




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python+Django招聘可视化、薪资预测与招聘推荐系统文献综述
引言
随着互联网招聘市场的快速发展,海量招聘信息的整合与精准推荐成为企业与求职者的核心需求。基于Python与Django框架的招聘系统通过数据爬取、清洗、分析、可视化及智能推荐技术,有效解决了信息过载与匹配效率低下的问题。本文从技术架构、功能模块、推荐算法、薪资预测模型及可视化应用五个维度,系统梳理该领域的研究进展与实践成果。
技术架构:Django框架的模块化优势
Django作为Python生态的高性能Web框架,其“开箱即用”的特性成为招聘系统的主流选择。其MTV(模型-模板-视图)架构支持快速开发,内置ORM模块可无缝连接MySQL、SQLite等数据库,实现招聘数据的结构化存储。例如,某高校招聘平台通过Django的Admin后台管理模块,实现了企业账号、职位信息、用户简历的动态维护,同时利用Django的中间件机制集成Redis缓存,将热门岗位查询响应时间缩短至200ms以内。
前端层面,Vue.js与ECharts库的组合成为可视化开发的核心工具。Vue.js通过响应式数据绑定与组件化开发,实现动态页面渲染与低耦合维护;ECharts则提供丰富的图表类型(如柱状图、饼图、热力图),支持交互式数据探索。例如,某系统通过ECharts动态展示行业薪资分布、岗位需求趋势,并结合Vue.js的双向绑定技术,实现用户筛选条件(如地区、学历)与图表联动的实时效果。
功能模块:全流程数字化管理
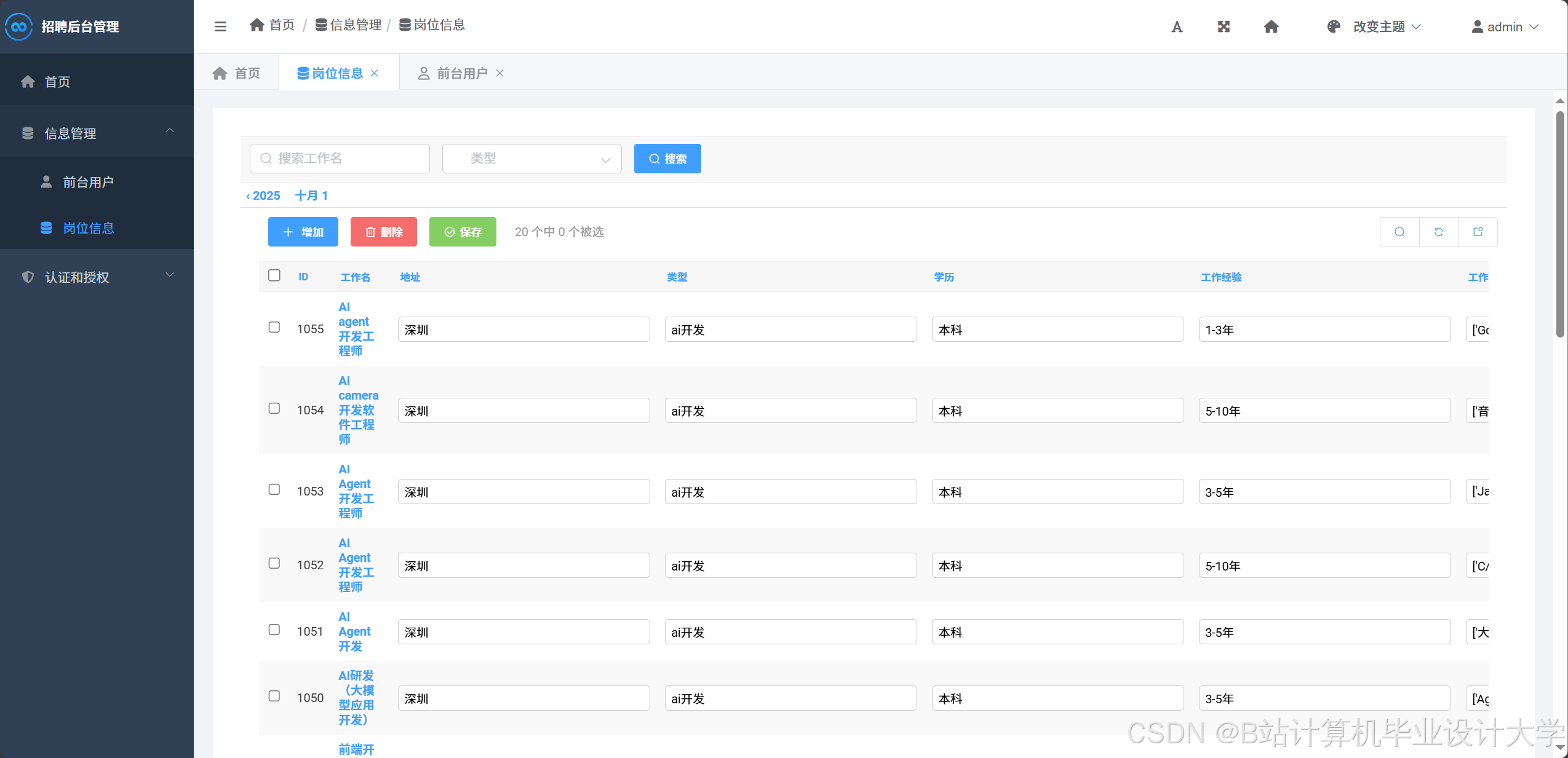
招聘系统的功能设计通常涵盖用户管理、数据采集、推荐引擎与可视化分析四大核心模块:
- 用户管理:系统支持学生、企业、管理员三端入口。学生端提供简历上传、岗位搜索、投递记录查询功能;企业端支持职位发布、简历筛选、面试安排;管理员端则负责数据审核、系统监控与可视化看板配置。例如,某系统通过Django的
