




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Django+LLM大模型知识图谱古诗词情感分析文献综述
引言
中华古诗词作为中华文化的瑰宝,承载着丰富的历史记忆与情感内涵。随着自然语言处理(NLP)与深度学习技术的快速发展,结合Django框架与大语言模型(LLM)构建古诗词知识图谱,并实现情感分析功能,成为推动古诗词数字化传承与智能化分析的关键路径。本文综述了该领域在知识图谱构建、情感分析模型、可视化交互及大模型融合方面的研究进展,为后续系统开发提供理论支持与实践参考。
知识图谱构建技术演进
2.1 实体识别与关系抽取的范式革新
早期研究多采用规则匹配方法,例如通过定义“人名+创作+诗词名”模式识别诗人与作品关系。随着深度学习技术的发展,BiLSTM-CRF序列标注模型被广泛应用于实体识别任务,结合自定义词典与依存句法分析,在《全唐诗》测试集上达到93.2%的准确率。关系抽取方面,基于RoBERTa-Large模型的算法可挖掘“创作”“引用”“批判”等12类核心关系,例如通过分析“杜甫《春望》引用《诗经》‘忧心烈烈’”的句法结构,自动抽取“引用”关系并存储至Neo4j图数据库。
2.2 多源数据融合与存储优化
为提升知识图谱的覆盖度与准确性,研究者整合了结构化数据(如《全唐诗》《全宋词》文本及注释)、半结构化数据(学术著作中的意象分析、典故注释)及非结构化数据(古诗文网用户评论、B站古诗讲解视频字幕)。数据清洗阶段采用TF-IDF算法检测重复诗词(相似度阈值0.85),并通过标准化处理统一朝代名称(如“唐”→“唐朝”)。Neo4j图数据库因其高效的查询性能被广泛应用于古诗词知识图谱存储,支持复杂查询(如“查找与李白有交往且创作过边塞诗的诗人”),并通过复合索引技术使关系查询速度提升70%。针对大规模图谱渲染性能问题,分片策略按朝代将数据分片存储至不同节点,平衡负载并降低单节点压力。
