



在云计算,大数据人工智能等技术的发展,数据库规模和复杂性不断增加,高可用架构的要求越来越高。主备复制(备份特质)作为实现数据库高可用性的基础技术,被各大数据库厂商广泛采用
实现数据库高可用性面临着诸多挑战,包括:
数据一致性:主备数据库之间的数据一致性是高可用架构的核心挑战,如何在保证性能的同时确保数据的强一致性是关键问题。
故障检测与切换:如何快速准确地检测主数据库故障,并实现自动或手动的故障转移,确保服务连续性。
性能影响:主备复制机制对数据库性能的影响需要控制在可接受范围内,避免因高可用设计导致系统性能大幅下降。
复杂性管理:随着数据库规模和架构复杂度的增加,高可用架构的管理和维护变得更加复杂,需要有效的监控和管理工具支持。
**主备复制机制的基本原理 **
主备复制是实现数据库高可用性的基础技术,其基本原理是将主数据库(Master)上的所有数据变更实时或近实时地复制到一个或多个备数据库(Slave 或 Standby)上。当主数据库发生故障时,备数据库可以接管服务,确保业务连续性。
主备复制的基本流程通常包括以下几个步骤:
-
日志生成:主数据库将数据变更操作记录到特定的日志文件中(如 MySQL 的 binlog、Oracle 的 Redo Log)。
-
日志传输:备数据库通过网络连接到主数据库,获取并复制这些日志文件。
-
日志应用:备数据库根据获取的日志文件,在本地执行相应的数据变更操作,保持与主数据库的数据一致性。
不同数据库系统的主备复制机制在日志格式、传输方式和应用策略等方面存在差异,这些差异直接影响着高可用架构的性能、可靠性和复杂度。
一、MySQL主备高可用机制分析
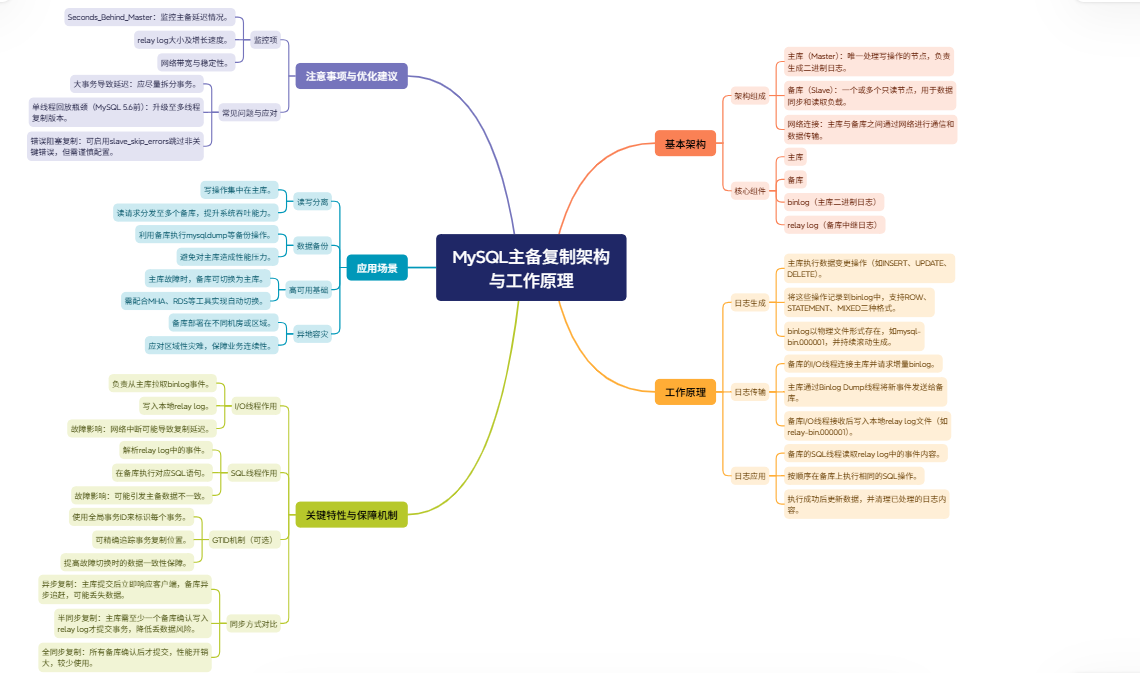
1. MySQL 主备复制基本原理与架构
MySQL 主备复制基本原理与架构 MySQL 主备复制是 MySQL 数据库提供的一种数据复制机制,允许将一个 MySQL 数据库(主库,Master)上的数据变更复制到一个或多个 MySQL 数据库(备库,Slave)上,从而实现数据冗余、高可用性和读写分离。
基本架构:
MySQL 主备复制的基本架构由一个主库和一个或多个备库组成,通过网络连接形成一个复制集群。
主库负责处理所有写操作,并将数据变更记录到二进制日志(binlog)中;备库通过 I/O 线程读取主库的 binlog,并通过 SQL 线程将这些变更应用到自身数据库中,保持与主库的数据一致性。
MySQL 主备复制的基本架构由一个主库和一个或多个备库组成,通过网络连接形成一个复制集群。
主库负责处理所有写操作,并将数据变更记录到二进制日志(binlog)中;备库通过 I/O 线程读取主库的 binlog,并通过 SQL 线程将这些变更应用到自身数据库中,保持与主库的数据一致性。
架构图:


1. 核心组件与角色
- Master(主节点):
- 处理客户端的写操作(如
