








1. Netfilter/IPTables简介
Netfilter/IPTables是继2.0.x的ipfwadm、2.2.x的ipchains之后,新一代的 Linux防火墙机制。Netfilter采用模块化设计,具有良好的可扩充性。其重要工具模块IPTables连接到 NetFilter的架构中,并允许使用者对数据报进行过滤、地址转换、处理等操作.Netfilter提供了一个框架,将对网络代码的直接干涉降到最低,并允许用规定的借口将其他包处理代码以模块的形式添加到内核中,具有极强的灵活性,当然自从2.6内核后,netfilter也把NAT加了进来.
开篇先来了一段专业叙述^^,其实本人接触netfilter也时日不多,一直想把整个框架流程给搞明白,做网络性能优化的时候接触了点,后来又实现8021p也用到了些(主要和过滤策略结合起来).这里就3.1.1的内核做了个分析.下面先看下源码树:
源码目录:kernel/net/ipv4/netfilter/*
Kernel/net/ipv6/netfilter/*
Kernel/net/netfilter/*
2.netfilter的功能框架
netfilter主要采用连接跟踪(Connection Tracking)、包过滤(Packet Filtering)、地址转换(NAT)、包处理(Packet Mangling)4种关键技术.
连接追踪
连接跟踪是包过滤、地址转换的基础,它作为一个独立的模块运行。采用连接跟踪技术在协议栈低层截取数据包,将当前数据包及其状态信息与历史数据包及其状态信息进行比较,从而得到当前数据包的控制信息,根据这些信息决定对网络数据包的操作,达到保护网络的目的.
当下层网络接收到初始化连接同步(Synchronize,SYN)包,将被netfilter规则库检查。该数据包将在规则链中依次序进行比较。如果该包应被丢弃,发送一个复位(Reset,RST)包到远端主机,否则连接接收。这次连接的信息将被保存在连接跟踪信息表中,并表明该数据包所应有的状态。这个连接跟踪信息表位于内核模式下,其后的网络包就将与此连接跟踪信息表中的内容进行比较,根据信息表中的信息来决定该数据包的操作。因为数据包首先是与连接跟踪信息表进行比较,只有SYN包才与规则库进行比较,数据包与连接跟踪信息表的比较都是在内核模式下进行的,所以速度很快.
包过滤
包过滤检查通过的每个数据包的头部,然后决定如何处置它们,可以选择丢弃,让包通过,或者更复杂的操作.
地址转换
网络地址转换源(NAT)分为(Source NAT,SNAT)和目的NAT(Destination NAT, DNAT)2种不同的类型。SNAT是指修改数据包的源地址(改变连接的源IP)。SNAT会在数据包送出之前的最后一刻做好转换工作。地址伪装(Masquerading)是SNAT的一种特殊形式。DNAT 是指修改数据包的目标地址(改变连接的目的IP)。DNAT 总是在数据包进入以后立即完成转换。端口转发、负载均衡和透明代理都属于DNAT.
包处理
利用包处理可以设置或改变数据包的服务类型(Type of Service, TOS)字段;改变包的生存期(Time to Live, TTL)字段;在包中设置标志值,利用该标志值可以进行带宽限制和分类查询.
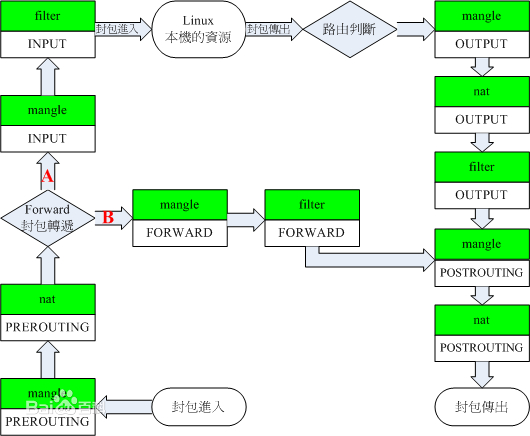
通过上面的概述我们已经对netfilter已经有了个大致的概念和模块的划分.那面我们还是看一下它的框架图吧:
这个图包括了应该所以的hook的地方,具体有IP层的5个,bridge的5个,还有arp层的3个. 这个图只是标出钩子点.没有具体的函数调用.(谅解^^).下面我们就分析下这个框架是如何运作起来的.
通过上一篇NAPI机制我们知道,最后数据包通过netif_receive_skb这个函数来查找具体的以太网协议处理函数继续往上走.下面我们就来看下这个函数:
/**
* netif_receive_skb - process receive buffer from network
* @skb: buffer to process
*
* netif_receive_skb() is the main receive data processing function.
* It always succeeds. The buffer may be dropped during processing
* for congestion control or by the protocol layers.
*
* This function may only be called from softirq context and interrupts
* should be enabled.
