




 FSDP是一种数据并行训练算法,通过分片模型参数和状态以减少内存需求,提高计算效率。它已在FairScale库中实现,可用于大规模NLP和Vision模型训练,如GPT-3,比传统方法如DDP更具优势。
FSDP是一种数据并行训练算法,通过分片模型参数和状态以减少内存需求,提高计算效率。它已在FairScale库中实现,可用于大规模NLP和Vision模型训练,如GPT-3,比传统方法如DDP更具优势。
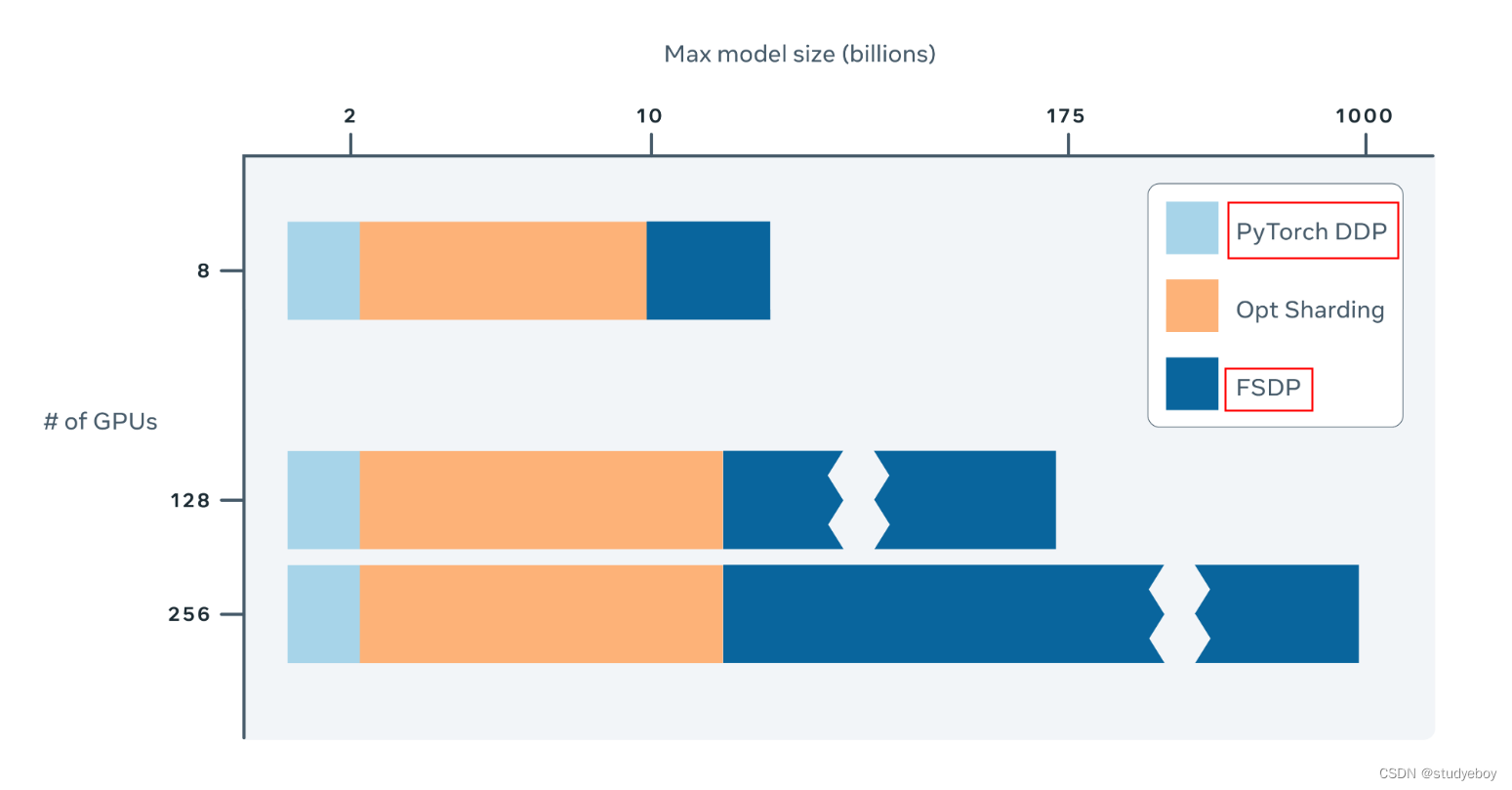
完全分片数据并行 (FSDP) ,它将AI 模型的参数分片到数据并行工作器上,并且可以选择将部分训练计算卸载到 CPU。顾名思义,FSDP 是一种数据并行训练算法。尽管参数被分片到不同的GPU,但每个微批次数据的计算仍然是每个 GPU Worker 本地的。这种概念上的简单性使得 FSDP 更容易理解,并且更适用于广泛的使用场景(与层内并行和管道并行相比)。与优化器状态+梯度分片数据并行方法相比,FSDP 参数分片更均匀,并且能够通过训练期间的通信和计算重叠获得更好的性能。
借助 FSDP,现在可以使用更少的 GPU 更有效地训练数量级更大的模型。FSDP 已在FairScale 库中实施,允许工程师和开发人员使用简单的 API 扩展和优化模型的训练。在 Facebook,FSDP 已经被集成并测试用于训练我们的一些NLP和Vision模型。
大规模训练的计算成本高
NLP 研究是一个特殊领域,我们可以看到有效利用计算来训练人工智能的重要性。去年,OpenAI 宣布他们已经训练了GPT-3,这是有史以来最大的神经语言模型,拥有 1750 亿个参数。据估计,训练GPT-3 大约需要 355 个 GPU 年,相当于 1,000 个 GPU 连续工作四个多月。
除了需要大量的计算和工程资源之外,大多数像这样的扩展方法都会引入额外的通信成本,并要求工程师仔细评估内存使用和计算效率之间的权衡。例如,典型的数据并行训练需要在每个 GPU 上维护模型的冗余副本,并且模型并行训练会引入额外的通信成本以在工作线程 (GPU) 之间移动激活。
相比之下,FSDP 相对来说不需要权衡。它通过跨 GPU 分片模型参数、梯度和优化器状态来提高内存效率,并通过分解通信并将其与前向和后向传递重叠来提高计算效率。FSDP 产生与标准分布式数据并行 (DDP) 训练相同的结果,并且可在易于使用的界面中使用,该界面是 PyTorch 的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 487
487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