COMMIT)。 - 生成 Binlog(二进制日志),记录所有修改数据库的事件(如 SQL 语句或行级变更)。
- 处理客户端的写操作(如
- Slave(从节点):
- 从 Master 获取 Binlog,并存储在 Relay Log(中继日志) 中。
- 通过 SQL 线程(未显示)应用 Relay Log 中的事件,实现数据同步。
2. Master 端流程
-
User THD(用户线程):
- Write:执行
COMMIT操作,将事务信息写入 Binlog。 - Push:将 Binlog 事件推入 ACK Request Queue(确认请求队列)。
- Sync:同步 Binlog 到磁盘,确保数据持久化。
- Wait ACK:等待 Slave 的确认(ACK)。
- Engine Commit:收到最新 ACK 后,完成引擎层面的提交。
- Write:执行
-
Dump THD(转储线程):
- Send Events Without ACK Request:发送无需确认的 Binlog 事件。
- Send Event With ACK Request:发送需确认的事件,并等待 ACK。
3. Slave 端流程
- IO THD(I/O 线程):
- 从 Master 获取 Binlog 事件。
- 将事件写入 Relay Log,供后续应用。
4. ACK 机制
-
ACK(确认):
- Slave 在成功写入 Relay Log 后,向 Master 发送 ACK。
- Master 维护最新的 ACK 信息(如
Binlog.000002,456),确保数据一致性。
-
OK:
- Master 收到 ACK 并完成 Engine Commit 后,向客户端返回
OK,表示事务提交成功。
- Master 收到 ACK 并完成 Engine Commit 后,向客户端返回
5. 关键点总结
- 日志作用:
- Binlog:记录 Master 上的所有数据变更。
- Relay Log:存储从 Master 获取的 Binlog 事件,供 Slave 应用。
- 多线程协作:
- User THD、Dump THD 和 IO THD 协同完成数据写入、同步和确认。
- 可靠性保障:
- ACK 机制确保 Master 和 Slave 数据同步的一致性。
6. 应用场景
- 数据备份与恢复:通过 Relay Log 实现 Slave 的数据备份和恢复。
- 读写分离:将读操作分流到 Slave,降低 Master 负载。
- 高可用性:Master 故障时,可快速切换到 Slave,保证服务连续性。
7. 优化建议
- 网络延迟:优化 Master 与 Slave 之间的网络环境。
- ACK 频率:合理设置 ACK 请求频率,平衡可靠性与性能。
- 存储性能:提升磁盘 I/O 性能,加快 Binlog 和 Relay Log 的写入速度。
