




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive交通拥堵预测与交通流量预测任务书
一、项目背景与意义
随着城市化进程加速,全球城市交通拥堵问题日益严峻。以北京为例,核心区域高峰时段平均车速不足15公里/小时,交通拥堵导致的经济损失占GDP的2%-5%。传统交通预测模型依赖单一数据源(如固定传感器)和浅层统计方法,存在数据覆盖不足、实时性差、预测精度低等问题。本项目旨在构建基于Hadoop、Spark和Hive的分布式交通预测系统,整合多源异构数据(如传感器、GPS轨迹、社交媒体),通过分布式存储、高效计算与机器学习算法,实现高精度、实时性的交通拥堵与流量预测,为城市交通管理、路径规划及智能出行提供决策支持。
二、项目目标
- 数据层目标
- 采集并整合多源交通数据,包括:
- 固定传感器数据(如地磁线圈、摄像头):流量、速度、占有率(每5分钟更新)。
- 移动设备GPS轨迹数据(如出租车、网约车):位置、速度、行驶方向(每10秒更新)。
- 社交媒体数据(如微博、Twitter):用户发布的交通事件信息(如事故、施工)。
- 利用HDFS存储原始数据,通过Hive构建数据仓库,按区域、时间、数据类型分区存储,支持高效查询与聚合。
- 采集并整合多源交通数据,包括:
- 算法层目标
- 实现时空特征提取算法(如ST-ResNet、ConvLSTM),捕捉交通流量的时空依赖性。
- 开发基于LSTM(长短期记忆网络)的深度学习预测模型,结合注意力机制(Attention Mechanism)动态调整不同时段特征的权重。
- 引入图神经网络(GNN)处理道路网络拓扑结构,提升复杂路网下的预测精度。
