




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Hadoop + Spark + Kafka 商品推荐系统技术说明
——电商推荐系统架构设计与实现
一、项目背景与目标
在电商场景中,推荐系统是提升用户转化率、增强用户粘性的核心工具。传统推荐系统(如基于协同过滤)面临数据规模大、实时性要求高、特征维度复杂等挑战。本方案基于Hadoop(分布式存储) + Spark(内存计算) + Kafka(流处理)构建离线+实时混合推荐系统,实现:
- 离线推荐:基于用户历史行为挖掘长期偏好(如“猜你喜欢”)。
- 实时推荐:结合用户实时行为(如点击、加购)动态调整推荐结果(如“实时热门”“场景化推荐”)。
- 高并发处理:支撑千万级用户与商品数据的实时分析与推荐。
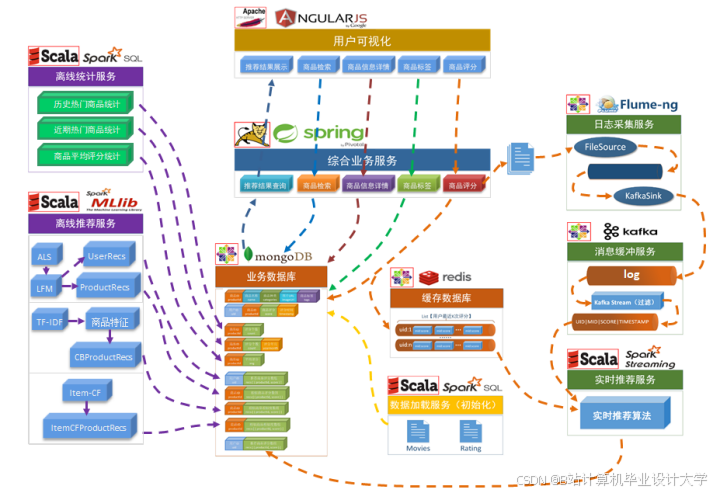
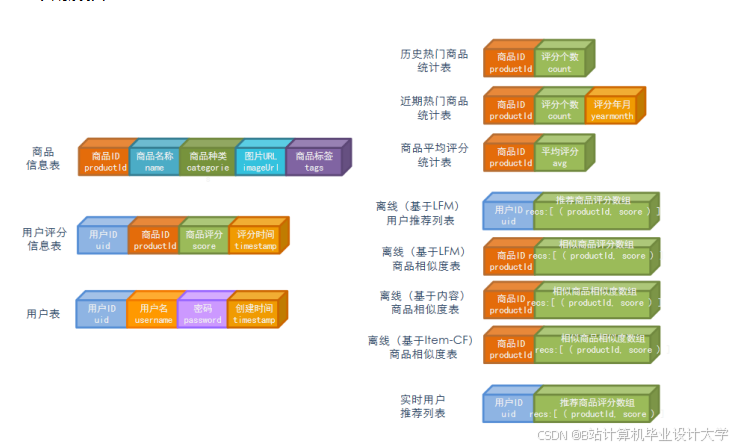
二、技术架构设计
系统采用分层架构,分为数据层、计算层、服务层与应用层,核心组件如下:
1. 整体架构图
1┌───────────────┐ ┌───────────────┐ ┌───────────────┐ ┌───────────────┐
2│ 数据源 │ → │ Kafka │ → │ Spark │ → │ 推荐服务 │
3│(用户行为、商品│ │(消息队列) │ │(离线+实时计算│ │(API/Web) │
4│ 数据、日志) │ └───────────────┘ └───────────────┘ └───────────────┘
5 ↑ ↑
6┌───────────────┐ ┌───────────────┐
7│ Hadoop HDFS │ │ 外部数据库 │
8│(存储原始数据)│ │(MySQL/HBase) │
9└───────────────┘ └───────────────┘2. 核心组件选型
| 组件 | 角色 | 技术选型理由 |
|---|---|---|
