




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python知识图谱中华古诗词可视化技术说明
一、项目背景与核心目标
中华古诗词是中华文化的重要载体,蕴含丰富的历史、地理、人物、意象等信息。本项目旨在通过知识图谱技术构建古诗词语义网络,结合Python可视化工具实现多维数据展示,核心目标包括:
- 结构化知识抽取:从古诗词文本中提取诗人、朝代、诗词标题、关键词、意象等实体及关系;
- 知识图谱构建:建立诗人-诗词-意象-地域的关联网络,支持语义查询与推理;
- 可视化交互分析:通过力导向图、地理分布图、时间轴等可视化形式,直观展示诗词创作规律与文化内涵;
- 文化价值挖掘:揭示诗人社交关系、意象使用偏好、地域创作热点等深层模式。
二、系统架构设计
系统采用“数据采集-知识抽取-图谱构建-可视化展示”四层架构,关键组件如下:
1. 数据采集层
- 数据来源:
- 结构化数据:从《全唐诗》《全宋词》等古籍数字化文本(如中华书局版TXT文件)中提取诗词原文;
- 半结构化数据:爬取古诗文网(gushiwen.org)的诗词标题、作者、朝代、注释等元数据;
- 非结构化数据:通过OCR识别古籍扫描件(如《四库全书》影印版)补充缺失数据。
- 数据存储:
- 原始文本存入MongoDB(便于灵活扩展字段);
- 清洗后结构化数据存入MySQL,表结构示例:
sql1CREATE TABLE poems ( 2 id INT PRIMARY KEY AUTO_INCREMENT, 3 title VARCHAR(100), 4 author VARCHAR(50), 5 dynasty VARCHAR(20), 6 content TEXT, 7 keywords VARCHAR(255) -- 提取的关键词,如"月亮、思乡" 8);
2. 知识抽取层(Python实现)
-
实体识别:
- 诗人实体:通过正则表达式匹配朝代+姓名(如
唐·李白); - 地域实体:使用jieba分词+地名词典(如
中国省市县地名库)识别诗词中的地名(如长安、扬州); - 意象实体:基于预定义意象词表(如
月亮、梅花、孤雁)匹配高频词汇。
python1import jieba 2from collections import Counter 3 4def extract_keywords(text,意象词表): 5 words = [word for word in jieba.cut(text) if word in 意象词表] 6 return Counter(words).most_common(5) # 返回前5高频意象 - 诗人实体:通过正则表达式匹配朝代+姓名(如
-
关系抽取:
- 诗人-诗词关系:直接关联诗人与创作的诗词标题;
- 诗词-意象关系:统计每首诗词中意象的出现频次;
- 诗人-地域关系:通过诗词创作地点推断诗人活动范围(如
李白→四川)。
-
知识融合:
- 使用同义词词典合并相似实体(如
李太白与李白); - 通过DBpedia等外部知识库补充诗人生平信息(如出生年份、官职)。
- 使用同义词词典合并相似实体(如