通过上述机制,MySQL 主从复制实现了高效、可靠的数据同步,适用于需要高可用性和负载均衡的场景。
工作原理:
- 日志生成:当主库上执行数据变更操作(如 INSERT、UPDATE、DELETE 等)时,这些操作会被记录到二进制日志(binlog)中。
- 日志传输:备库的 I/O 线程通过连接主库,读取主库的 binlog,并将其写入本地的中继日志(relay log)。
- 日志应用:备库的 SQL 线程读取中继日志中的内容,并在备库上执行相应的数据变更操作,使备库的数据与主库保持一致。
MySQL 8.0 主备复制:
增强的 GTID 功能:8.0 版本进一步优化了 GTID 的处理和存储,提高了性能和可靠性。
原子 DDL 支持:8.0 版本支持原子 DDL 操作,确保 DDL 操作的完整性和一致性,减少了复制中断的风险。
自动故障转移准备:8.0 版本为后续的自动故障转移功能做了准备,增强了复制的健壮性和容错性。
更好的安全性:增强了复制用户的权限管理和安全性,提供了更完善的复制加密和认证机制。
MySQL GTID 机制详解

GTID(全局事务标识符)是 MySQL 5.6 版本引入的一项重要功能,它为每个事务提供了一个全局唯一的标识符,大大简化了主备复制的管理和故障恢复过程。
GTID 组成与生成:
• 组成:GTID 由两部分组成,格式为source_id:transaction_id,其中source_id是 MySQL 实例的 UUID(存储在 auto.cnf 文件中),transaction_id是该实例上事务的序列号。
• 生成:当主库执行事务时,系统会为事务分配一个由 server uuid 和事务序列号组成的 GTID。事务提交时,GTID 会被记录到 binlog 中,并在主备复制过程中传递给备库。
GTID 复制流程:
-
主库执行事务并生成 GTID,将其记录到 binlog 中。
-
备库的 I/O 线程读取主库的 binlog,并将包含 GTID 的事务写入中继日志。
-
备库的 SQL 线程从中继日志中读取 GTID,并检查该 GTID 是否已在备库执行过。
-
如果 GTID 已执行,备库会跳过该事务;如果未执行,备库会执行该事务并将 GTID 记录到自身的 gtid_executed 集合中。
GTID 相关参数:
• gtid_mode:启用 GTID 模式,有效值为 OFF、OFF_PERMISSIVE、ON_PERMISSIVE、ON。
• enforce_gtid_consistency:强制 GTID 一致性,确保只有兼容的事务才能执行。
• gtid_executed:表示当前实例已执行的 GTID 集合。
• gtid_purged:表示已执行但已从 binlog 中清除的 GTID 集合,是 gtid_executed 的子集。