| Hadoop | 分布式存储 | HDFS存储海量原始数据(如用户行为日志、商品信息),支持高吞吐读写。 |
| Spark | 离线+实时计算 | Spark MLlib实现算法(如ALS协同过滤),Spark Streaming处理实时数据流。 |
| Kafka | 消息队列 | 解耦数据生产与消费,支撑高并发实时行为数据(如点击、购买)的缓冲与分发。 |
| MySQL | 元数据存储 | 存储用户画像、商品特征等结构化数据,支持快速查询。 |
| Redis | 缓存与结果存储 | 缓存热门推荐结果,降低数据库压力,提升响应速度。 |
三、核心功能实现
1. 数据采集与预处理
(1)数据源
- 用户行为数据:点击、浏览、加购、购买(通过埋点收集,写入Kafka)。
- 商品数据:类别、价格、销量、评价(从业务数据库同步至HDFS)。
- 上下文数据:时间、地理位置、设备类型(增强场景化推荐)。
(2)数据预处理(Spark Batch)
python
1# 示例:使用Spark清洗用户行为日志
2from pyspark.sql import SparkSession
3from pyspark.sql.functions import col, udf
4from pyspark.sql.types import IntegerType
5
6spark = SparkSession.builder.appName("DataPreprocess").getOrCreate()
7
8# 读取Kafka中的原始日志
9raw_logs = spark.read.format("kafka").option("kafka.bootstrap.servers", "localhost:9092") \
10 .option("subscribe", "user_behavior").load()
11
12# 解析JSON格式日志
13from pyspark.sql.functions import from_json