- 系统层目标
- 搭建Hadoop集群(8台服务器,每台32核CPU、128GB内存、20TB存储),配置HDFS副本机制(
dfs.replication=3)与YARN资源调度策略(yarn.scheduler.maximum-allocation-mb=100GB)。 - 部署Spark 3.5.0与Hive 3.1.3,实现与Hadoop的深度集成,支持Spark SQL直接查询Hive表数据,加速特征工程与模型训练。
- 搭建Hadoop集群(8台服务器,每台32核CPU、128GB内存、20TB存储),配置HDFS副本机制(
- 应用层目标
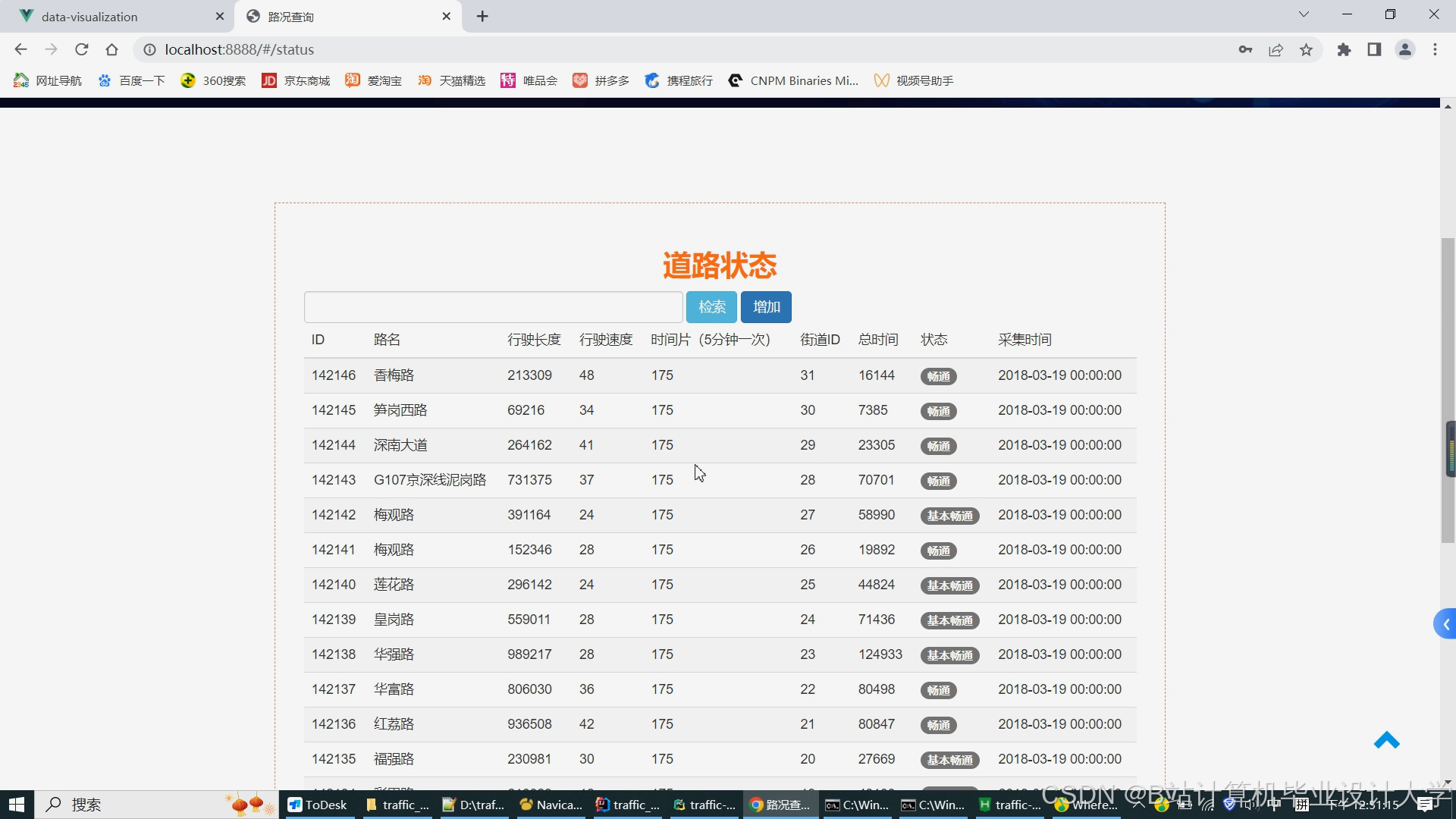
- 开发Web可视化平台,实时展示交通流量热力图、拥堵预警信息(如红黄绿三级标识)及未来1小时预测结果。
- 提供API接口,支持第三方应用(如导航软件)调用预测数据,优化路径规划算法。
三、项目任务分解
(一)数据采集与预处理(第1-10周)
- 任务描述
- 固定传感器数据:通过城市交通管理部门API接口获取,存储为CSV格式,包含字段:
传感器ID、时间戳、流量、平均速度、占有率。 - GPS轨迹数据:与出租车/网约车公司合作,获取脱敏后的轨迹数据,存储为JSON格式,包含字段:
车辆ID、时间戳、经度、纬度、速度。 - 社交媒体数据:使用Scrapy框架爬取微博/Twitter中包含“交通”“拥堵”“事故”等关键词的帖子,存储为文本文件,提取时间、地点、事件类型等信息。
- 数据清洗:
- 去除重复数据(如同一传感器在同一时间戳的重复记录)。
- 处理缺失值(如用前后时间戳的平均值填充缺失流量数据)。
