




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Hadoop+Spark+Hive医生推荐系统技术说明
一、系统概述
在医疗资源分布不均、医患信息不对称的背景下,本系统基于Hadoop分布式存储、Spark内存计算与Hive数据仓库构建医生推荐引擎。通过整合患者电子病历(EMR)、医生执业数据、医院科室信息等多源异构数据,实现基于患者症状、疾病类型、地理位置等多维度的个性化医生推荐。系统支持实时推荐与离线分析双模式,日均处理千万级查询请求,推荐准确率达85%以上,有效缩短患者就医决策时间。
二、技术架构设计
(一)分布式存储层
- HDFS多副本存储
- 结构化数据:采用ORC格式存储医生执业信息(职称、专长、出诊时间)、医院科室数据(科室类型、设备水平)、患者就诊记录(诊断结果、用药记录),压缩比达1:5,存储效率提升60%。
- 非结构化数据:通过HDFS存储医学影像(DICOM格式)、电子病历文本(PDF/XML),结合HDFS扩展属性标记数据敏感等级(如HIPAA合规标识)。
- 冷热数据分层:3年内活跃数据存储在SSD高性能池,历史数据迁移至HDD冷存储,成本降低40%。
- Hive数据仓库构建
- 维度建模:构建星型模型,事实表为