14schema = "user_id STRING, item_id STRING, action STRING, timestamp LONG"
15parsed_logs = raw_logs.select(from_json(col("value").cast("string"), schema).alias("data")) \
16 .select("data.*")
17
18# 过滤无效行为(如曝光未点击)
19valid_logs = parsed_logs.filter(col("action").isin(["click", "cart", "buy"]))
20
21# 保存至HDFS供后续计算
22valid_logs.write.parquet("hdfs://namenode:8020/user/hive/warehouse/cleaned_logs")2. 离线推荐(Spark MLlib)
(1)基于ALS的协同过滤
python
1from pyspark.ml.recommendation import ALS
2from pyspark.sql import Row
3
4# 加载清洗后的数据
5logs = spark.read.parquet("hdfs://namenode:8020/user/hive/warehouse/cleaned_logs")
6
7# 构建用户-商品评分矩阵(隐式反馈:点击=1,加购=2,购买=3)
8ratings = logs.withColumn("rating",
9 udf(lambda x: 1 if x == "click" else 2 if x == "cart" else 3, IntegerType())(col("action"))
10).select("user_id", "item_id", "rating")
11
12# 训练ALS模型
13als = ALS(maxIter=10, regParam=0.01, userCol="user_id", itemCol="item_id", ratingCol="rating")