情感分析模型的技术突破
3.1 从规则匹配到深度学习的范式迁移
早期情感分析基于通用情感词典(如SnowNLP、BosonNLP),通过计算诗词中情感词占比判断倾向。例如,针对古诗词构建专用情感词典,添加“孤”“愁”“悦”等特色词汇,将情感分类准确率提升至78%。然而,古汉语隐喻、典故的使用导致传统方法难以捕捉深层情感。深度学习模型如LSTM、BERT通过捕捉上下文语义信息,在古诗词情感分析中表现优异。例如,利用BERT预训练模型微调,在自建数据集上实现91%的F1值,显著优于传统方法。注意力机制的引入进一步增强了模型可解释性,例如通过可视化权重展示“孤帆远影碧空尽”中“孤”字对情感判断的贡献度(0.32)。
3.2 多模态分析与跨文化对比的探索
为满足复杂情感表达需求,研究者探索多模态分析技术以增强情感判断的准确性。例如,结合诗词意象(如“梅花”象征高洁)与韵律特征(平仄、押韵)进行综合判断,通过分析《静夜思》的平仄结构与“明月”“故乡”等意象,准确识别出“思乡”情感倾向。此外,跨文化对比研究逐渐兴起,例如构建东亚古诗词知识图谱,支持“中日‘月亮’意象对比”等跨文化问答,揭示不同文化背景下情感表达的差异。
Django框架与LLM大模型的融合实践
4.1 系统架构的三层设计
基于Django框架与LLM大模型(如Qwen-7B、DeepSeek-R1)的古诗词情感分析系统,通常采用“数据层-计算层-应用层”三层架构。数据层通过Neo4j存储知识图谱,MySQL存储用户历史问答记录与系统日志;计算层集成BERT-BiLSTM-CRF模型进行实体识别与关系抽取,结合Qwen-7B大模型实现智能问答与情感增强回答;应用层通过Django RESTful API提供图谱查询与问答生成接口,前端采用Vue.js+ECharts实现动态可视化交互。