• master_auto_position:在 CHANGE MASTER TO 语句中使用,启用自动位置发现,无需指定 binlog 文件名和位置。
MySQL 多线程复制机制分析
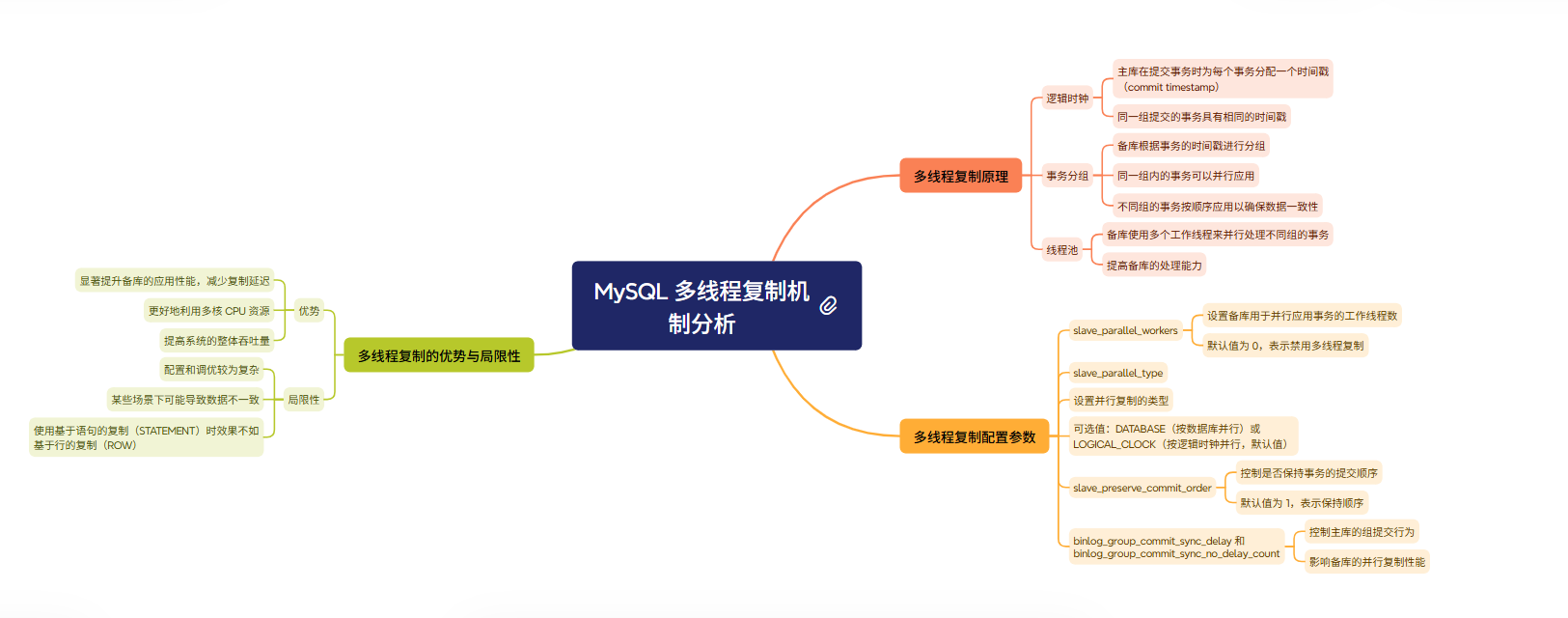
MySQL 5.7 版本引入了基于逻辑时钟的多线程复制(MTS,Multi-Threaded Slave),显著提升了备库的应用性能,特别是在处理大量并发事务的场景中。
多线程复制原理:
-
逻辑时钟:主库在提交事务时会为每个事务分配一个时间戳(commit timestamp),同一组提交的事务具有相同的时间戳。
-
事务分组:备库根据事务的时间戳将其分组,同一组内的事务可以并行应用,而不同组的事务则按顺序应用,以确保数据一致性。
-
线程池:备库使用多个工作线程来并行应用不同组的事务,从而提高备库的处理能力。
多线程复制配置参数:
-
slave_parallel_workers:设置备库用于并行应用事务的工作线程数,默认值为 0(禁用多线程复制)。
-
slave_parallel_type:设置并行复制的类型,有效值为 DATABASE(按数据库并行)或 LOGICAL_CLOCK(按逻辑时钟并行,默认值)。
-
slave_preserve_commit_order:控制是否保持事务的提交顺序,默认值为 1(保持顺序)。
-
binlog_group_commit_sync_delay和binlog_group_commit_sync_no_delay_count:控制主库的组提交行为,影响备库的并行复制性能。
多线程复制的优势与局限性:
优势:显著提升备库的应用性能,减少复制延迟;更好地利用多核 CPU 资源;提高系统的整体吞吐量。
局限性:配置和调优较为复杂;某些场景下可能导致数据不一致;在使用基于语句的复制(STATEMENT)时效果不如基于行的复制(ROW)。
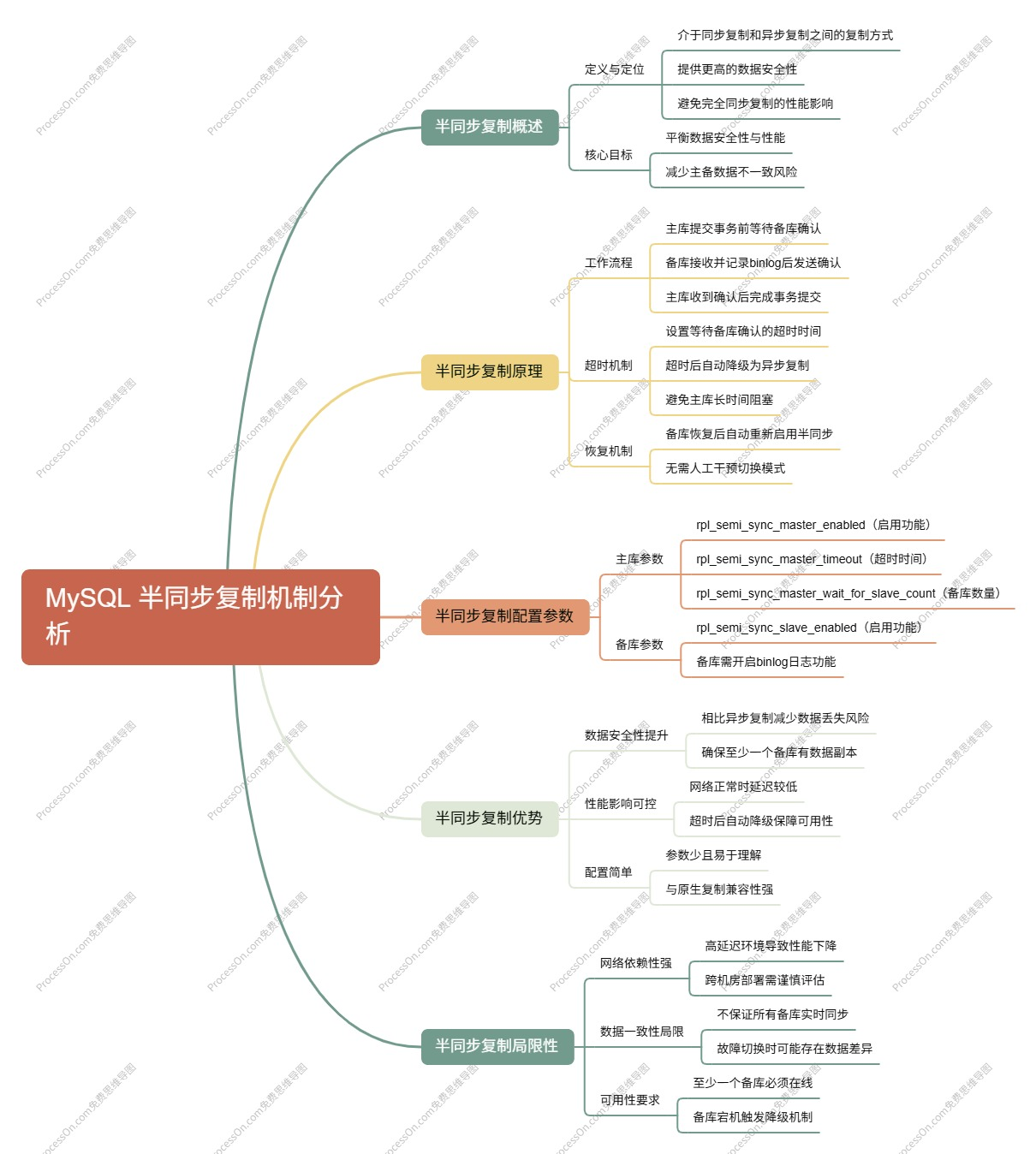
MySQL 半同步复制机制分析
MySQL 半同步复制是一种介于同步复制和异步复制之间的复制方式,旨在提供更高的数据安全性,同时避免完全同步复制对性能的影响。
半同步复制原理:
工作流程:主库在提交事务前,会等待至少一个备库确认已收到并记录该事务的 binlog。
超时机制:如果在指定时间内未收到备库的确认,主库会自动降级为异步复制模式,以保证性能和可用性。
恢复机制:当备库恢复可用后,主库会自动恢复为半同步复制模式。
半同步复制配置参数:
rpl_semi_sync_master_enabled:启用主库的半同步复制功能。
rpl_semi_sync_slave_enabled:启用备库的半同步复制功能。
rpl_semi_sync_master_timeout:设置主库等待备库确认的超时时间(毫秒),默认值为 10000。