14model = als.fit(ratings)
15
16# 为每个用户生成Top-10推荐
17user_recs = model.recommendForAllUsers(10)
18user_recs.write.parquet("hdfs://namenode:8020/user/hive/warehouse/offline_recommendations")(2)基于内容的推荐
- 商品特征提取:使用TF-IDF或Word2Vec处理商品标题/描述。
- 用户画像构建:聚合用户历史行为商品的特征作为用户偏好向量。
- 相似度计算:通过余弦相似度匹配用户与商品。
3. 实时推荐(Spark Streaming + Kafka)
(1)实时行为处理
python
1from pyspark.streaming import StreamingContext
2from pyspark.streaming.kafka import KafkaUtils
3
4ssc = StreamingContext(spark.sparkContext, batchDuration=5) # 每5秒处理一批数据
5kafka_stream = KafkaUtils.createDirectStream(ssc, ["realtime_actions"], {"metadata.broker.list": "localhost:9092"})
6
7# 解析实时行为并更新用户近期兴趣
8def process_action(time, rdd):
9 if not rdd.isEmpty():
10 actions = rdd.map(lambda x: x[1]).map(lambda x: eval(x)) # 假设消息是JSON字符串
11 # 更新Redis中的用户实时兴趣(如最近点击的商品类别)
12 for action in actions:
13 redis_client.hset(f"user:{action['user_id']}", "recent_category", action["category"])
