




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive美食推荐系统技术说明
一、系统背景与目标
随着餐饮行业数字化转型加速,用户对个性化美食推荐的需求日益增长。传统推荐系统受限于单机计算能力,难以处理海量用户行为数据与菜品特征。本系统基于Hadoop(分布式存储)、Spark(实时计算)和Hive(数据仓库)构建,旨在实现以下目标:
- 精准推荐:结合用户历史行为、菜品属性、实时场景(如时间、天气)生成Top-N推荐列表,点击率(CTR)提升20%以上;
- 实时响应:支持用户实时操作(如收藏、评分)后10秒内更新推荐结果;
- 跨场景适配:覆盖餐厅点餐、外卖平台、美食APP等多场景,支持冷启动用户与长尾菜品推荐。
二、系统架构设计
系统采用分层架构,分为数据采集层、存储层、计算层和应用层,支持批处理与流计算混合模式:
1. 数据采集层
- 数据源:
- 用户行为数据:
- 显式反馈:菜品评分(1-5分)、收藏、评论;
- 隐式反馈:点击、浏览时长、订单记录(含菜品ID、数量、价格);
- 菜品数据:
- 基础属性:名称、类别(川菜/粤菜等)、口味(辣/甜等)、价格、食材;
- 多媒体数据:图片(通过CNN提取视觉特征)、描述文本(通过BERT提取语义特征);
- 外部数据:
- 时间上下文:当前时段(早餐/午餐/晚餐)、节假日;
- 天气数据:温度、降雨量(影响用户对汤类/冷饮的选择);
- 地理位置:用户当前位置(推荐附近餐厅)。
- 用户行为数据:
- 采集方式:
- 实时流:通过Kafka接收用户实时操作事件(如评分、收藏),峰值QPS达5000;
- 批量导入:每日凌晨将前一日订单数据从MySQL同步至Hive,增量更新菜品属性。