rpl_semi_sync_master_wait_for_slave_count:设置主库等待多少个备库的确认,默认值为 1。
半同步复制的优势与局限性:
优势:提供比异步复制更高的数据安全性,减少数据丢失风险;在大多数情况下对性能影响较小;配置相对简单。
局限性:在高延迟网络环境中可能影响主库性能;不能完全保证数据一致性;需要至少一个备库始终可用,否则会降级为异步复制。
二、PostgreSQL 主备高可用机制分析
PostgreSQL 流复制基本原理与架构
PostgreSQL 流复制(Streaming Replication)是 PostgreSQL 数据库提供的一种高性能、高可靠的数据复制机制,允许将一个 PostgreSQL 数据库(主节点,Primary)上的数据变更实时复制到一个或多个 PostgreSQL 数据库(备节点,Standby)上,从而实现高可用性、灾难恢复和读写分离。
基本架构:
PostgreSQL 流复制的基本架构由一个主节点和一个或多个备节点组成,通过网络连接形成一个复制集群。主节点负责处理所有写操作,并将数据变更记录到预写式日志(WAL,Write-Ahead Logging)中;备节点通过流复制协议从主节点获取 WAL 日志,并应用这些日志以保持与主节点的数据一致性。
PostgreSQL 流复制的基本架构由一个主节点和一个或多个备节点组成,通过网络连接形成一个复制集群。主节点负责处理所有写操作,并将数据变更记录到预写式日志(WAL,Write-Ahead Logging)中;备节点通过流复制协议从主节点获取 WAL 日志,并应用这些日志以保持与主节点的数据一致性。
架构图:
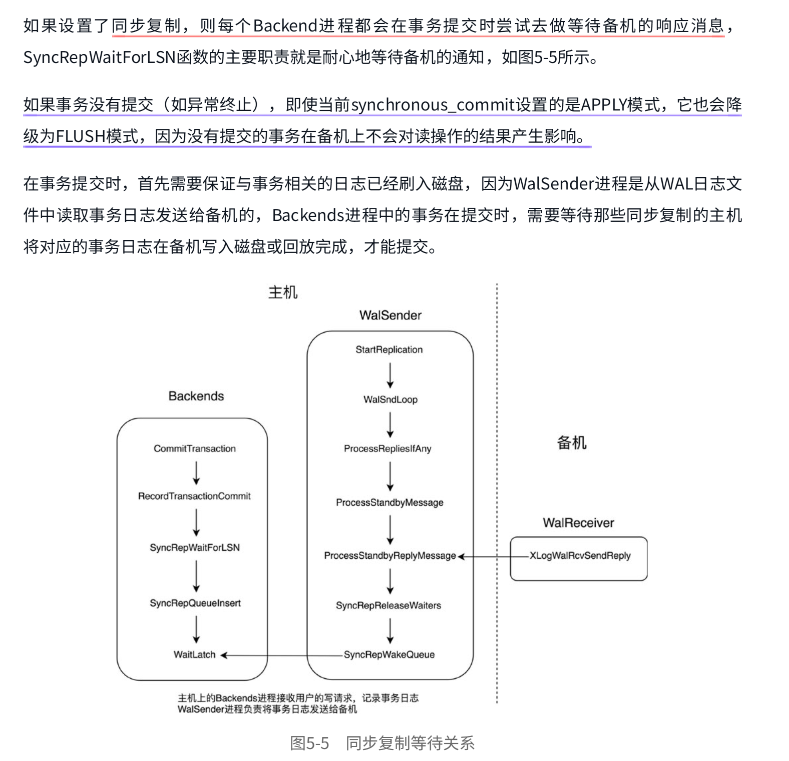
1. 核心概念
- 同步复制(Synchronous Replication):
确保主库(Primary)事务提交前,其修改已复制到至少一个备库(Standby)。提升数据可靠性和容灾能力。 - 关键组件:
- Backend 进程:处理客户端事务提交。
- WalSender 进程:主库发送 WAL 日志。
- WalReceiver 进程:备库接收并处理 WAL 日志。
- LSN(Log Sequence Number):标识 WAL 日志位置,确保数据一致性。
2. 事务提交流程
- CommitTransaction:Backend 进程发起事务提交。
- RecordTransactionCommit:记录事务提交信息。
- SyncRepWaitForLSN:等待备库确认接收/应用 WAL 日志。
- SyncRepQueueInsert:将请求加入同步等待队列。
- WaitLatch:Backend 进程进入等待状态,直至收到备库确认或超时。
3. 进程交互流程
-
WalSender(主库):
- StartReplication:启动复制。