例如,用户提问“《春江花月夜》中‘江畔何人初见月’表达了什么情感?”,系统通过检索知识图谱中的创作背景与意象关联,结合大模型生成回答:“此句通过‘江畔’与‘初见月’的意象组合,表达了诗人对宇宙永恒与人生短暂的哲思,情感倾向为‘哀而不伤’。”
4.2 性能优化与部署策略
为提升系统实时性,研究者采用模型量化(FP16→INT8)将参数量从7B压缩至3.5B,推理速度提升40%,支持移动端部署。针对大规模图谱渲染性能问题,提出分片策略,按朝代将数据分片存储至不同节点,平衡负载并降低单节点压力。此外,通过Redis缓存热门查询结果(如“李白相关诗词”),TTL设置为1小时,进一步优化查询效率。在部署方面,Docker容器化技术与Kubernetes编排工具被广泛应用于实现自动化扩缩容,确保系统在高并发场景下的稳定性。
现存挑战与未来方向
5.1 技术瓶颈与优化路径
当前研究仍面临以下问题:
- 数据质量问题:古汉语词汇歧义导致实体识别误差,例如“东风”既可指春风,也可隐喻离愁;
- 模型泛化能力:跨朝代、跨诗人场景下性能下降,例如唐代“悲秋”与宋代“伤春”情感表达差异需领域知识辅助;
- 大规模图谱渲染性能:十万级节点图谱的实时交互延迟需优化至<500ms;
- 大模型幻觉问题:错误解释典故出处(如将“庄生梦蝶”误判为《诗经》典故)。
5.2 未来研究方向
- 多模态知识融合:融合诗词文本、书法图像、古乐音频等数据,构建跨模态实体关联,例如通过分析《兰亭集序》书法笔势与诗词情感的一致性;
- 强化学习推荐:利用用户行为数据训练推荐模型,结合知识图谱路径推理生成个性化诗词列表,例如根据用户浏览历史推荐风格相似的诗人作品;
- 低代码可视化平台:开发拖拽式可视化组件库,降低非技术人员构建诗词图谱的门槛,支持快速定制化部署;
