




 本文是关于深度学习优化方法的学习笔记,涵盖了Mini-Batch Gradient Descent、指数加权平均、Momentum、RMSprop、Adam算法以及学习率衰减和局部最优问题的探讨。文章详细介绍了各方法的原理和应用场景,并通过实例展示了它们的效果差异。
本文是关于深度学习优化方法的学习笔记,涵盖了Mini-Batch Gradient Descent、指数加权平均、Momentum、RMSprop、Adam算法以及学习率衰减和局部最优问题的探讨。文章详细介绍了各方法的原理和应用场景,并通过实例展示了它们的效果差异。
1.Mini-Batch Gradient descent
Mini-batch每次处理训练数据的一部分,即用其子集进行梯度下降,算法速度会执行的更快。
方法分为两个步骤:
- Shuffle:
洗牌一般同步打乱原来数据集X和对应标签Y中的数据信息,使得数据随机分散到不同的minibatch中
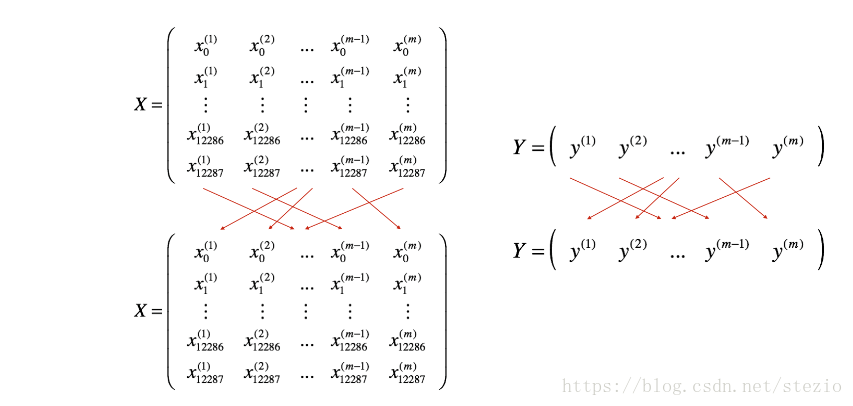
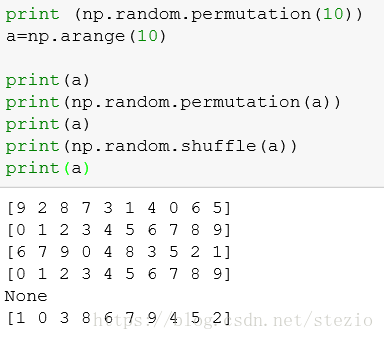
代码中用到了np.random.permutation()方法作为洗牌方法,对于打乱顺序有两种方法。permutation是返回一个新的数组,不对原来数组进行改动,而shuffle不返回值,对原来数组基础上进行打乱顺序操作。
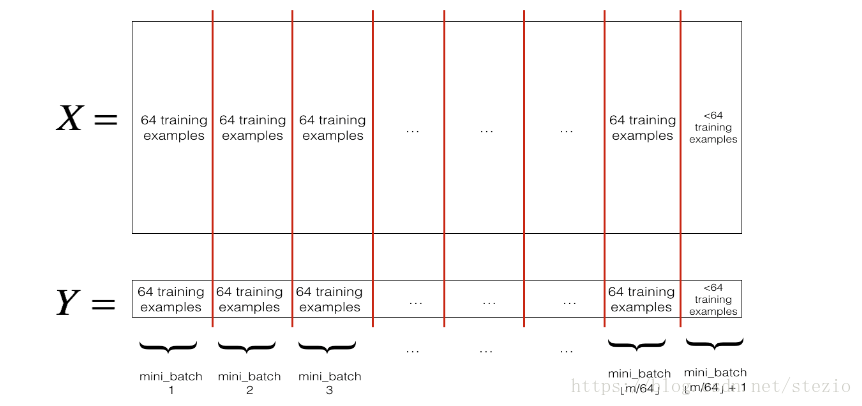
- Partition:
将对应X,Y划分到各个minibatch中,每个minibatch里数据数量相等,除了最后一个可能略少于其他minibatch。
Mini-batch 大小的选择
- 在划分时通常采取2的次方项作为minibatch的大小。
- 如果训练样本的大小比较小时,如
 时 ------ 选择batch梯度下降法;
时 ------ 选择batch梯度下降法; - 如果训练样本的大小比较大时,典型的大小为:
 ;
; - Mini-batch的大小要符合CPU/GPU内存。
当minibatch的size选择为1的时候,称为Stochastic Gradient Descent
几个方法效果比较如下:
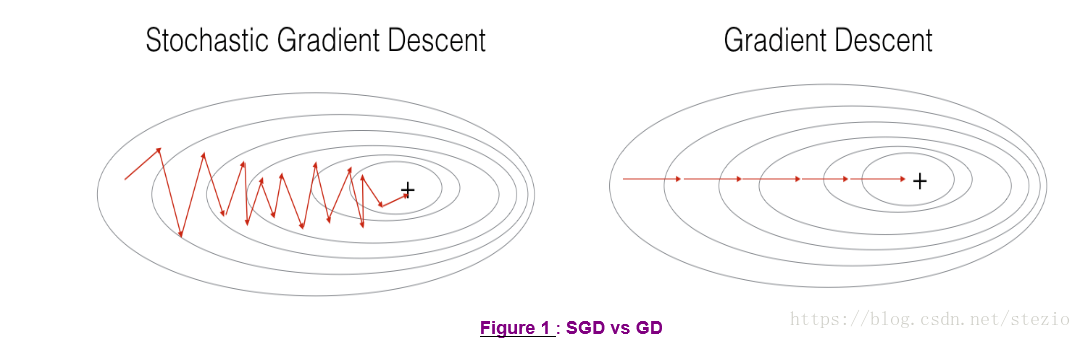
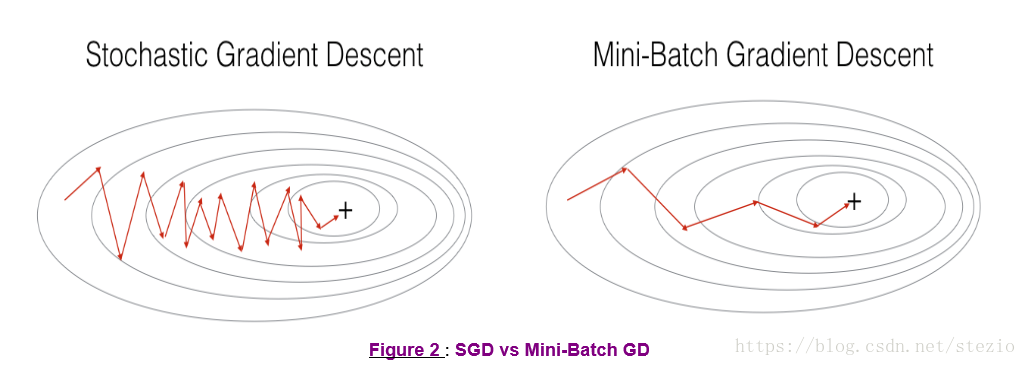
图中“+”表示损失函数的最小值点
2.指数加权平均
指数加权平均的关键函数:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