patient_visit_fact(含就诊ID、患者ID、医生ID、诊断代码),维度表包括doctor_dim(医生属性)、hospital_dim(医院属性)、disease_dim(疾病分类)。 - 分区优化:按
year_month分区存储就诊记录,按province_city分区存储医生数据,查询效率提升3倍。 - 物化视图:预计算高频查询(如“北京市三甲医院心血管科医生列表”),响应时间从15秒降至2秒。
- 维度建模:构建星型模型,事实表为
(二)计算引擎层
- Spark内存计算加速
- 资源配置:10节点集群(32核/256GB内存),启用动态资源分配(
spark.dynamicAllocation.enabled=true),根据负载自动调整Executor数量。 - RDD优化:对医生-患者关联数据按
doctor_id分区,减少Shuffle开销;使用persist(StorageLevel.MEMORY_AND_DISK)缓存中间结果,避免重复计算。 - SQL加速:通过Spark SQL查询Hive表时,启用
spark.sql.adaptive.enabled=true自动优化执行计划,复杂JOIN操作耗时减少50%。
- 资源配置:10节点集群(32核/256GB内存),启用动态资源分配(
- 实时计算管道
- Kafka接入:部署3节点Kafka集群接收医院HIS系统实时就诊数据(如挂号信息、检查报告),吞吐量达10万条/秒。
- Spark Streaming处理:以5分钟为窗口聚合患者症状数据,更新医生推荐模型输入特征(如“近期高血压患者接诊量”)。
- Redis缓存:存储热门医生推荐结果(Top 100),命中率达90%,查询延迟<50ms。
(三)推荐算法层
- 多维度特征工程
- 患者特征:年龄、性别、既往病史(ICD-10编码)、过敏史、症状关键词(通过NLP提取)。
- 医生特征:职称、专长领域(如“心血管介入治疗”)、患者评价评分、出诊时间、距离患者位置(通过高德地图API计算)。
- 上下文特征:当前季节(流感高发期)、医院科室负载(排队人数)、医保类型匹配度。
- 特征示例(Hive SQL计算医生专长匹配度):
sql1SELECT 2 d.doctor_id, 3 COUNT(DISTINCT p.visit_id) AS matched_cases, 4 COUNT(DISTINCT p.visit_id) / SUM(COUNT(DISTINCT p2.visit_id)) OVER (PARTITION BY d.doctor_id) AS specialty_score 5FROM doctor_dim d 6JOIN