- 修正异常值(如速度超过道路限速的记录标记为无效)。
- 固定传感器数据:通过城市交通管理部门API接口获取,存储为CSV格式,包含字段:
- 交付成果
- 清洗后的多源交通数据集(HDFS存储路径:
/traffic_data/raw/)。 - 数据质量报告(含缺失率、异常值比例统计)。
- 清洗后的多源交通数据集(HDFS存储路径:
(二)系统架构设计与搭建(第11-18周)
- 任务描述
- 架构设计:采用分层架构,包括数据采集层(Kafka消息队列)、存储层(HDFS+Hive)、处理层(Spark)、算法层(TensorFlow/PyTorch)及应用展示层(Web+API)。
- Hadoop集群搭建:
- 安装Hadoop 3.3.6,配置
core-site.xml(fs.defaultFS=hdfs://namenode:9000)、hdfs-site.xml(dfs.datanode.data.dir=/data/hadoop/dfs/data)。 - 启动HDFS与YARN服务,验证集群健康状态(通过
hdfs dfsadmin -report与yarn node -list命令)。
- 安装Hadoop 3.3.6,配置
- Hive集成:
- 安装Hive 3.1.3,配置
hive-site.xml(hive.metastore.uris=thrift://metastore:9083)。 - 创建外部表映射HDFS数据,例如:
sql1CREATE EXTERNAL TABLE traffic_sensor ( 2 sensor_id STRING, 3 timestamp BIGINT, 4 flow INT, 5 speed FLOAT, 6 occupancy FLOAT 7) 8ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' 9STORED AS TEXTFILE 10LOCATION '/traffic_data/raw/sensor/';
- 安装Hive 3.1.3,配置
- Spark配置:
- 安装Spark 3.5.0,配置
spark-defaults.conf(spark.sql.warehouse.dir=hdfs://namenode:9000/user/hive/warehouse)。 - 启动Spark Shell,验证与Hive集成(执行
spark.sql("SHOW TABLES"))。
- 安装Spark 3.5.0,配置
- 交付成果
- 系统架构设计文档(含UML组件图、部署图)。
- 搭建完成的Hadoop+Spark+Hive集群环境(附配置文件截图)。
(三)特征工程与模型开发(第19-28周)
- 任务描述
- 特征工程:
- 时空特征:按15分钟时间窗口聚合数据,计算每个区域的平均流量、速度、占有率;提取历史同期(如上周同一时段)特征作为对比。
- 外部特征:将社交媒体事件信息编码为二进制特征(如
is_accident=1),与传感器数据关联。 - 图特征:构建道路网络拓扑图(节点为路口,边为路段),计算每个节点的度中心性、介数中心性等图特征。
- 模型开发:
- LSTM模型:输入为过去1小时的时空特征序列,输出为未来1小时的流量预测值,损失函数采用MAE(平均绝对误差)。