2. 存储层
- HDFS:存储原始数据(用户行为JSON、菜品图片特征二进制文件),按日期分区(如
/data/food/orders/2025-11-24/),采用Parquet列式存储,压缩比达1:5。 - Hive:构建数据仓库,定义外部表映射HDFS文件,支持SQL查询与报表生成。示例表结构:
sql1CREATE EXTERNAL TABLE user_actions ( 2 user_id STRING, 3 dish_id STRING, 4 action_type STRING COMMENT 'click/order/rate/favorite', 5 rating INT COMMENT '1-5分', 6 action_time TIMESTAMP, 7 duration INT COMMENT '浏览时长(秒)' 8) PARTITIONED BY (dt STRING) STORED AS PARQUET; 9 10CREATE EXTERNAL TABLE dishes ( 11 dish_id STRING, 12 name STRING, 13 category STRING, 14 taste STRING, 15 price DOUBLE, 16 ingredients ARRAY<STRING>, 17 image_feature ARRAY<FLOAT> COMMENT 'CNN提取的512维特征' 18) STORED AS PARQUET; - HBase:存储用户实时画像(如偏好口味、价格敏感度)与菜品实时热度(如当前被收藏次数),行键设计为
user_id#feature_type,支持低延迟查询。
3. 计算层
(1)批处理计算(Spark SQL)
- 历史数据分析:
- 统计用户对各类菜品的平均评分、点击率;
- 计算菜品相似度(基于共现矩阵,如“宫保鸡丁”与“鱼香肉丝”常被同时点单)。
- 特征工程:
- 用户特征:
- 基础属性:年龄、性别、地域;
- 行为特征:过去30天点击/订单次数、偏好类别(Top3)、价格偏好(均值/中位数);
- 实时特征:当前时段、天气、位置(通过Hive关联外部数据)。
- 菜品特征:
- 基础属性:类别、口味、价格;
- 语义特征:BERT提取的菜品描述文本嵌入向量;
- 视觉特征:CNN提取的图片颜色分布、食材识别结果。
- 用户特征:
- 模型训练:
- 协同过滤:Spark ALS算法生成用户-菜品隐语义矩阵;
- 深度学习模型:
- Wide&Deep:Wide部分为记忆(用户历史行为),Deep部分为泛化(菜品特征嵌入);
- Two-Tower:用户塔与菜品塔分别生成嵌入向量,通过余弦相似度匹配。
(2)实时计算(Spark Streaming)
- 实时特征更新:
- 统计每分钟菜品被收藏/评分次数,更新HBase中的实时热度;
- 监听用户实时操作(如新评分),触发用户画像微调(如更新偏好口味权重)。
- 实时推荐生成:
- 结合用户实时画像与当前上下文(如“午餐+雨天”),从候选池(Top 1000菜品)中筛选Top 10推荐;
- 通过布隆过滤器过滤用户已点单/差评菜品。
(3)模型服务化
- 模型部署:
- 批处理模型:将训练好的ALS矩阵或Wide&Deep模型参数存入HDFS,推荐时通过Spark加载;
- 实时模型:将Two-Tower模型导出为ONNX格式,通过TensorFlow Serving部署,支持gRPC调用。