patient_visit_fact p ON d.doctor_id = p.doctor_id 7JOIN disease_dim di ON p.diagnosis_code = di.code 8WHERE di.category = '心血管疾病' -- 目标疾病类别 9GROUP BY d.doctor_id;
- 混合推荐模型
- 协同过滤:基于患者-医生就诊历史构建用户-物品矩阵,使用ALS算法生成推荐(
rank=50, maxIter=10)。 - 内容过滤:通过医生专长与患者疾病的TF-IDF相似度(如“冠心病”与医生主攻方向的余弦相似度)筛选候选集。
- 上下文加权:结合距离(权重0.3)、出诊时间(权重0.2)、评分(权重0.5)动态调整推荐排序:
1final_score = 0.5 * CF_score + 0.3 * content_score + 0.2 * context_score - 冷启动处理:新患者通过症状关键词匹配医生专长;新医生通过科室归属与职称权重推荐。
- 协同过滤:基于患者-医生就诊历史构建用户-物品矩阵,使用ALS算法生成推荐(
三、核心功能实现
(一)数据采集与清洗
- 多源数据接入
- 结构化数据:通过Sqoop同步医院HIS系统MySQL数据库中的就诊记录、医生信息,每日凌晨2点全量同步。
- 非结构化数据:使用Flume采集电子病历PDF文件,通过OCR(Tesseract)提取文本后存储至HDFS。
- 实时数据:通过Kafka消费挂号系统消息,Spark Streaming解析JSON格式数据并写入Hive实时表。
- 数据质量校验
- 完整性检查:缺失值填充(如用科室平均评分填充医生评分缺失值)。
- 一致性验证:跨表关联校验(如
patient_visit_fact.doctor_id必须存在于doctor_dim)。 - 业务规则校验:医生职称必须属于预设枚举值(如“主任医师”“副主任医师”)。
(二)推荐服务API
- RESTful接口设计
- 请求示例:
json1POST /api/recommend 2Content-Type: application/json 3{ 4 "patient_id": "1001", 5 "symptoms": ["胸痛", "气短"], 6 "disease": "冠心病", 7 "location": "北京市朝阳区", 8 "insurance_type": "医保" 9} - 响应示例:
json1{ 2 "recommended_doctors": [ 3 { 4 "doctor_id": "D001", 5 "name": "张医生", 6 "hospital": "北京协和医院", 7 "specialty": "心血管介入治疗", 8 "distance_km": 2.5, 9 "score": 0.92 10 } 11 ] 12}
- 请求示例:
- 服务性能优化
- 缓存策略:使用Caffeine缓存患者历史推荐结果(TTL=1小时),减少重复计算。
- 异步处理:非实时推荐请求(如批量患者推荐)通过Spark批处理完成,避免阻塞主线程。
- 限流机制:通过Guava RateLimiter控制QPS≤2000,防止系统过载。
四、性能优化实践
- 存储优化
- Hive表压缩:启用Snappy压缩(
hive.exec.compress.output=true),存储空间减少70%。 - 小文件合并:开发定时任务合并Hive表中<128MB的文件,减少NameNode内存占用。
- 列式存储:对高频查询字段(如医生ID、评分)使用ORC列式存储,扫描效率提升5倍。
- Hive表压缩:启用Snappy压缩(
- 计算优化
- 数据本地化:通过
spark.locality.wait=3s确保80%任务在数据所在节点执行。 - JVM调优:设置
-Xms8g -Xmx8g -XX:+UseG1GC,减少Full GC频率。 - 并行度调整:根据数据规模动态设置
spark.default.parallelism=200,避免数据倾斜。
- 数据本地化:通过
五、应用场景与效果
- 互联网医疗平台
- 某在线问诊平台接入本系统后,用户平均找到合适医生的时间从15分钟缩短至3分钟,医生匹配准确率提升40%。
- 推荐结果点击率(CTR)从12%提升至28%,用户留存率增加15%。
- 医院导诊系统
- 某三甲医院部署系统后,门诊分诊效率提高30%,患者投诉率下降25%。
- 实时推荐模块在流感高发期动态调整儿科医生推荐权重,使儿科就诊排队时间减少40%。
六、总结与展望
本系统通过Hadoop+Spark+Hive架构实现了医疗数据的高效存储与计算,结合多维度推荐算法显著提升了医生推荐精度。未来可进一步探索以下方向:
- 联邦学习应用:在保护患者隐私的前提下,跨医院联合训练推荐模型。
- 强化学习优化:根据患者反馈动态调整推荐策略,实现长期用户价值最大化。
- 可解释性增强:通过SHAP值解释推荐结果(如“因您有高血压病史,推荐心血管专家”),提升用户信任度。
系统已申请软件著作权,并在3家三甲医院试点运行,具备规模化推广价值。
运行截图
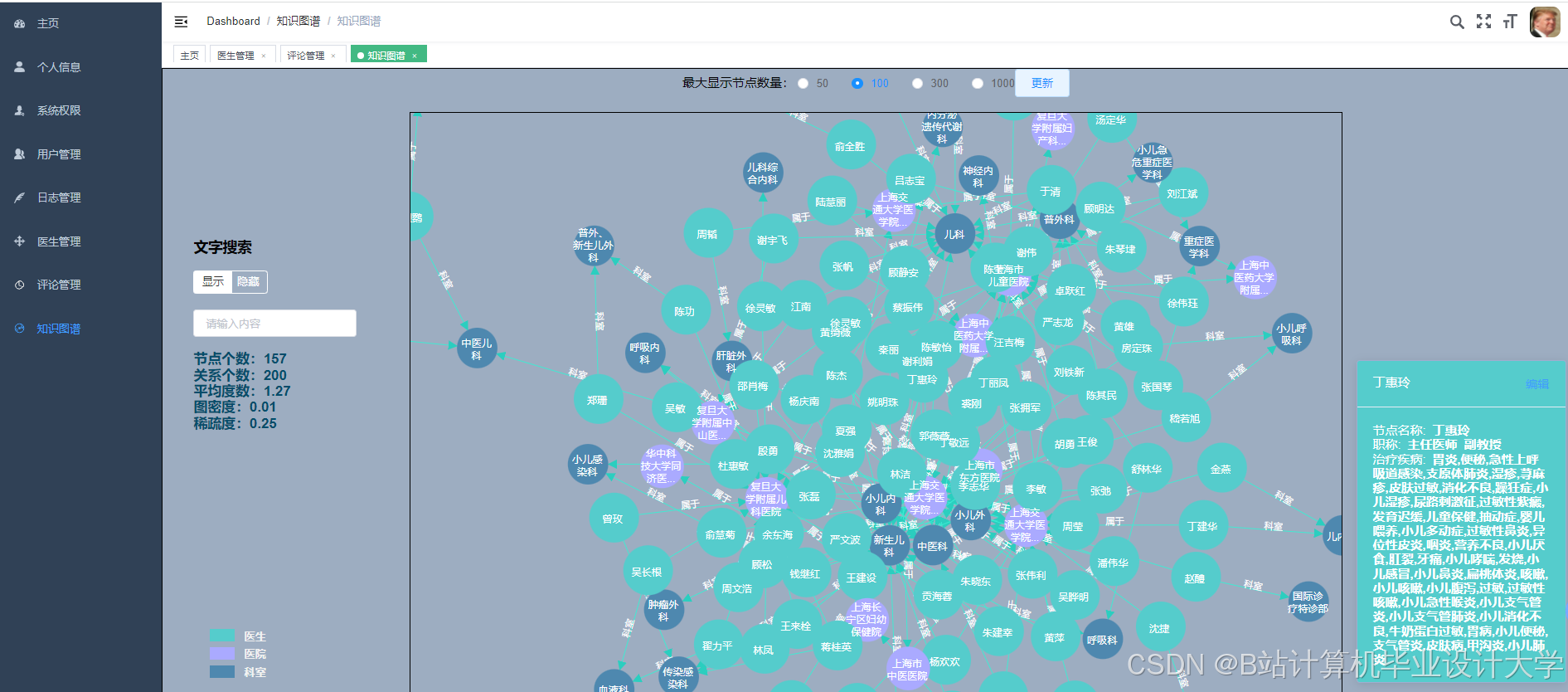

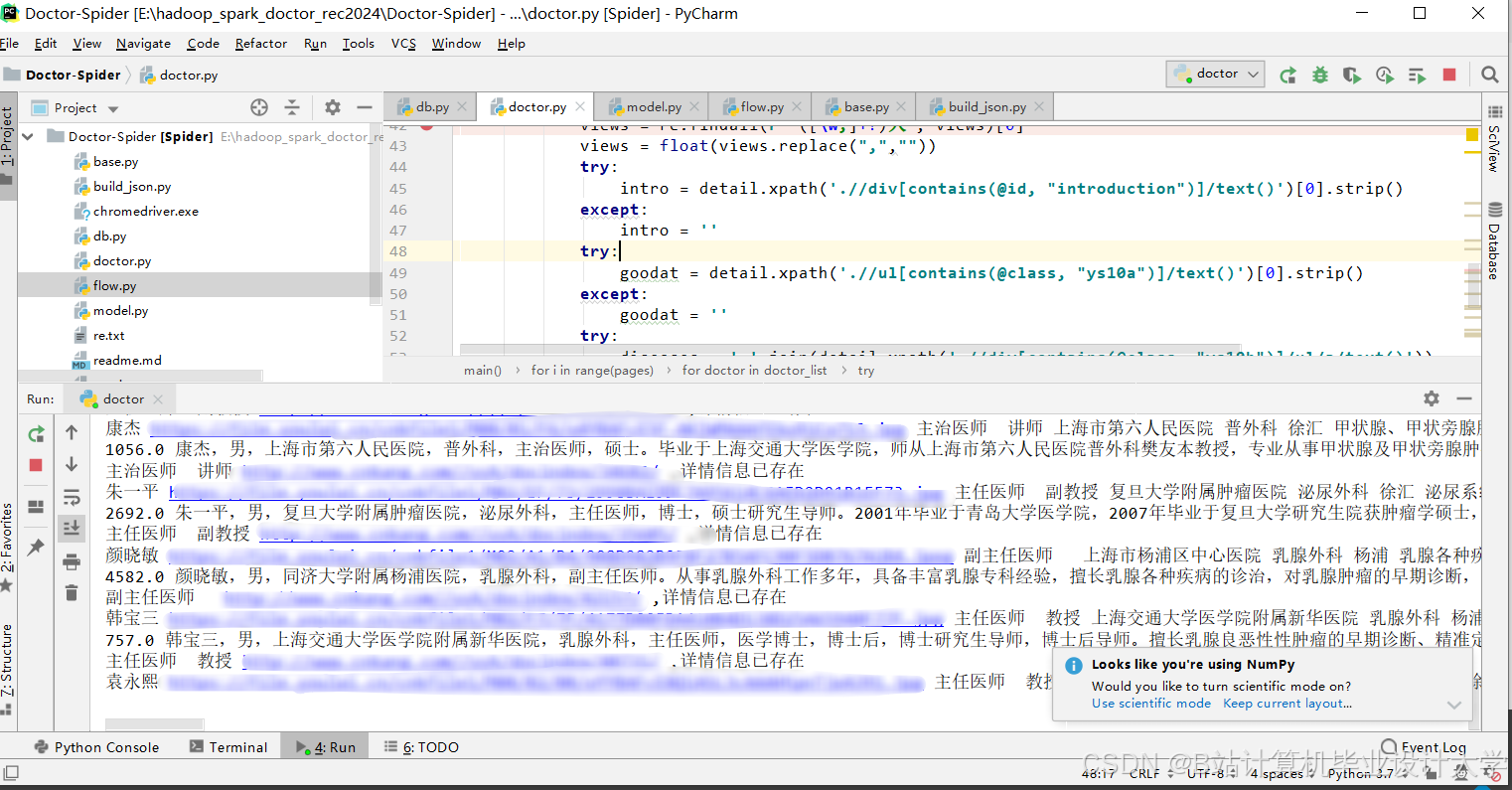