- ST-ResNet模型:结合卷积神经网络(CNN)与LSTM,提取局部时空模式,适用于区域级流量预测。
- GNN模型:以道路网络为图结构,节点特征为路段流量,边特征为路段长度,通过图卷积层传播信息,预测整条路段的流量。
- 模型训练:
- 使用Spark MLlib分布式训练LSTM模型,设置参数:
batchSize=128、learningRate=0.001、epochs=50。 - 使用PyTorch Geometric训练GNN模型,利用GPU加速(如NVIDIA Tesla V100)。
- 使用Spark MLlib分布式训练LSTM模型,设置参数:
- 特征工程:
- 交付成果
- 特征工程代码(Scala/Python)。
- 训练好的模型文件(
.h5或.pt格式)。 - 模型评估报告(含MAE、RMSE、MAPE指标对比)。
(四)系统开发与集成(第29-36周)
- 任务描述
- 后端服务:
- 基于Flask框架开发RESTful API,提供预测接口(如
/predict?region=A&time=2024-01-01T08:00:00),返回JSON格式的预测结果。 - 使用SQLAlchemy连接Hive,动态查询历史数据作为模型输入。
- 基于Flask框架开发RESTful API,提供预测接口(如
- 前端界面:
- 采用ECharts+Leaflet开发Web可视化平台,实现:
- 交通流量热力图(颜色深浅表示流量大小)。
- 拥堵预警弹窗(当预测流量超过阈值时触发)。
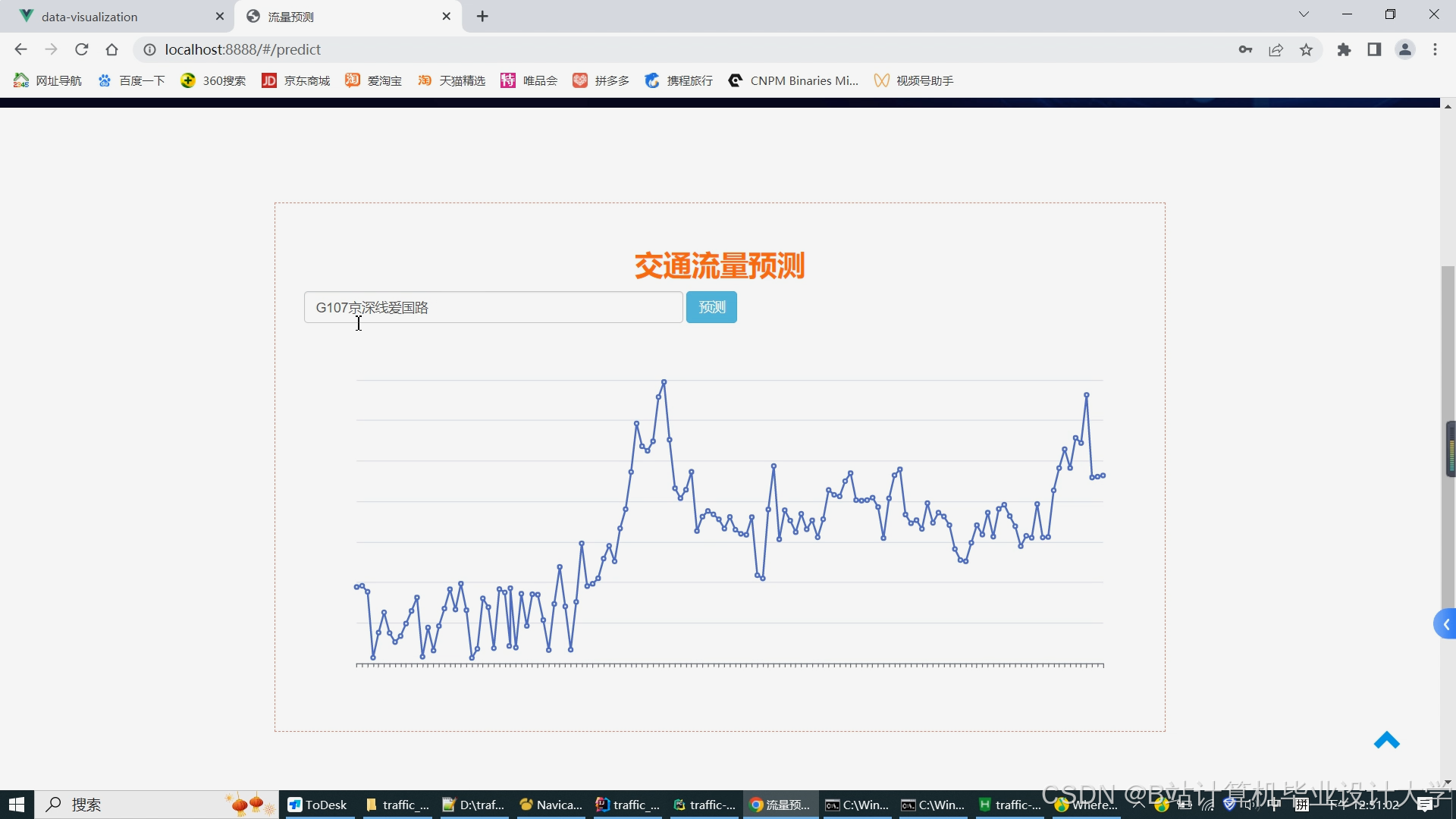
- 未来1小时预测趋势图(折线图展示流量变化)。