*
* Return values (usually ignored):
* NET_RX_SUCCESS: no congestion
* NET_RX_DROP: packet was dropped
*/
int netif_receive_skb(struct sk_buff *skb)
{
if (netdev_tstamp_prequeue)
net_timestamp_check(skb);
if (skb_defer_rx_timestamp(skb))
return NET_RX_SUCCESS;
#ifdef CONFIG_RPS
{
struct rps_dev_flow voidflow, *rflow = &voidflow;
int cpu, ret;
rcu_read_lock();
cpu = get_rps_cpu(skb->dev, skb, &rflow);
if (cpu >= 0) {
ret = enqueue_to_backlog(skb, cpu, &rflow->last_qtail);
rcu_read_unlock();
} else {
rcu_read_unlock();
ret = __netif_receive_skb(skb);
}
return ret;
}
#else
return __netif_receive_skb(skb);
#endif
}
这里我们发现具体的处理数据的代码已经被封装了. 包括我们看3.1.1的process_backlog代码就会清楚,它是直接调用了__netif_receive_skb这个函数:
点击(此处)折叠或打开
- static int __netif_receive_skb(struct sk_buff *skb)
- {
- struct packet_type *ptype, *pt_prev;
- rx_handler_func_t *rx_handler;
- struct net_device *orig_dev;
- struct net_device *null_or_dev;
- bool deliver_exact = false;
- int ret = NET_RX_DROP;
- __be16 type;
-
- if (!netdev_tstamp_prequeue)
- net_timestamp_check(skb);
-
- trace_netif_receive_skb(skb);
-
- /* if we've gotten here through NAPI, check netpoll */
- if (netpoll_receive_skb(skb))
- return NET_RX_DROP;
-
- if (!skb->skb_iif)
- skb->skb_iif = skb->dev->ifindex;
- orig_dev = skb->dev;
-
- skb_reset_network_header(skb);
- skb_reset_transport_header(skb);
- skb_reset_mac_len(skb);
-
- pt_prev = NULL;
-
- rcu_read_lock();
-
- another_round:
-
- __this_cpu_inc(softnet_data.processed);
-
- if (skb->protocol == cpu_to_be16(ETH_P_8021Q)) {
- skb = vlan_untag(skb);
- if (unlikely(!skb))
- goto out;
- }
-
- #ifdef CONFIG_NET_CLS_ACT
- if (skb->tc_verd & TC_NCLS) {
- skb->tc_verd = CLR_TC_NCLS(skb->tc_verd);
- goto ncls;
- }
- #endif
-
- list_for_each_entry_rcu(ptype, &ptype_all, list) {
- if (!ptype->dev || ptype->dev == skb->dev) {
- if (pt_prev)
- ret = deliver_skb(skb, pt_prev, orig_dev);
- pt_prev = ptype;
- }
- }
-
- #ifdef CONFIG_NET_CLS_ACT
- skb = handle_ing(skb, &pt_prev, &ret, orig_dev);
- if (!skb)
- goto out;
- ncls:
- #endif
-
- rx_handler = rcu_dereference(skb->dev->rx_handler);
- if (rx_handler) {
- if (pt_prev) {
- ret = deliver_skb(skb, pt_prev, orig_dev);
- pt_prev = NULL;
- }
- switch (rx_handler(&skb)) {
- case RX_HANDLER_CONSUMED:
- goto out;
- case RX_HANDLER_ANOTHER:
- goto another_round;
- case RX_HANDLER_EXACT:
- deliver_exact = true;
- case RX_HANDLER_PASS:
- break;
- default:
- BUG();
- }
- }
-
- if (vlan_tx_tag_present(skb)) {
- if (pt_prev) {
- ret = deliver_skb(skb, pt_prev, orig_dev);
- pt_prev = NULL;
- }
- if (vlan_do_receive(&skb)) {
- ret = __netif_receive_skb(skb);
- goto out;
- } else if (unlikely(!skb))
- goto out;
- }
-
- /* deliver only exact match when indicated */
- null_or_dev = deliver_exact ? skb->dev : NULL;
-
- type = skb->protocol;
- list_for_each_entry_rcu(ptype,
- &ptype_base[ntohs(type) & PTYPE_HASH_MASK], list) {
- if (ptype->type == type &&
- (ptype->dev == null_or_dev || ptype->dev == skb->dev ||
- ptype->dev == orig_dev)) {
- if (pt_prev)
- ret = deliver_skb(skb, pt_prev, orig_dev);
- pt_prev = ptype;
- }
- }
-
- if (pt_prev) {
- ret = pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
- } else {
- atomic_long_inc(&skb->dev->rx_dropped);
- kfree_skb(skb);
- /* Jamal, now you will not able to escape explaining
- * me how you were going to use this. :-)
- */
- ret = NET_RX_DROP;
- }
-
- out:
- rcu_read_unlock();
- return ret;
- }
这里我们不关注其他代码,只关注黑体标注的部分.首先是第一个list_for_each_entry_rcu部分,它查询ptype_all链表注册的协议处理函数,这里匹配的是ETH_P_ALL(具体定义在if_ether.h头文件里),注册是通过dev_add_pack这个函数,这个链表默认为空. 第二个list_for_each_entry_rcu就是具体的查询具体协议的处理函数里,比如ip_rcv . 它查询的是ptype_base链表,注册函数依然是dev_add_pack函数.这里我们贴出部分关键代码:
type = skb->protocol;
list_for_each_entry_rcu(ptype,
&ptype_base[ntohs(type) & PTYPE_HASH_MASK], list) {
if (ptype->type == type &&
(ptype->dev == null_or_dev || ptype->dev == skb->dev ||
ptype->dev == orig_dev)) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
}
.....
通过deliver_skb就调用到了具体的协议接受模块了.但是我们发现在__netif_receive_skb里没有handle_bridge函数,那么哪里来处理bridge的包呢? 后来发现在两个list_for_each_entry_rcu查询之间有这么一行:
rx_handler = rcu_dereference( skb->dev->rx_handler
















 1945
1945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









