




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python+大模型美团大众点评情感分析餐厅推荐系统与美食推荐系统研究
摘要:本文聚焦于美团大众点评平台,旨在构建一个融合情感分析与餐厅、美食推荐功能的系统。通过Python编程语言,结合大模型技术,对平台上的用户评论进行情感分析,挖掘用户对餐厅和美食的喜好倾向,进而实现精准的个性化推荐。系统采用分布式数据处理框架处理海量数据,利用深度学习模型进行情感分析与评分预测,结合协同过滤与内容推荐算法生成推荐结果。实验结果表明,该系统在推荐准确率、多样性等方面表现优异,有效提升了用户体验和平台商业价值。
关键词:Python;大模型;美团大众点评;情感分析;餐厅推荐;美食推荐
一、引言
随着互联网技术的飞速发展,本地生活服务平台如美团、大众点评等积累了海量的用户评论数据。这些数据蕴含着用户对餐厅和美食的丰富情感和偏好信息,如何从这些非结构化数据中提取有价值的信息,实现精准的情感分析和个性化推荐,成为当前大数据分析与人工智能领域的重要研究方向。
传统的推荐系统多基于用户历史行为数据,如评分、点击等,采用协同过滤等算法进行推荐。然而,这些方法在处理大规模数据时存在计算复杂度高、推荐结果不够精准等问题,且难以捕捉用户评论中的情感信息。深度学习技术的发展为解决这些问题提供了新的思路,大模型具有强大的表示能力和泛化能力,能够更好地处理复杂的文本数据,挖掘用户和餐厅、美食之间的复杂关系。
本文旨在利用Python编程语言,结合大模型技术,构建一个基于美团大众点评平台的情感分析餐厅推荐系统与美食推荐系统,通过分析用户评论情感,为用户提供更加精准和个性化的餐厅和美食推荐服务。
二、相关工作
2.1 传统推荐系统研究