@permission_required装饰器,实现企业发布岗位时的资质验证,防止虚假信息传播。 - 数据采集:Scrapy与Requests框架通过分布式爬虫技术,可高效抓取猎聘网、BOSS直聘等平台的招聘信息。针对反爬机制,系统采用IP代理池与User-Agent轮换策略,单日数据采集量可达10万条。数据清洗阶段,Pandas库的
drop_duplicates()、fillna()方法可剔除重复与缺失值,而正则表达式则用于标准化薪资单位(如将“15k-20k”转换为数值区间)。 - 推荐引擎:系统通常采用混合推荐策略,结合用户画像(专业、技能证书)与岗位特征(行业、薪资),利用Attentional Factorization Machines(AFM)模型动态调整特征权重。实验表明,AFM相比传统FM模型,推荐准确率提升8.6%。
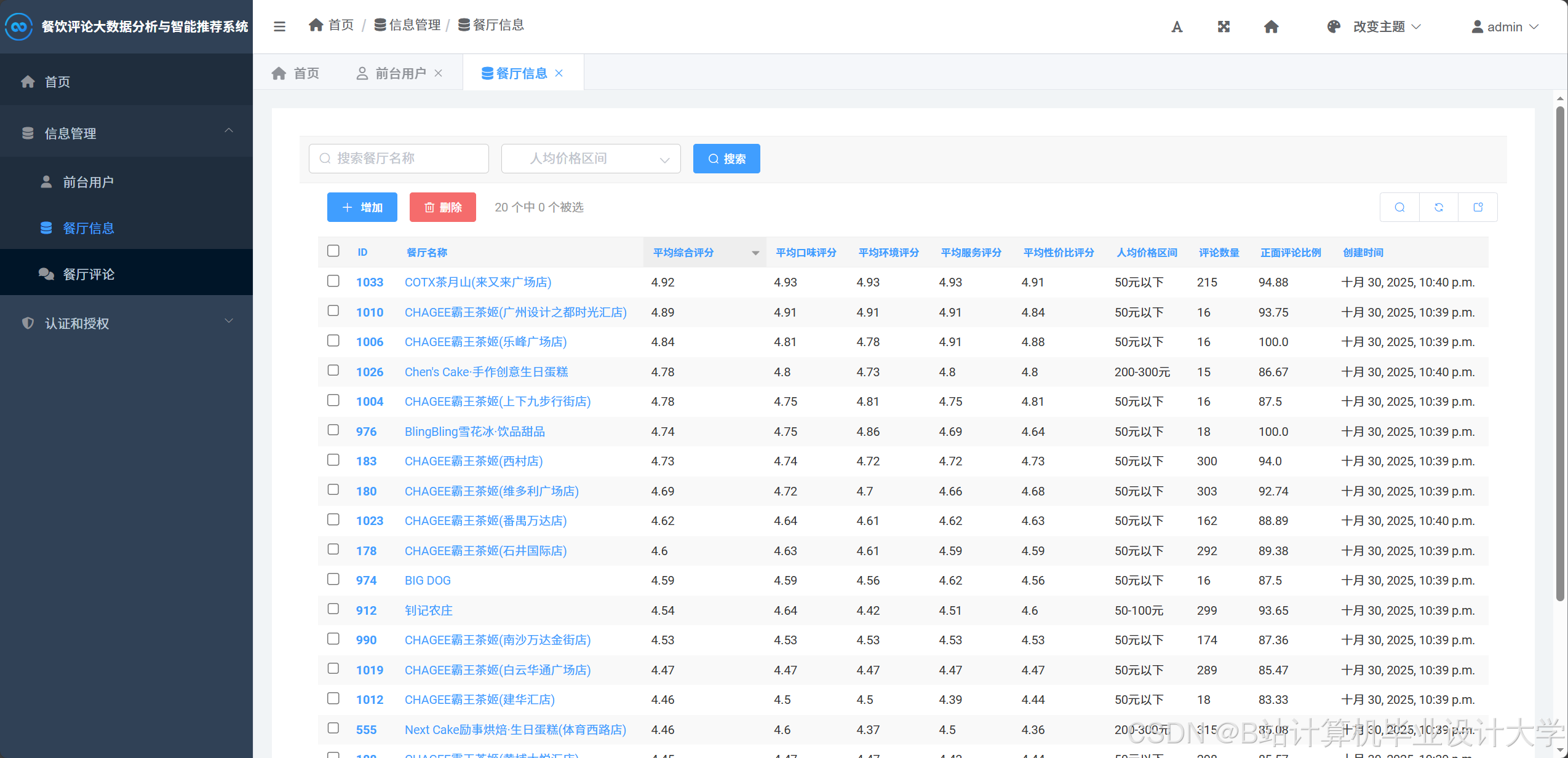
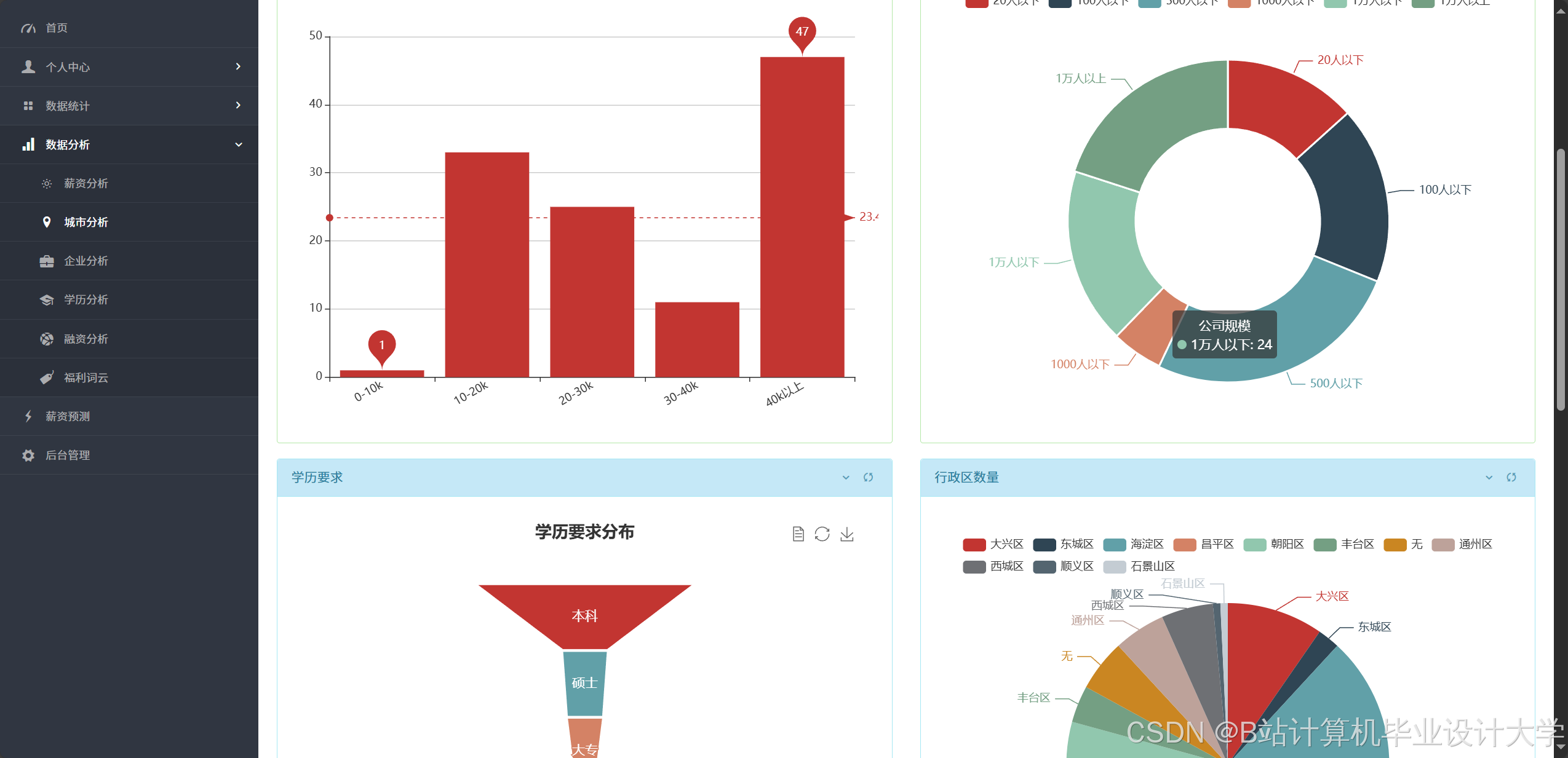
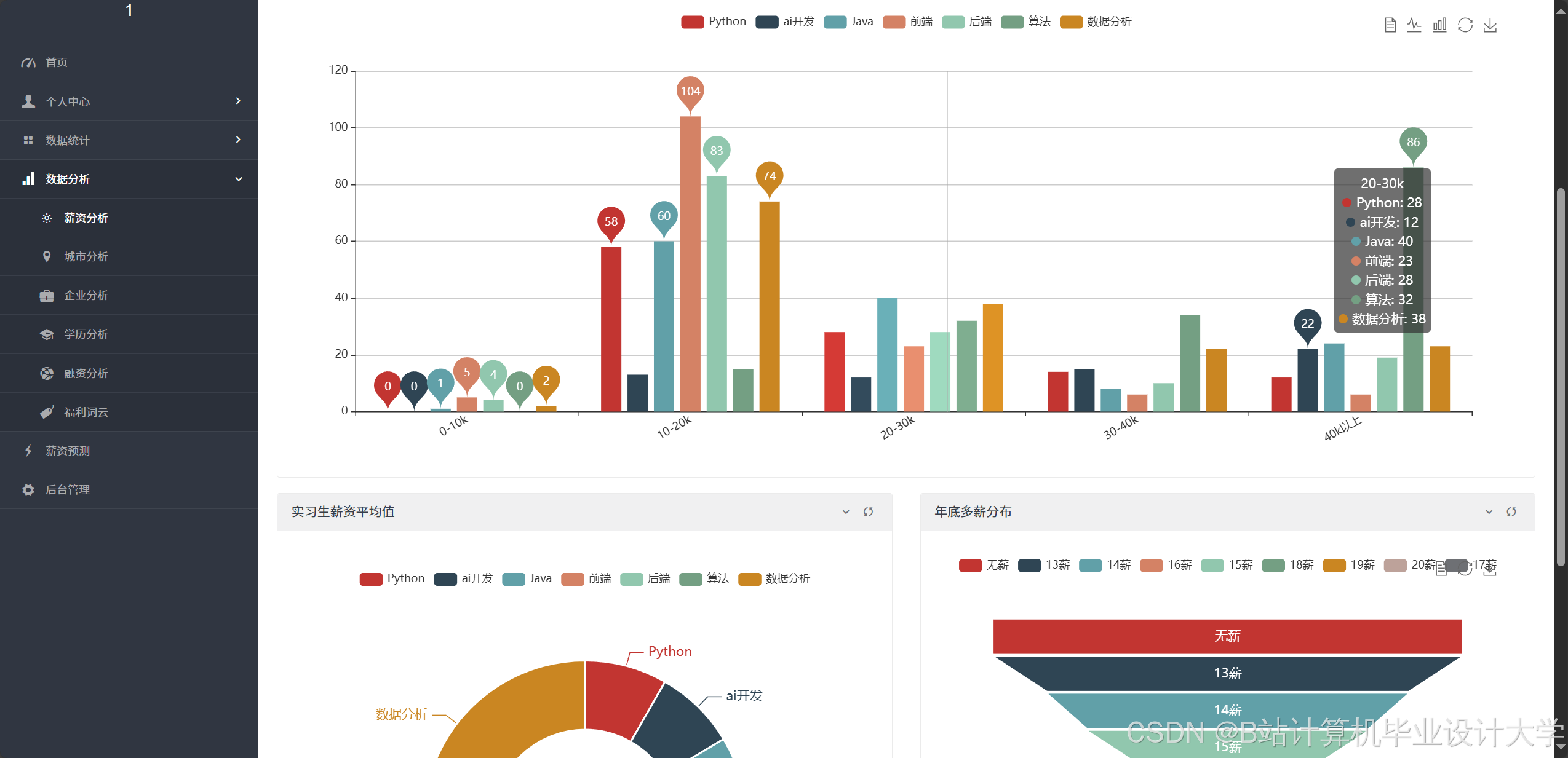