- WalSndLoop:循环发送 WAL 日志。
- ProcessRepliesIfAny:处理备库回复。
- SyncRepReleaseWaiters:释放等待的 Backend 进程。
-
WalReceiver(备库):
- 接收 WAL 日志并写入本地存储。
- XLogWalRcvSendReply:向主库发送确认消息。
4. 同步等待机制
- SyncRepWaitForLSN:
- 核心函数,确保备库已接收/应用 WAL 日志。
- 依赖 synchronous_commit 参数控制同步级别:
- on(默认):等待备库应用日志。
- remote_write:仅等待备库写入日志。
- 异常处理:
- 事务未正常提交时,自动降级为 remote_write 模式,避免阻塞读操作。
5. 总结
- 目标:通过主备进程协作,保障数据一致性。
- 关键交互:Backend 等待 WalSender 发送日志,WalReceiver 确认接收,最终释放等待进程。
- 适用场景:高可用性需求场景,如金融、电信等对数据一致性要求严格的业务。
6. 图片内容对应关系
| 图片模块 | 解释内容 |
|---|---|
| 事务提交流程图 | Backend 进程调用 SyncRepWaitForLSN 等待备库确认。 |
| WalSender/WalReceiver | WalSender 发送 WAL 日志,WalReceiver 接收并发送确认。 |
| LSN 与同步参数 | LSN 标识日志位置,synchronous_commit 控制同步级别。 |
以上为图片中 PostgreSQL 同步复制机制的完整解释,涵盖核心流程、进程交互及参数配置。
工作原理:
-
日志生成:当主节点执行数据变更操作时,这些操作会被记录到 WAL 日志中。
-
日志传输:备节点通过流复制协议连接到主节点,请求并接收 WAL 日志数据。
-
日志应用:备节点接收到 WAL 日志后,将其应用到自身数据库中,保持与主节点的数据一致性。
-
持续同步:主节点和备节点之间保持持续的连接,主节点不断将新生成的 WAL 日志发送给备节点,确保数据的实时同步。
PostgreSQL 物理复制与逻辑复制机制对比
PostgreSQL 提供了两种主要的复制方式:物理复制和逻辑复制,它们在实现原理、应用场景和性能特点上存在显著差异。
物理复制:
• 原理:物理复制基于 WAL 日志的物理块级复制,备节点通过接收并应用主节点的 WAL 日志来保持数据一致性。
• 特点: ◦ 复制速度快,因为只需要复制和应用 WAL 日志,无需解析和执行 SQL 语句。
-
要求主节点和备节点的数据库结构和配置完全一致。
-
备节点在复制过程中处于只读模式,可以用于查询,但不能进行写操作。
-
支持流式复制(实时复制)和基于文件的复制(定期快照)。
-
应用场景:适用于需要高可用性、灾难恢复和高性能复制的场景,是 PostgreSQL 默认的复制方式。