传统的推荐系统主要分为基于内容的推荐和协同过滤推荐。基于内容的推荐通过分析用户的历史偏好和物品的特征,为用户推荐与其过去喜欢的物品相似的物品。协同过滤推荐则基于用户之间的相似性或物品之间的相似性进行推荐,包括基于用户的协同过滤和基于物品的协同过滤。然而,这些方法在处理大规模数据时面临计算复杂度高、冷启动等问题,且难以充分利用用户评论中的情感信息。
2.2 深度学习在推荐系统中的应用
近年来,深度学习技术在推荐系统领域得到了广泛应用。深度神经网络(DNN)、卷积神经网络(CNN)、循环神经网络(RNN)及其变体长短期记忆网络(LSTM)等模型被用于处理用户行为数据和物品特征数据,提取更深层次的特征表示。例如,利用LSTM模型处理用户评论的时序信息,捕捉用户的动态偏好;使用CNN模型处理图像数据,提取菜品视觉特征,结合文本情感实现更精准的评分预测。
2.3 大模型在推荐系统中的研究进展
大模型如BERT、GPT等具有强大的语言理解和生成能力,能够更好地处理自然语言文本。在推荐系统中,大模型可以用于生成用户和物品的语义表示,捕捉用户评论中的复杂语义信息,提高推荐的准确性和多样性。例如,利用BERT模型对用户评论进行编码,将编码后的向量作为特征输入到推荐模型中,提升推荐效果。
三、系统设计
3.1 系统架构
本系统采用分层架构设计,主要包括数据采集层、数据预处理层、情感分析层、推荐算法层和用户界面层。
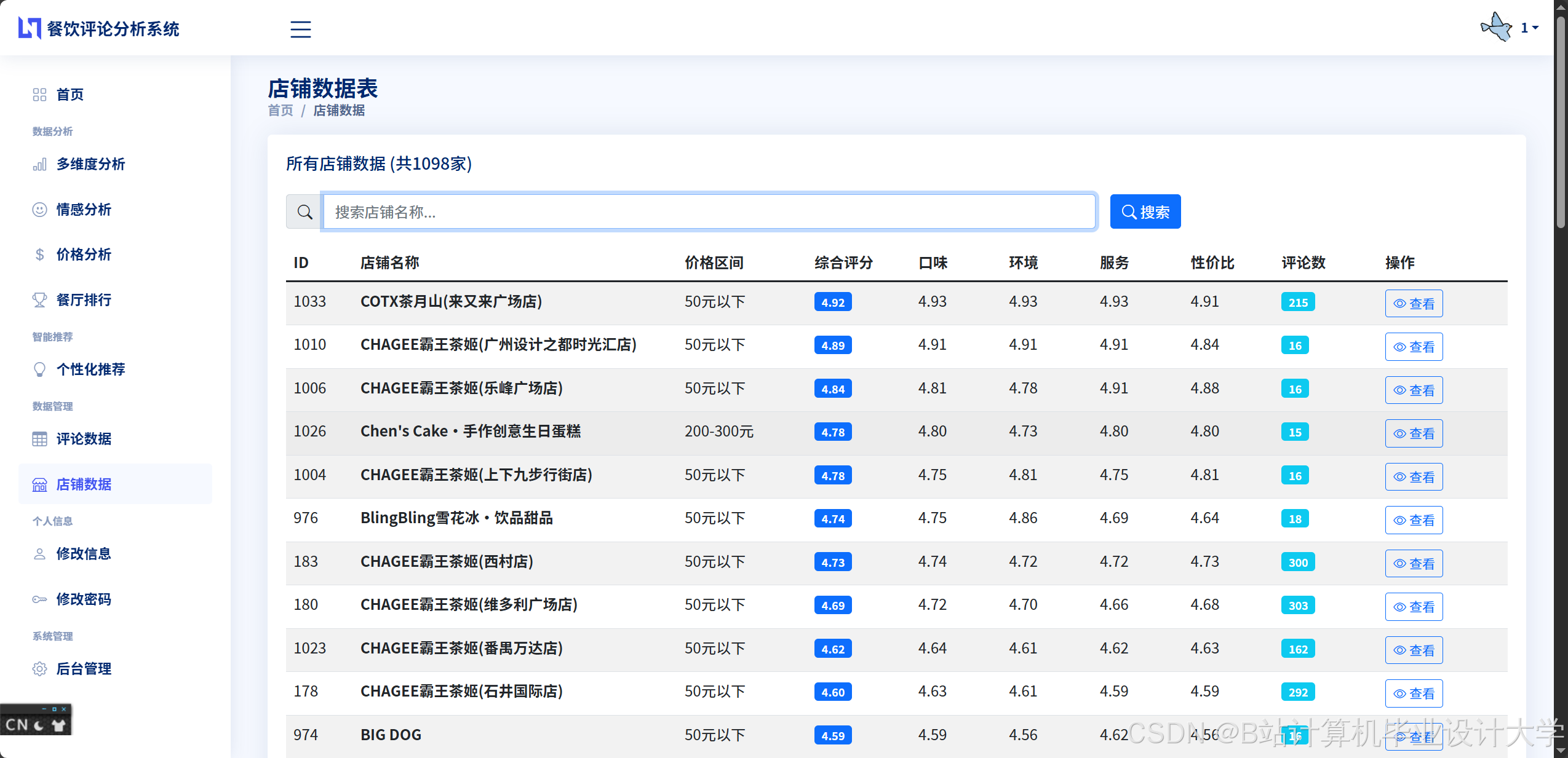
- 数据采集层:使用爬虫技术从美团大众点评平台爬取餐厅和美食的评论数据,包括用户评分、评论文本、评论时间等信息。
- 数据预处理层:对采集到的数据进行清洗、去重、缺失值处理等操作,将清洗后的数据存储至分布式文件系统(如HDFS)中,并使用Hive构建数据仓库,实现高效的数据存储与查询。