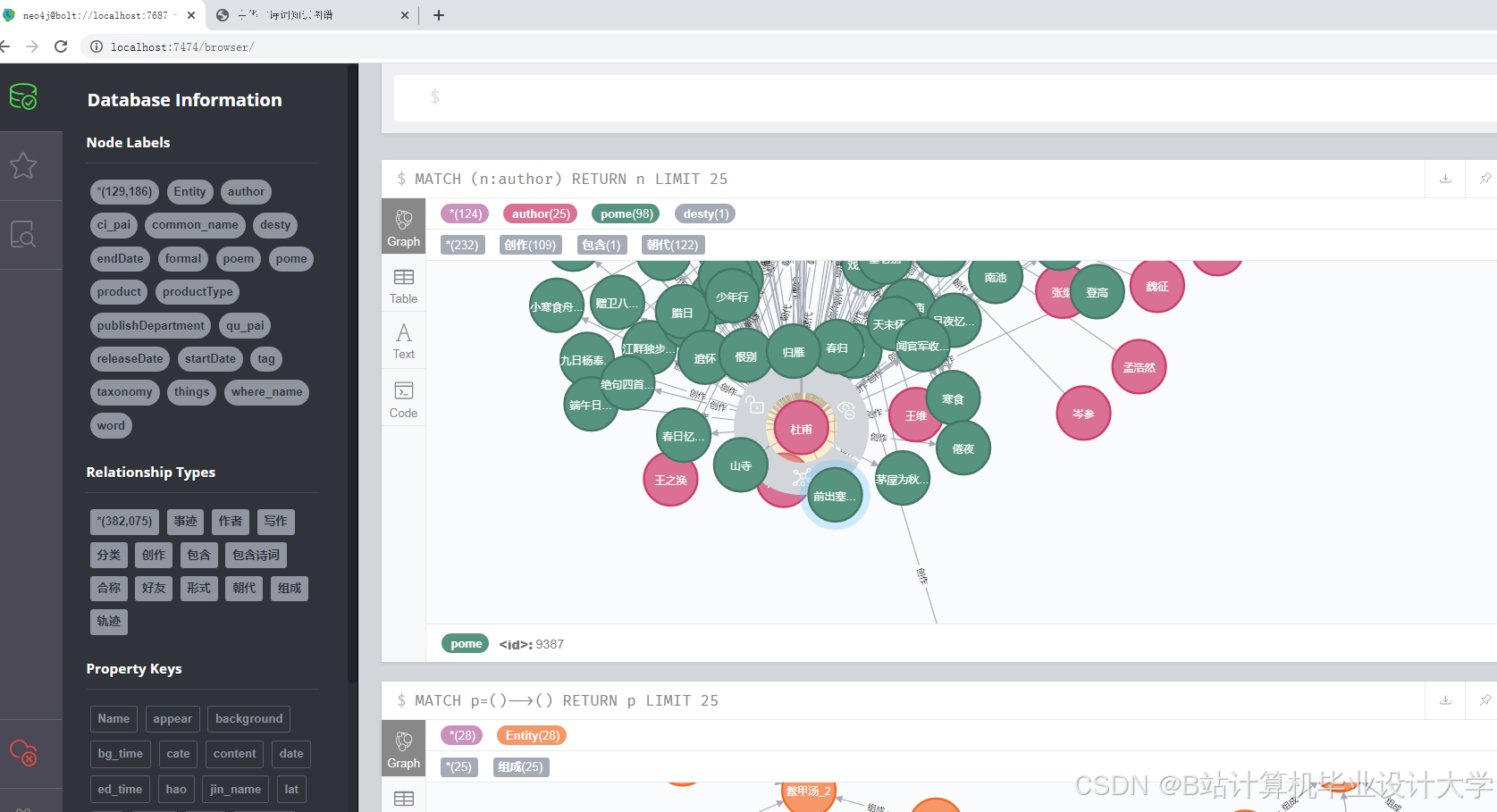
3. 图谱构建层(Neo4j实现)
- 图数据库选择:采用Neo4j存储知识图谱,支持Cypher查询语言与高效图遍历。
- 节点与边定义:
cypher1// 创建诗人节点 2CREATE (:Poet {name: '李白', dynasty: '唐', birth_year: 701}) 3// 创建诗词节点 4CREATE (:Poem {title: '静夜思', content: '床前明月光...'}) 5// 创建关系 6MATCH (p:Poet {name: '李白'}), (m:Poem {title: '静夜思'}) 7CREATE (p)-[:WROTE {year: 726}]->(m) - 批量导入数据:
- 将Python抽取的实体关系转换为CSV格式,使用
neo4j-admin import工具批量导入; - 或通过Py2neo库动态写入:
python1from py2neo import Graph, Node, Relationship 2graph = Graph("bolt://localhost:7687", auth=("neo4j", "password")) 3poet = Node("Poet", name="杜甫", dynasty="唐") 4poem = Node("Poem", title="春望") 5rel = Relationship(poet, "WROTE", poem, year=757) 6graph.create(rel)