逻辑复制:
• 原理:逻辑复制基于数据库对象(如表、行)的逻辑变更进行复制,备节点通过订阅主节点的发布(Publication)来获取数据变更。
• 特点:
◦ 更灵活,可以选择性地复制特定的数据库对象(如表、视图等)。
◦ 主节点和备节点可以有不同的数据库结构,只要复制的对象兼容。
◦ 支持双向复制和多主复制,但需要谨慎管理以避免冲突。 ◦ 性能相对较低,因为需要解析和执行 SQL 语句。
• 应用场景:适用于需要选择性复制、异构环境和复杂复制拓扑的场景,如数据分片、数据集成和特定业务需求。

PostgreSQL 高可用集群解决方案
PostgreSQL 社区提供了多种高可用集群解决方案,这些方案基于流复制构建,提供了自动故障转移、负载均衡和管理工具,以满足不同业务场景的需求。
- PostgreSQL 自带的高可用功能:
• 热备(Hot Standby):备节点可以在保持与主节点同步的同时提供只读查询服务,提高资源利用率。
• 同步复制:通过设置 synchronous_standby_names 参数,可以配置主节点等待至少一个备节点确认接收 WAL 日志后再提交事务,确保数据安全性。
• 异步复制:默认复制方式,主节点无需等待备节点确认即可提交事务,提供更高的性能但可能存在数据丢失风险。
- 第三方高可用解决方案:
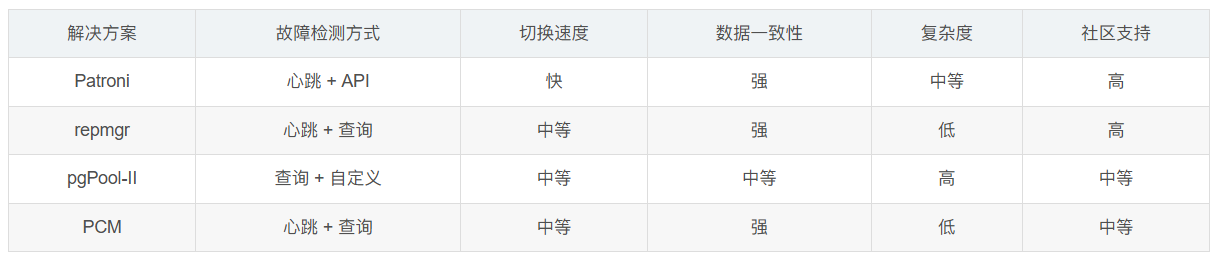
• Patroni:一个开源的 PostgreSQL 高可用解决方案,提供自动故障转移、领导者选举和集群管理功能,支持多数据中心部署。
• PostgreSQL Cluster Manager (PCM):一个轻量级的 PostgreSQL 集群管理器,提供自动故障转移和简单的管理界面。
• pgPool-II:一个连接池和负载均衡器,结合流复制可以实现读写分离和高可用性,支持自动故障转移。
• repmgr:一个开源的 PostgreSQL 复制和集群管理工具,提供自动故障转移和集群管理功能。 3. 分布式 PostgreSQL 解决方案:
• Citus:一个分布式 PostgreSQL 扩展,提供分片和分布式查询处理功能,结合流复制可以构建大规模分布式数据库集群。
• TimescaleDB:一个用于时间序列数据的 PostgreSQL 扩展,结合流复制可以构建高性能的时间序列数据管理系统。
PostgreSQL 故障检测与自动切换机制
PostgreSQL 的高可用解决方案通常包括故障检测和自动切换机制,以确保在主节点发生故障时,备节点可以自动接管服务,实现业务连续性。
故障检测机制:
• 心跳检测:通过定期发送心跳消息来监测节点的存活状态,通常使用 TCP Keepalive 或专用的心跳协议。
• 查询检测:通过执行简单的查询(如 SELECT 1)来验证节点是否响应,检测数据库服务是否正常。