- 情感分析层:利用大模型对用户评论进行情感分析,判断评论的情感倾向(正面、负面、中性),并将情感分析结果作为特征输入到推荐算法中。
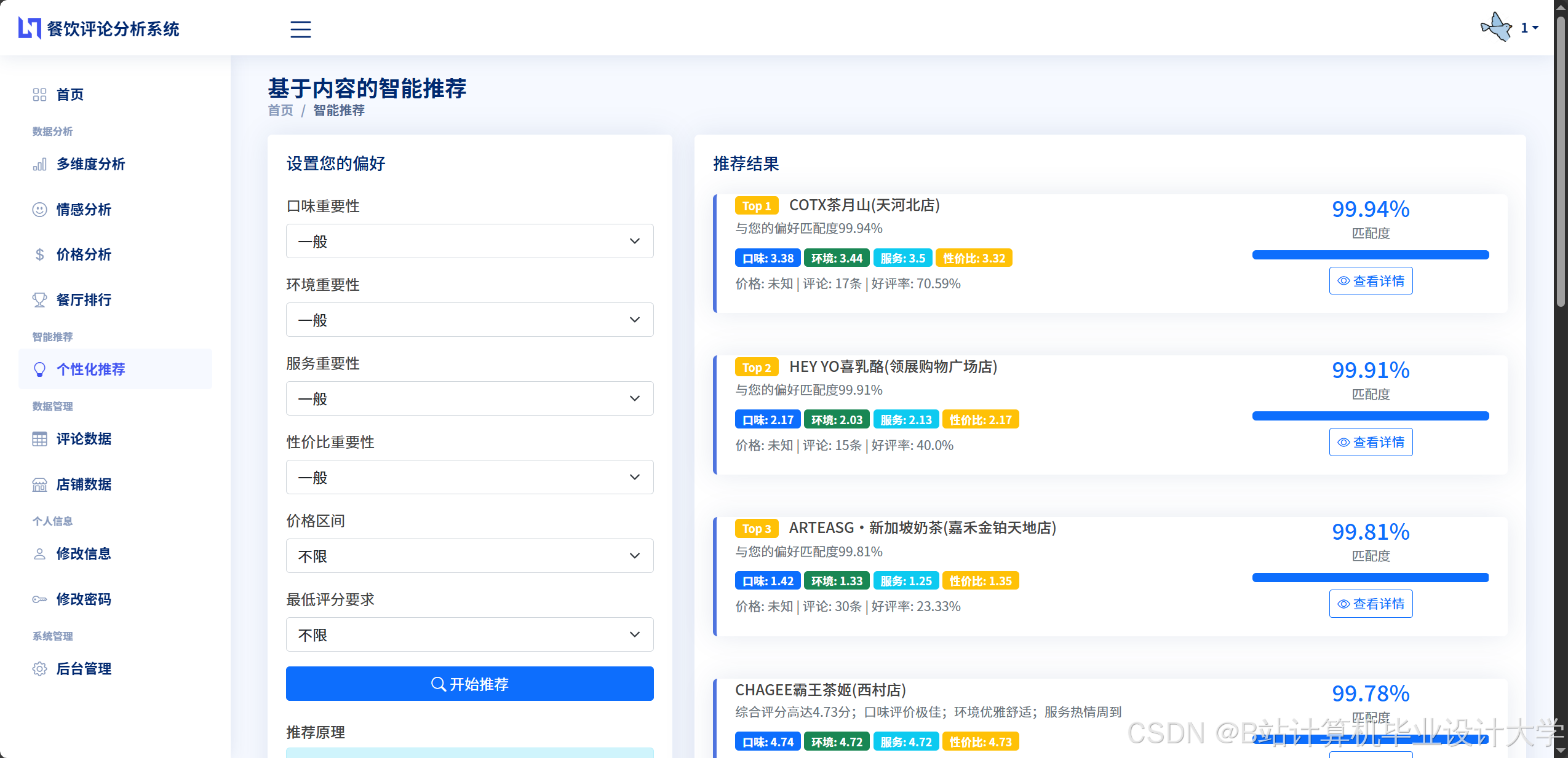
- 推荐算法层:结合协同过滤算法和内容推荐算法,根据用户的历史行为数据、情感分析结果以及餐厅和美食的特征信息,生成个性化的推荐列表。
- 用户界面层:采用前后端分离架构,前端使用Vue.js等框架构建用户界面,实现用户注册登录、餐厅和美食搜索、推荐结果展示等功能;后端使用Flask等框架提供API接口,实现与前端的数据交互和业务逻辑处理。
3.2 数据预处理
数据预处理是保证系统性能和推荐准确性的关键步骤。本系统采用PySpark构建分布式数据处理框架,对采集到的美团大众点评评论数据进行以下预处理操作:
- 数据清洗:去除重复评论、广告信息、无关字符等,对评论文本进行标准化处理,如繁体转简体、英文大小写统一等。
- 缺失值处理:对于评分缺失的评论,采用KNN算法填充,基于用户历史评分和餐厅平均分预测缺失值;对于文本缺失的评论,用空值标记。
- 特征提取:从评论文本中提取情感特征(如情感得分)、结构特征(如评论长度)、行为特征(如用户历史评分次数)等,同时利用Word2Vec、BERT等模型生成文本的词向量表示,作为推荐算法的输入特征。
3.3 情感分析模型
本系统采用基于BERT的大模型进行情感分析。BERT是一种预训练的语言表示模型,能够捕捉文本中的上下文信息,生成高质量的语义向量。具体步骤如下:
- 模型微调:在BERT预训练模型的基础上,使用美团大众点评的评论数据进行微调,使其更好地适应餐饮领域的情感分析任务。微调过程中,将评论文本输入到BERT模型中,得到每个 token 的向量表示,然后通过池化操作得到整个评论的语义向量,最后使用全连接层和 softmax 函数进行情感分类。