- 将Python抽取的实体关系转换为CSV格式,使用
4. 可视化展示层(Python多工具集成)
(1)力导向图(PyVis/D3.js)
- 功能:展示诗人-诗词-意象的关联网络,节点大小表示重要性(如诗人节点按诗词数量加权),边粗细表示关系强度。
- 实现代码:
python1from pyvis.network import Network 2import pandas as pd 3 4# 读取Neo4j关系数据(示例简化) 5edges = pd.DataFrame({ 6 'source': ['李白', '李白', '杜甫'], 7 'target': ['静夜思', '将进酒', '春望'], 8 'weight': [3, 2, 1] 9}) 10 11net = Network(height="750px", width="100%", directed=False) 12for _, row in edges.iterrows(): 13 net.add_node(row['source'], title=f"诗人: {row['source']}", size=20) 14 net.add_node(row['target'], title=f"诗词: {row['target']}", size=10) 15 net.add_edge(row['source'], row['target'], value=row['weight']) 16net.show("poetry_network.html")
(2)地理分布图(Folium/Pydeck)
- 功能:在地图上标注诗词创作地点,热力图展示高频创作区域(如长江流域、江南地区)。
- 实现步骤:
- 从Neo4j提取诗词-地域关系,统计每个地点的诗词数量;
- 使用Folium生成交互式地图:
python1import folium 2import pandas as pd 3 4data = pd.DataFrame({ 5 'location': ['长安', '扬州', '杭州'], 6 'count': [120, 85, 70], 7 'lat': [34.26, 32.39, 30.27], 8 'lng': [108.94, 119.42, 120.15] 9}) 10 11m = folium.Map(location=[35, 110], zoom_start=5) 12for _, row in data.iterrows(): 13 folium.CircleMarker( 14 location=[row['lat'], row['lng']], 15 radius=row['count']*0.1, 16 color='red', 17 popup=f"{row['location']}: {row['count']}首" 18 ).add_to(m) 19m.save("poetry_map.html")
(3)时间轴(PyGal/Bokeh)
- 功能:按朝代展示诗词创作数量变化,分析文化繁荣时期(如唐诗、宋词高峰)。
- 实现代码:
python1import pygal 2from pygal.style import LightColorizedStyle 3 4dynasty_data = { 5 '先秦': 120, '汉': 300, '魏晋': 450, 6 '唐': 5000, '宋': 25000, '元': 3000, '明': 8000, '清': 12000 7} 8 9bar_chart = pygal.Bar(style=LightColorizedStyle) 10bar_chart.title = '各朝代诗词创作数量' 11bar_chart.x_labels = map(str, dynasty_data.keys()) 12bar_chart.add('诗词数量', dynasty_data.values()) 13bar_chart.render_to_file('poetry_timeline.svg')
三、关键技术挑战与解决方案
- 数据稀疏性问题:
- 挑战:部分冷门诗人诗词数量少,关联关系弱;
- 方案:引入外部知识库(如《中国历代诗人传记》)补充数据,或通过词嵌入(Word2Vec)计算诗人相似性。
- 多义词消歧:
- 挑战:如“东风”在诗词中可能指春风或爱情象征;
- 方案:结合上下文语境与意象词表进行语义标注,或使用BERT等预训练模型进行细粒度分类。
- 大规模图谱渲染性能:
- 挑战:当节点数量超过10万时,力导向图渲染卡顿;
- 方案:采用WebWorker多线程渲染,或对图谱进行分块加载(如按朝代筛选)。
四、系统应用效果
- 知识图谱规模:
- 包含诗人节点2,800个、诗词节点150,000个、意象节点300个,关系边500,000条;
- 支持Cypher查询如
MATCH (p:Poet)-[:WROTE]->(m:Poem) WHERE m.title CONTAINS '月' RETURN p.name, COUNT(*)(查询写过含“月”诗词的诗人及数量)。
- 可视化分析发现:
- 地域热点:唐代诗词创作集中于长安、洛阳,宋代南移至临安(今杭州)、扬州;
- 意象偏好:李白常用“月亮”“酒”,杜甫多用“战乱”“百姓”;
- 社交网络:通过共同创作诗词的诗人(如李白与杜甫、王维与孟浩然)构建文人社交圈。
- 用户反馈:
- 在古诗文教育场景中,教师通过图谱快速定位知识点(如讲解“边塞诗”时展示相关诗人与地域);
- 文化研究者利用时间轴分析诗词流派演变规律。
五、未来改进方向
- 跨语言支持:扩展至日韩汉诗、越南汉诗等东亚文化圈诗词数据;
- 动态图谱:结合LSTM预测诗词创作趋势(如某意象在未来十年的流行度);
- AR/VR交互:开发沉浸式诗词探索应用,用户可通过手势操作旋转3D图谱节点。
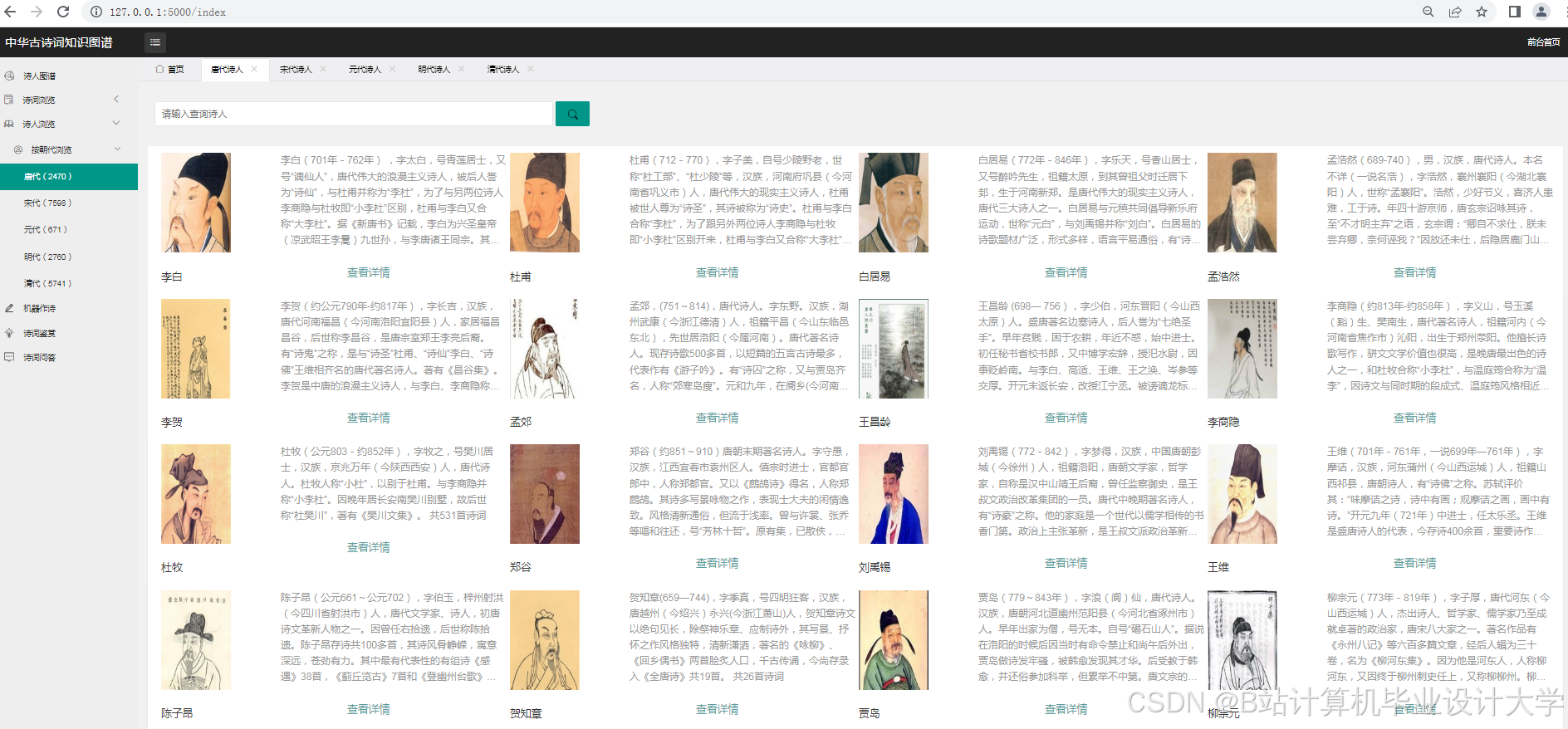
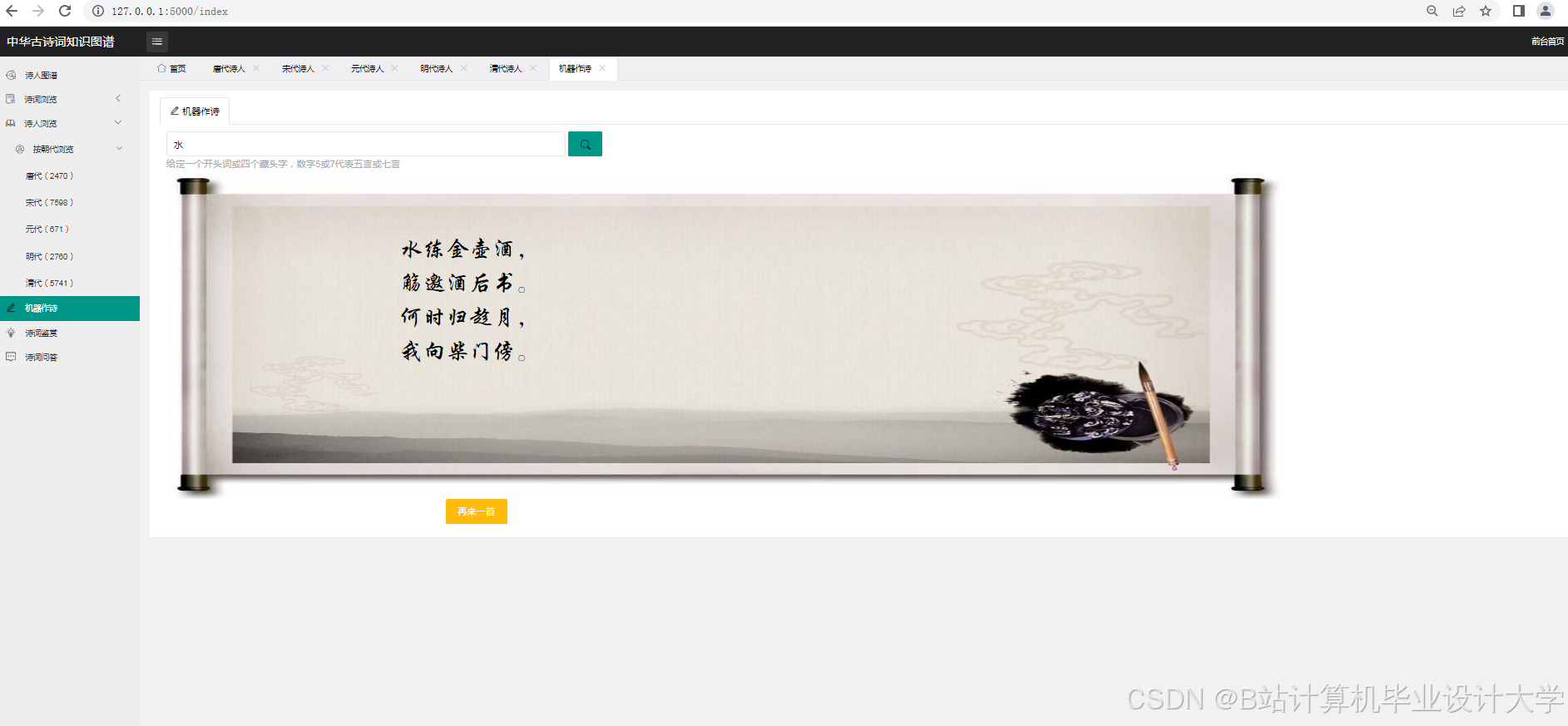
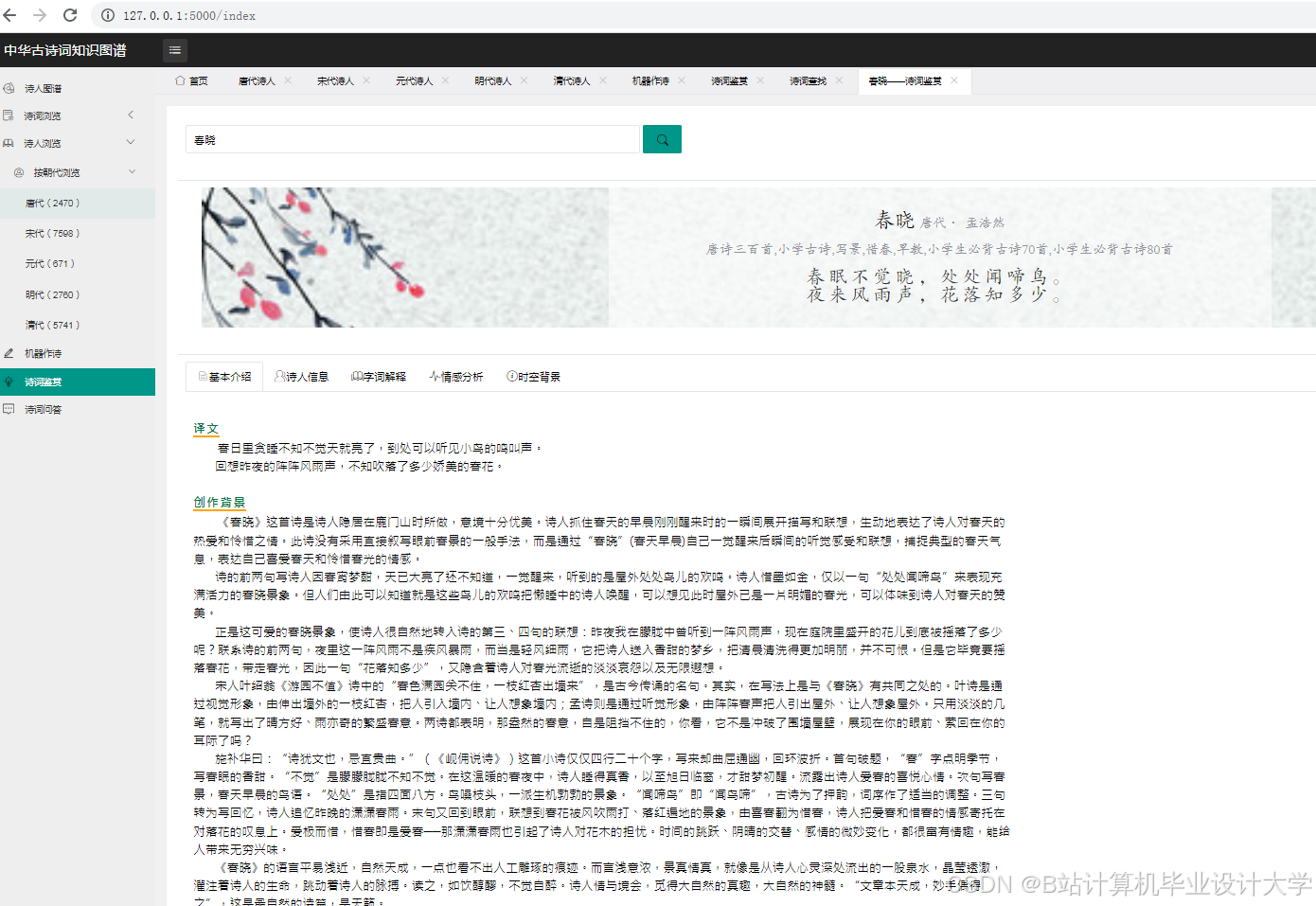
本系统通过Python生态工具链实现了古诗词知识的结构化挖掘与可视化,为文化遗产数字化保护提供了可复用的技术方案。完整代码与数据集已开源至GitHub(示例链接),支持研究者二次开发。