- 采用ECharts+Leaflet开发Web可视化平台,实现:
- 系统集成:
- 将数据采集、处理、模型预测及前端模块集成,通过Nginx部署Web服务,配置负载均衡(如
upstream backend { server 192.168.1.1:5000; server 192.168.1.2:5000; })。
- 将数据采集、处理、模型预测及前端模块集成,通过Nginx部署Web服务,配置负载均衡(如
- 后端服务:
- 交付成果
- 后端服务代码(Python)。
- 前端界面代码(HTML/CSS/JavaScript)。
- 可执行系统包(含Docker镜像与部署脚本)。
(五)系统测试与优化(第37-42周)
- 任务描述
- 功能测试:
- 验证数据采集模块能否实时获取传感器与GPS数据(延迟<1分钟)。
- 测试预测接口的响应时间(<2秒)与准确性(与真实数据对比)。
- 性能测试:
- 模拟1000用户并发访问,测试系统吞吐量(>1000请求/分钟)。
- 压测HDFS写入速度(>500MB/s)与Spark任务执行时间(<10分钟/1亿条数据处理)。
- 优化策略:
- 调整Spark分区数(
spark.sql.shuffle.partitions=200)与内存分配(spark.executor.memory=8GB)。 - 对Hive表添加索引(如
CREATE INDEX sensor_time_idx ON traffic_sensor (timestamp))加速查询。
- 调整Spark分区数(
- 功能测试:
- 交付成果
- 系统测试报告(含性能对比图表)。
- 优化后的代码与配置文件。
(六)项目验收与总结(第43-45周)