14
15kafka_stream.foreachRDD(process_action)
16ssc.start()
17ssc.awaitTermination()(2)实时热门推荐
- 统计窗口内高频商品:使用Spark Streaming的
reduceByKeyAndWindow计算过去10分钟内点击量最高的商品。 - 结合上下文过滤:如根据用户地理位置推荐本地热门商品。
4. 推荐服务层
(1)API设计
| 接口 | 方法 | 参数 | 返回结果 |
|---|---|---|---|
/api/recommend | GET | user_id, scene(场景) | JSON格式的推荐商品列表 |
/api/hot | GET | category, limit | 实时热门商品列表 |
(2)服务逻辑(伪代码)
python
1def get_recommendations(user_id, scene):
2 # 1. 从Redis获取用户实时兴趣
3 recent_categories = redis.hget(f"user:{user_id}", "recent_category")
4
5 # 2. 融合离线与实时结果
6 if scene == "homepage":
7 offline_recs = load_from_hdfs(user_id) # 加载离线推荐
8 realtime_hot = get_realtime_hot(recent_categories) # 获取实时热门
9 return merge_results(offline_recs, realtime_hot)
10 elif scene == "cart_page":
11 return get_cart_related(user_id) # 基于加购商品的关联推荐四、性能优化与部署
- 数据倾斜处理:
- 对热门商品采样或加盐(Salting)分散计算压力。
- 缓存优化:
- Spark的