运行截图
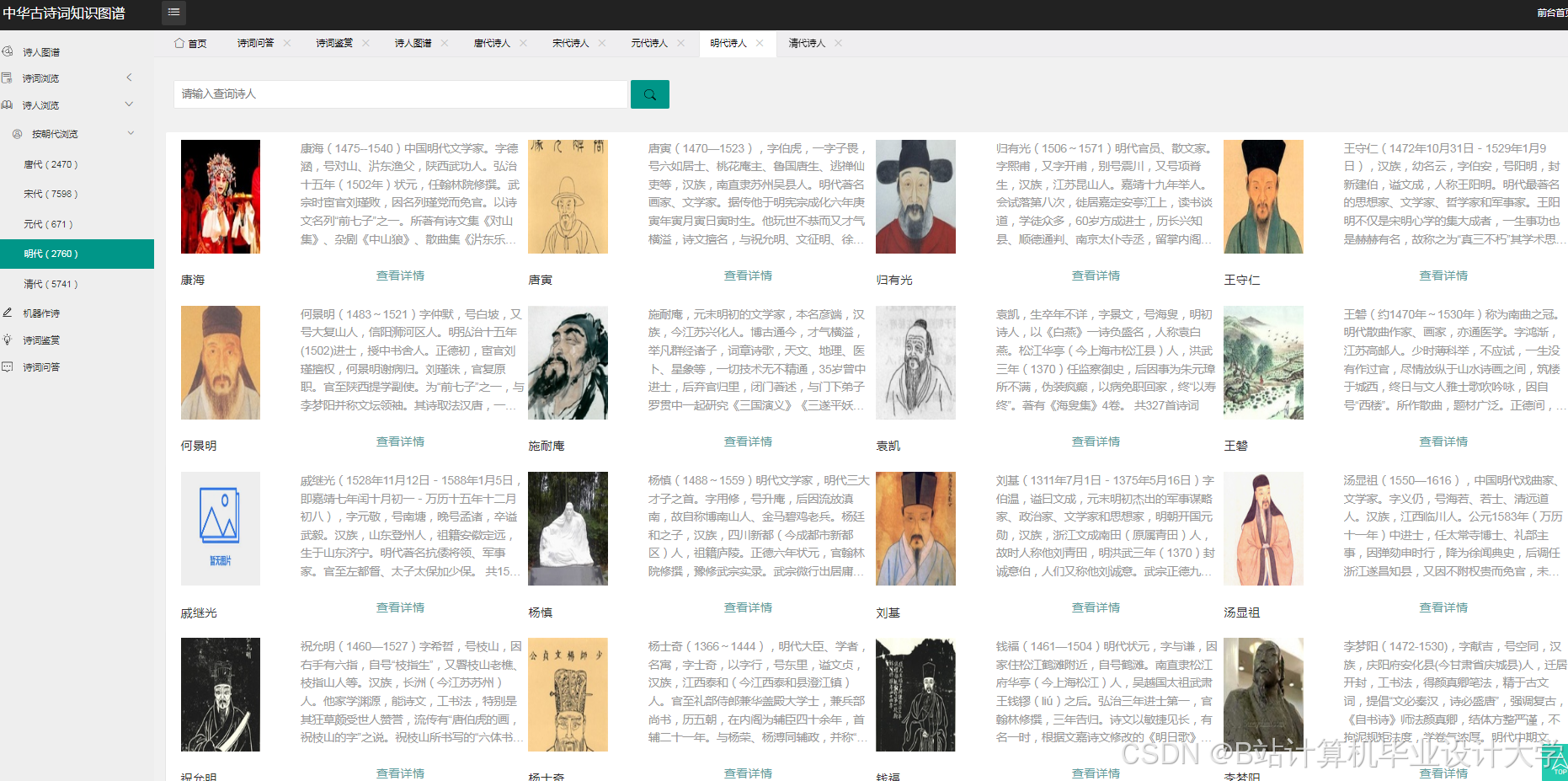
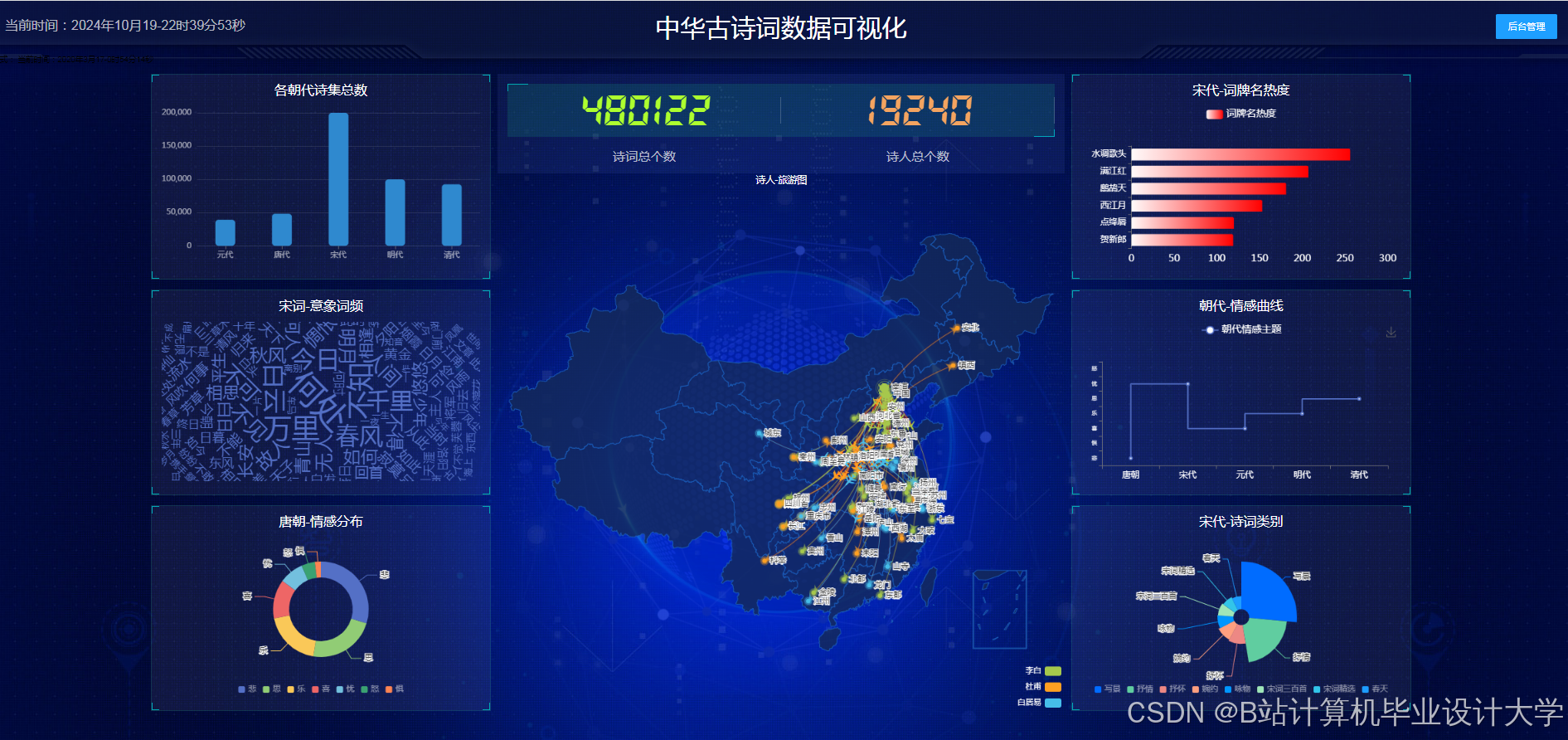
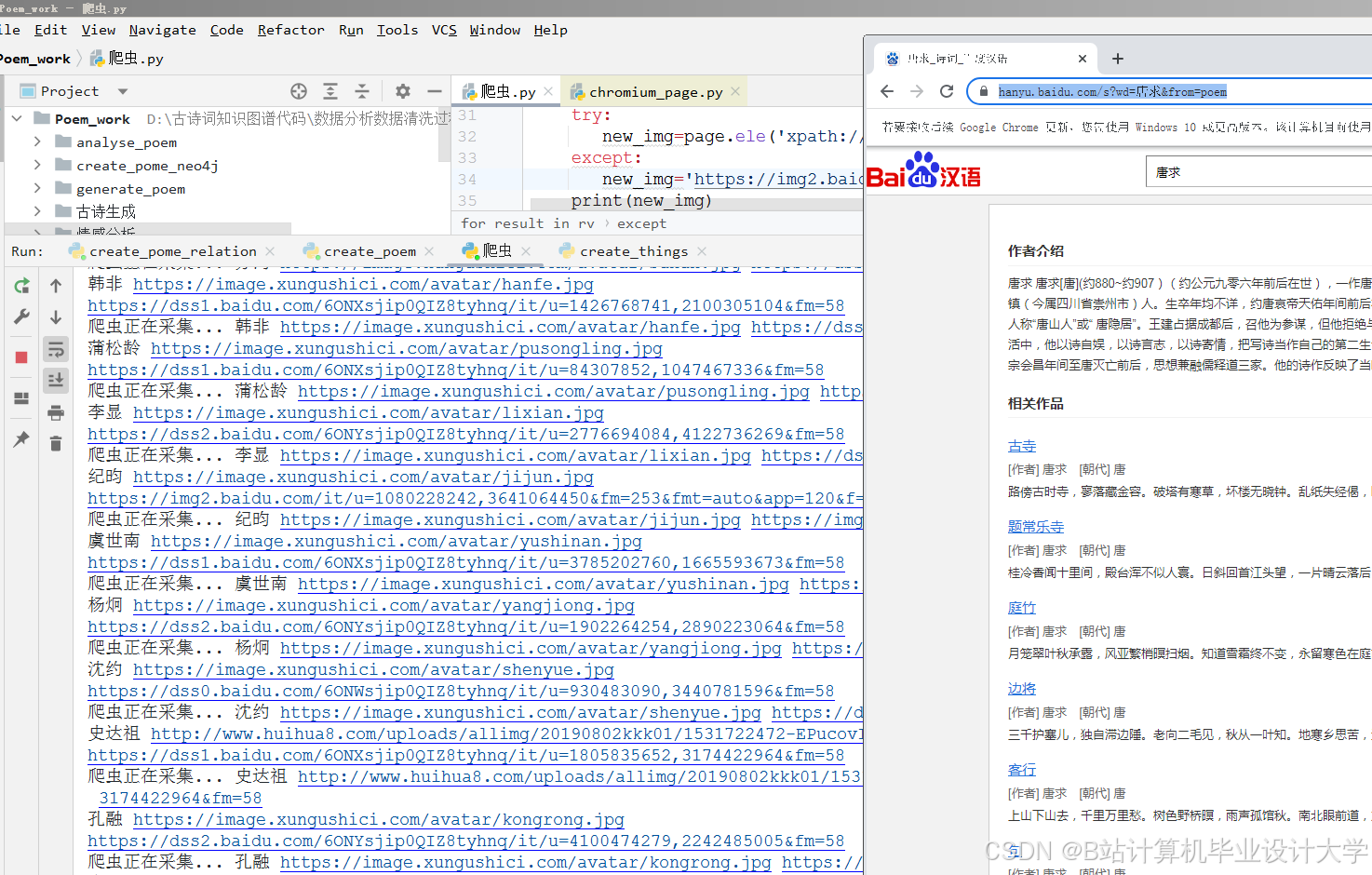
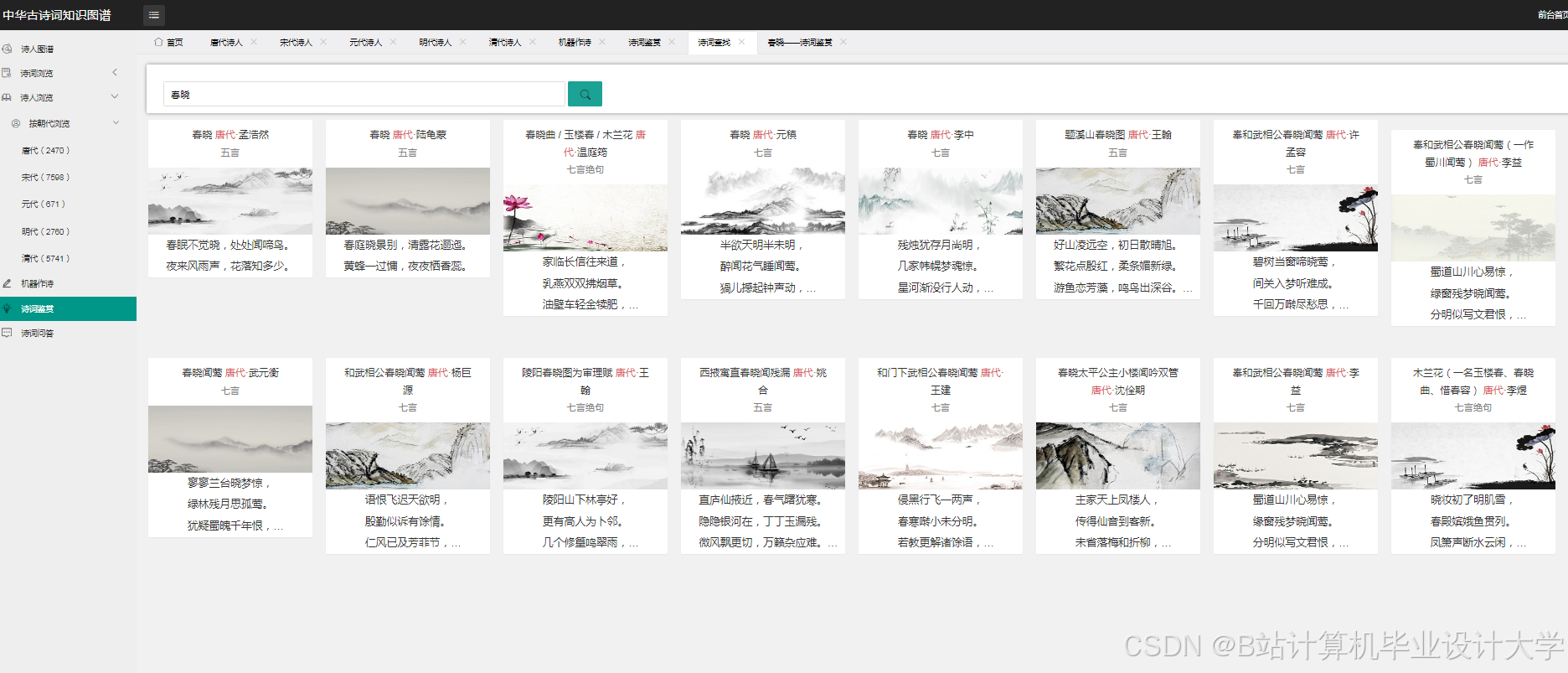
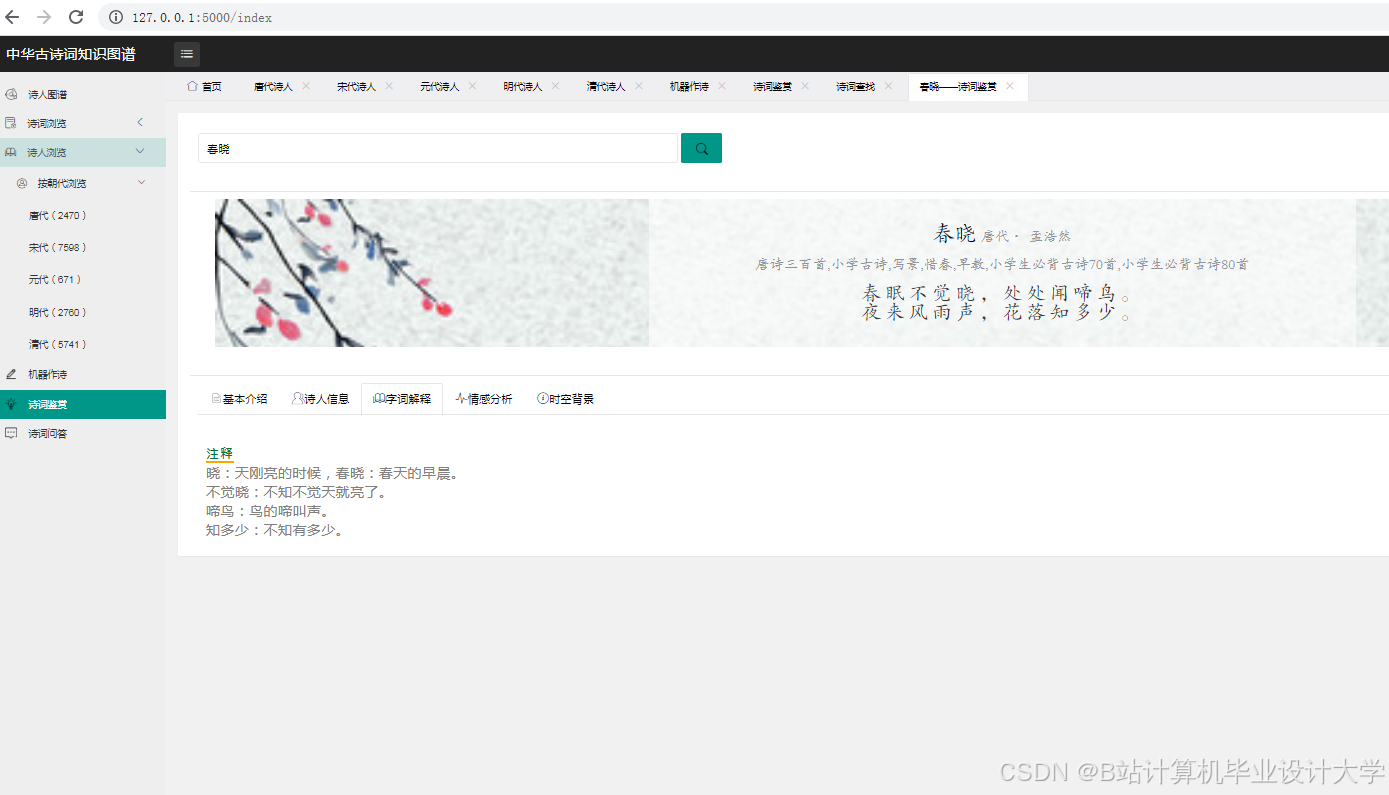
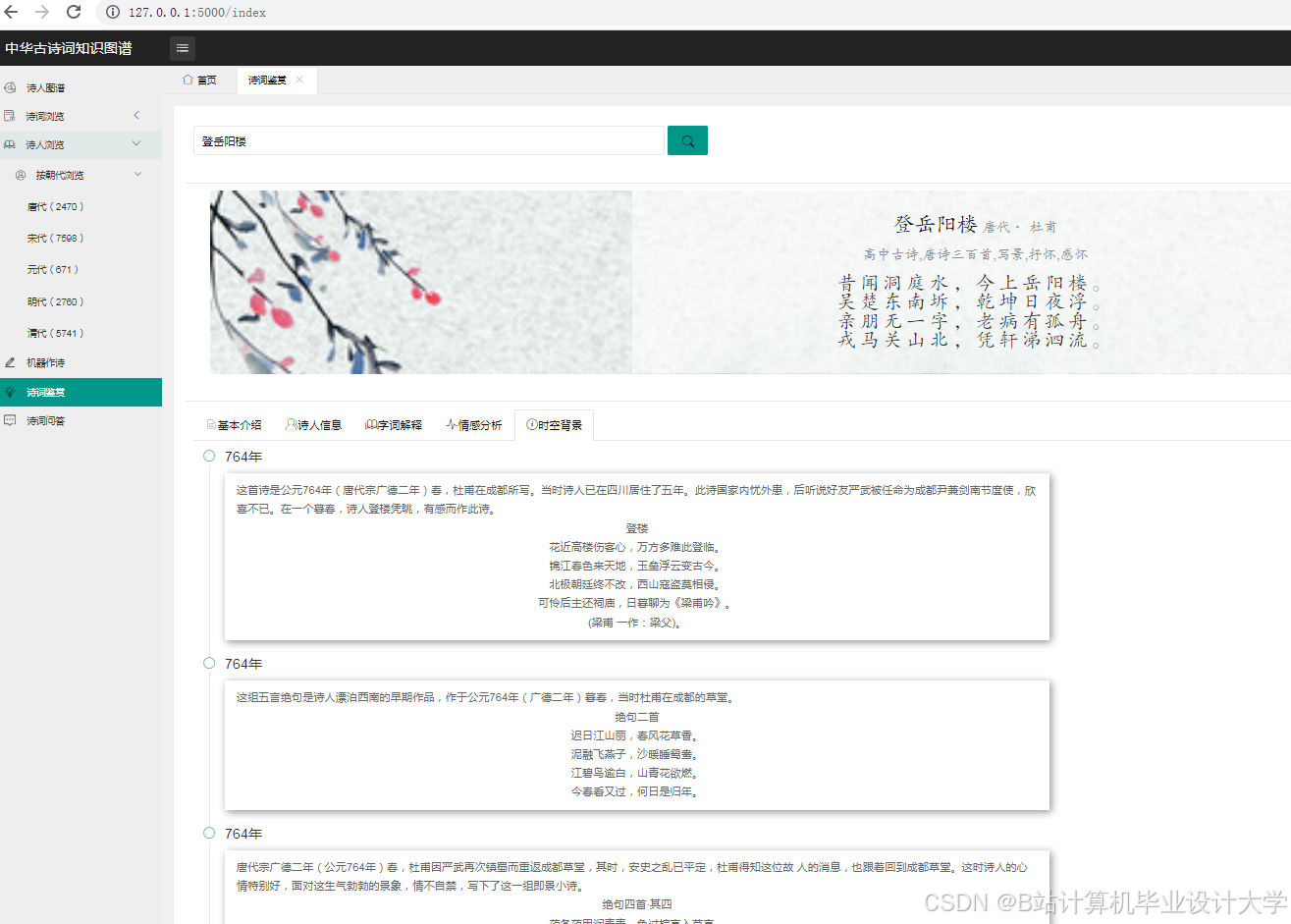
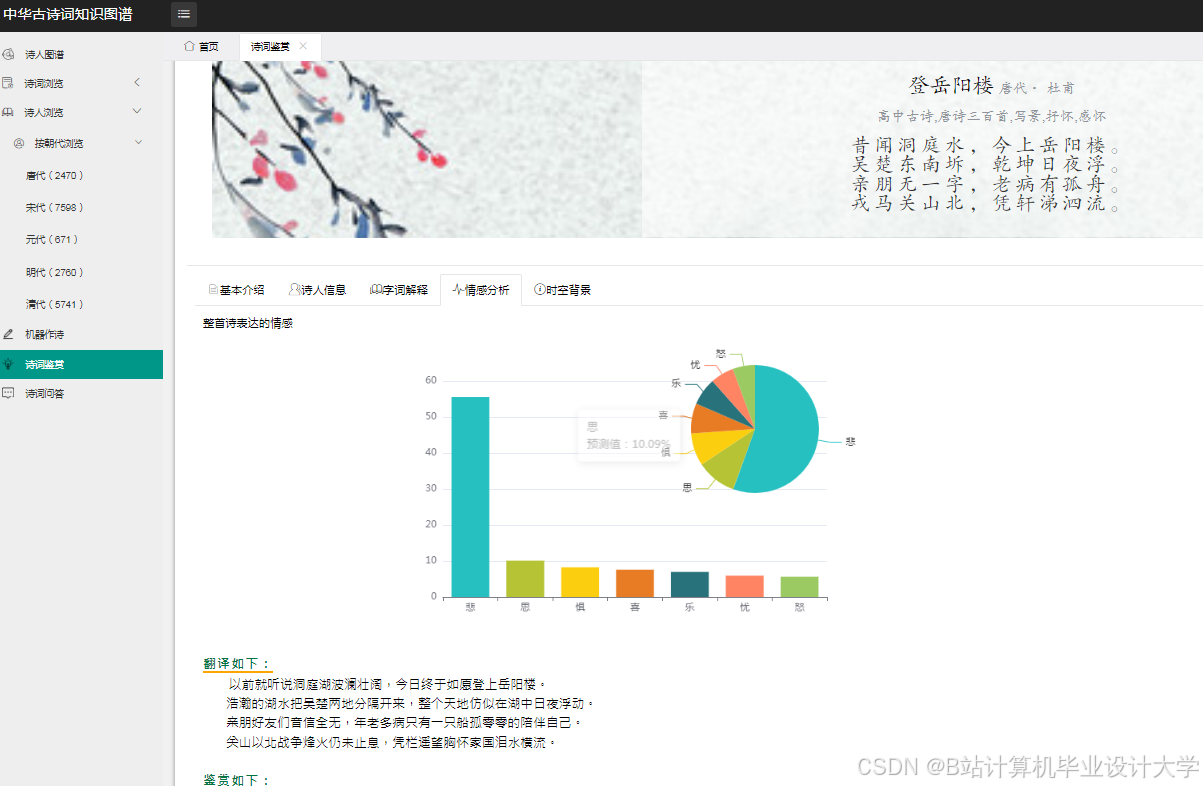
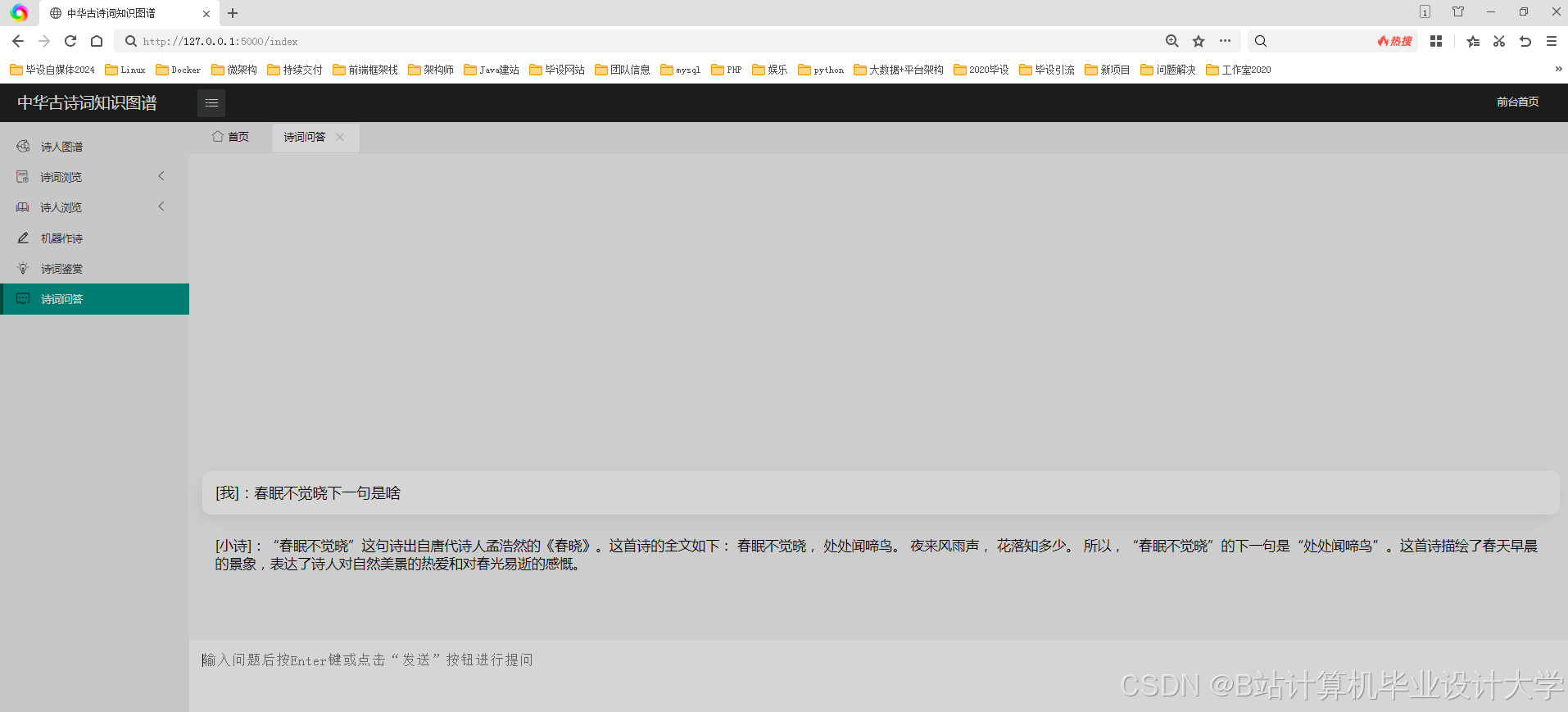
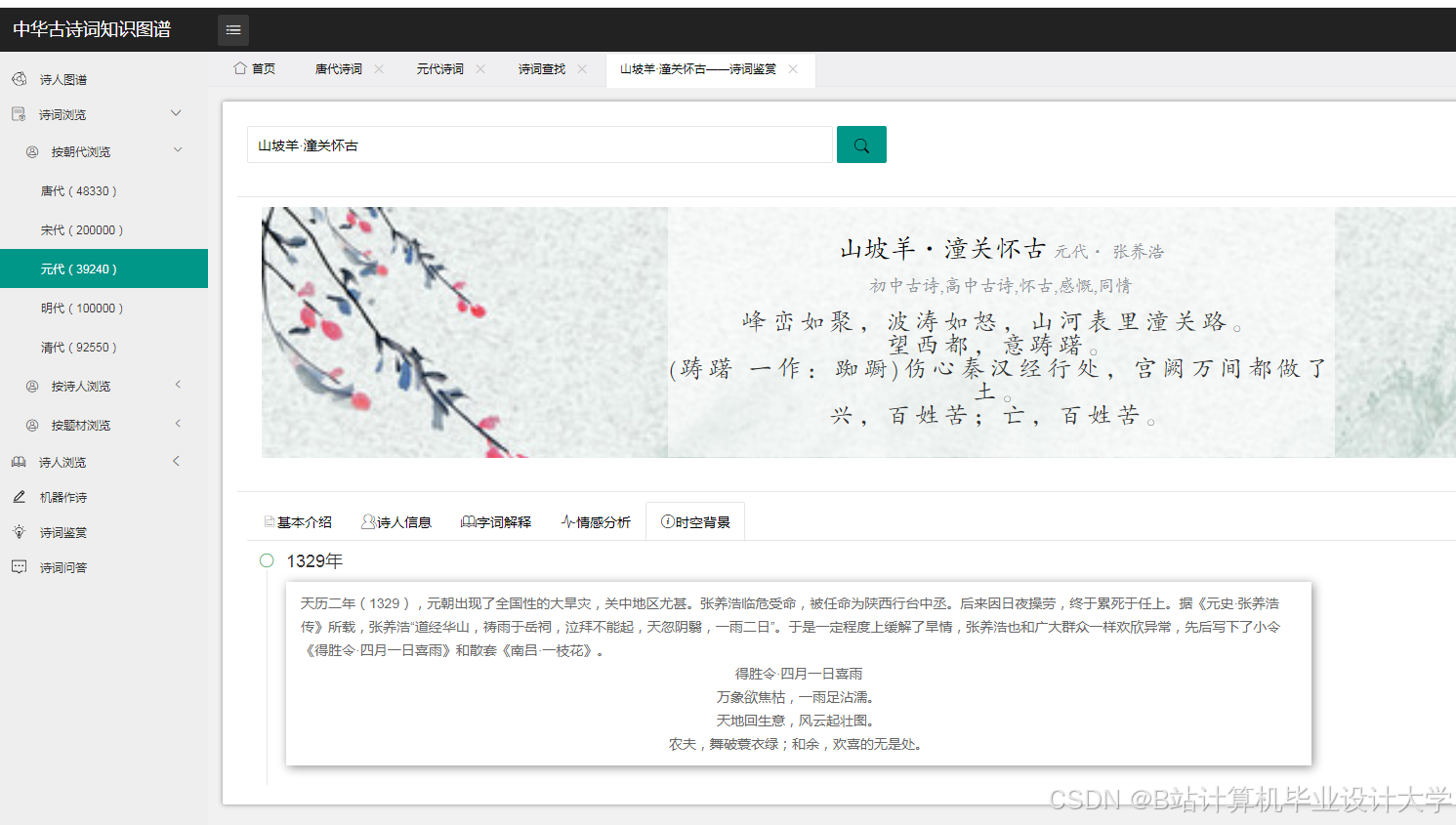
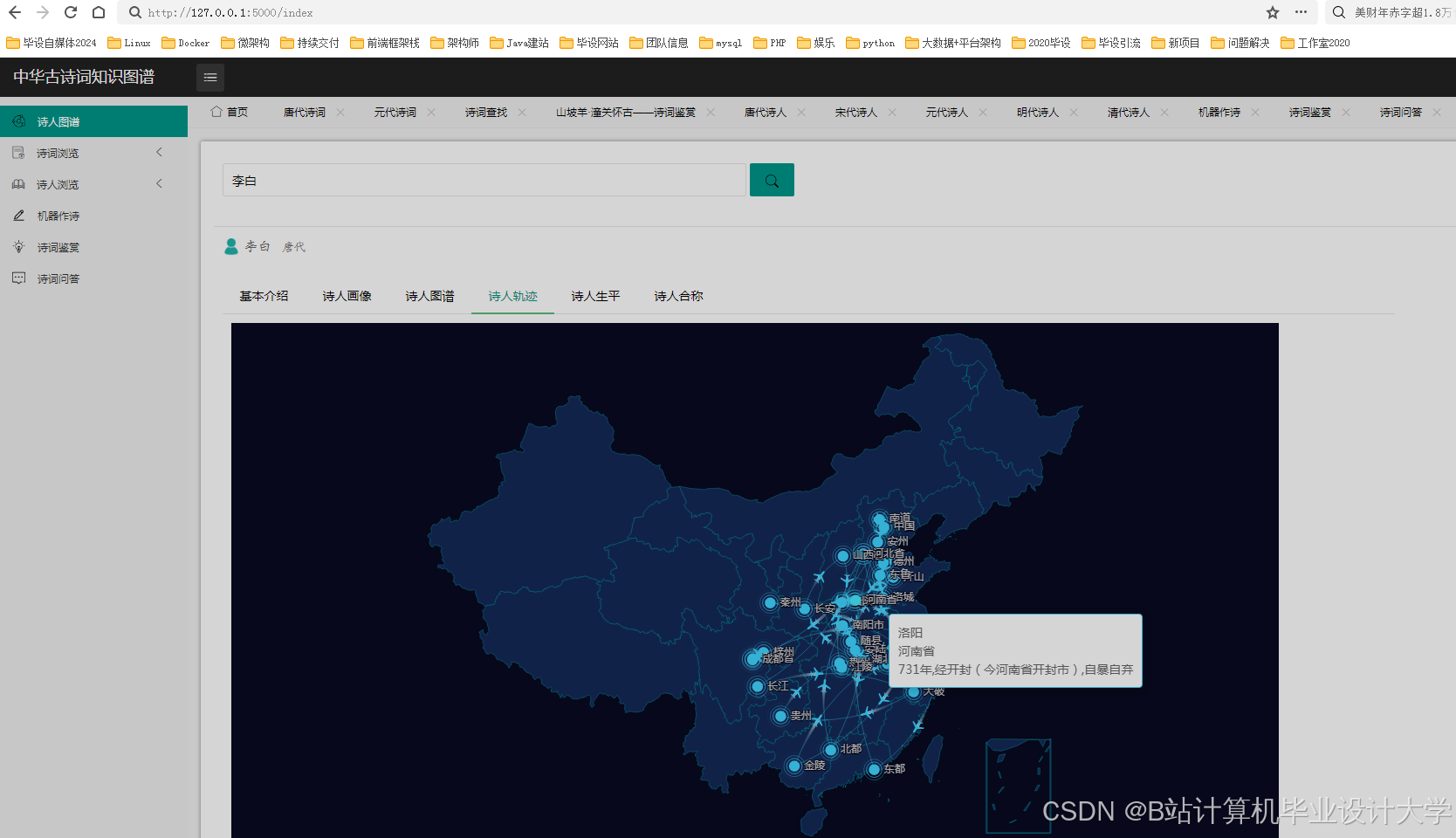
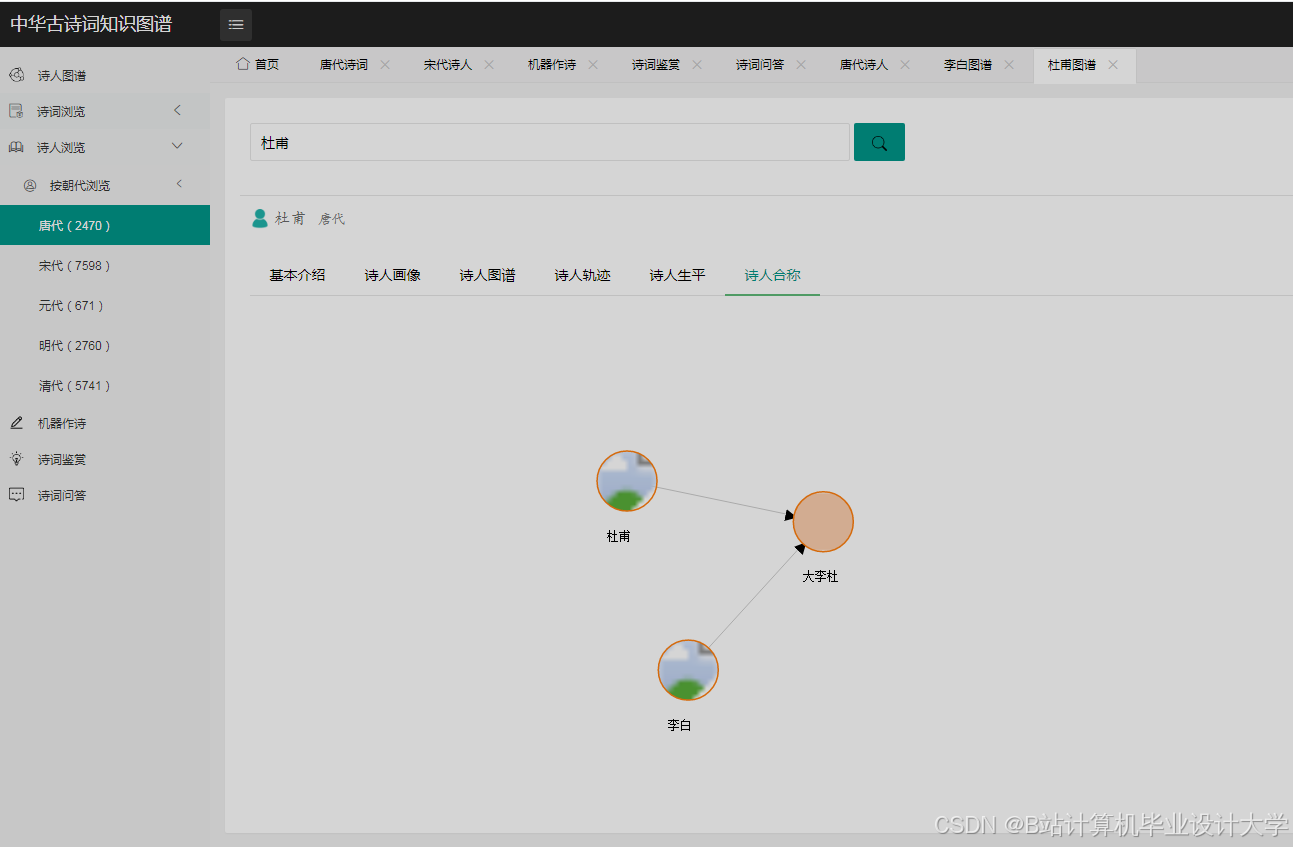
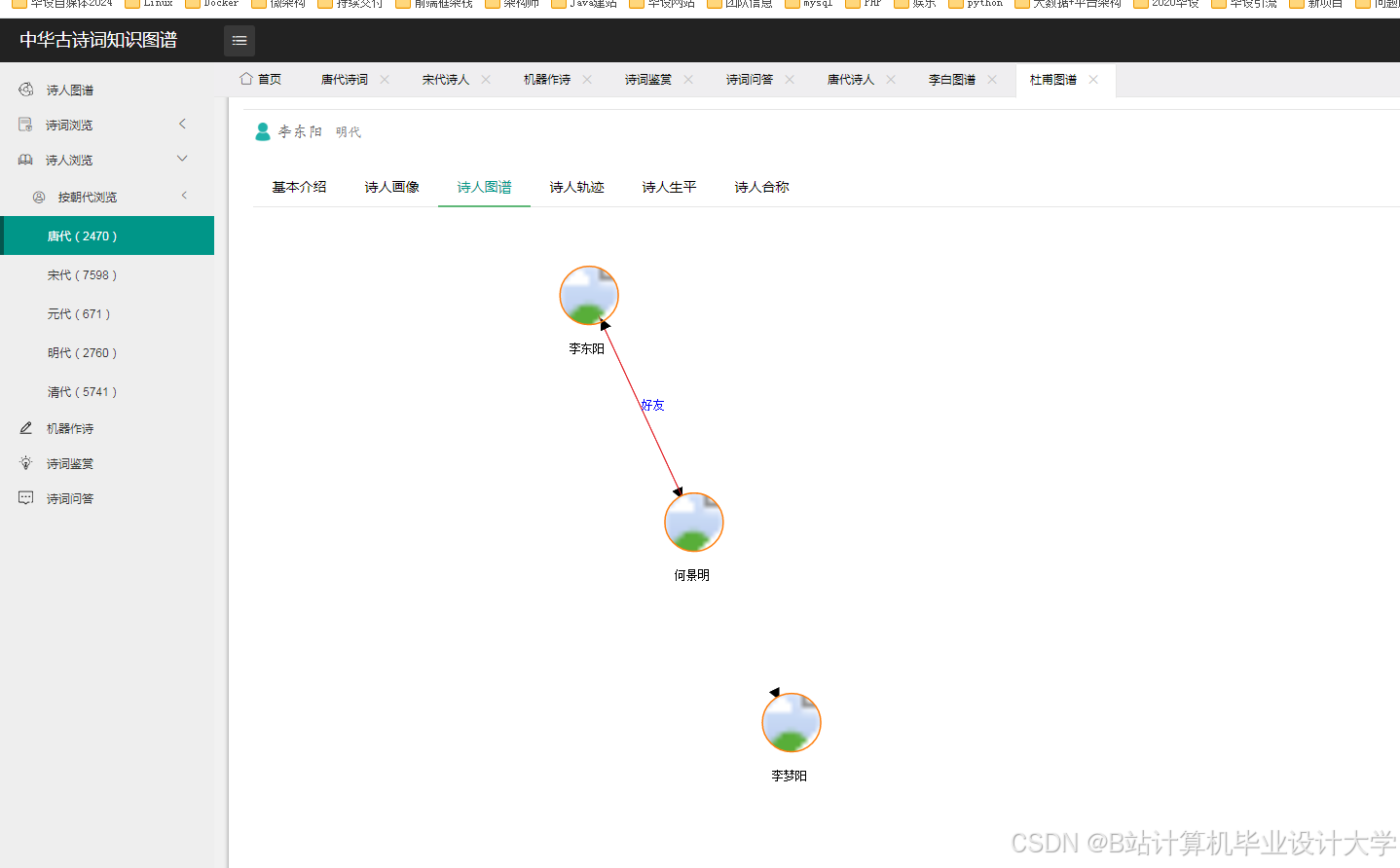
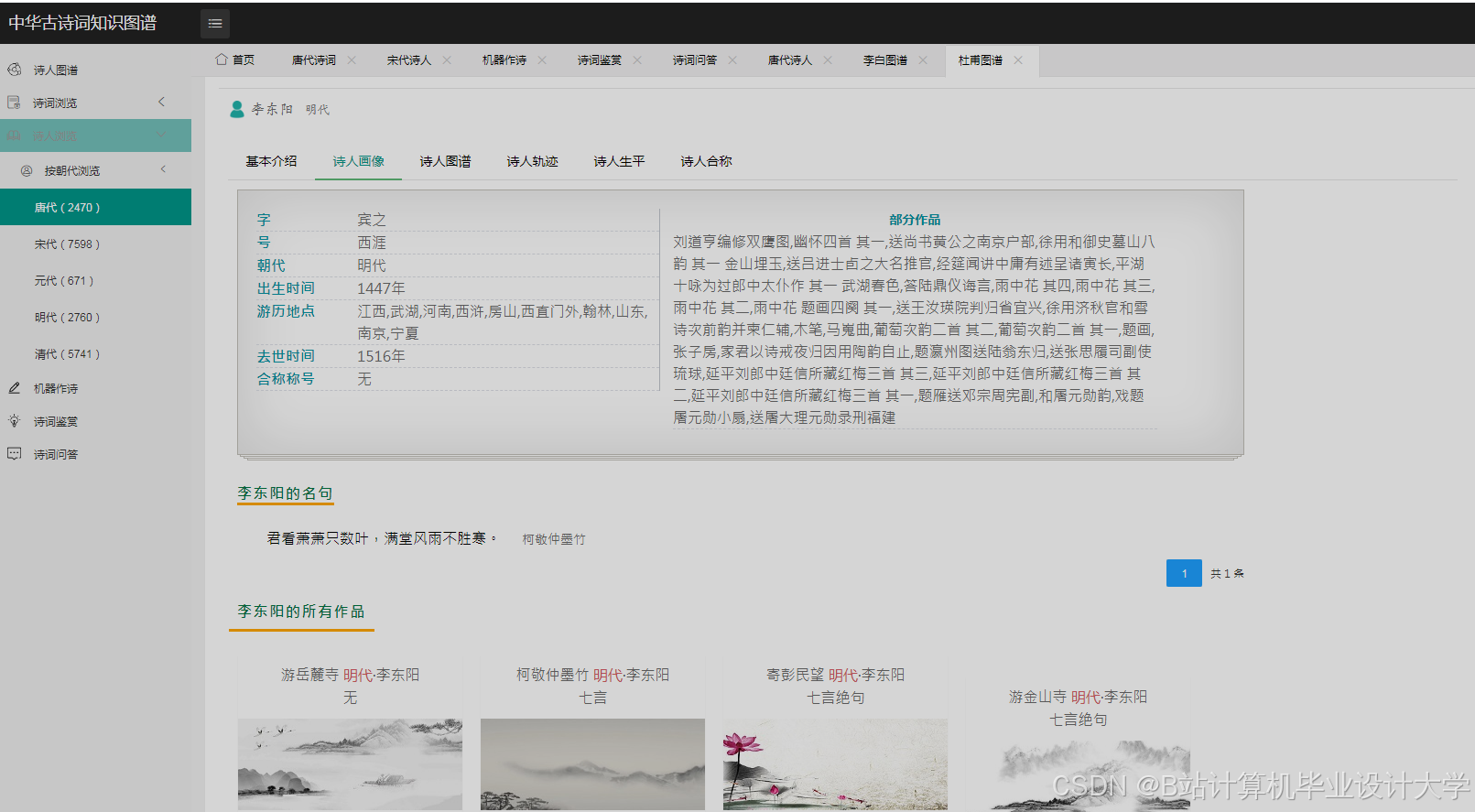
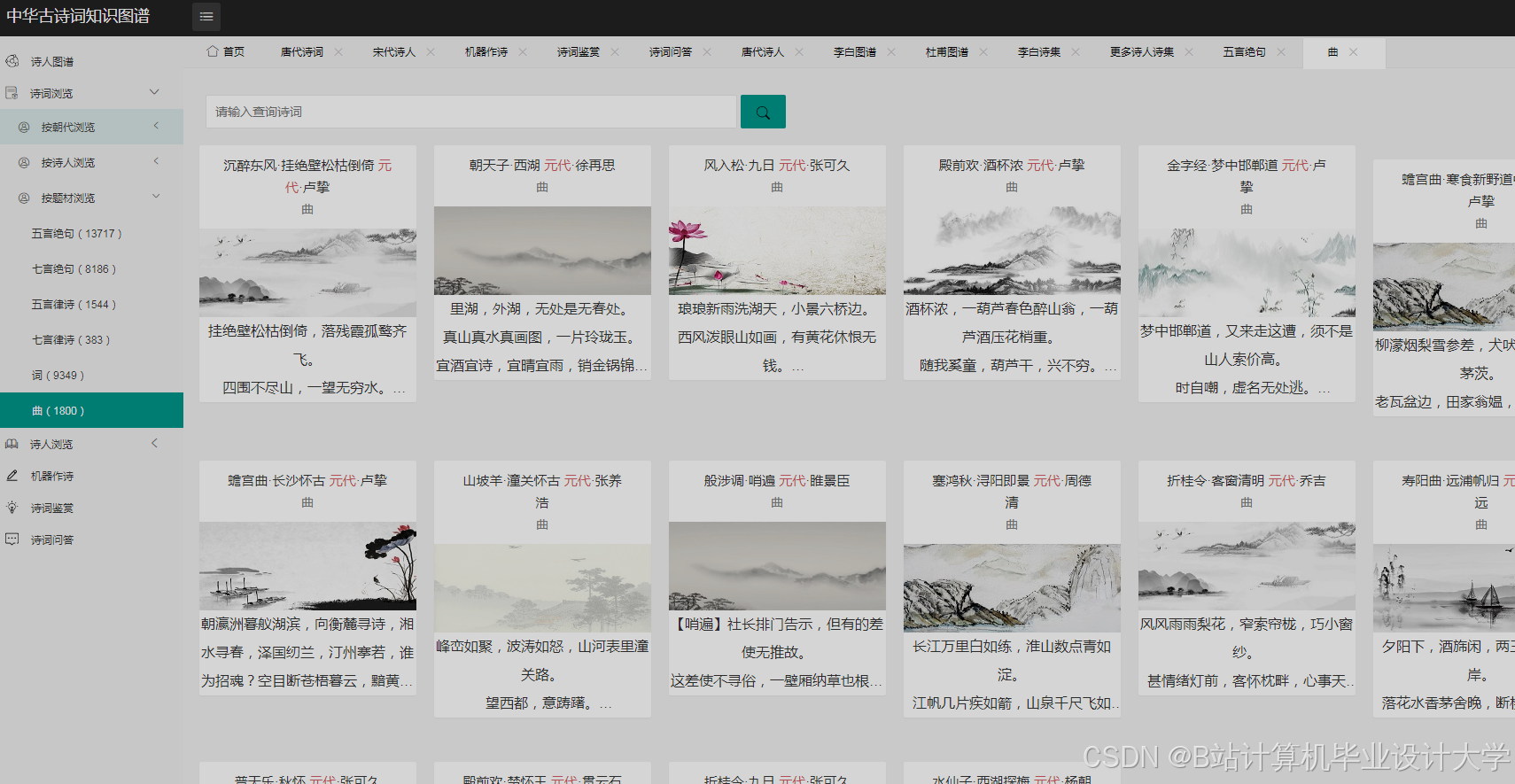
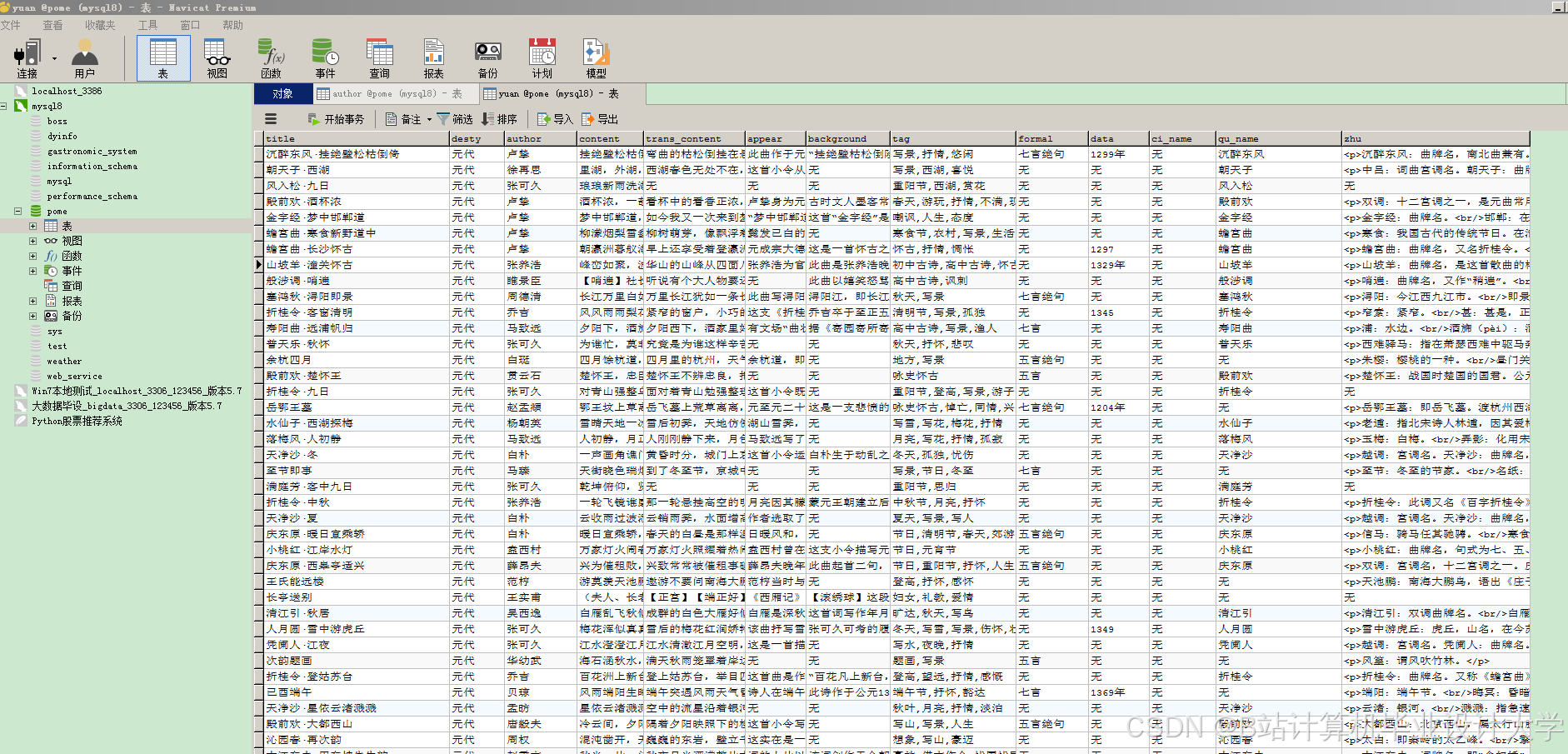
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











