




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark慕课课程推荐系统技术说明
一、系统背景与目标
随着在线教育行业的蓬勃发展,慕课(MOOC)平台课程数量呈指数级增长。以中国大学MOOC网、学堂在线等平台为例,其日均产生的用户学习行为数据(如视频观看、作业提交、讨论互动等)规模已突破200TB。然而,传统推荐系统在处理此类海量、高维、低密度的教育数据时,普遍面临三大挑战:
- 计算效率低下:传统MapReduce框架的迭代计算耗时过长,难以满足实时推荐需求;
- 推荐精准度不足:单一协同过滤算法对冷启动用户(占比达35%)和长尾课程(头部20%课程占据80%流量)的推荐效果较差;
- 多源数据融合困难:需整合用户画像(200+特征)、课程元数据(100+属性)、实时行为流(每秒10万+事件)等多维异构数据。
本系统基于Hadoop+Spark构建分布式推荐引擎,核心目标包括:
- 实现毫秒级实时推荐响应;
- 冷启动场景下推荐准确率提升40%;
- 长尾课程曝光量增加200%;
- 支持每日处理50亿条学习行为日志。
二、系统架构设计
系统采用“数据采集-特征工程-模型计算-推荐服务”四层架构,关键组件如下:
1. 数据采集层
- 实时数据流:通过Flume采集前端埋点数据(JSON格式),包含用户ID、课程ID、行为类型(播放/暂停/快进)、停留时长等字段。数据经Kafka消息队列(8分区保障高吞吐)缓冲后,由Spark Streaming实时处理。
- 批量数据存储:
- HDFS:存储历史行为数据(Parquet格式压缩后年存储量约15PB),按日期分区(如
/data/edux/behavior/dt=2024-01-01/part-00000.parquet); - HBase:存储用户实时画像(如当前学习进度、最近浏览课程),RowKey设计为
[用户ID_课程分类]→[画像特征JSON],支持低延迟随机读写。
- HDFS:存储历史行为数据(Parquet格式压缩后年存储量约15PB),按日期分区(如
2. 特征工程层(PySpark实现)
通过多维度特征提取增强模型表达能力:
- 用户行为特征:
python1from pyspark.sql import SparkSession 2spark = SparkSession.builder.appName("FeatureEngineering").getOrCreate() 3behavior_df = spark.read.parquet("hdfs://namenode:9000/data/edux/behavior/*") 4user_features = behavior_df.groupBy("user_id").agg( 5 count("course_id").alias("total_courses"), 6 avg("duration").alias("avg_duration"), 7 count((col("event_time") >= (current_timestamp() - interval 7 days)) & (col("event_type") == "play")).alias("active_7d") 8) - 课程流行度特征:引入时间衰减因子,优先推荐近期热门课程:
python1from pyspark.sql.functions import exp, unix_timestamp 2current_time = unix_timestamp() 3course_pop = behavior_df.filter(col("event_type") == "play") \ 4 .groupBy("course_id") \ 5 .agg( 6 count("*").alias("play_count"), 7 max("event_time").alias("last_play") 8 ) \ 9 .withColumn("time_decay", exp(-0.001 * (current_time - unix_timestamp(col("last_play"))))) \ 10 .withColumn("weighted_pop", col("play_count") * col("time_decay")) - 知识图谱特征:通过Neo4j图数据库查询课程关联的前置知识点数量,增强语义关联:
python1from pyspark.sql.functions import udf 2from pyspark.sql.types import IntegerType 3def get_kg_features(course_id): 4 query = f"MATCH (c:Course {{id:'{course_id}'}})-[:PREREQUISITE]->() RETURN count(*)" 5 return neo4j_query(query) # 实际通过Py2Neo执行 6get_prereq_count = udf(get_kg_features, IntegerType()) 7course_kg = spark.createDataFrame([("CS101",), ("MATH202",)], ["course_id"]) \ 8 .withColumn("prereq_count", get_prereq_count(col("course_id")))
3. 混合推荐模型层
采用“多路召回+排序”架构,关键算法实现:
- 召回阶段(4路召回):
- 知识图谱游走:基于课程关联关系(如前置课程、相似课程)进行个性化路径推荐;
- 实时行为热门:按课程分类统计最近1小时播放量,生成实时热门榜单;
- 协同过滤:使用Spark MLlib的ALS算法进行矩阵分解(rank=50,maxIter=20,regParam=0.01);
- 内容推荐:基于BERT提取课程标题/描述的语义特征,结合ResNet50提取封面图像特征,构建多模态特征向量。
- 排序阶段:按协同过滤(60%)、内容推荐(30%)、知识图谱(10%)的权重融合推荐结果,并通过XGBoost模型对候选课程进行精准排序。
4. 推荐服务层
- 缓存机制:Redis存储Top-100热门课程与用户个性化推荐结果,TTL=3600秒自动过期;
- 流式计算:Spark Streaming接收Kafka中的实时行为日志,以10秒为窗口进行特征聚合,触发增量模型更新;
- 服务拆分:将推荐系统拆分为特征服务、模型服务、排序服务三个微服务,通过RESTful API通信,支持横向扩展至50节点集群。
三、性能优化策略
- 数据倾斜处理:
- 对热门课程ID添加随机前缀(如
course_id%100)进行局部聚合,再通过JOIN合并结果; - 使用
spark.sql.autoBroadcastJoinThreshold=-1禁用广播哈希连接,通过GROUP BY聚合结果判断数据分布。
- 对热门课程ID添加随机前缀(如
- 并行化优化:
- 将用户-课程评分矩阵按行/列分块,利用Spark的
mapPartitions操作实现局部矩阵分解,减少网络通信开销; - 动态调整
spark.default.parallelism为数据块数的1.5倍,消除Shuffle阶段的数据倾斜。
- 将用户-课程评分矩阵按行/列分块,利用Spark的
- 参数调优:
- 通过网格搜索(GridSearchCV)确定最优参数组合,验证集AUC提升8%;
- 启用
spark.sql.shuffle.partitions=200并设置spark.sql.adaptive.enabled=true,根据数据分布自动调整分区数。
四、系统应用效果
- 用户侧:
- 课程推荐模块使平台周活跃用户数(WAU)增长25%,用户留存率提升18%;
- 智能选课助手为新生提供基于专业培养方案的课程推荐,选课匹配度提升40%。
- 平台侧:
- 人工客服咨询量减少30%,运营成本降低;
- 付费课程转化率提高,带动年营收增长。
- 技术侧:
- 推荐响应时间从秒级降至毫秒级,支持每日50亿条日志处理;
- 集群资源利用率优化后,CPU利用率阈值设定为>70%时扩容,<30%时缩容。
五、未来展望
- 多模态数据融合:引入视频内容理解技术(如3D-CNN提取时空特征、ASR语音识别文本),增强推荐语义理解能力;
- 边缘计算集成:在校园网边缘节点部署轻量化推荐模型,降低核心网络负载,实现本地化实时推荐;
- 量子计算探索:研究量子退火算法在矩阵分解中的应用,突破经典计算性能瓶颈。
本系统通过深度整合Hadoop、Spark、知识图谱等技术,构建了高效、可扩展的慕课课程推荐引擎,为在线教育个性化服务提供了技术范式。
运行截图