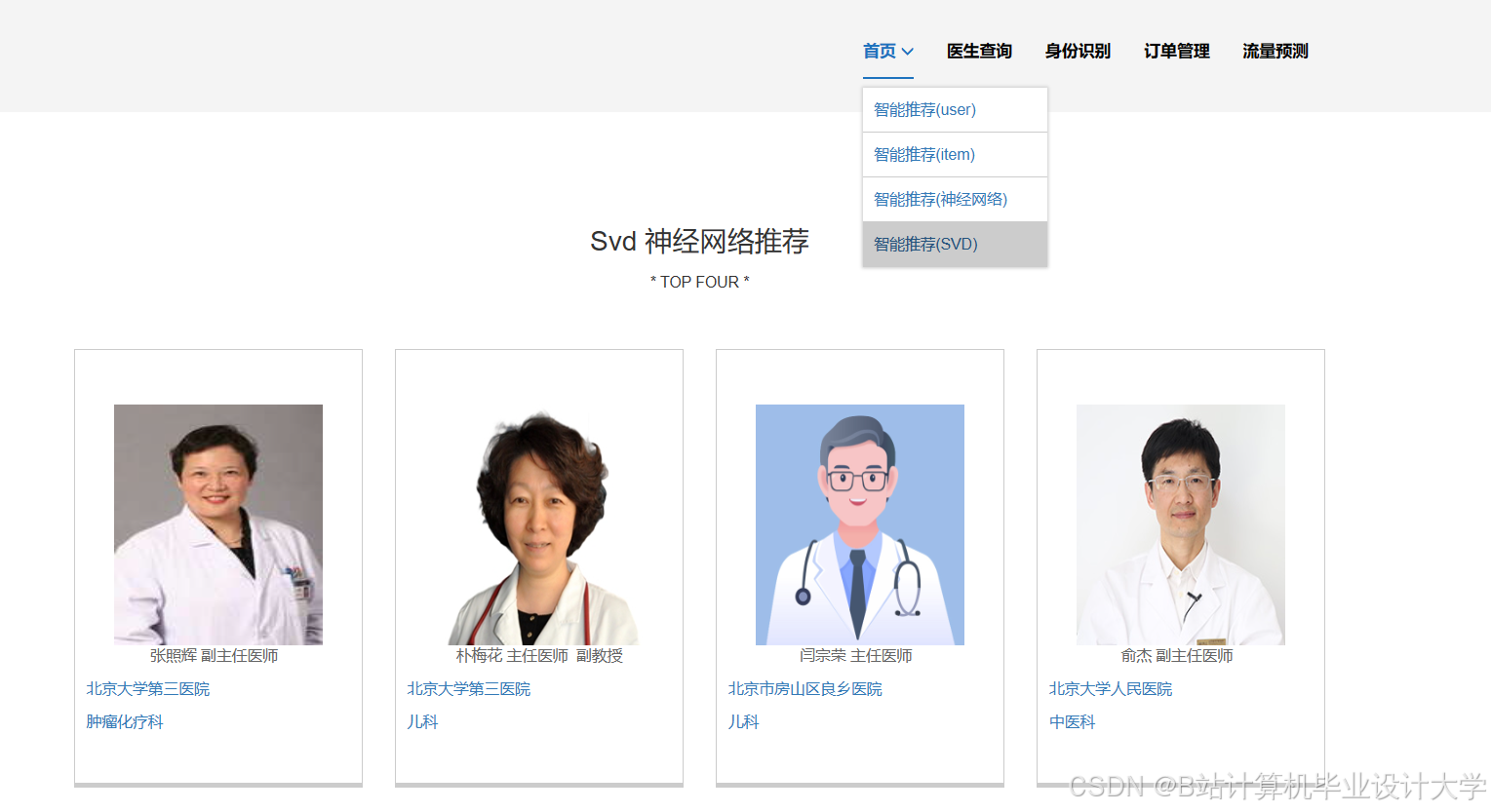
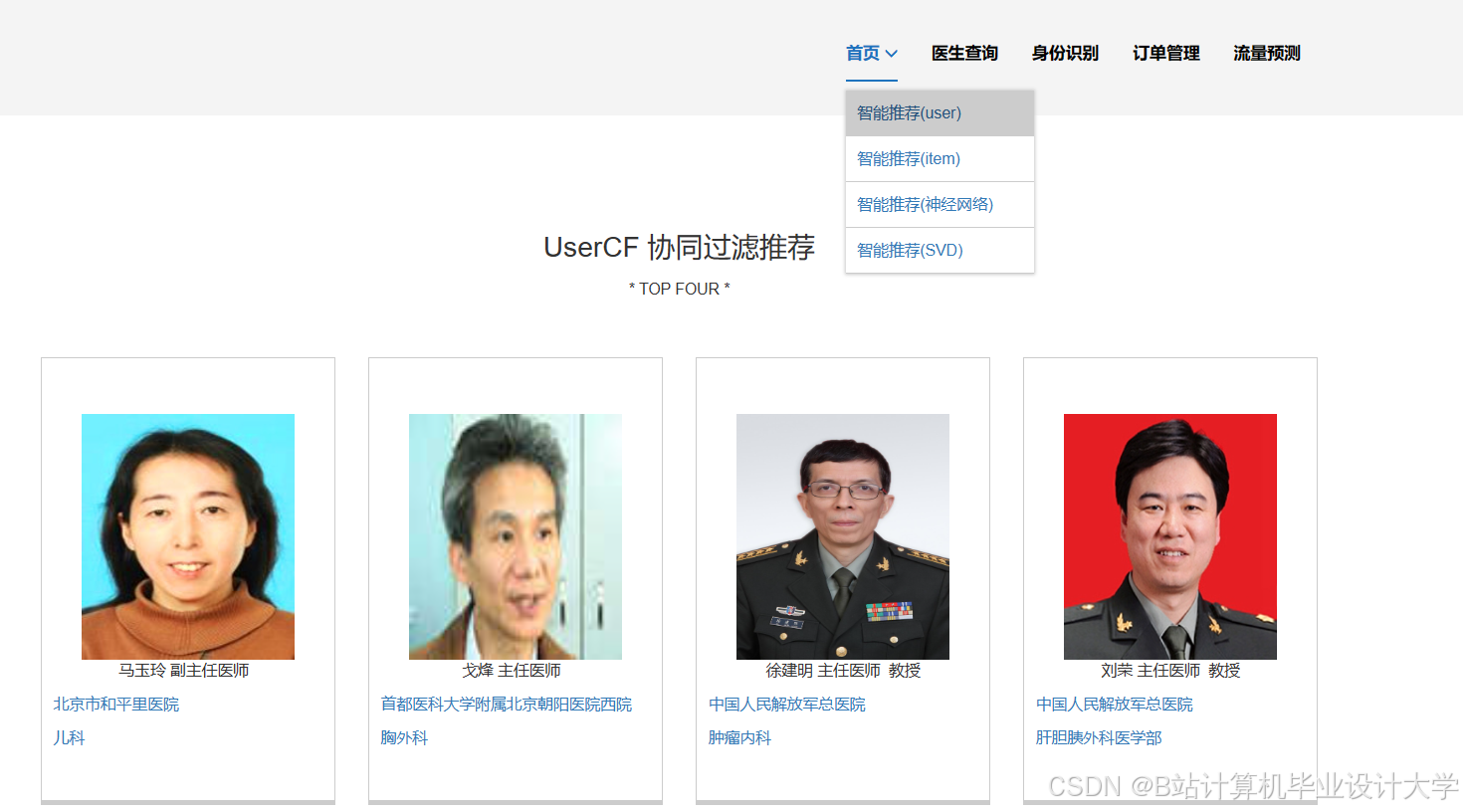
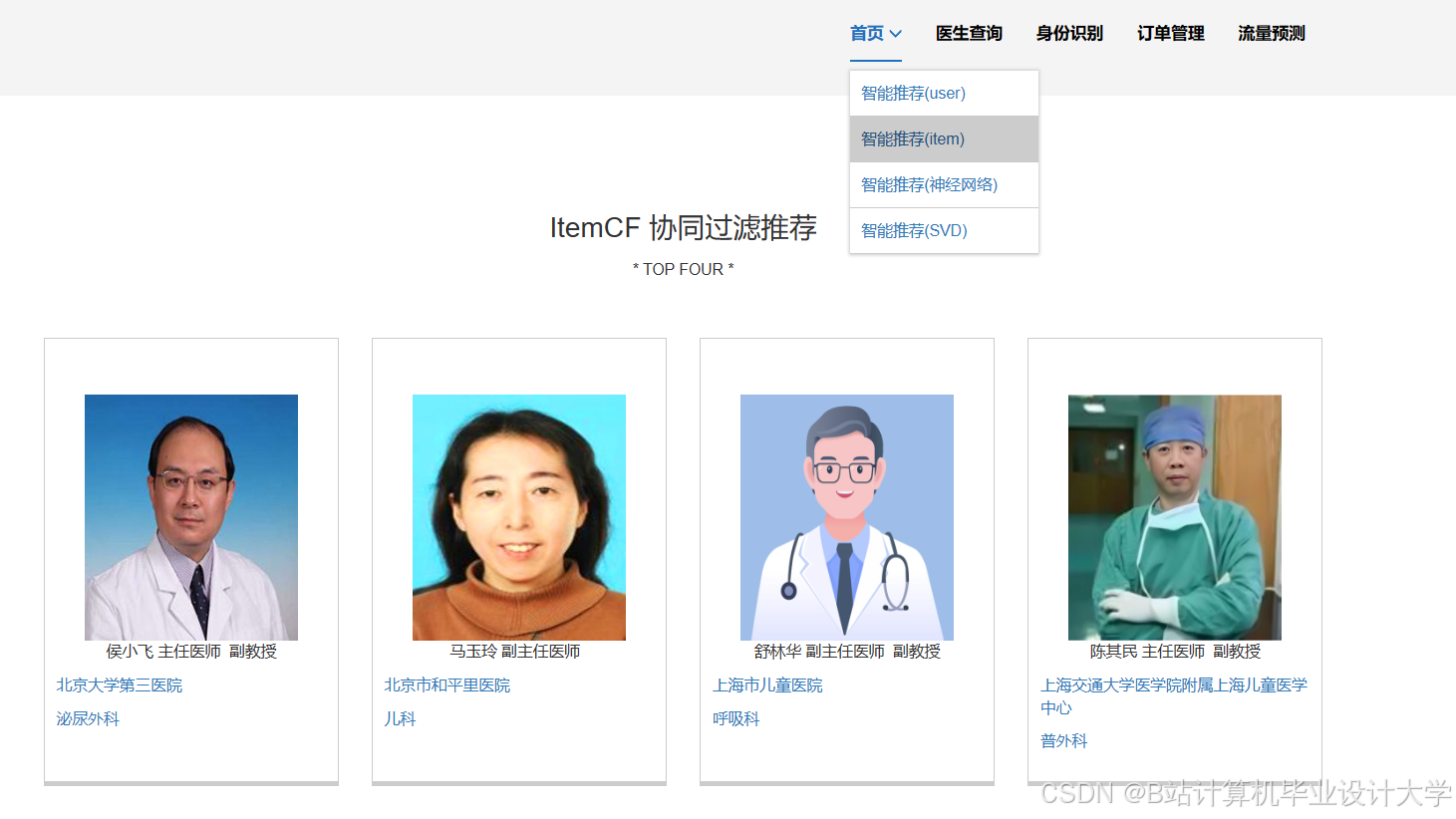
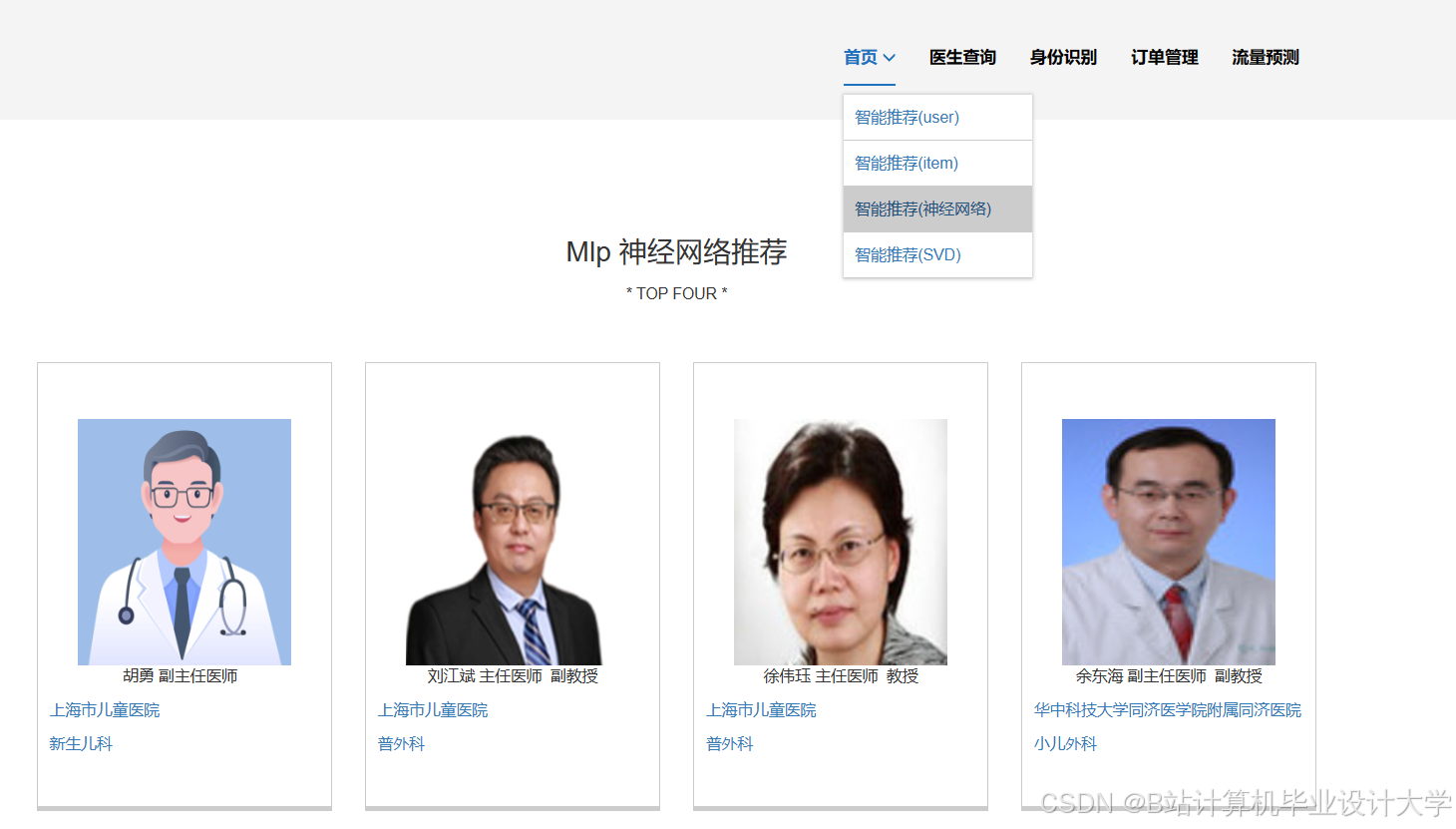
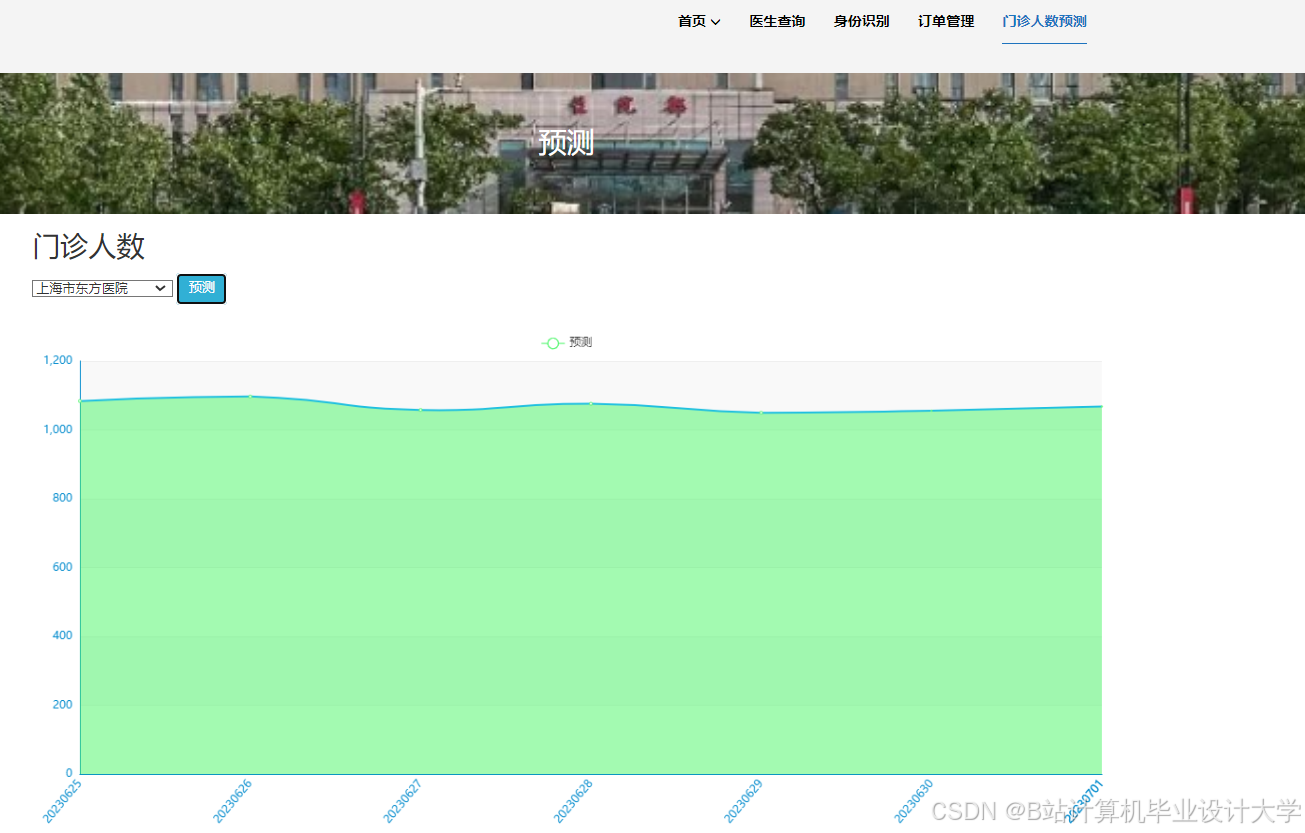
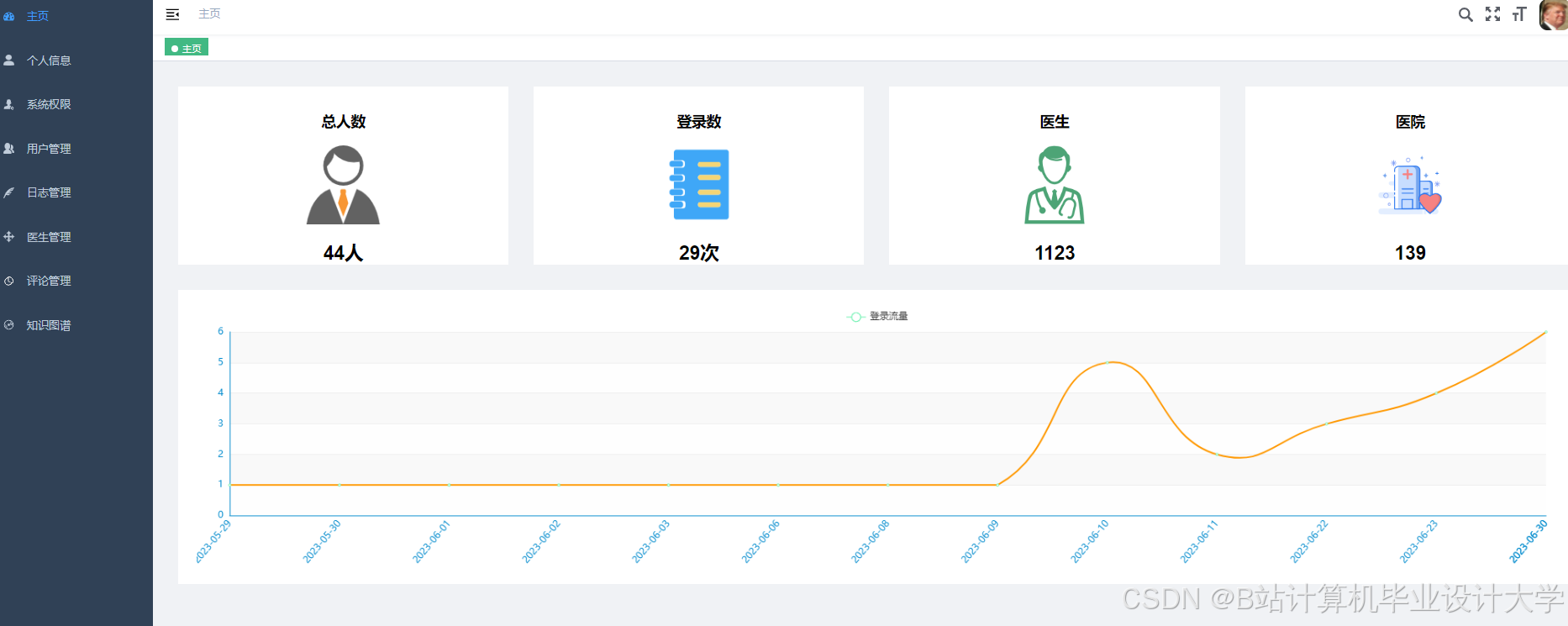
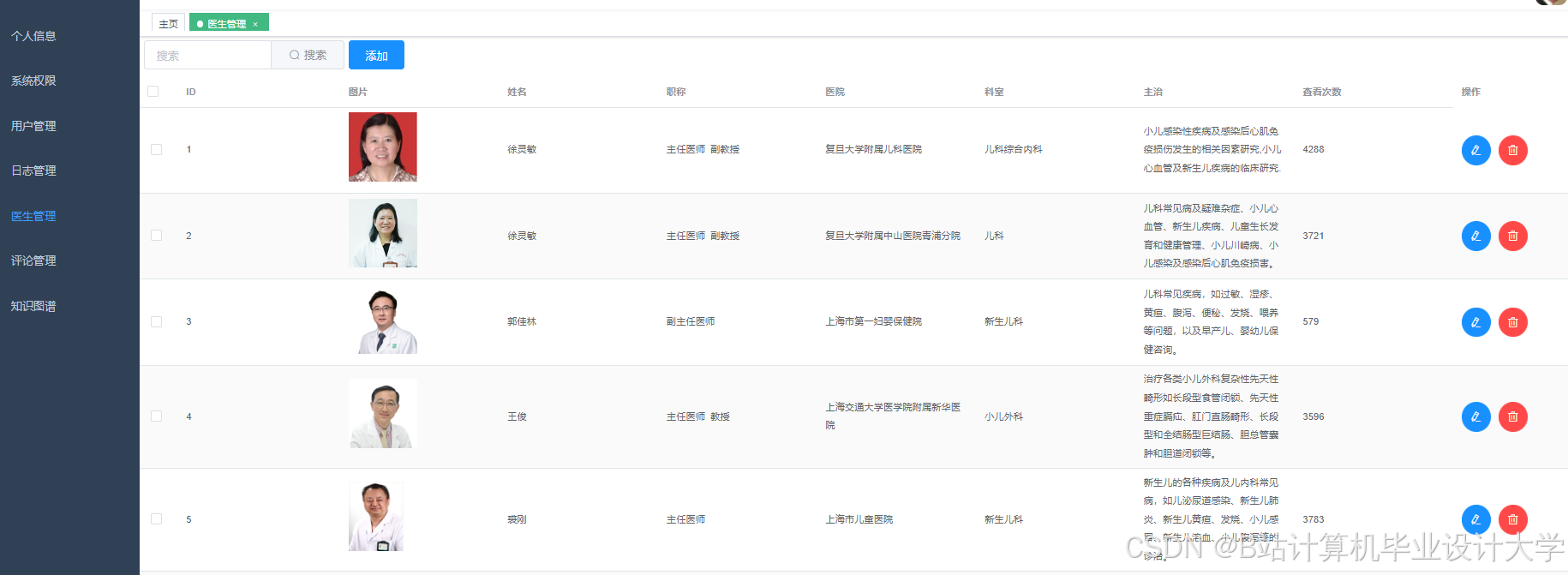
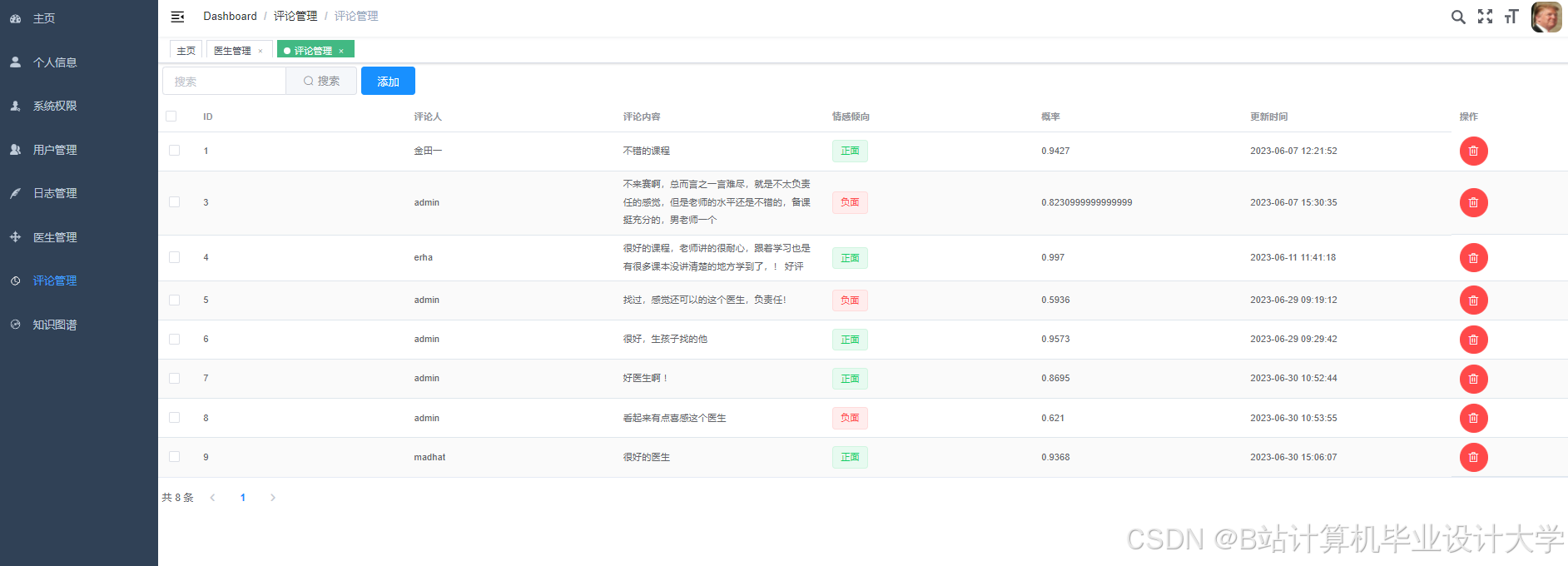
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是优快云毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是优快云特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓


















 924
924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