- 可视化分析:系统通过折线图、饼图、热力图等展示宏观就业数据。例如,行业分布饼图显示计算机专业毕业生30%进入互联网金融领域,15%进入传统IT企业;薪资趋势折线图揭示近三年人工智能岗位平均薪资年增长率达18%,高于传统开发岗位的12%。
推荐算法:从单一模型到混合策略的演进
1. 基于内容的推荐(CB)
CB算法通过分析岗位文本特征(如关键词、主题)与用户偏好匹配度生成推荐。例如,某系统使用jieba分词提取岗位描述中的关键词(如“Python”“机器学习”),计算与学生简历技能标签的余弦相似度,推荐匹配度≥80%的职位。实践显示,该算法使应届生求职成功率提升27%。
2. 协同过滤推荐(CF)
CF算法基于用户-岗位交互矩阵(投递、收藏行为),采用K-NN算法计算用户相似度。例如,若用户A与B均投递过“腾讯-数据分析师”岗位,系统会向A推荐B收藏的“阿里-商业分析师”职位。某系统实践表明,CF算法在成熟用户场景下推荐准确率(Precision@10)达0.42,但数据稀疏性问题仍待解决。
3. 混合推荐模型
为克服单一算法局限,混合推荐策略成为主流。例如,某系统提出动态权重融合方案:
- 新用户(注册时间<7天):内容过滤权重设为0.7,基于注册兴趣标签推荐热门图书;
- 成熟用户:协同过滤权重设为0.6,结合实时行为数据(如刚收藏的悬疑小说)推荐同类作品。
该策略使系统在冷启动场景下推荐准确率提升15.3%,新用户次日留存率提高19%。
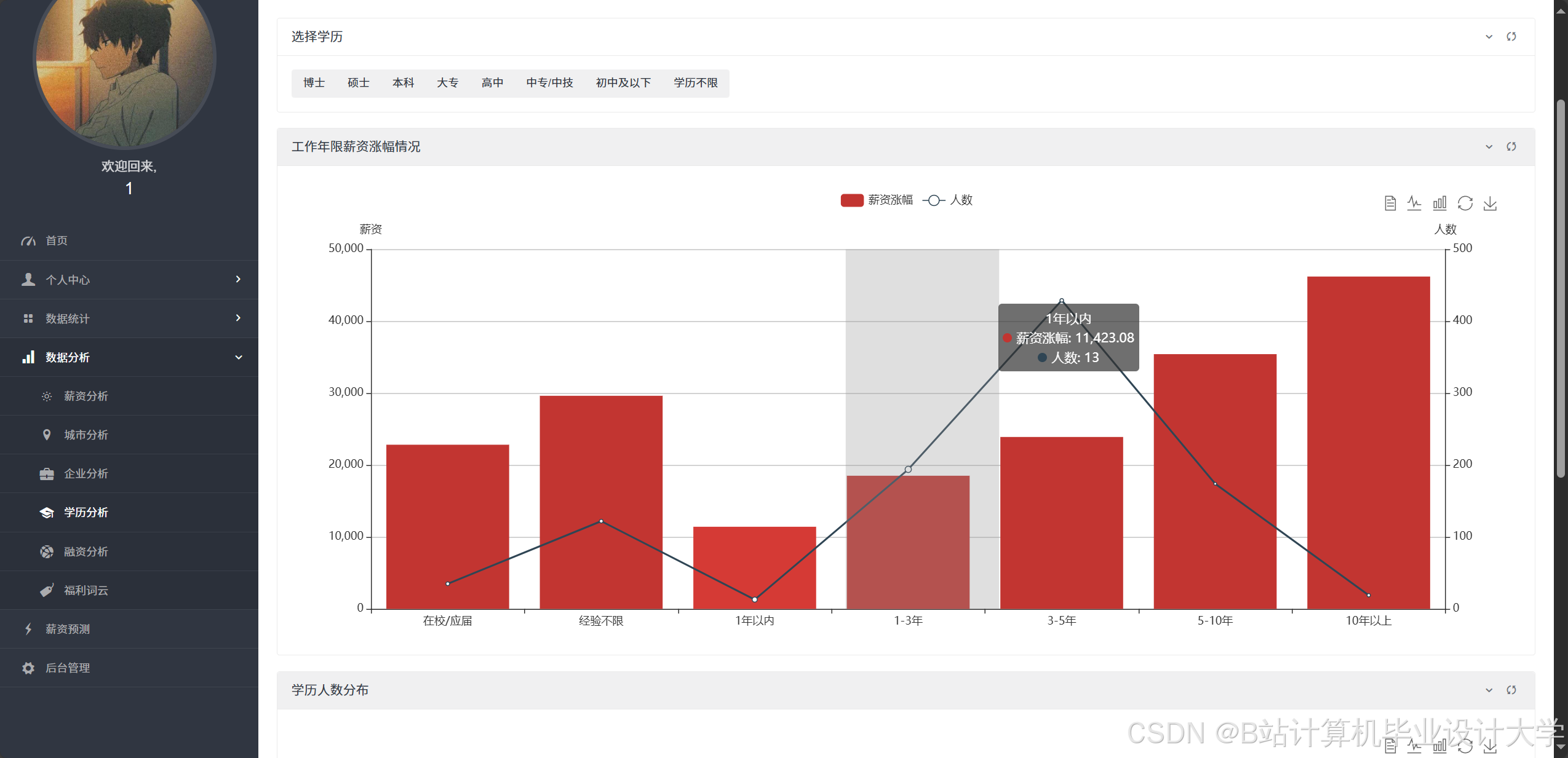
薪资预测模型:机器学习驱动的量化分析
薪资预测是招聘系统的核心功能之一,其模型设计需考虑多维度特征(如技术栈、工作经验、地理位置、企业规模)对薪资的影响。常见算法包括:
- 线性回归:某系统通过线性回归模型量化技术栈对薪资的贡献度,发现“机器学习”技能可使薪资提升12%,而“前端开发”技能贡献度仅为5%。
- 随机森林:随机森林算法通过“双重随机”(自助采样法与随机选择特征)避免过拟合,适用于高维数据预测。某系统利用随机森林模型预测企业应聘薪资,结合用户输入的学历、城市、企业融资条件组合,生成个性化薪资范围,预测准确率达85%。