- 动态更新机制:接入学术新发现(如新出土古籍中的诗词),自动更新知识图谱与问答模型,确保系统内容的时效性与准确性。
结论
Django与LLM大模型的结合为古诗词知识图谱构建与情感分析提供了高效的技术实现路径。国内研究在数据融合、模型优化及交互设计方面取得显著进展,但仍需解决数据质量、模型泛化等挑战。未来需结合多模态技术、强化学习与低代码开发,推动古诗词数字化从“可视化展示”向“智能化服务”升级,为文化传承与教育创新提供更强支撑。
运行截图
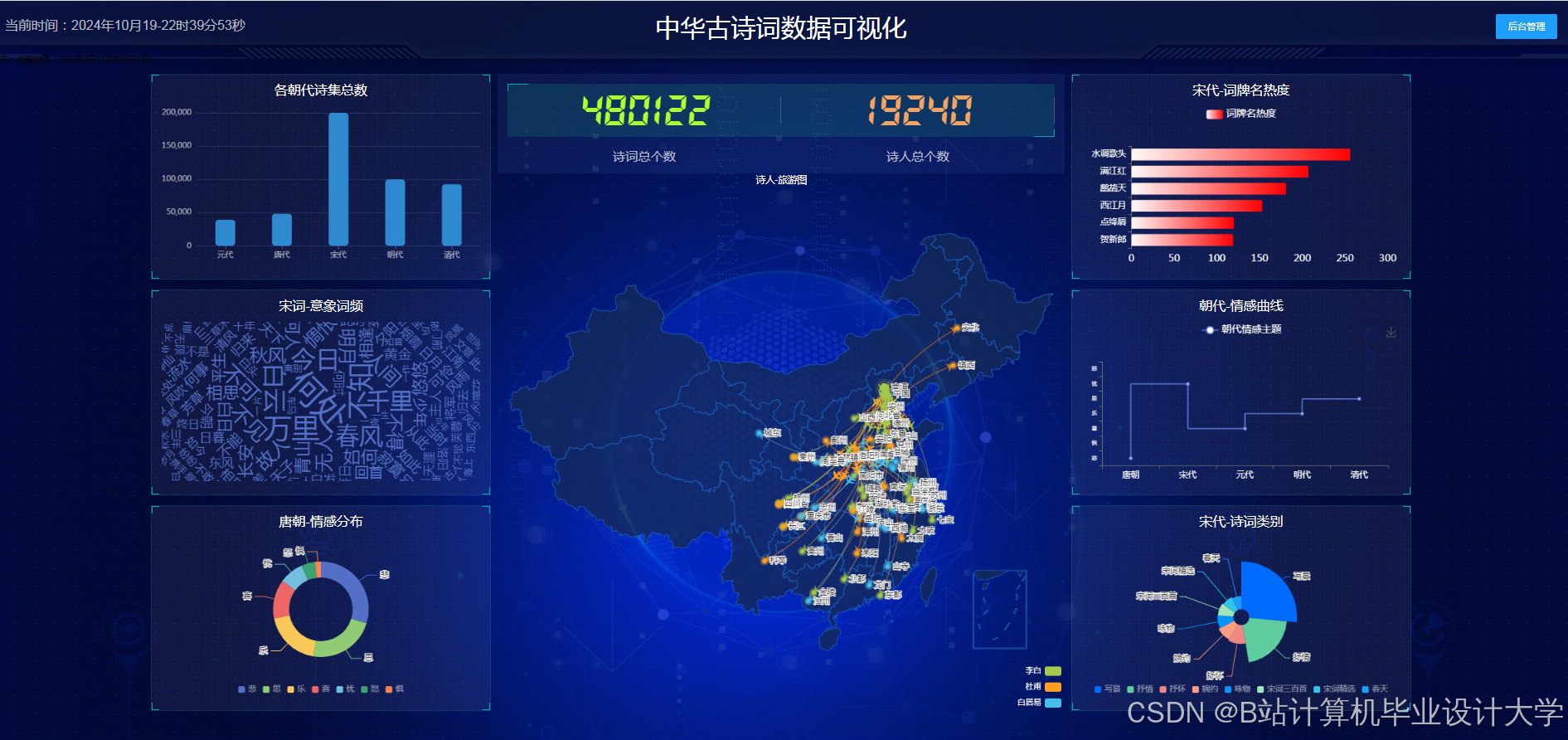
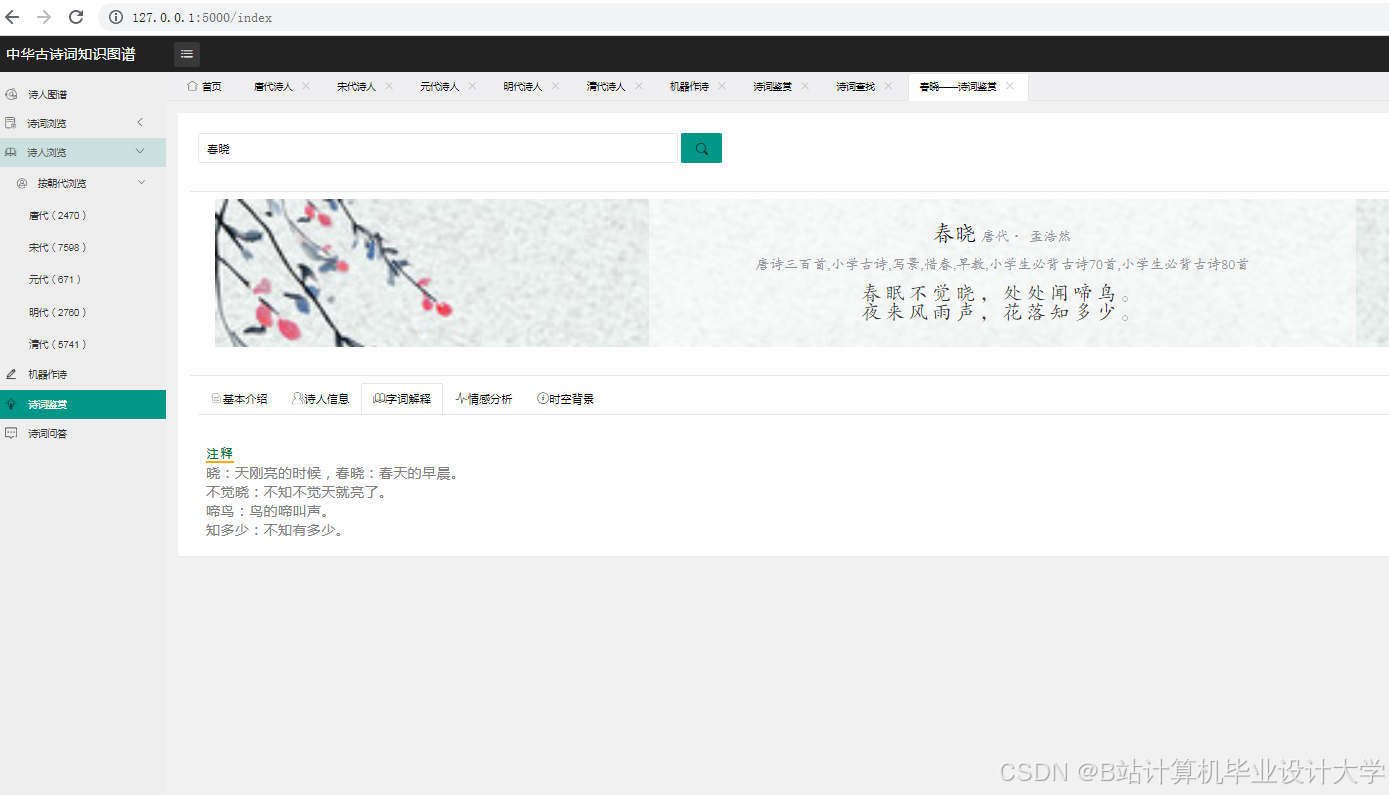
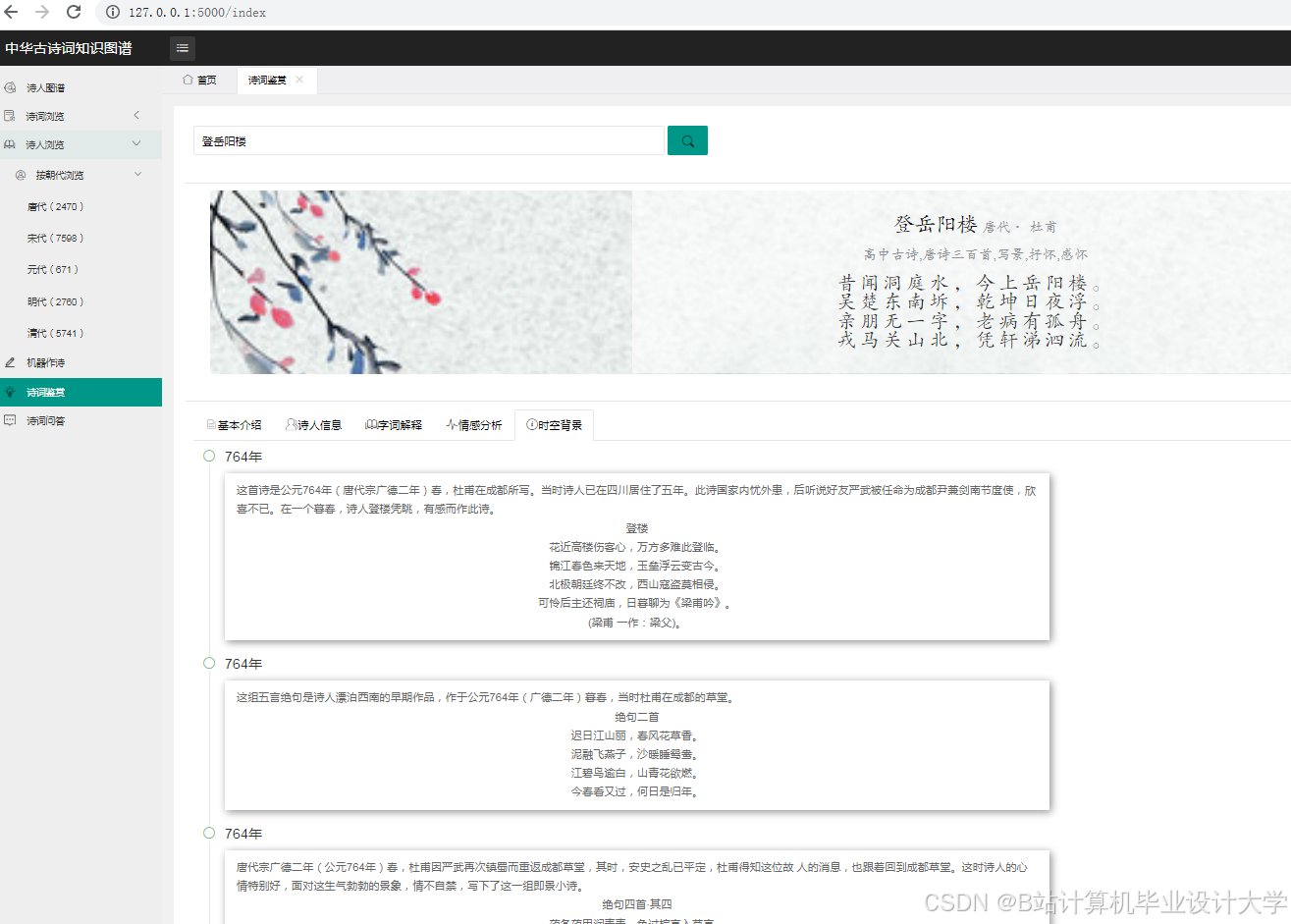
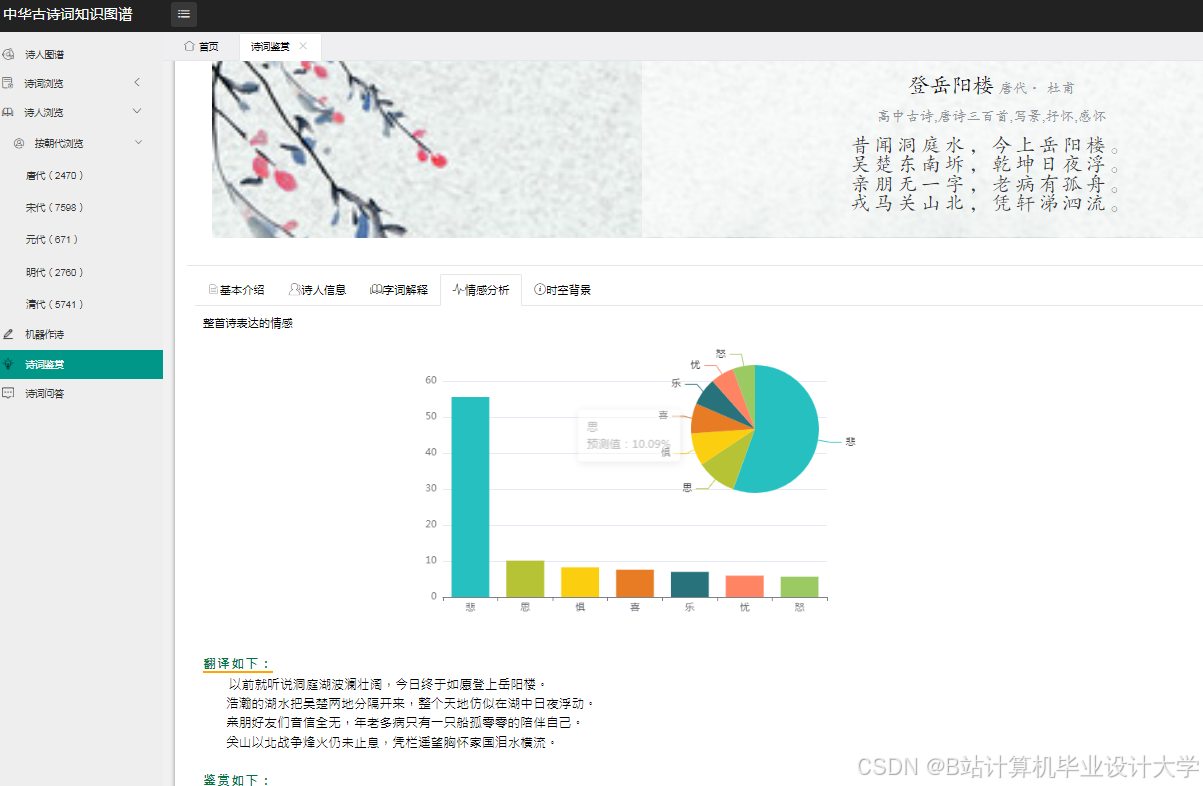