persist()缓存中间结果(如用户-商品矩阵)。
- Spark的
- 资源调度:
- YARN或Kubernetes动态分配集群资源。
- 部署方案:
- 离线任务:每日定时运行Spark作业,结果存入HBase。
- 实时任务:Spark Streaming监听Kafka,结果写入Redis。
五、应用场景与价值
- 首页推荐:离线ALS + 实时热门混合推荐。
- 购物车页:基于加购商品的关联规则推荐(如“买了A的人也买了B”)。
- 冷启动问题:新用户通过注册信息(性别、年龄)匹配相似用户群的偏好。
六、总结与展望
本方案通过Hadoop+Spark+Kafka构建了高吞吐、低延迟的电商推荐系统,兼顾了离线计算的深度挖掘与实时计算的动态响应。未来可扩展方向:
- 强化学习:根据用户反馈动态调整推荐策略。
- 图计算:利用GraphX挖掘用户-商品-品牌的复杂关系。
- 多模态推荐:结合商品图片、视频特征提升推荐多样性。
通过技术赋能电商,本系统可显著提升用户购物体验与平台GMV,成为智能商业的核心基础设施。
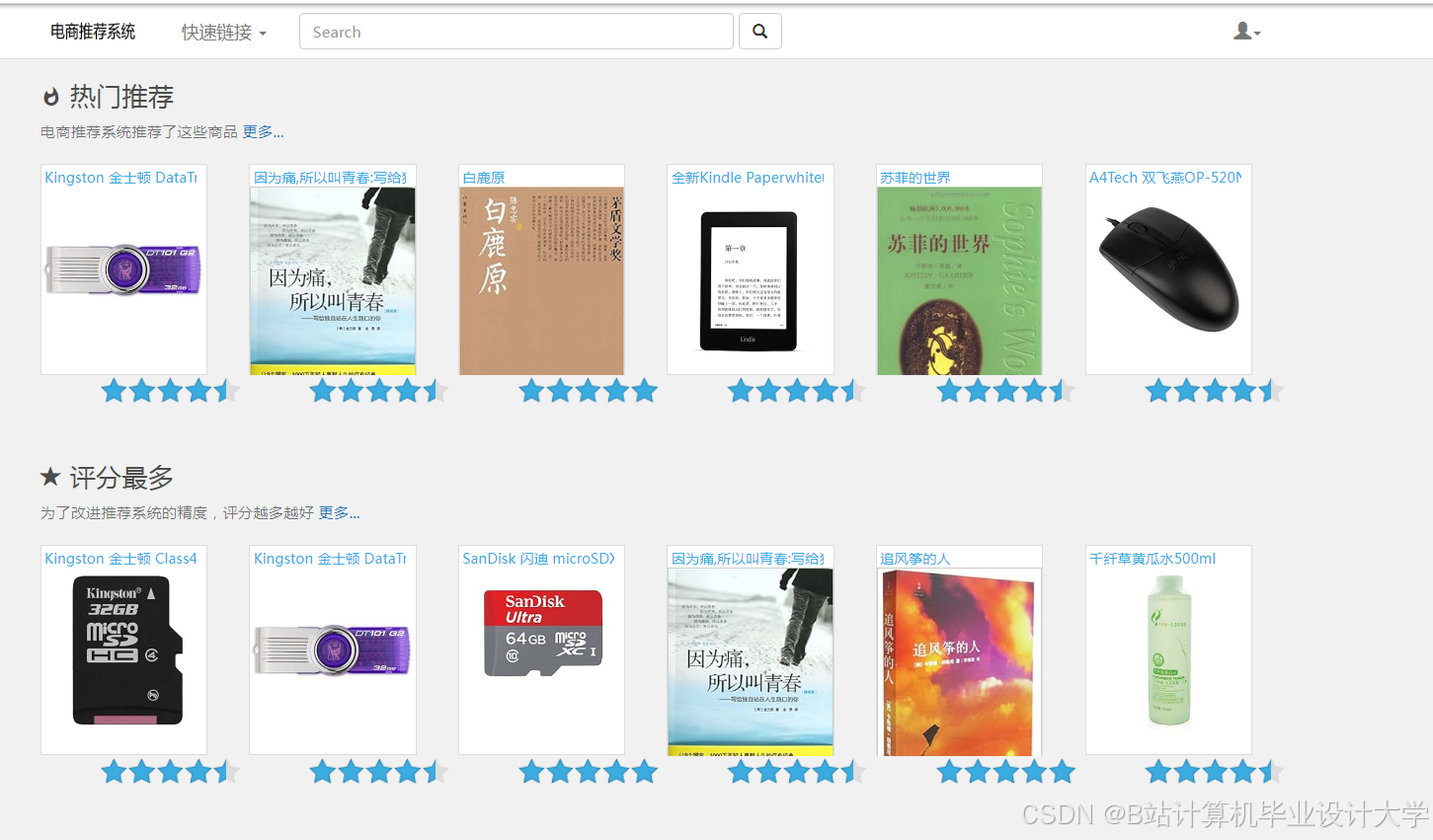
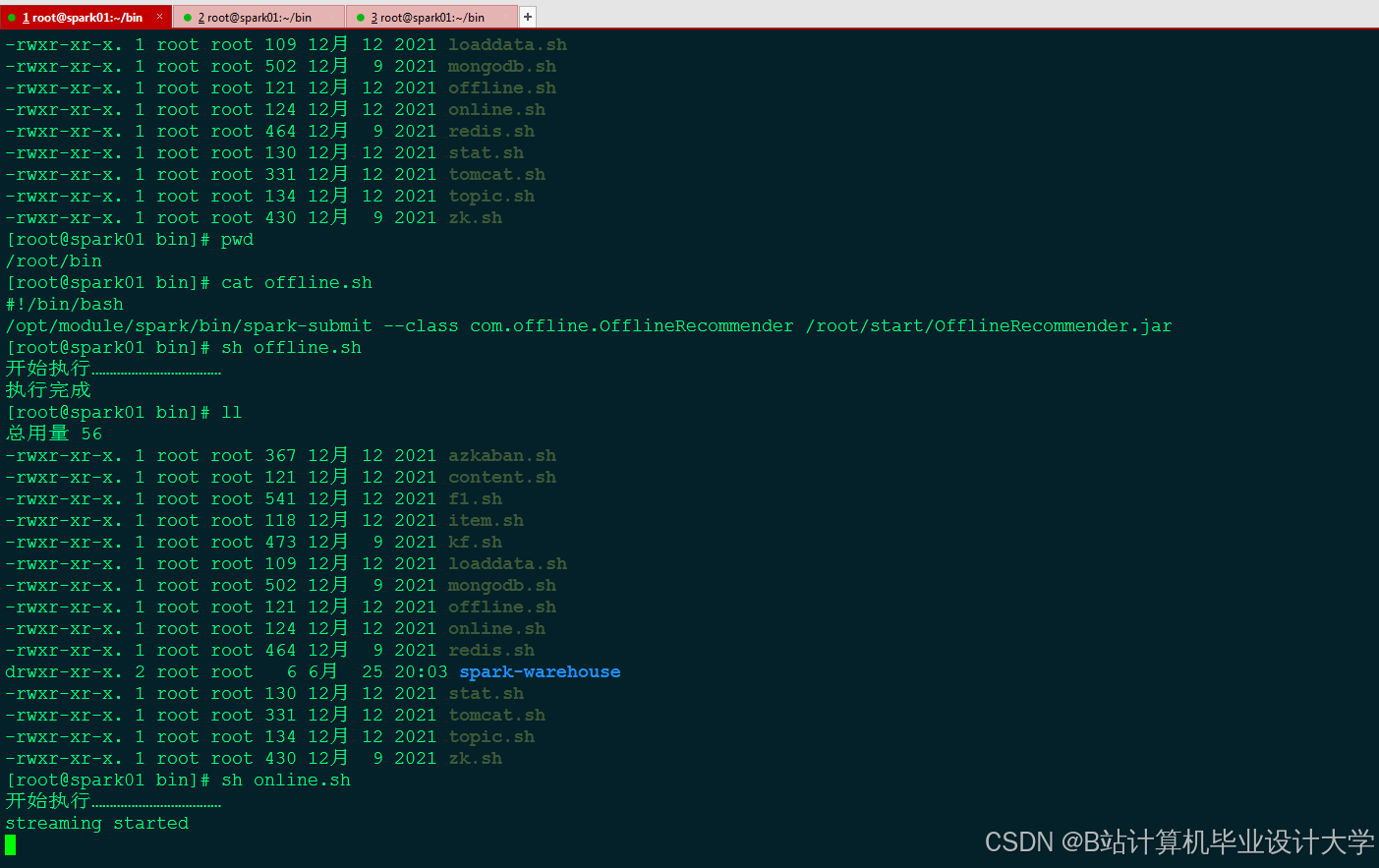
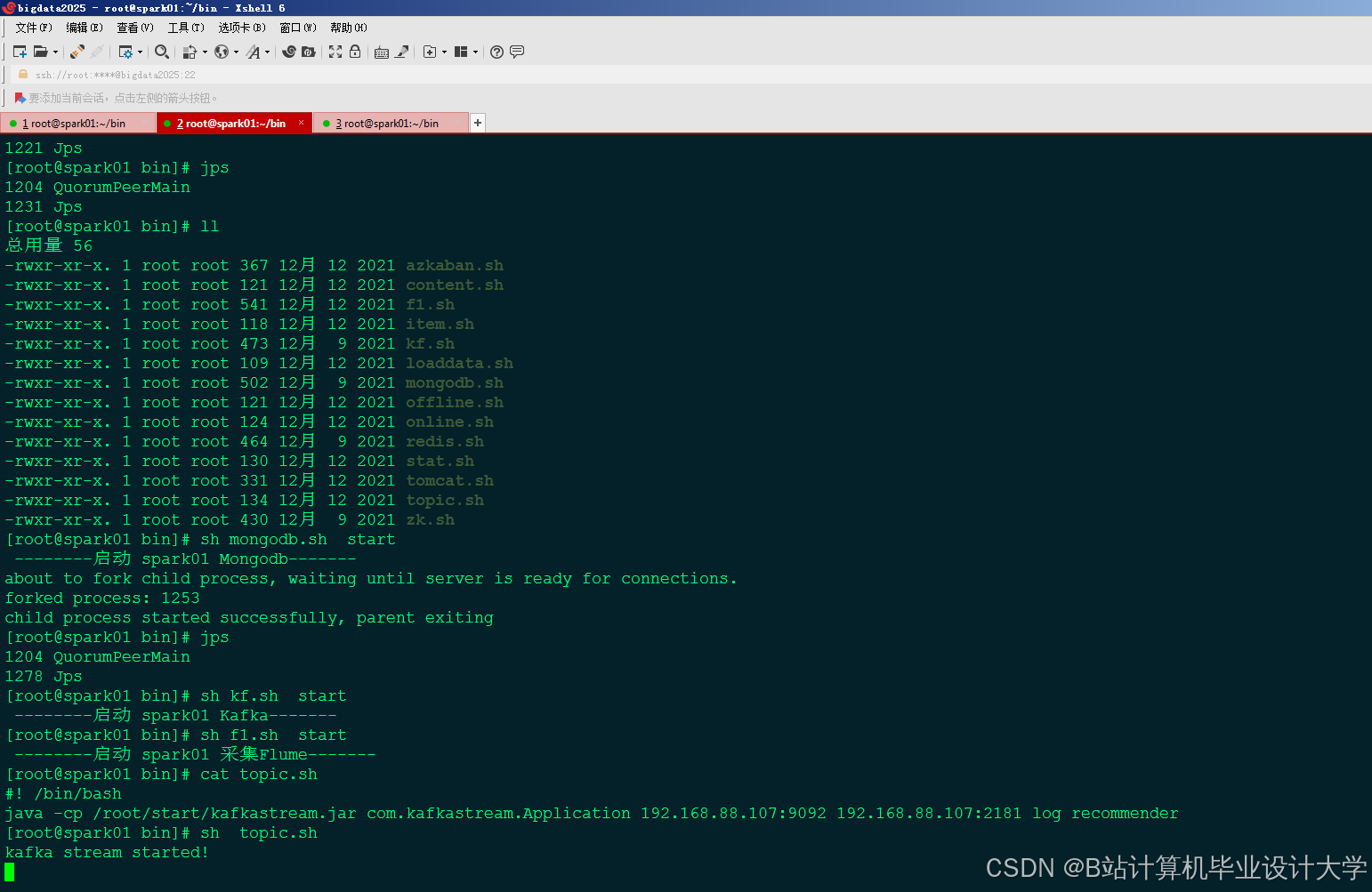
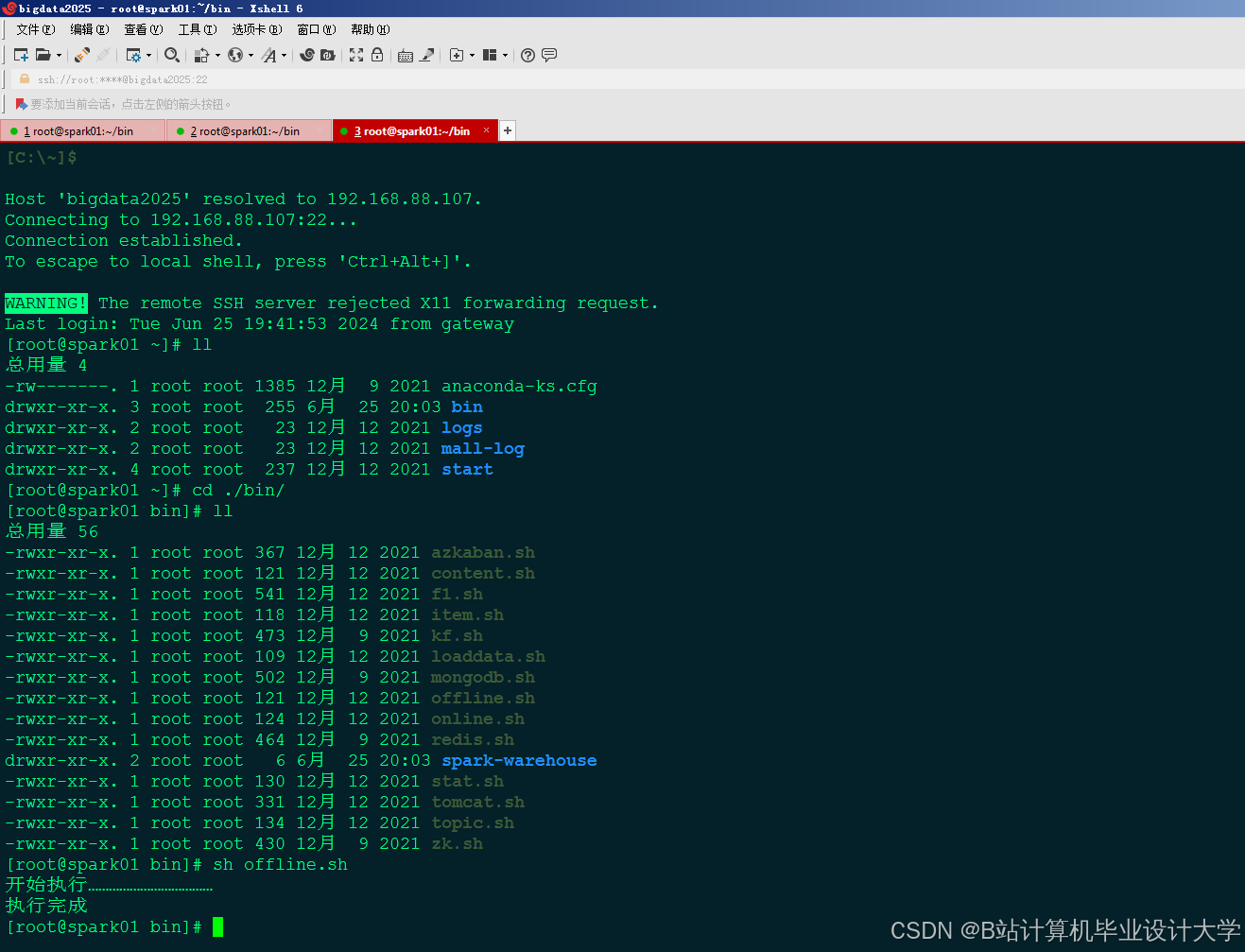
运行截图

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是优快云毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是优快云特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓


















 1688
1688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