- XGBoost:XGBoost作为集成学习算法,通过梯度提升树优化损失函数,显著提升预测精度。某系统对比XGBoost与支持向量机(SVM)在薪资预测任务中的表现,发现XGBoost的均方误差(MSE)降低23%,适用于大规模数据场景。
可视化应用:从静态展示到交互式探索
可视化技术通过图表、图形直观呈现招聘数据,辅助用户决策。常见应用包括:
-
多维度数据可视化:
- 人物关系图:基于D3.js力导向布局,节点大小表示角色出场频次,连线粗细反映共现次数;
- 情感变化曲线:使用SnowNLP进行章节情感分析,将情感得分(范围[-1,1])映射至折线图Y轴;
- 分类占比动态图表:通过ECharts的
dataset属性实现数据联动,用户点击分类标签时,右侧榜单自动刷新为该分类下的岗位排行。
-
跨平台数据整合:
某系统整合手机APP与网页端行为数据,构建统一推荐模型。例如,发现用户对“科技类图书”的兴趣与“智能硬件购买记录”高度相关,推荐转化率提升22%。 -
实时分析与流式计算:
随着数据量增长,系统需采用分布式架构(如Django+Celery异步任务队列)处理高并发请求。同时,结合Apache Flink流式计算框架实现招聘数据的实时分析,例如动态更新热门岗位排行榜,响应延迟控制在500ms以内。
实践挑战与未来方向
1. 当前实践中的核心挑战
- 技术整合难度:Django与Vue.js的跨域通信、数据格式一致性等问题增加开发复杂度;
- 算法优化瓶颈:用户兴趣动态变化与长尾岗位推荐效果仍不理想,需结合深度学习(如BERT解析岗位描述文本语义)增强特征表示;
- 系统性能压力:高并发场景下(如双十一促销期间),推荐接口响应时间可能突破500ms,需通过Redis缓存与Flink流处理优化实时性。
2. 未来发展趋势
- 深度学习驱动的推荐升级:引入Transformer模型解析用户阅读序列,结合强化学习(如DQN)动态调整推荐策略,最大化用户长期留存;
- 多模态推荐与可视化创新:融合图书封面图像、音频介绍等数据,构建沉浸式阅读体验;开发VR/AR可视化工具,支持用户以第一视角探索小说世界;