• 延迟检测:监测备节点与主节点之间的复制延迟,当延迟超过阈值时可能触发故障转移。
• 自定义脚本:允许用户定义自定义的健康检查脚本,实现更灵活的故障检测逻辑。
自动切换流程:
- 故障检测:高可用解决方案检测到主节点无响应或不可用。
- 领导者选举:如果存在多个备节点,需要选举一个新的主节点,通常基于优先级或延迟等因素。 3. 故障转移:将选定的备节点提升为主节点,停止复制并开始接受写请求。
- 重新配置:更新集群配置,将其他备节点重新指向新的主节点,并恢复复制。
- 通知与监控:向管理员发送通知,并更新监控系统以反映新的集群状态。
PostgreSQL 主备高可用的优势与局限性
优势:
-
高性能复制:物理复制基于 WAL 日志的块级复制,性能高且资源消耗少。
-
强数据一致性:通过同步复制可以实现强数据一致性,确保零数据丢失。
-
灵活的复制方式:提供物理复制和逻辑复制两种方式,满足不同业务需求。
-
丰富的生态系统:有多种成熟的高可用解决方案和工具,如 Patroni、repmgr、pgPool-II 等。
-
热备功能:备节点可以在保持同步的同时提供只读查询服务,提高资源利用率。
-
开源免费:PostgreSQL 是开源数据库,无需支付额外的高可用功能授权费用。
局限性:
-
切换复杂性:虽然有自动切换解决方案,但故障切换仍然是一个复杂的过程,需要谨慎配置和测试。
-
性能影响:同步复制会对主节点性能产生一定影响,特别是在高并发写场景中。
-
存储要求:备节点需要与主节点相同的存储容量,增加了硬件成本。
-
管理复杂性:随着集群规模的扩大,管理和维护的复杂性也会增加。
-
兼容性限制:某些扩展和功能在复制环境中可能存在兼容性问题,需要特别处理。
-
不支持多主写入:默认不支持多主写入,需要额外配置和管理来实现分布式写入。
MySQL和pg异同点
相同点 :
• 依赖日志实现同步 :三者均以日志作为数据同步的核心载体。MySQL 依据二进制日志(binlog),PostgreSQL 基于写前日志(WAL),Oracle 则凭借重做日志(Redo Log)来记录数据库的变更操作,备库通过获取并重放这些日志,实现与主库的数据一致。
• 具备主备角色分工 :都有明确的主库与备库概念。主库负责处理事务并生成日志,备库从主库获取日志后进行重放以更新本地数据,正常情况下,读写操作主要在主库进行,备库一般为只读状态,用于数据备份和故障切换等场景。
• 支持多种同步模式 :都支持异步复制与同步复制。异步模式下,主库事务提交后,备库异步接收和应用日志,数据一致性为最终一致性;同步模式中,主库需等待备库确认接收日志甚至完成日志应用后,才认为事务提交成功,能更好地保障数据的强一致性。
不同:


















 1223
1223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