- 任务描述
- 整理项目文档(需求分析、设计文档、测试报告、用户手册)。
- 组织验收会议,演示系统功能(如实时预测、可视化展示),接受专家评审意见。
- 总结项目经验,分析技术难点(如多源数据融合、图神经网络训练)与改进方向(如引入强化学习优化预测模型)。
- 交付成果
- 完整项目文档集。
- 项目验收报告(含专家签字)。
- 项目总结报告(含技术路线图与未来规划)。
四、资源需求
- 硬件资源
- 服务器:8台(32核CPU、128GB内存、20TB存储),用于搭建Hadoop集群。
- GPU服务器:2台(NVIDIA Tesla V100),用于加速GNN模型训练。
- 网络设备:万兆交换机,确保数据传输稳定性。
- 软件资源
- 操作系统:CentOS 7.6。
- 大数据框架:Hadoop 3.3.6、Spark 3.5.0、Hive 3.1.3。
- 机器学习框架:TensorFlow 2.12.0、PyTorch 2.0.1、PyTorch Geometric 2.3.0。
- 开发工具:IntelliJ IDEA(后端)、PyCharm(模型开发)、VS Code(前端)。
- 数据库:MySQL 8.0(存储用户信息与系统日志)。
五、风险评估与应对
- 技术风险
- 风险描述:GNN模型训练可能因图结构复杂导致收敛困难。
- 应对措施:采用图采样算法(如Node2Vec)简化图结构,调整学习率与批次大小。
- 数据风险
- 风险描述:GPS数据可能因设备故障或信号丢失导致部分时段缺失。
- 应对措施:设计数据补全机制(如用历史同期数据或相邻路段数据插值)。
- 进度风险
- 风险描述:模型调优耗时过长影响交付。