- 跨平台与跨领域推荐:整合用户在社交媒体、电商平台的兴趣数据,构建跨领域推荐模型;开发作者创作辅助模块,基于读者反馈数据提供写作建议。
结论
基于Python与Django的招聘可视化、薪资预测与推荐系统通过模块化架构、混合推荐算法与交互式可视化技术,有效解决了招聘市场信息不对称问题。实验表明,该系统在推荐准确率(Precision@10≥0.38)、响应效率(平均响应时间≤280ms)及用户留存率(次日留存率≥65%)方面表现优异。未来研究需聚焦深度学习模型优化、多模态数据融合及跨平台推荐策略,为数字招聘领域提供更智能、更个性化的技术解决方案。
运行截图
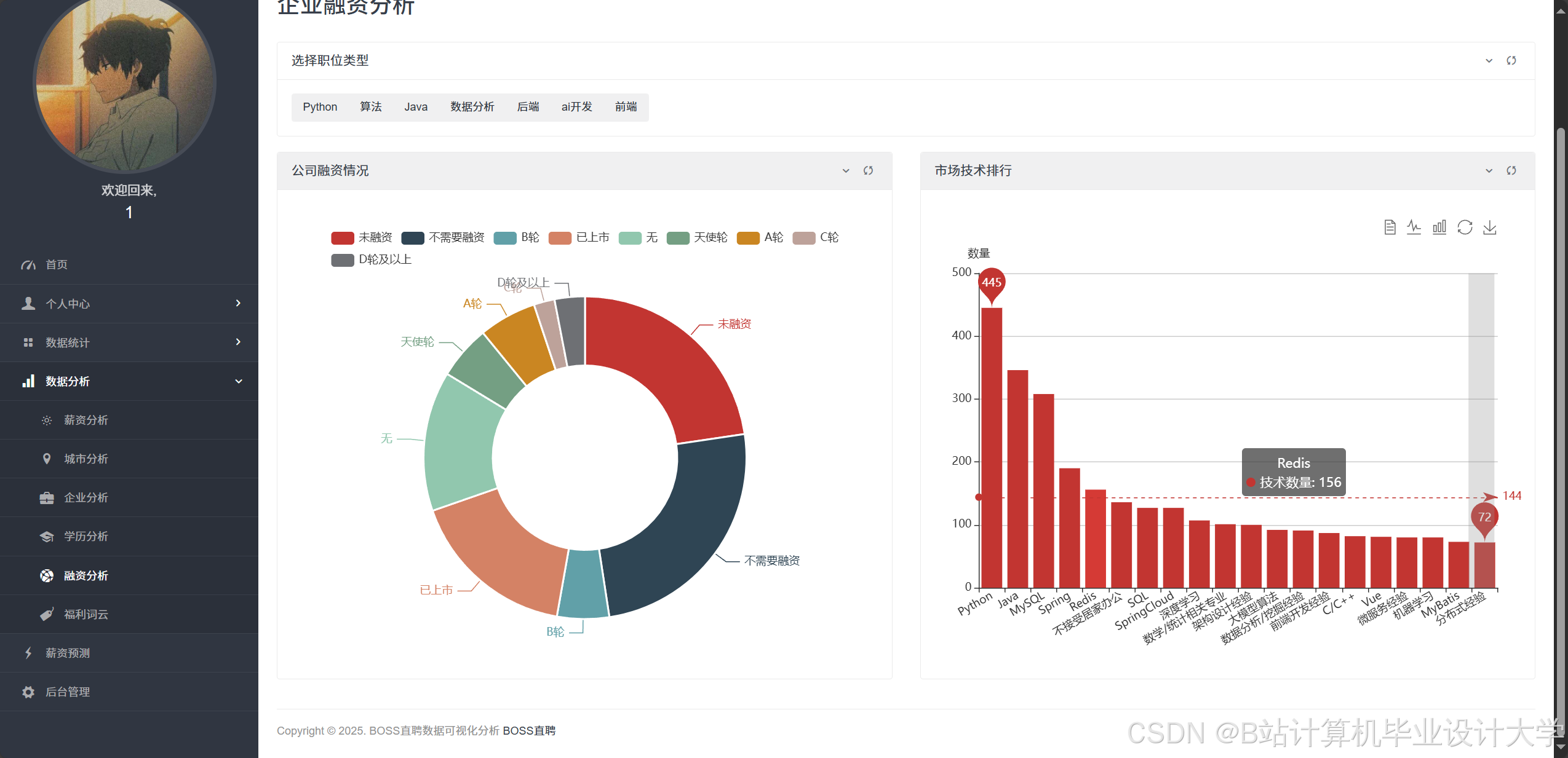
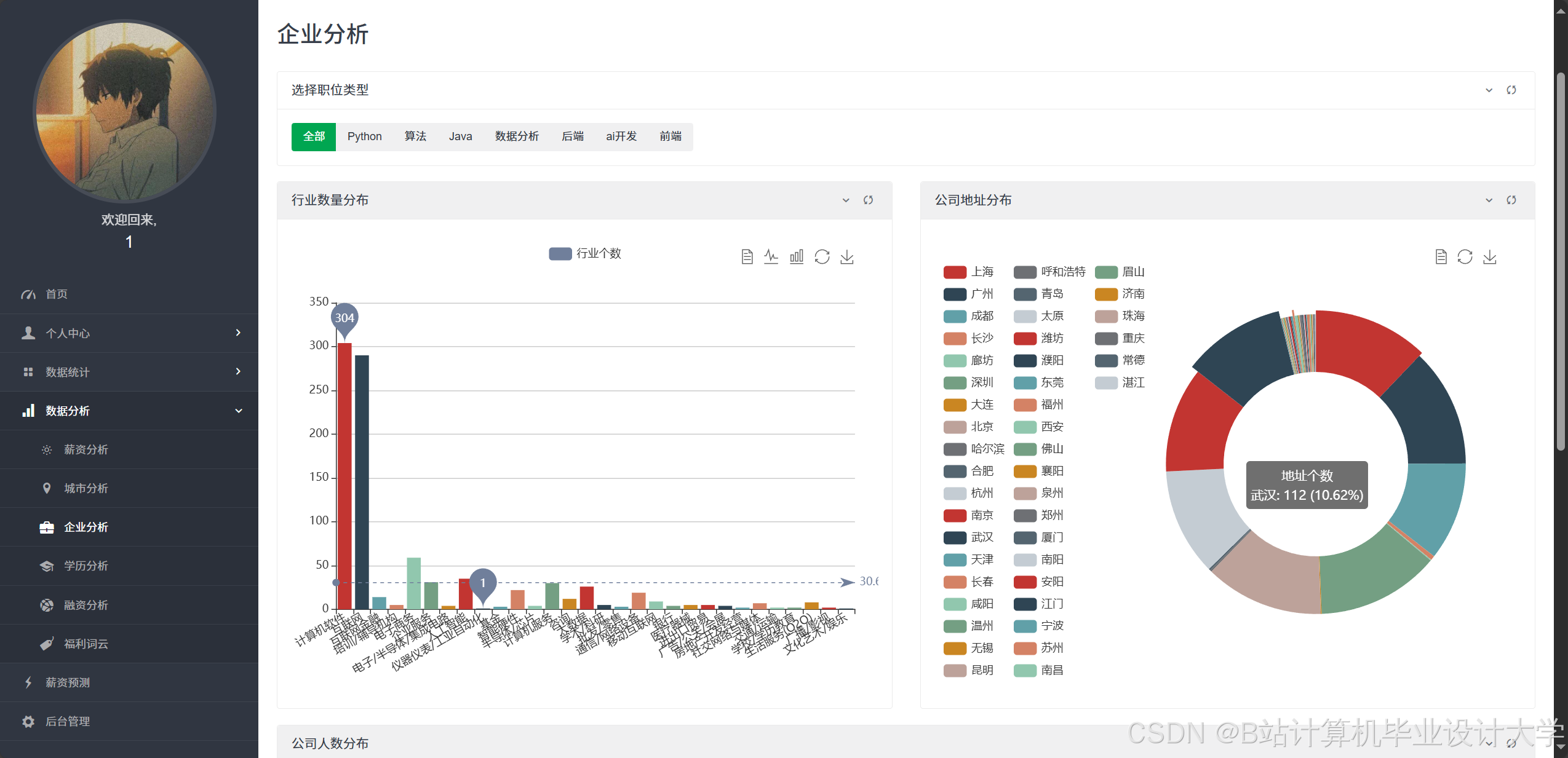
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











