



点击上方“猿芯”,选择“设为星标”
后台回复"1024",有份惊喜送给面试的你

前言
最近系统(基于 SpringCloud + K8s)上线,运维团队早上 8 点左右在群里反馈,系统登录无反应!我的第一反应是 MySQL 数据库扛不住了。
排查问题也是一波三折,有网络问题,也有 MySQL 读写分离后数据库参数优化问题。
问题回顾
1、运维团队早上 8 点左右在群里反馈,系统登录无反应。
2、DevOps 团队通过查看 Kibana 日志
发现 ELK、K8s 集群、Redis、Mongodb、Nginx、文件服务器全部报:”Connect Unknown Error“,中间件服务集体挂彩,团队成员惊出一身冷汗。。。一想到某联大领导每日混迹于办公门户,瑟瑟发抖呀。。。
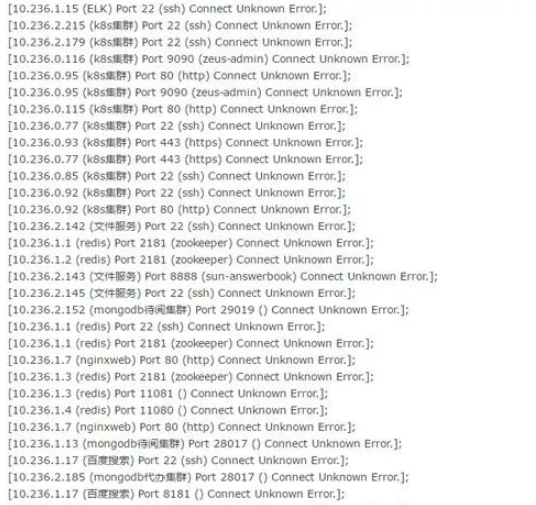
心里嘀咕难道 K8s 容器也挂了?那还怎么玩?
3、查看监控短信,连续收到数据库读写分离Master-Slave警告信息

问题定位
1、Connect Unknown Error
经过从 K8s 团队确认,在早上 8 点左右出现了网络中断,持续了大概 1 分钟左右,导致 K8s 平台剔除响应超时的微服务节点,同时不断的启动新的容器。通过日志分析,8 点半左右容器平台恢复正常,但是前台页面查询数据很慢(后来定位是 MySQL 数据库服务器 CPU 占用 92% ,导致数据库服务器处理应用请求很慢)。
2、MySQL 读写分离 Master-Slave 警告信息
MHA架构
MySQL 读写分离是采用 MHA 架构,一主两从(Master-Slave)。
Master 负责数据的写操作,同时通过 binlog 日志同步到两个 Slave 从库,从库负责应用程序的查询操作。
在报 Connect Unknown Error 异常后,我们检查了 MySQL 服务器,发现 Master 节点 CPU 占用 92%(应用层读写请求全部路由到了 Master节点原因导致),而两个 Slave 节点全部处于空闲状态,并且主从数据不同步了。
3、数据库DBA通过查看 MySQL 的 show processlist 命令,发现有大量的 “create sort index(排序索引)” SQL 语句(约 36 个)
经排查发现有个 cms_article 表有几百万的数据,客户端分页查询请求,虽然只取 10 条数据行,但是实际查询了几百万行数据,而且要在数据库内存中进行了几百万数据内存排序。所以出现了大量的 create sort index 排序索引。而且频繁执行 Create Sort Index 会造成 MySQL 占满服务器 CPU,导致服务器请求无响应,甚至假死状态!
解决办法
1、Connect Unknown Error
K8s 平台自动剔除响应超时的微服务节点,同时启动新的容器,直至恢复到故障前的容器节点水平,依靠 K8s 平台自我修复。
2、MySQL 读写分离 Master-Slave 警告信息
恢复步骤
-
重启
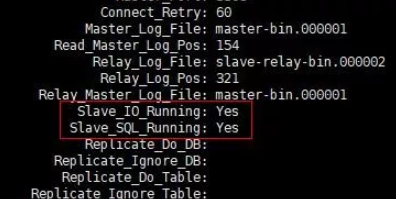
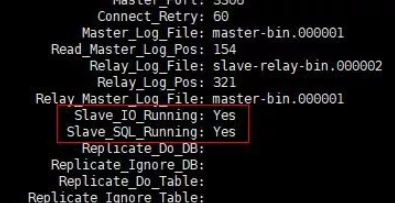
Master-Slave节点,应用层读写请求正常,但是主从数据还是不同步,经定位是mysql同步线程Slave_IO_Running和Slave_SQL_Running都为No。 -
晚上重启
Slave_IO_Running和Slave_SQL_Runningbinlog日志同步线程
只有 Slave_IO_Running 和 Slave_SQL_Running 都为 yes ,则表示同步成功。
3、数据库 DBA 通过查看 MySQL 的 show processlist 命令,发现有大量的 “create sort index (排序索引)” SQL 语句(约 36 个)
innodb_buffer_pool_size 从 500M 调整为 300G(服务器共 500G 内存)。
innodb_buffer_pool_size 用于缓存索引和数据的内存大小,这个当然是越多越好,数据读写在内存中非常快,减少了对磁盘的读写。
当数据提交或满足检查点条件后才一次性将内存数据刷新到磁盘中。然而内存还有操作系统或数据库其他进程使用,一般设置buffer pool 大小为总内存的 1/5 至1/4。若设置不当,内存使用可能浪费或者使用过多。
对于繁忙的服务器, buffer pool 将划分为多个实例以提高系统并发性,减少线程间读写缓存的争用。
buffer pool 的大小首先受 innodb_buffer_pool_instances 影响, 当然影响较小。
MySQL 性能调优总结
预计 44W 用户 峰值在线人数 5 万左右。
1、innodb_buffer_pool_size=500M
太小,严重影响数据库性能。
服务器共 500G 内存,但只给 MySQL 缓冲池分配了 500M,非常影响数据库性能,且造成资源浪费。
建议设置为服务器内存的 60%。
2、expire_logs_days=7
太短,只能保留 7 天的 binlog,只能恢复 7 天内的任意数据。建议设置为参数文件里被覆盖的 90 天的设置。
3、long_query_time=10
太长,建议设置为 2 秒,让慢查询日志记录更多的慢查询。
4、transaction-isolation = read-committed
建议注释掉,使用数据库默认的事务隔离级别
5、innodb_lock_wait_timeout = 5
设置得太小,会导致事务因锁等待超过5秒,就被回滚。建议和云门户设置得保持一致,云门户大小为 120。
6、autocommit = 0
#建议改为 mysql 默认的自动提交( autocommit=1 ),提升性能,方便日常操作

往期推荐
作者简介:猿芯,一枚简单的北漂程序员。喜欢用简单的文字记录工作与生活中的点点滴滴,愿与你一起分享程序员灵魂深处真正的内心独白。我的微信号:WooolaDunzung,公众号【猿芯】输入 1024 ,有份面试惊喜送给你哦。
< END >
【猿芯】

微信扫描二维码,关注我的公众号。
原创不易,莫要干想,如果觉得有点用的话,动动你的发财之手,一键三连击:分享、点赞、在看,你们的鼓励是我写作更多优质文章的最强动力 ^_^
分享、点赞、在看,3连3连!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