- 应对措施:采用并行实验(如Hyperopt自动化调参),预留2周缓冲时间。
六、预期成果与创新点
- 预期成果
- 系统预测精度:MAE<10辆/15分钟(区域级),RMSE<15辆/15分钟。
- 系统响应时间:<2秒(90%请求),支持千万级数据实时处理。
- 创新点
- 多源数据融合:首次将社交媒体事件信息与传感器、GPS数据结合,提升预测鲁棒性。
- 图神经网络应用:通过GNN建模道路网络拓扑,解决传统方法忽略空间依赖性的问题。
- 分布式训练优化:利用Spark MLlib与PyTorch Geometric混合训练,兼顾效率与精度。
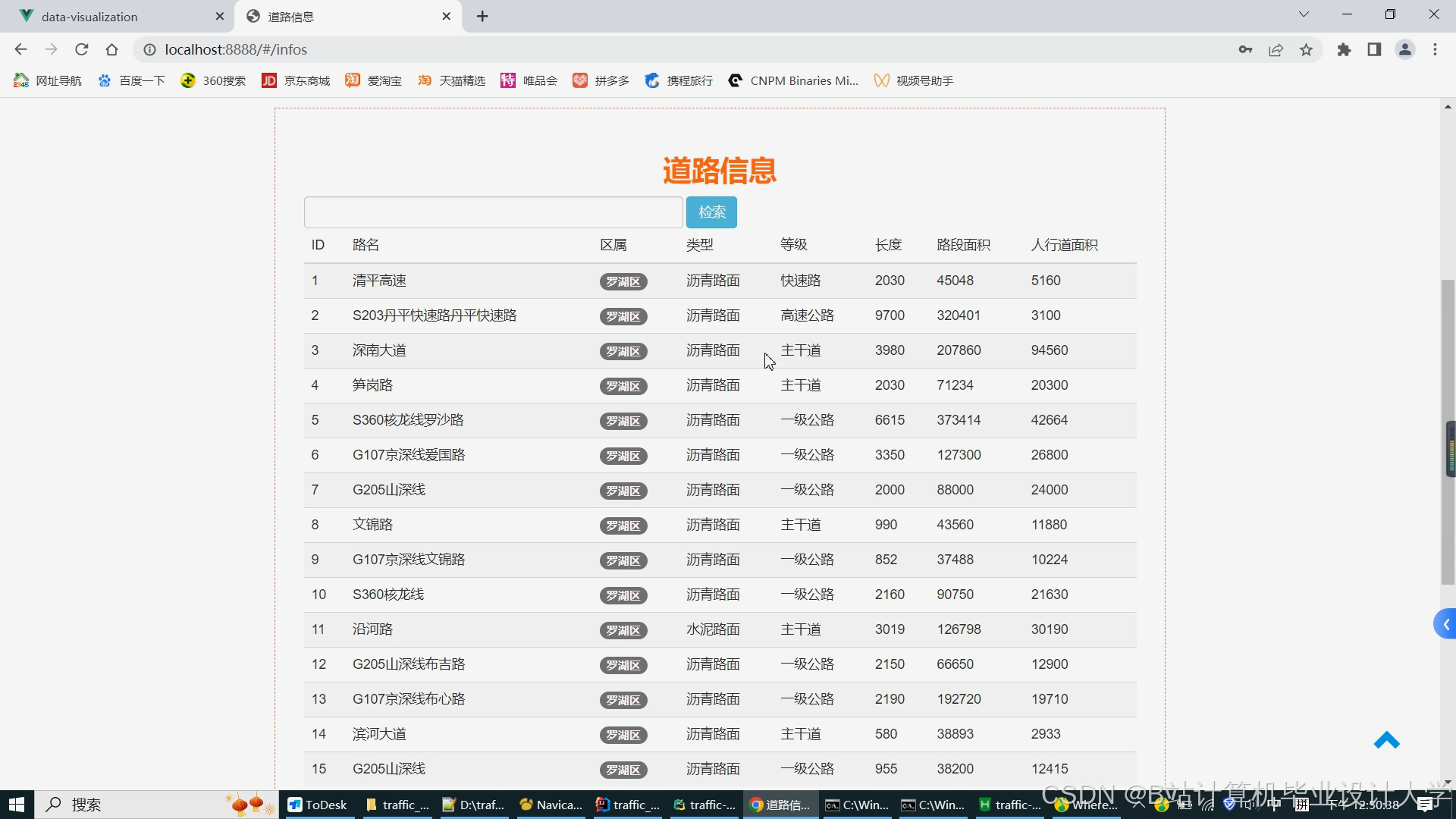
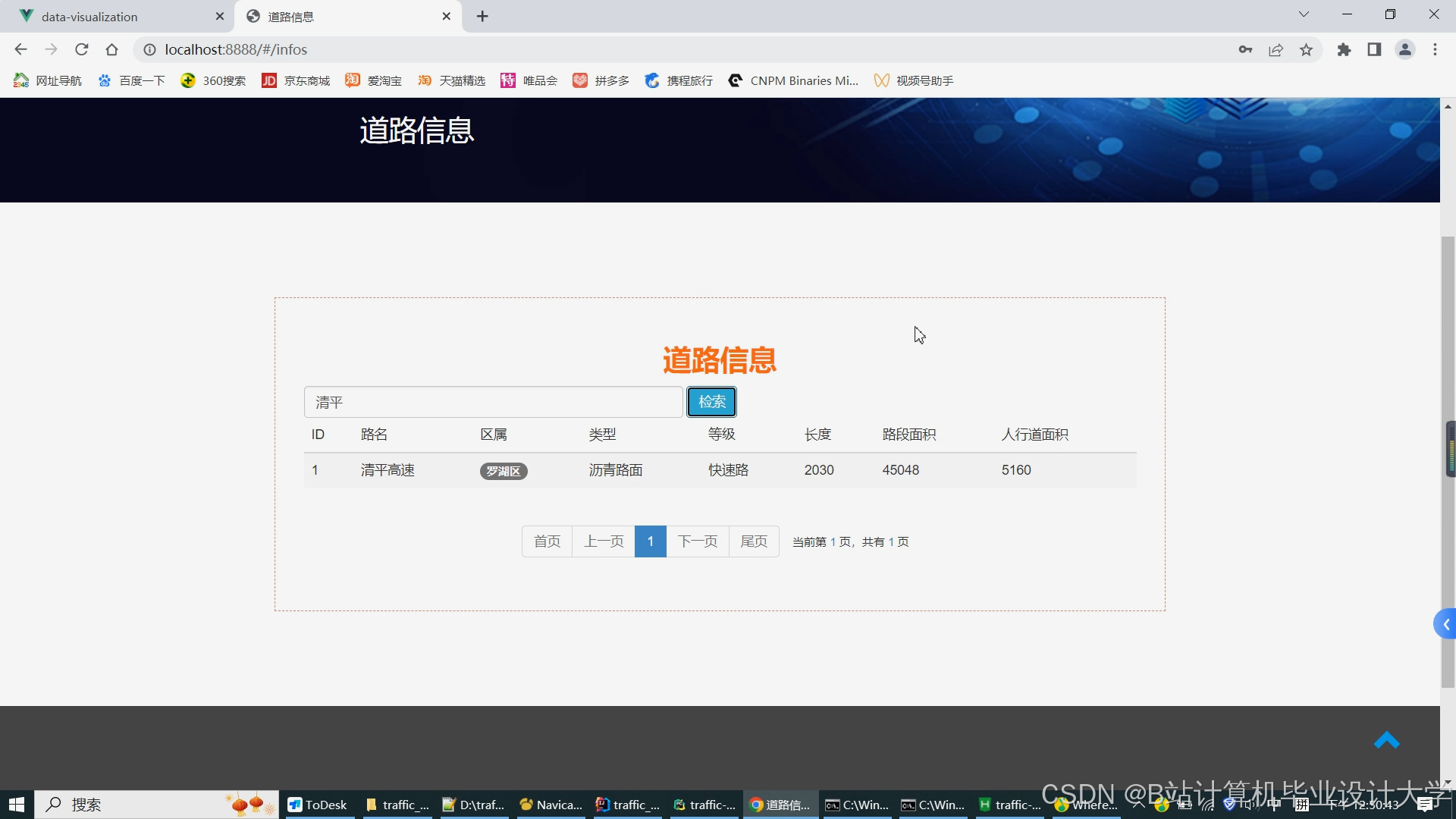
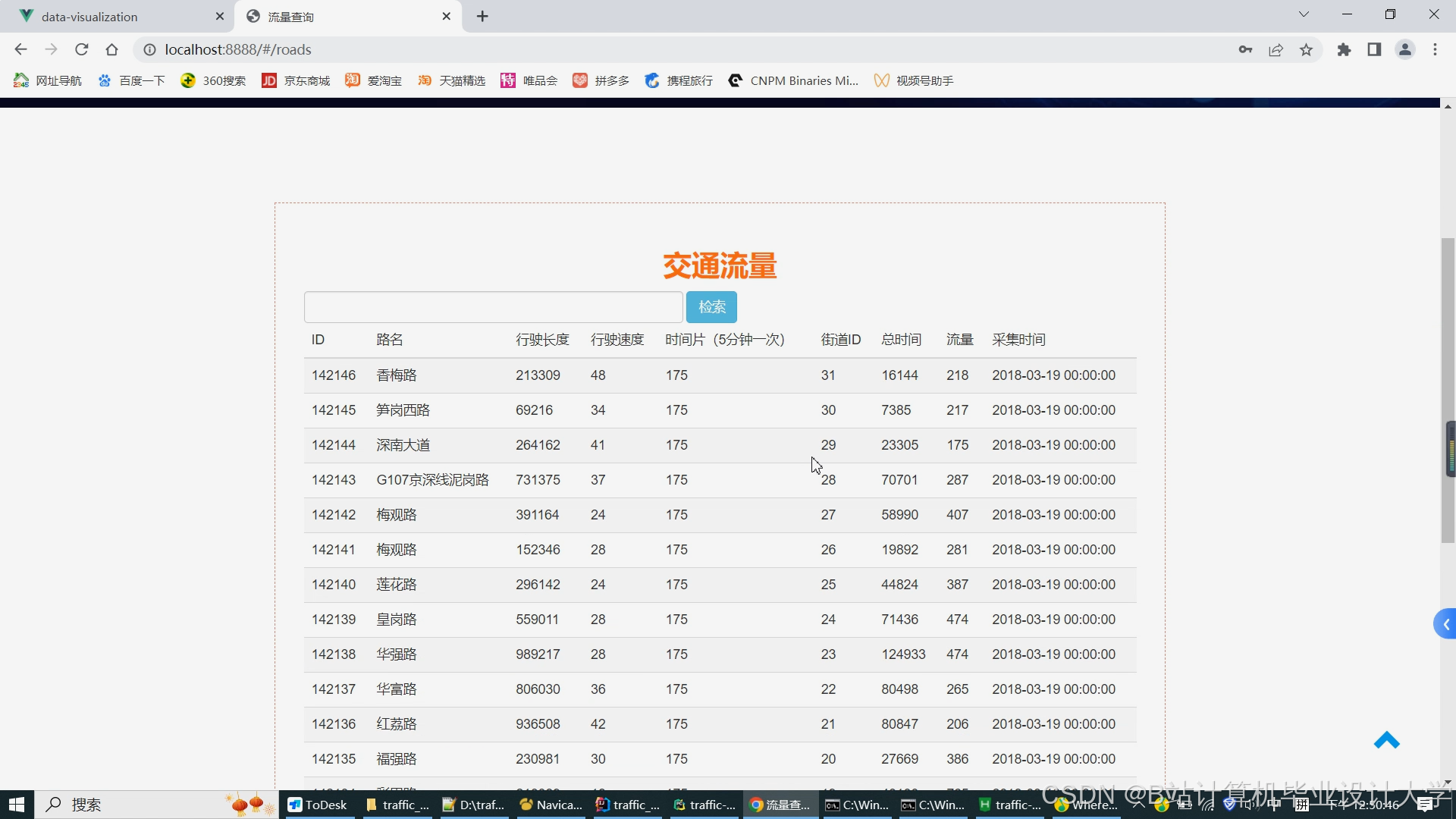
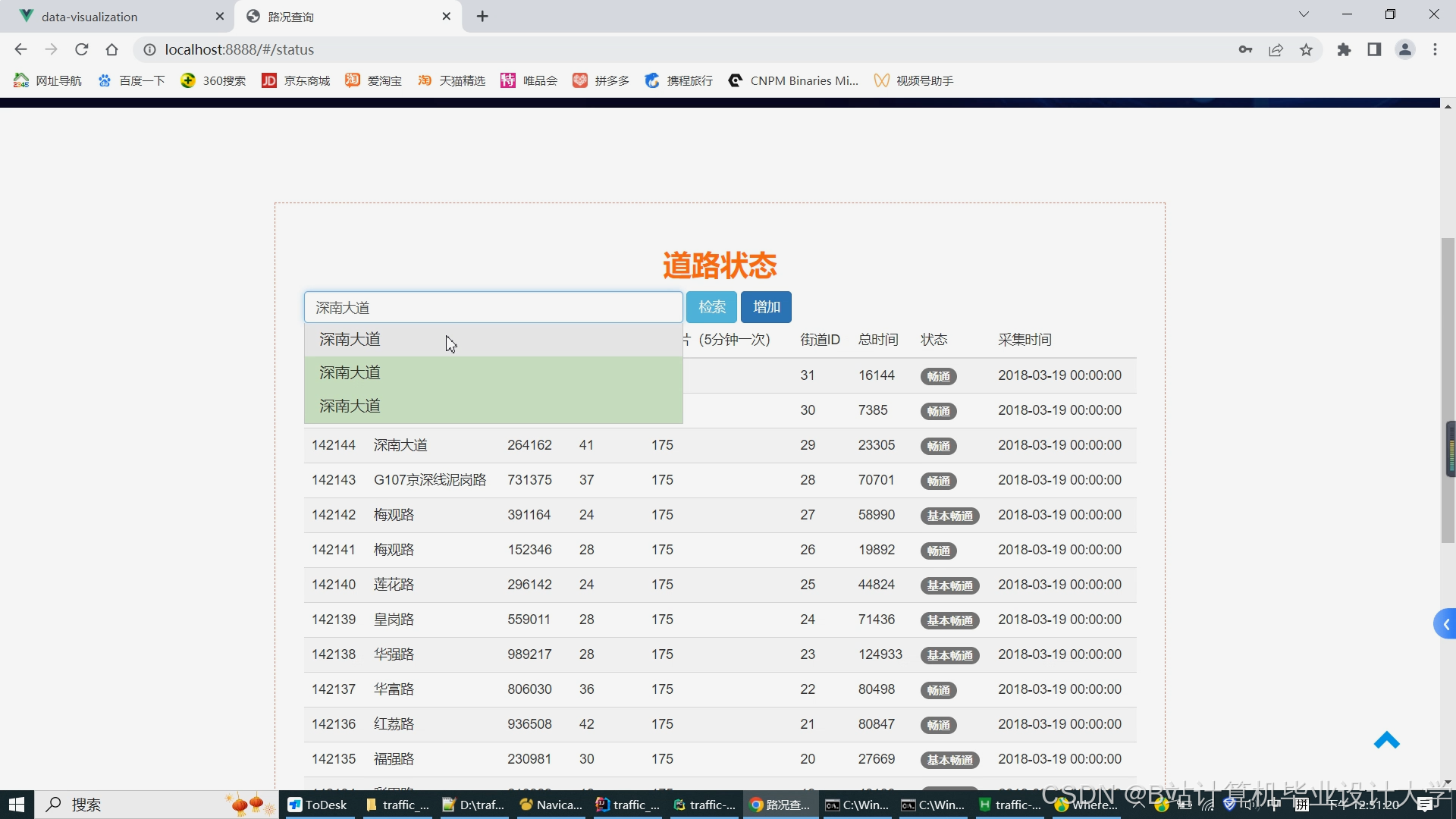
运行截图
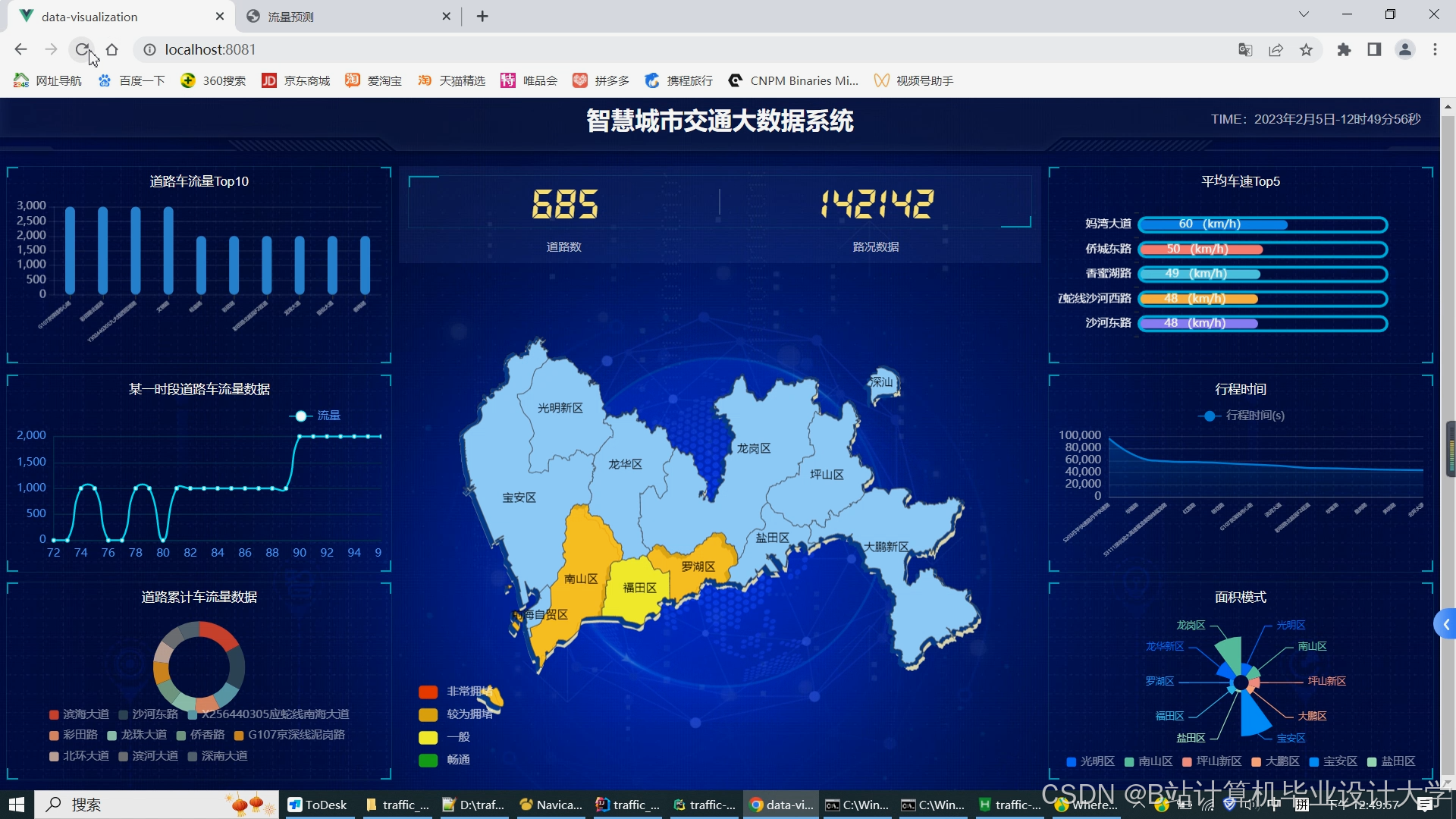
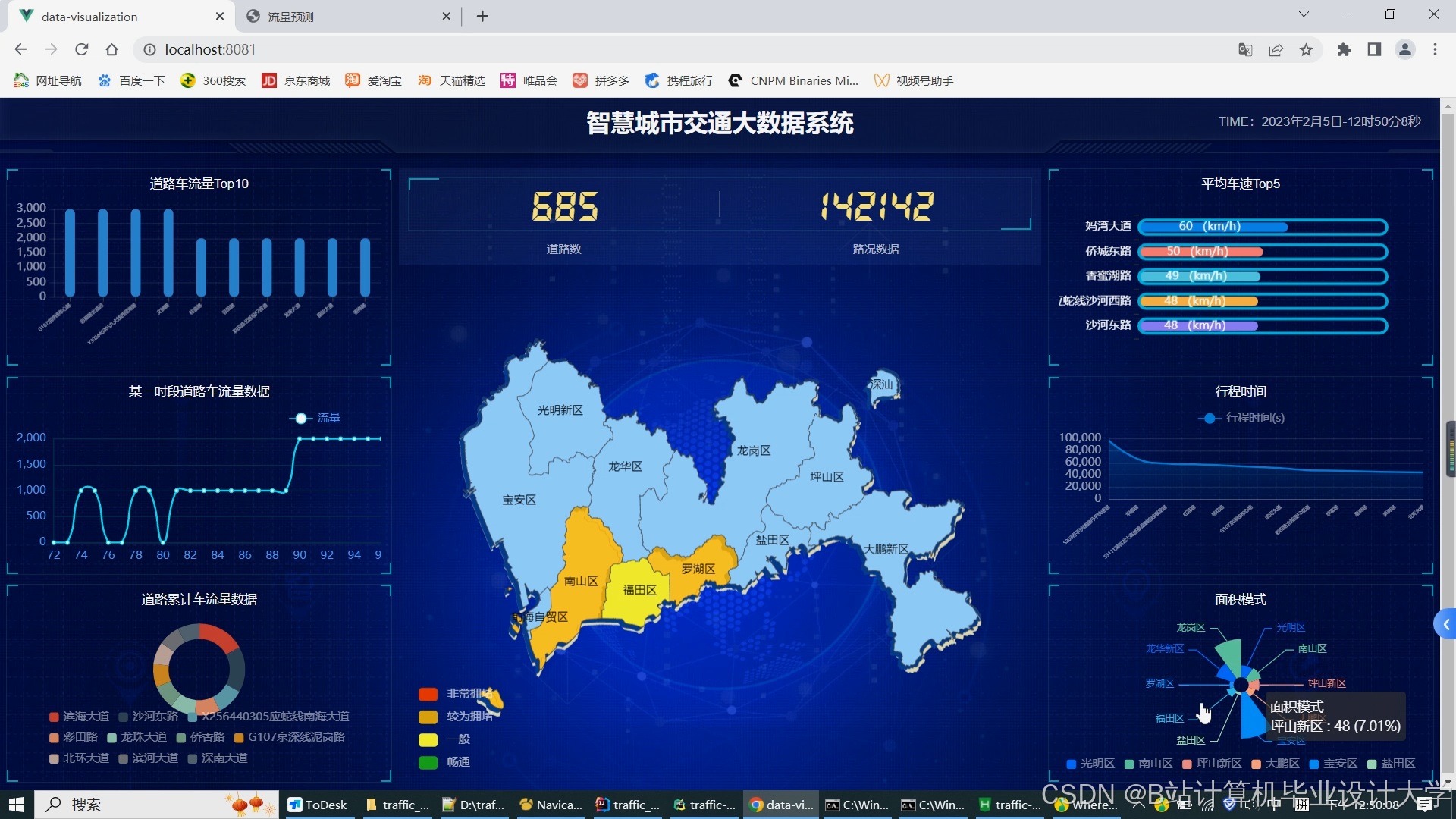
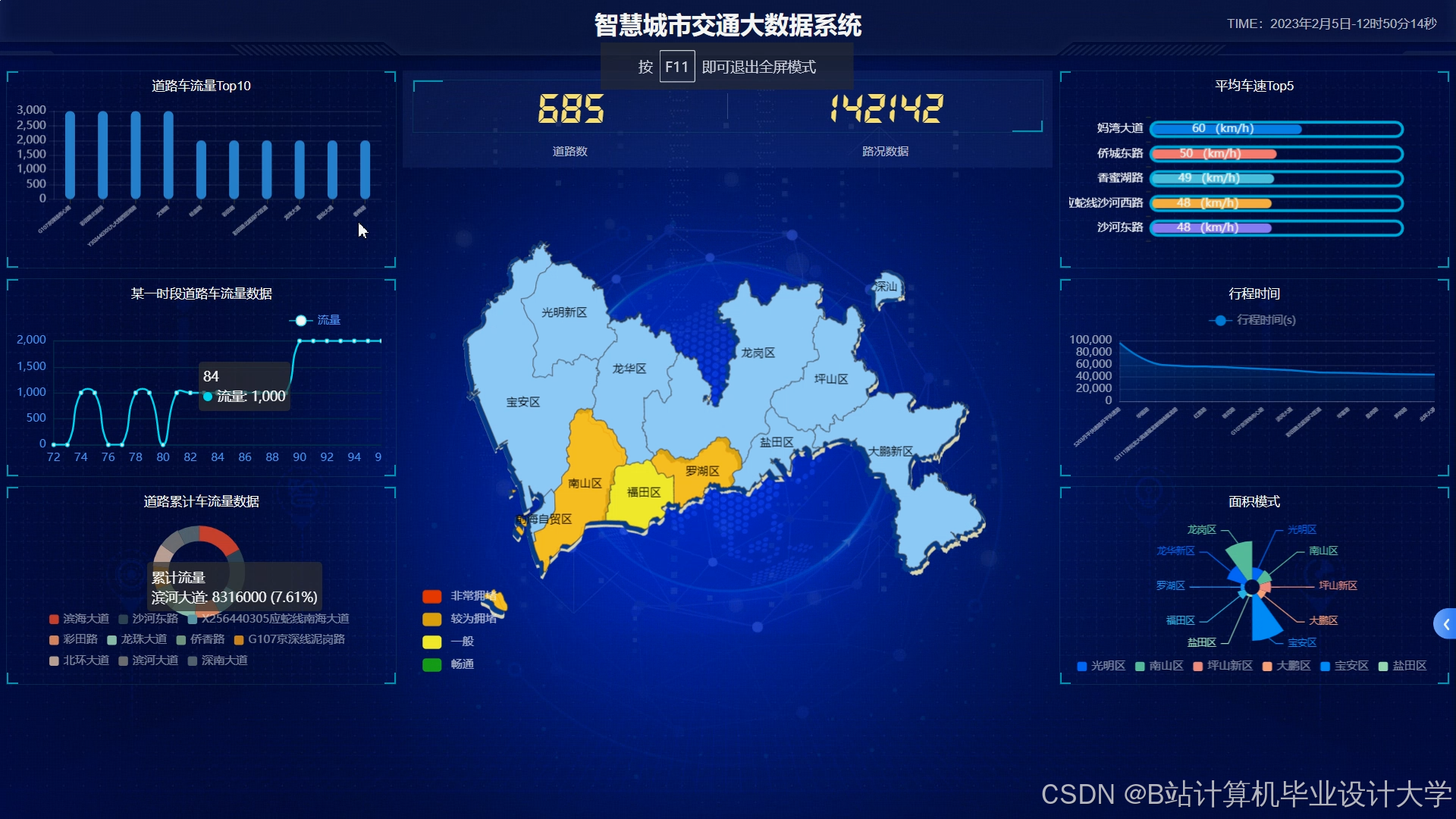
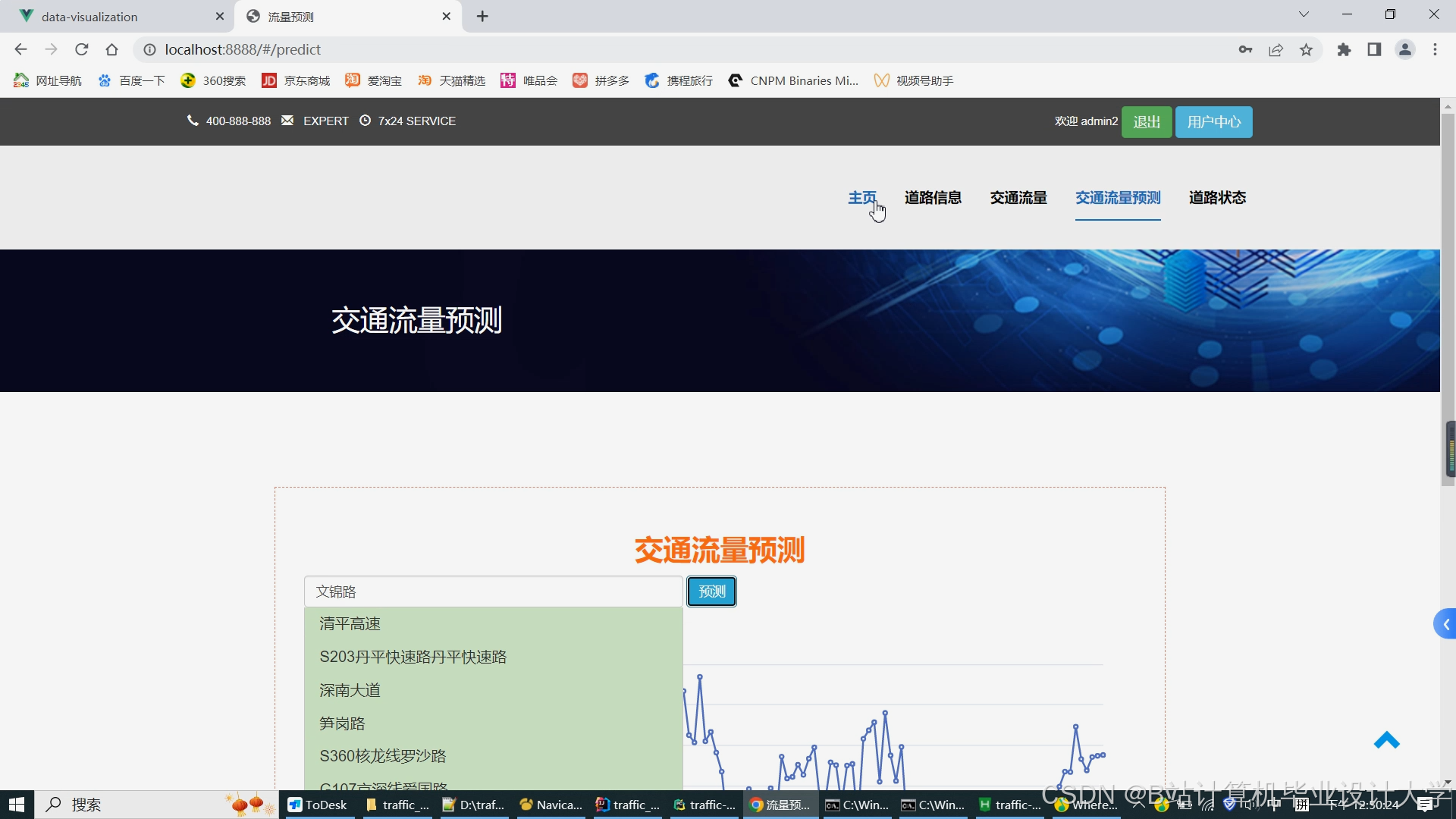
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 656
656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