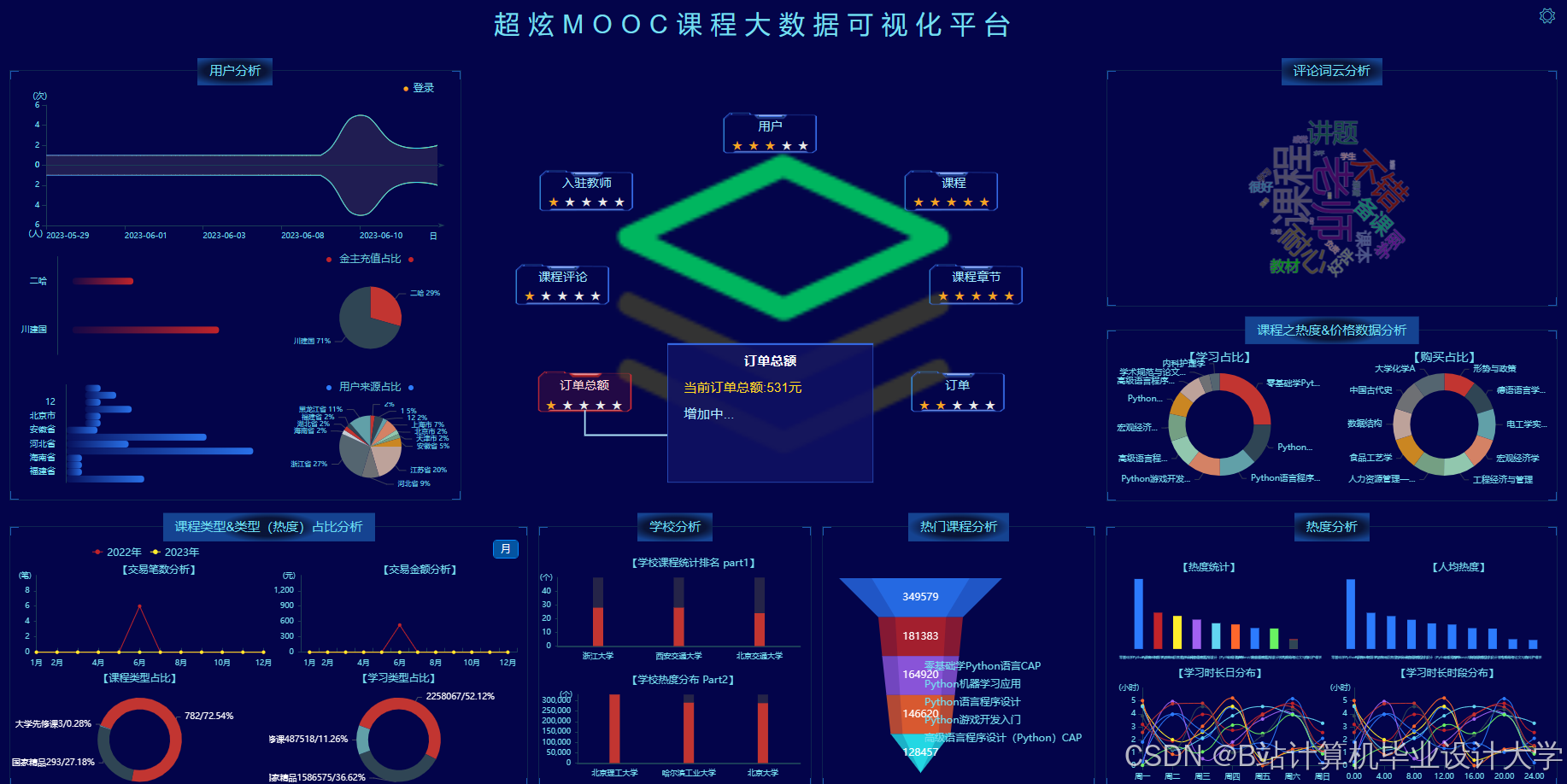




推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 393
393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