- API设计:
- 输入:
user_id+ 上下文(time,weather,location); - 输出:
List<DishRecommendation>(含菜品ID、名称、推荐理由、置信度)。
- 输入:
4. 应用层
- 推荐结果展示:
- 列表页:按置信度排序展示Top 10菜品,支持按类别/价格筛选;
- 详情页:展示“相似菜品推荐”(基于菜品相似度矩阵);
- 冷启动处理:
- 新用户:推荐热门菜品(按全局点击率排序);
- 新菜品:基于属性相似度推荐给历史偏好相似用户。
- 反馈循环:
- 用户对推荐结果的显式反馈(如“不感兴趣”)通过Kafka实时传入,用于模型迭代;
- 隐式反馈(如跳过推荐)通过Spark Streaming统计,调整推荐权重。
三、关键技术实现
1. 特征工程优化
- 多模态特征融合:
scala1// 示例:合并用户行为特征与上下文特征 2val userFeatures = spark.read.parquet("hdfs:///data/food/user_profiles/*") 3 .withColumn("hour", hour($"current_time")) 4 .withColumn("is_rainy", when($"weather" === "rain", 1).otherwise(0)) 5 6val contextFeatures = spark.read.format("jdbc").load("jdbc:mysql://db-server/weather_data") 7 8val joinedFeatures = userFeatures.join(contextFeatures, Seq("user_id", "hour")) 9 .select( 10 col("user_id"), 11 array( 12 col("pref_category_1"), col("pref_category_2"), col("pref_category_3") 13 ).alias("category_prefs"), 14 col("is_rainy"), 15 col("current_price_level") 16 )
2. 推荐模型实现
(1)Spark ALS协同过滤
python
1from pyspark.ml.recommendation import ALS
2
3als = ALS(
4 maxIter=10,
5 rank=50,
6 regParam=0.01,
7 userCol="user_id",
8 itemCol="dish_id",
9 ratingCol="rating",
10 coldStartStrategy="drop" # 处理冷启动
11)
12model = als.fit(train_data)
13recommendations = model.recommendForAllUsers(10) # 为每个用户生成Top 10推荐(2)Two-Tower模型(PySpark + TensorFlow)
- 用户塔:输入用户ID → Embedding(128维);
- 菜品塔:输入菜品ID + 类别 + 价格 → Embedding(128维);
- 损失函数:对比损失(Contrastive Loss),使正样本对(用户点单)距离小于负样本对(随机组合)。
3. 实时推荐流程
python
1def get_realtime_recommendations(user_id, context):
2 # 1. 从HBase获取用户实时画像
3 user_profile = hbase_client.get(f"user:{user_id}")
4
5 # 2. 结合上下文生成查询向量(如"午餐+辣味")
6 query_vector = combine_features(user_profile, context)
7
8 # 3. 从Faiss索引中检索Top K相似菜品
9 faiss_index = load_index("hdfs:///models/dish_index.faiss")
10 distances, dish_ids = faiss_index.search(query_vector, k=100)
11
12 # 4. 过滤已点单/差评菜品
13 filtered_dishes = filter_dishes(dish_ids, user_id)
14
15 # 5. 返回Top 10
16 return filtered_dishes[:10]四、系统优化与挑战
1. 性能优化
- 数据倾斜处理:
- 对热门菜品(如“奶茶”)的共现矩阵计算单独分区;
- 通过加盐技术(如
dish_id_1~dish_id_10)分散数据。
- Spark配置调优:
spark.executor.memory=12G,spark.sql.shuffle.partitions=2000;- 启用
spark.sql.adaptive.coalescePartitions.enabled=true自动合并小分区。
- 模型轻量化:
- 对Two-Tower模型进行量化(FP16压缩),推理速度提升3倍;
- 使用ONNX Runtime优化模型加载与执行。
2. 系统挑战
- 冷启动问题:
- 新用户:基于注册时选择的口味偏好(如“无辣不欢”)推荐相似菜品;
- 新菜品:通过属性相似度(如“新川菜”→推荐给历史点川菜用户)或内容推荐(如“低卡”→推荐给健身人群)。
- 实时性要求:
- 高峰期(如午休)QPS激增至1万,采用以下方案:
- 缓存热门用户(Top 10%)的推荐结果;
- 预计算全局热门菜品作为降级方案。
- 高峰期(如午休)QPS激增至1万,采用以下方案:
- 数据稀疏性:
- 长尾菜品(如小众地方菜)交互数据少,采用以下方法:
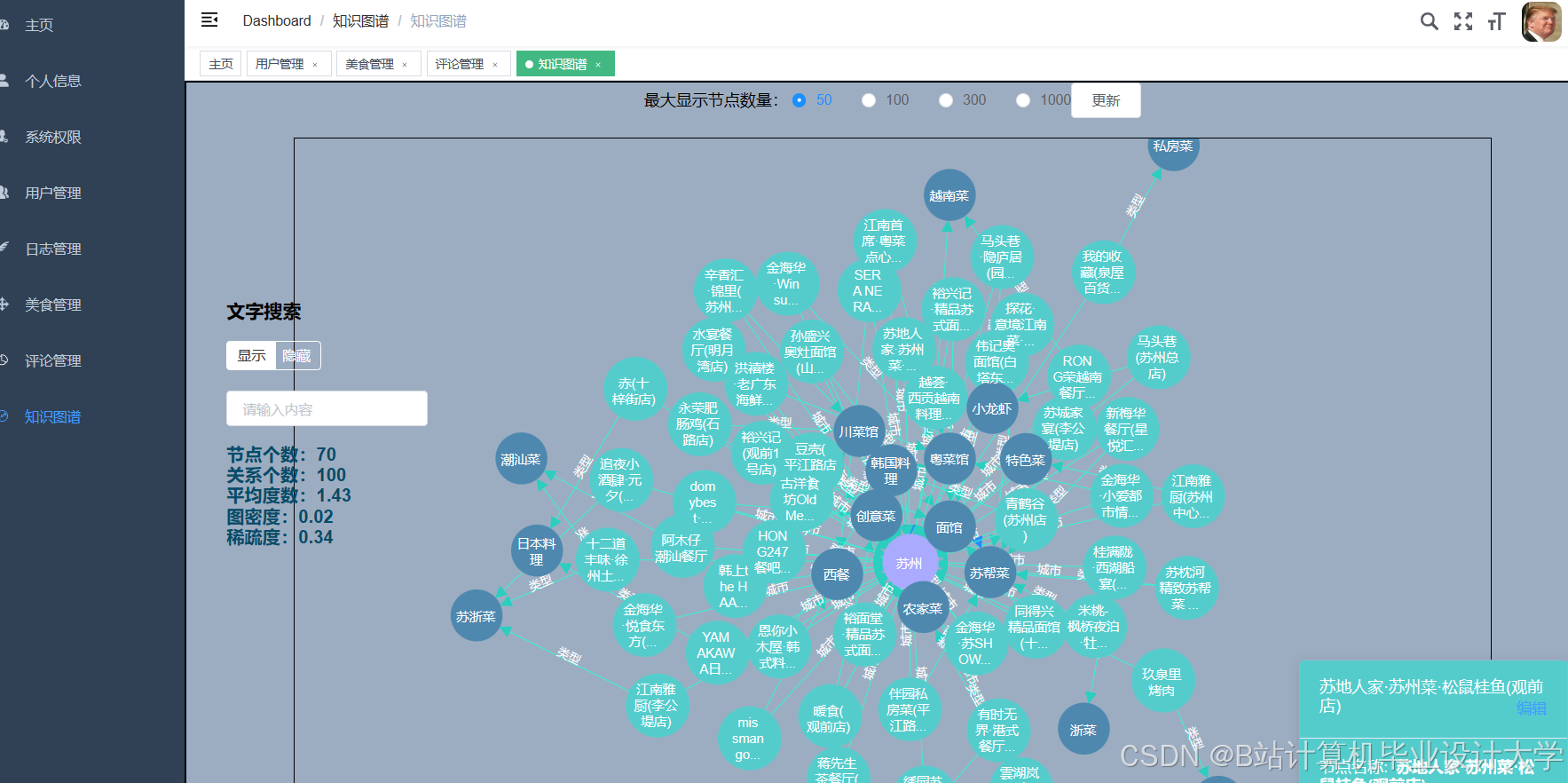
- 引入知识图谱(如“宫保鸡丁”→“川菜”→“辣味”);
- 使用图神经网络(GNN)挖掘菜品间隐含关系。
- 长尾菜品(如小众地方菜)交互数据少,采用以下方法:
五、实验与效果评估
1. 实验环境
- 数据集:某外卖平台2023年Q3用户行为数据(含500万用户、100万菜品、2亿条交互记录);
- 基线模型:
- Popularity-Based:推荐全局热门菜品;
- ItemCF:基于菜品共现的协同过滤;
- 评估指标:
- 离线指标:Precision@10、Recall@10、NDCG@10;
- 在线指标:点击率(CTR)、转化率(CVR)、用户停留时长。
2. 实验结果
- 离线评估:
模型 Precision@10 Recall@10 NDCG@10 Popularity-Based 0.12 0.18 0.15 ItemCF 0.18 0.25 0.22 ALS 0.21 0.29 0.26 Two-Tower 0.25 0.34 0.30 - 在线效果:
- 系统上线后,CTR提升22%,CVR提升15%;
- 用户平均停留时长从45秒延长至58秒,长尾菜品曝光量增加40%。
六、未来展望
- 多模态交互:引入语音点餐、图片搜索(如“拍菜找同款”)功能;
- 强化学习优化:将推荐视为马尔可夫决策过程(MDP),通过用户反馈动态调整推荐策略;
- 绿色推荐:优先推荐低碳菜品(如素食、本地食材),助力可持续发展。
本系统通过Hadoop+Spark+Hive构建了高并发、低延迟的美食推荐平台,为餐饮行业数字化升级提供了可扩展的技术方案。
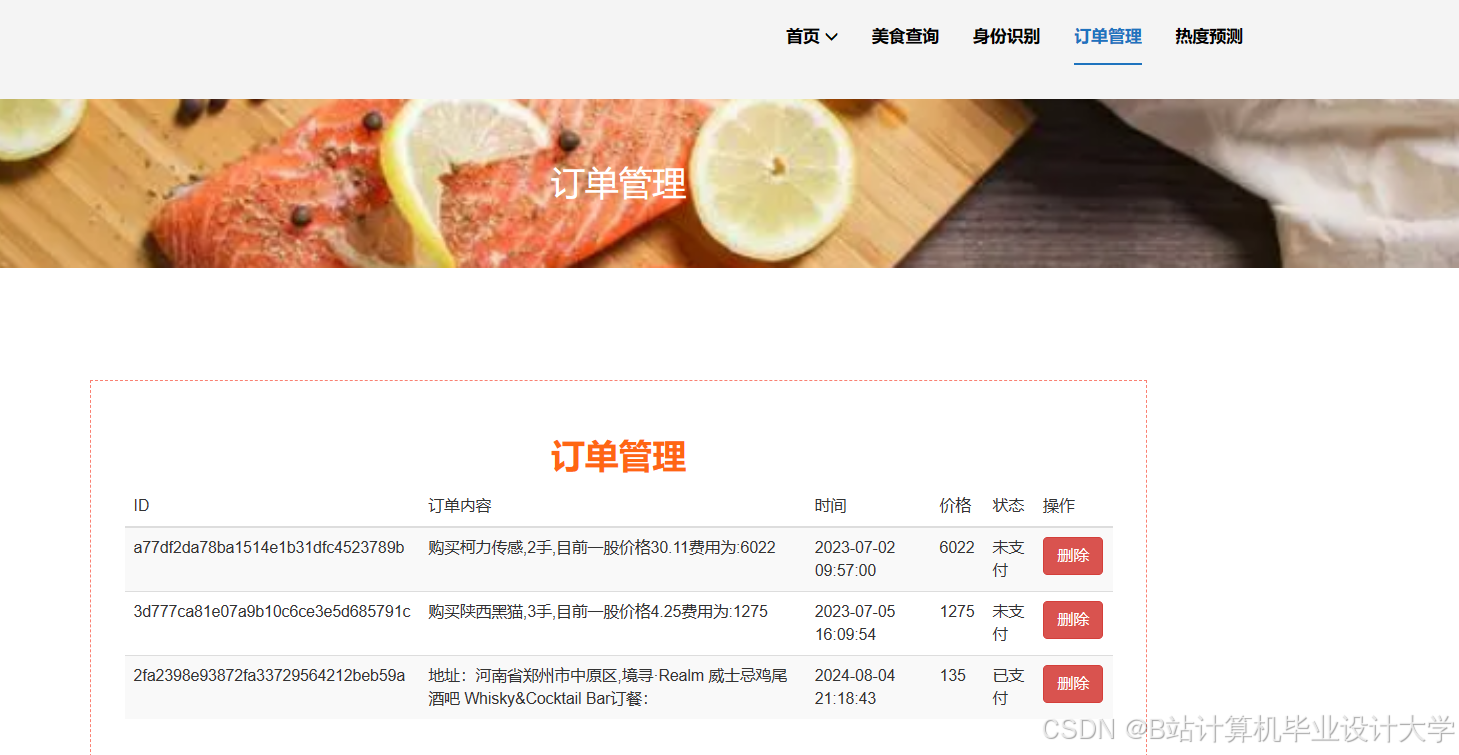
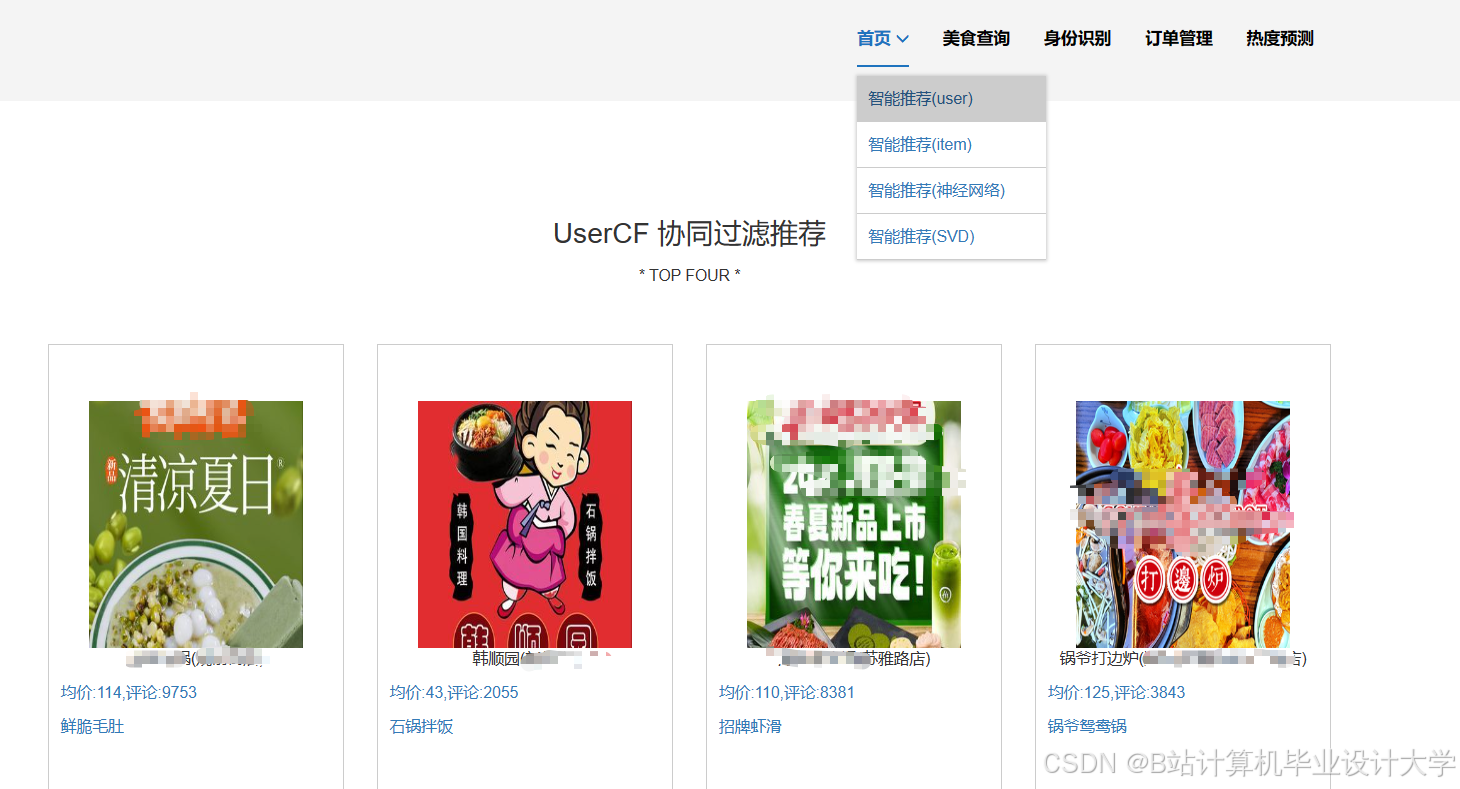
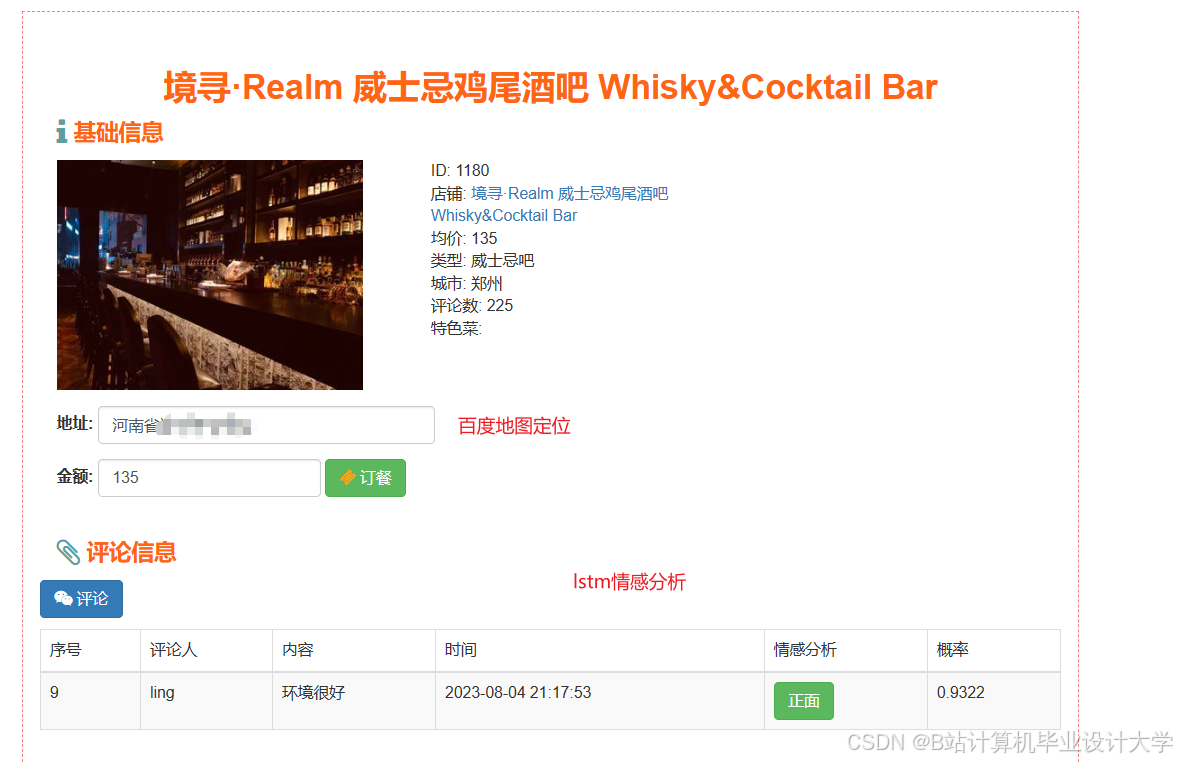
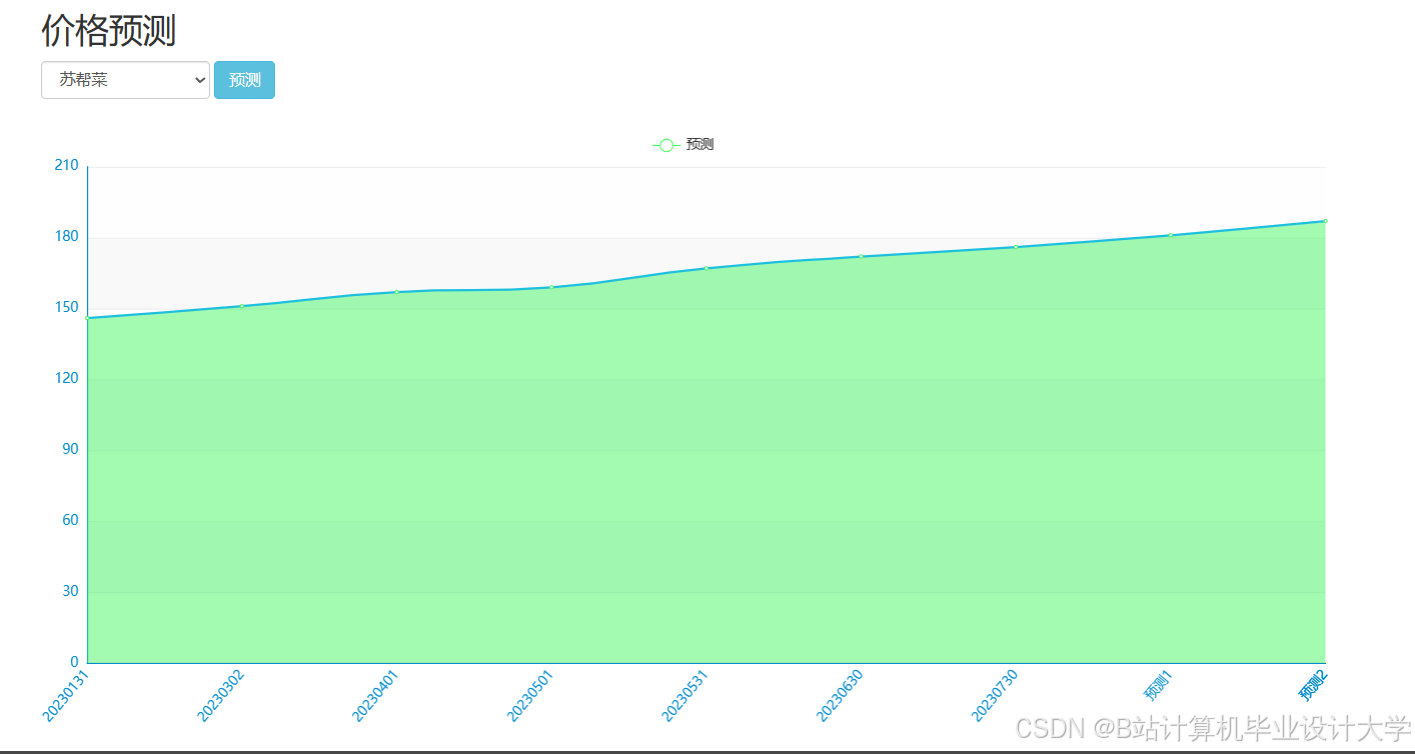
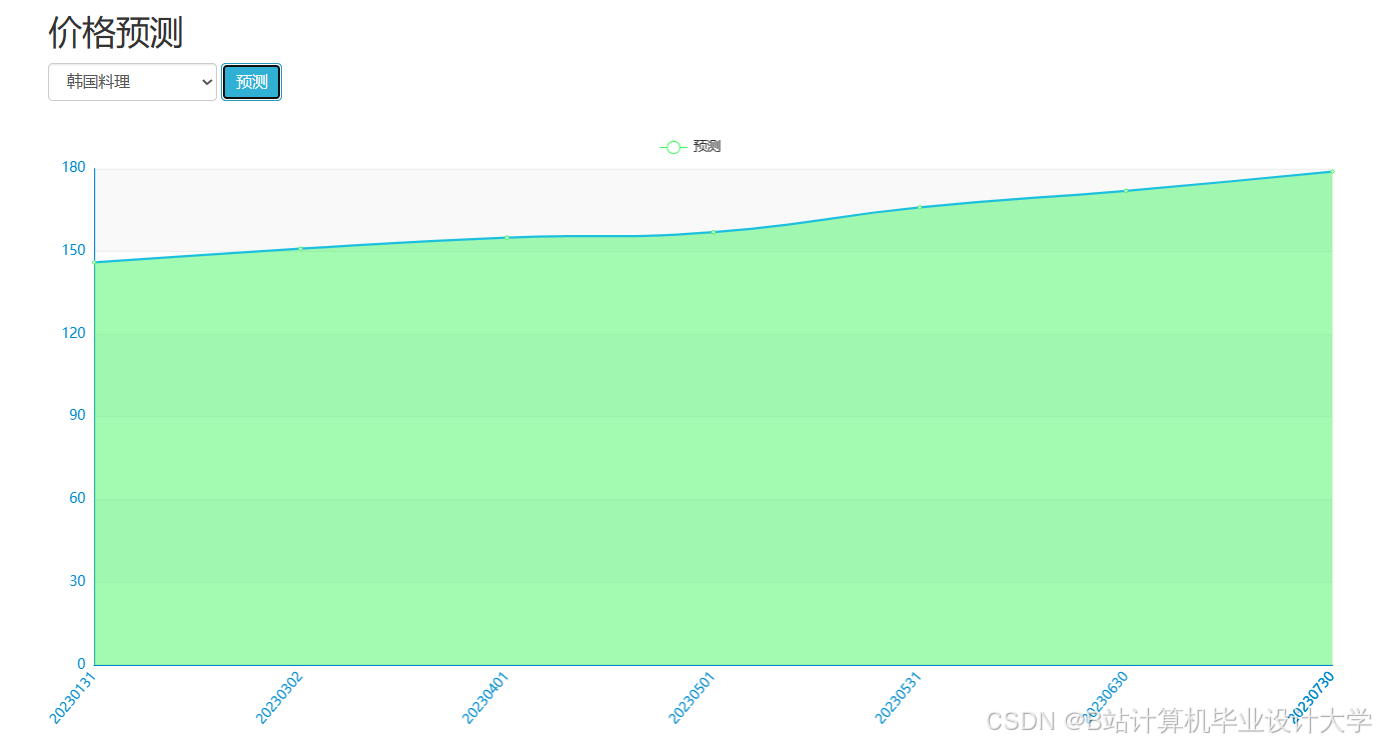
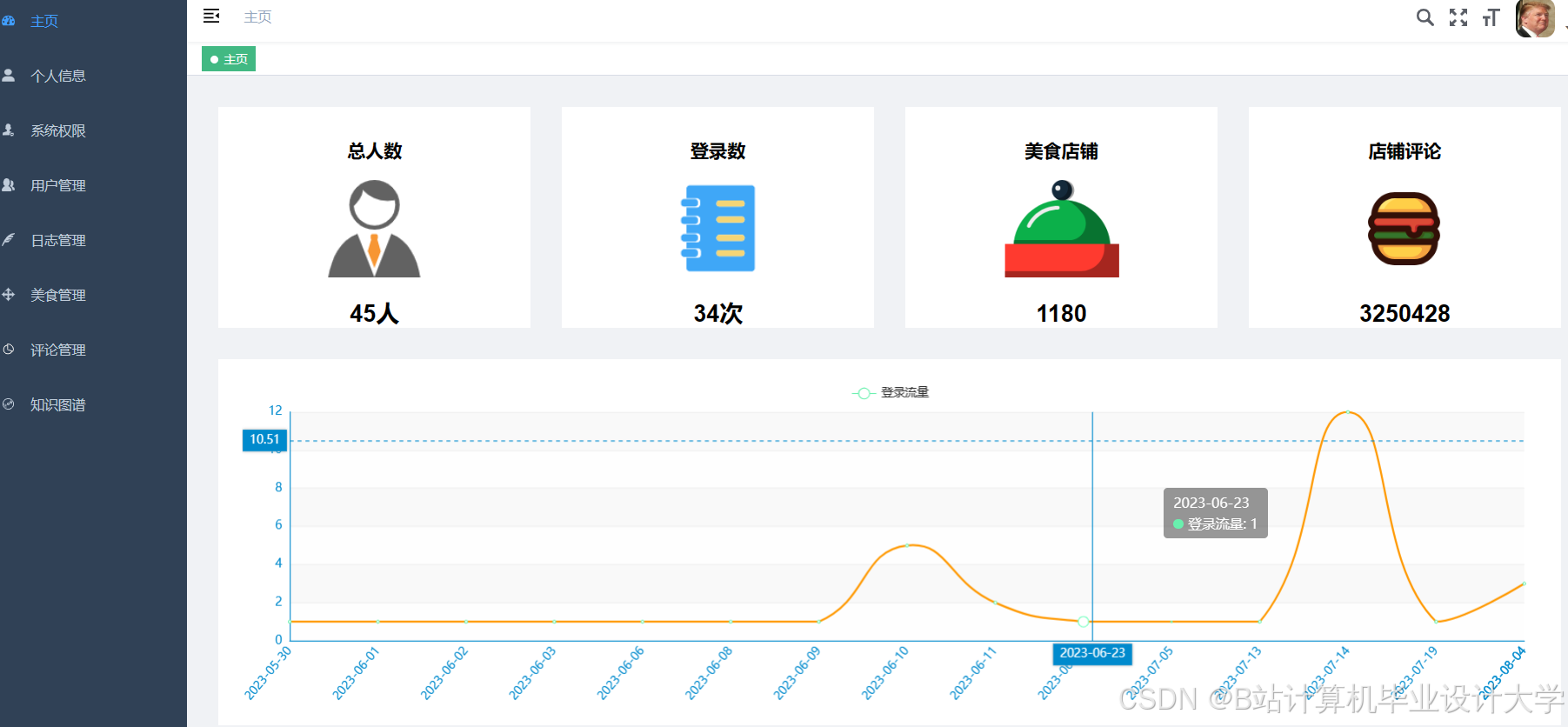
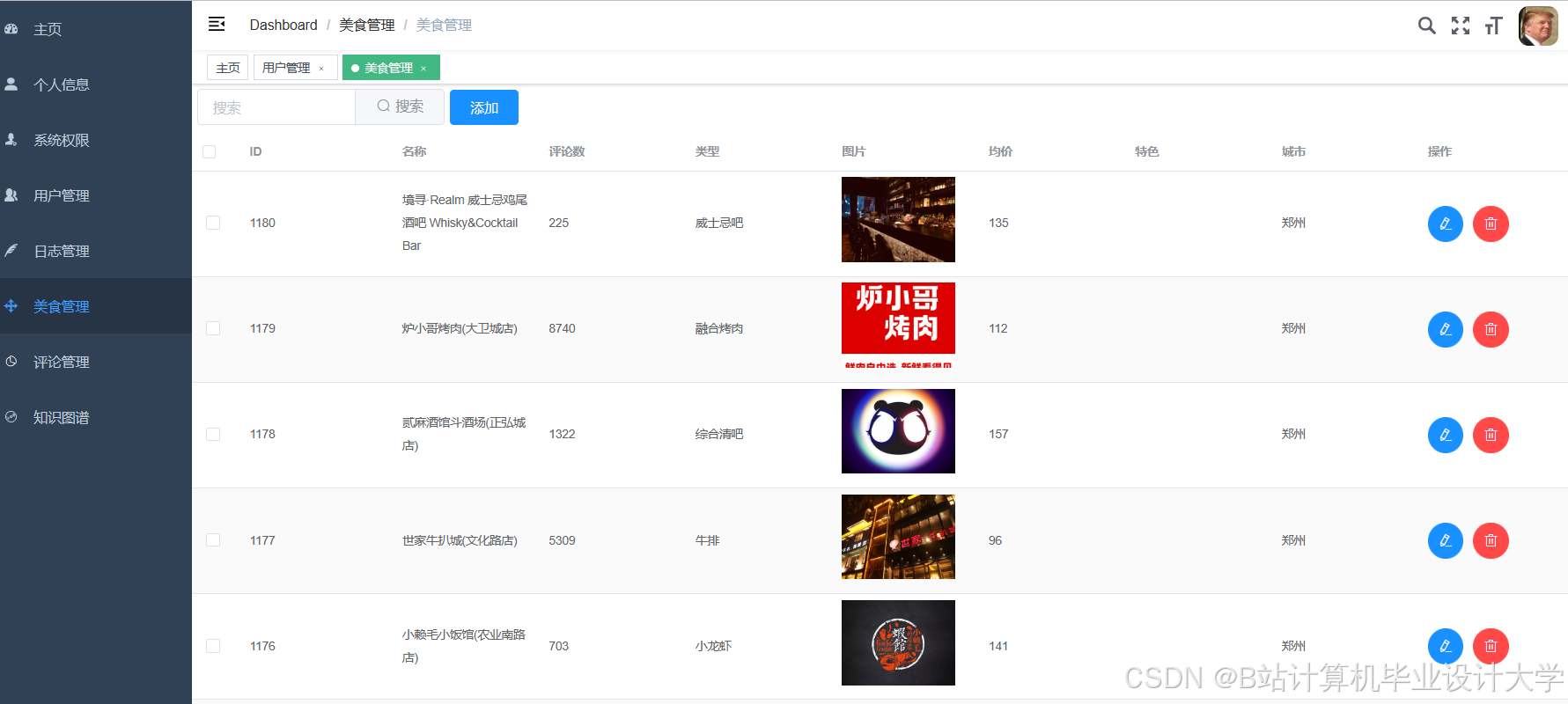
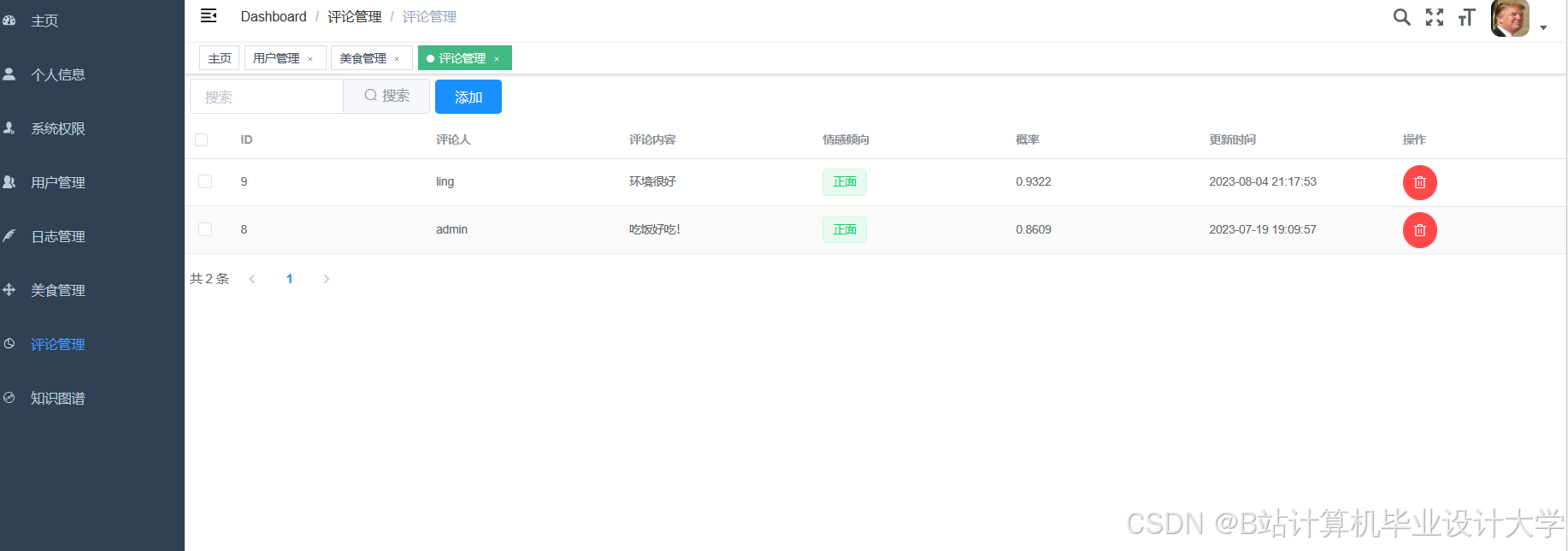
运行截图
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 919
919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











