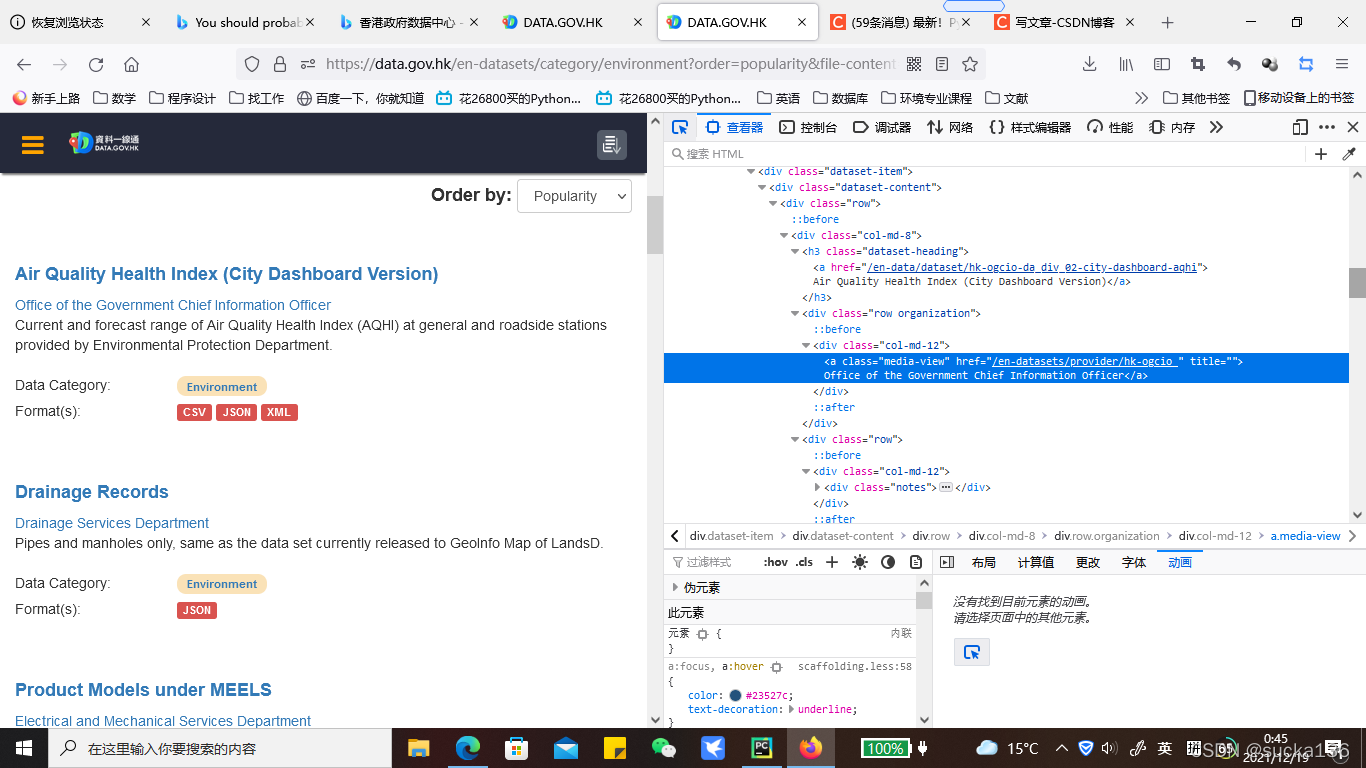
实现语句:
sel.xpath('//h3[@class="dataset-heading"]/a/text()').getall()分析以上语句中的xpath语法:
//h3 #定位到所有标签名为h3的元素
//h3[@class=''dataset-heading''] #定位到所有标签名为h3且属性名为dataset-heading的元素,必须是双引号
//h3[@class=''dataset-heading'']/a #定位到所有标签名为h3且属性名为dataset-heading的元素的元素名为a的子节点
这时肯定会有疑问了,为啥可以打个中括号??别急,我们来打印结果看看先。
![]()
我们可以看到,实际上,xpath解析的结果会以列表的形式返回,这也就默许了xpath语法可以结合列表属性,对节点查找的内容进行修改。
| 路径写法 | 结果 |
| /父节点/子节点[1] | 选取属于父节点中子元素的第一个子元素 |
| /父节点/子节点[last()] | 选取属于父节点中子元素的最后一个子元素 |
| /父节点/子节点[position()] | 选取最前面的两个属于父节点的子元素 |
| //元素名[@属性名] | 选取拥有该属性名的所有元素 |
| //元素名[@属性名=“x”] | 选取拥有值为x的属性的所有元素 |
| /父节点/子元素名[某孙元素>u]/另一个孙元素 | 选取所有某孙元素大于u的父节点下子元素的另一个孙元素 |


















 771
771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