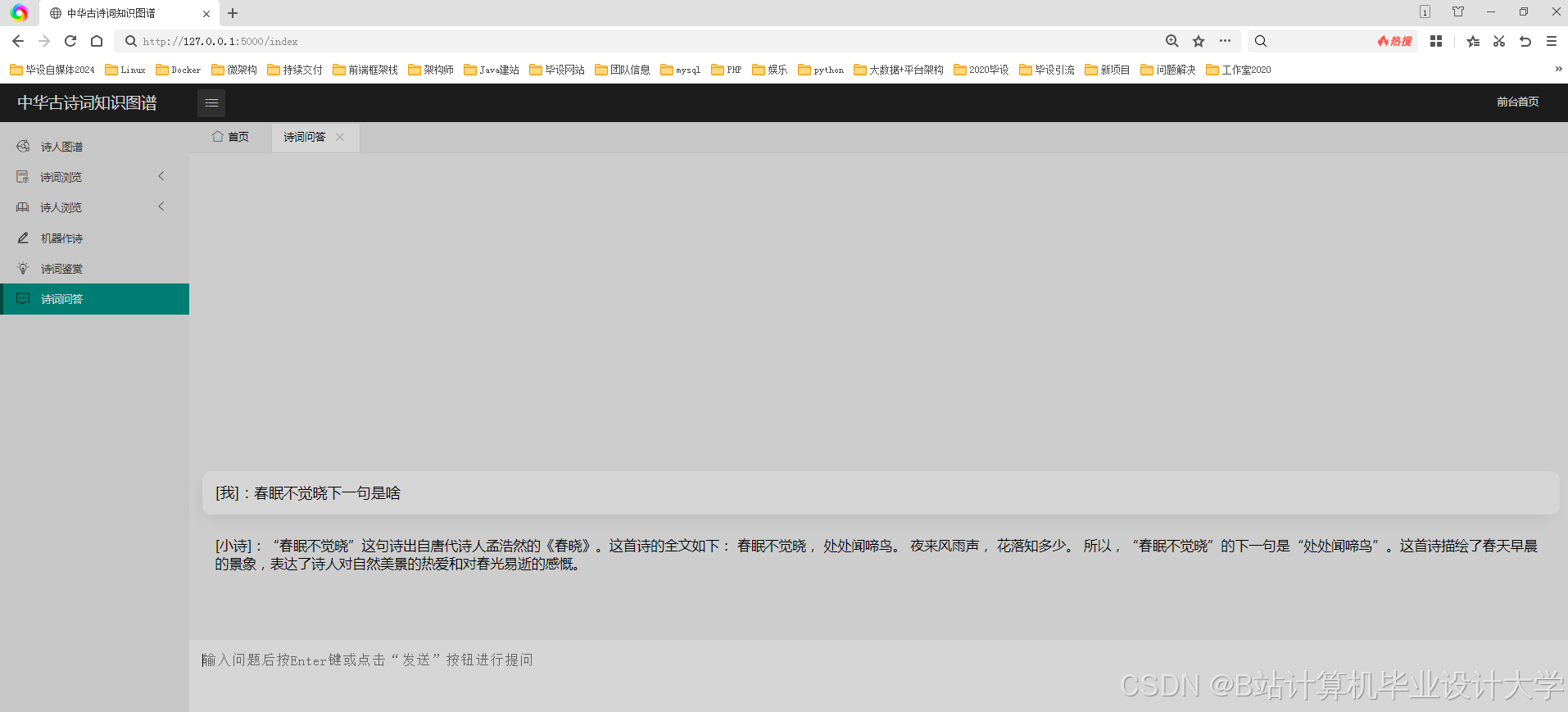
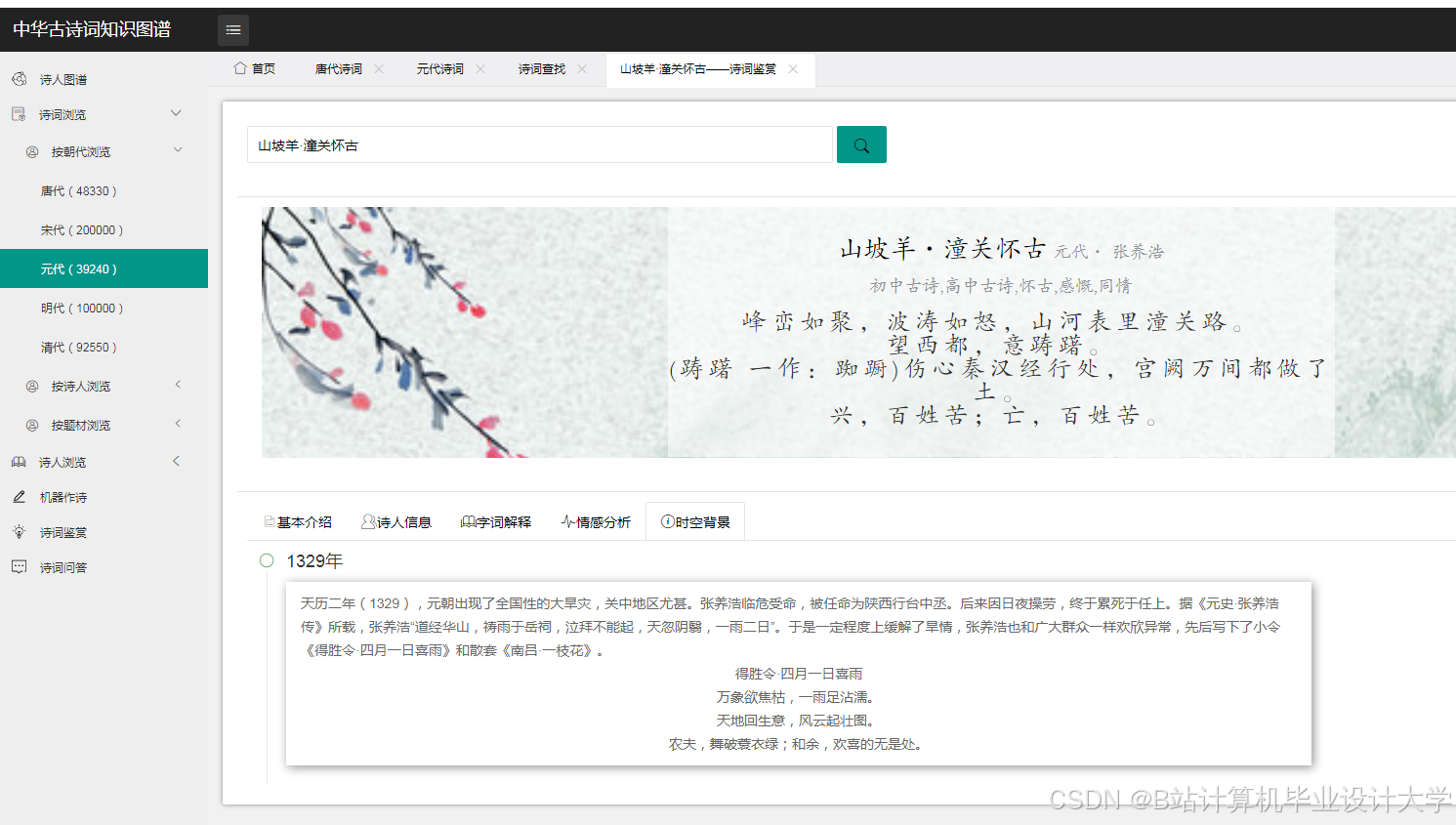
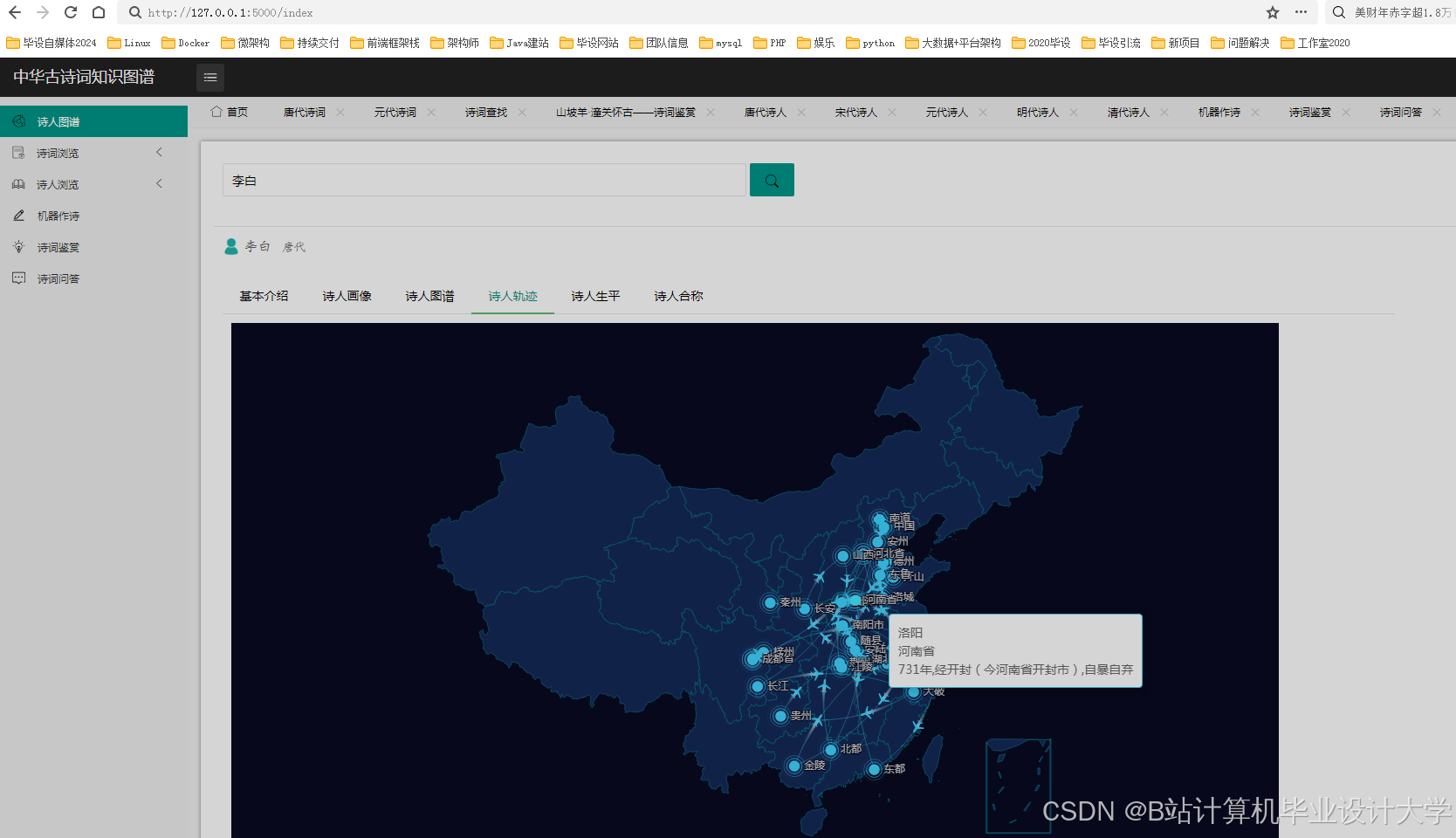
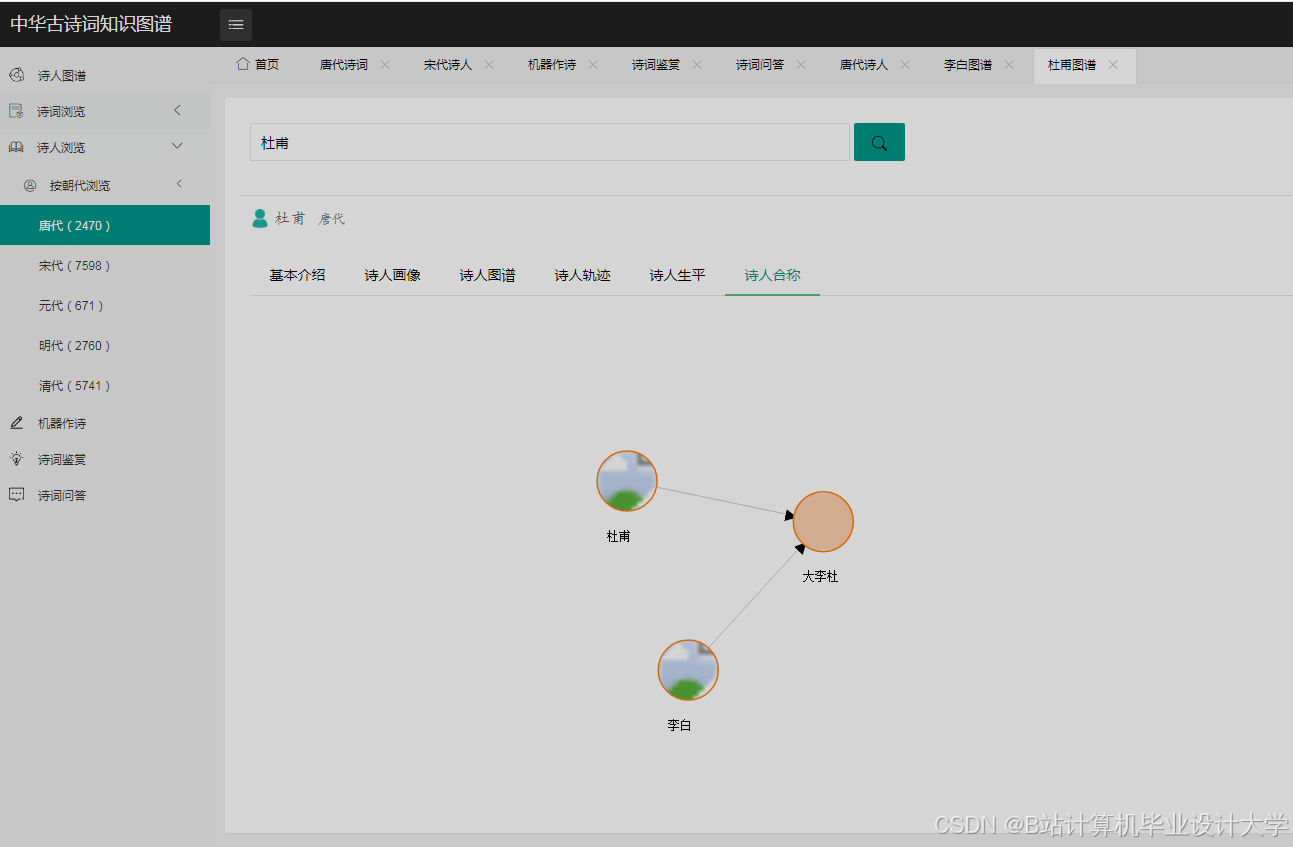
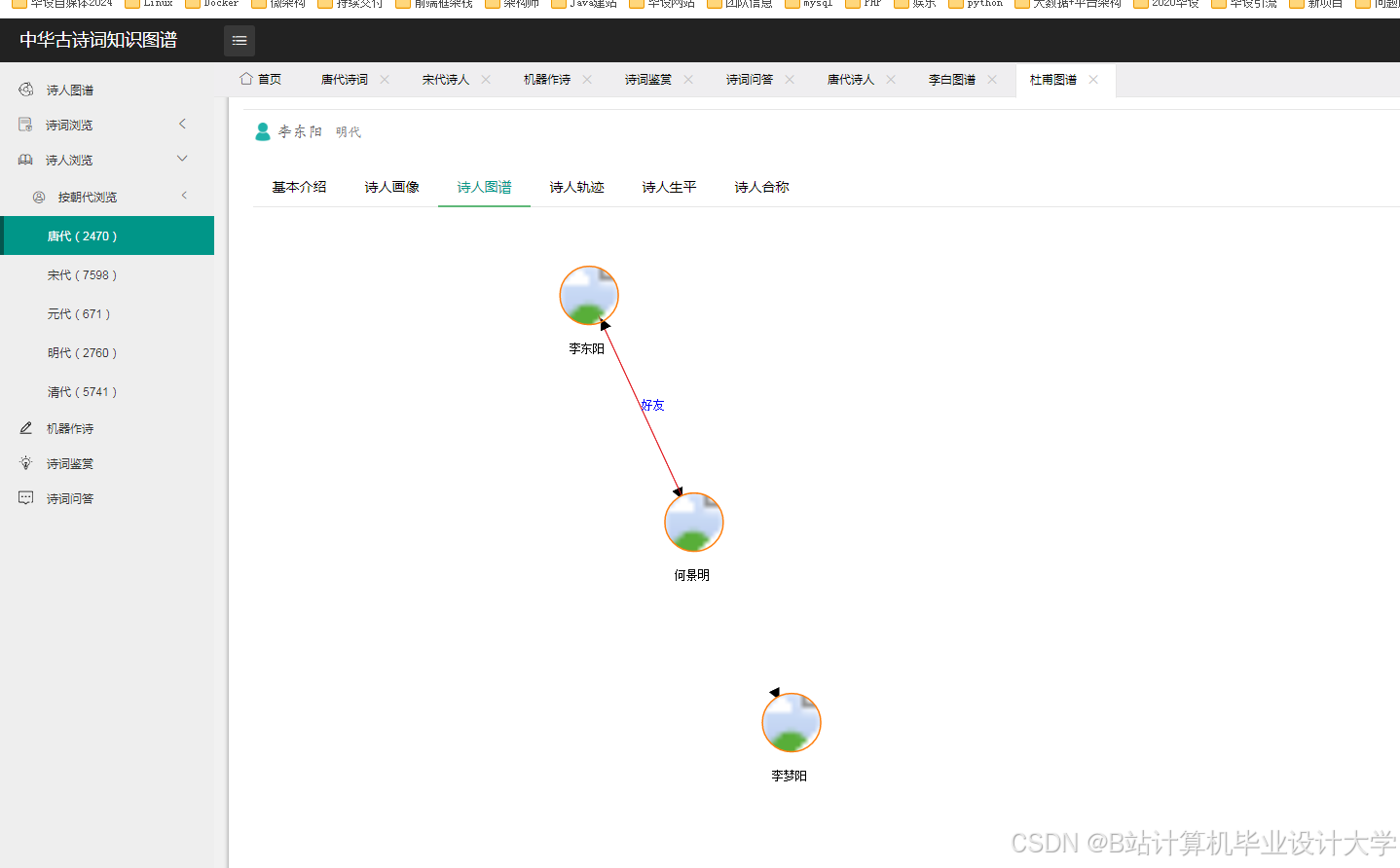
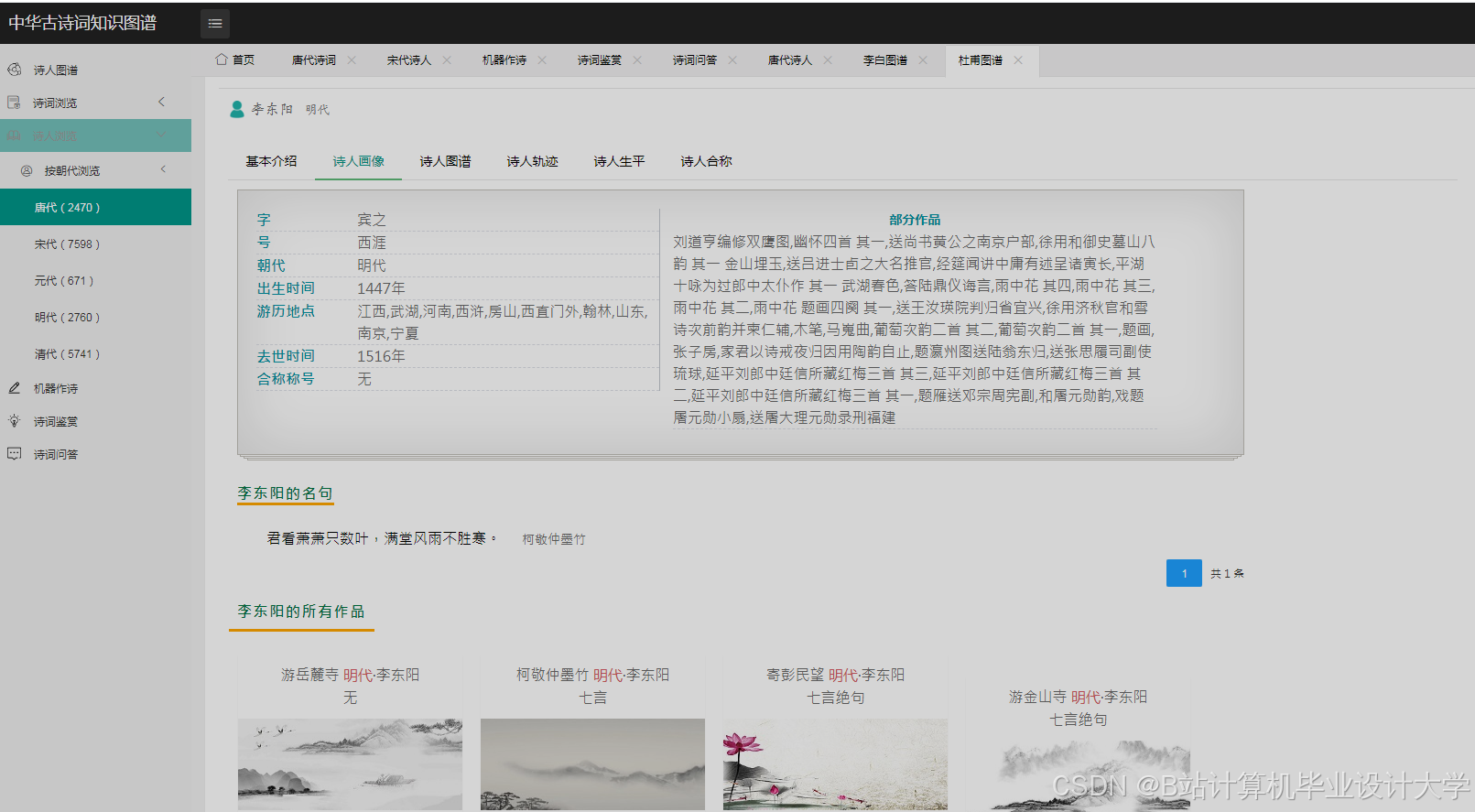
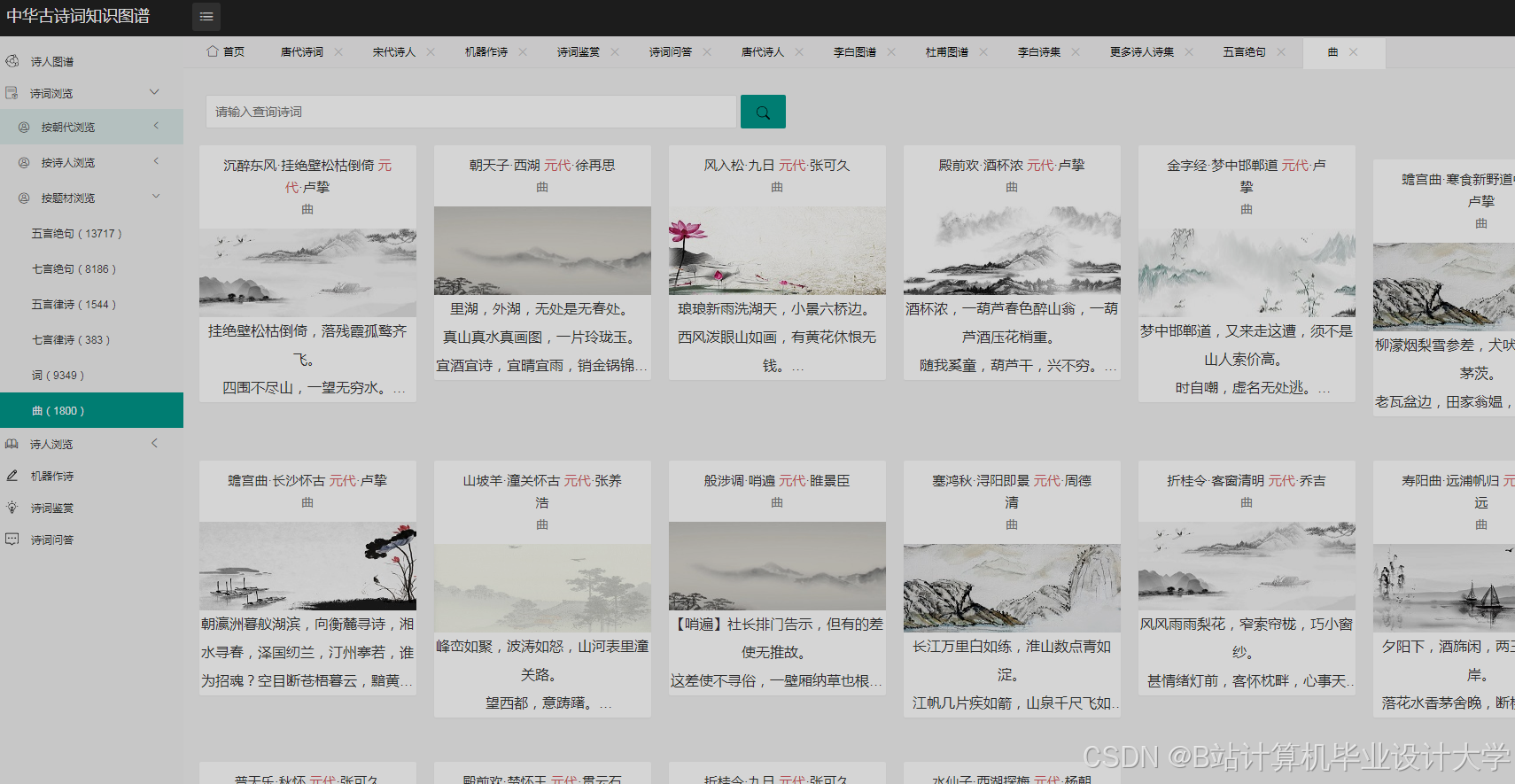
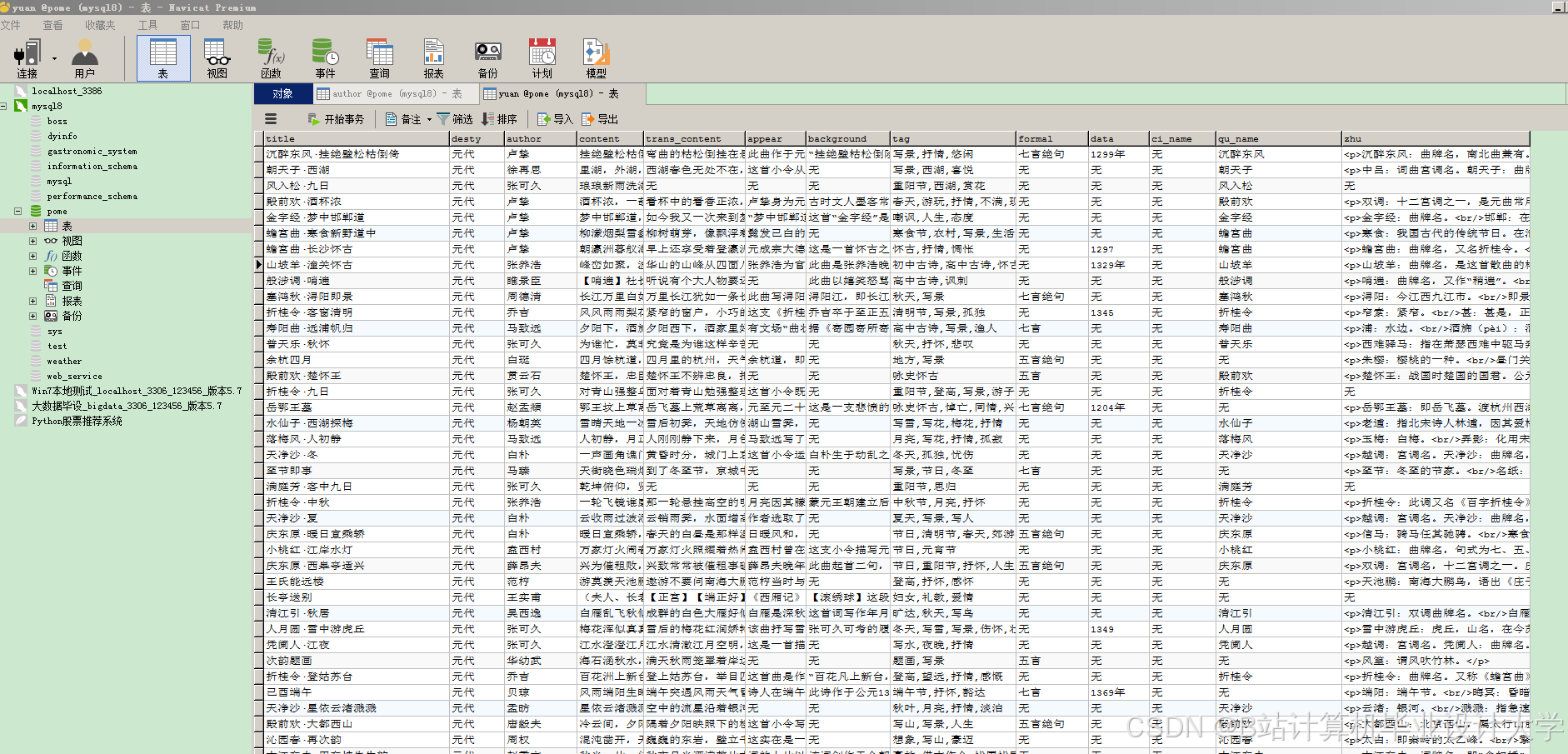
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