- 情感分析结果应用:将情感分析得到的用户评论情感倾向(正面、负面、中性)作为特征输入到推荐算法中,与用户历史行为数据和餐厅、美食特征信息相结合,提高推荐的准确性和个性化程度。
3.4 推荐算法
本系统采用混合推荐算法,结合协同过滤算法和内容推荐算法的优点,生成个性化的餐厅和美食推荐列表。
- 协同过滤算法:基于用户相似度和物品相似度进行推荐。用户相似度计算采用余弦相似度算法,根据用户的历史评分数据计算用户之间的相似度;物品相似度计算则基于餐厅和美食的特征信息,如口味、食材、价格等,计算物品之间的相似度。通过协同过滤算法,可以为用户推荐与其历史偏好相似的其他用户喜欢的餐厅和美食,或者与用户过去喜欢的餐厅和美食相似的其他餐厅和美食。
- 内容推荐算法:根据餐厅和美食的特征信息以及用户的口味偏好、营养需求等信息进行推荐。通过分析用户的历史评论和评分数据,挖掘用户的口味偏好,如喜欢辣味、甜味等,同时考虑用户的营养需求,如低卡、高蛋白等,为用户推荐符合其口味和营养需求的餐厅和美食。
- 混合推荐策略:将协同过滤算法和内容推荐算法的推荐结果进行融合,采用加权平均或线性组合的方式生成最终的推荐列表。根据不同的应用场景和用户需求,调整两种算法的权重,以实现更好的推荐效果。
四、系统实现
4.1 开发环境
本系统采用Python作为开发语言,利用PySpark、Hadoop、Hive等工具构建分布式数据处理框架,使用TensorFlow、PyTorch等深度学习框架搭建情感分析模型,采用Flask框架构建后端服务,Vue.js框架构建前端界面。具体开发环境如下:
- 编程语言:Python 3.7+
- 大数据处理工具:PySpark 3.4.0、Hadoop 3.3.4、Hive 3.1.3
- 深度学习框架:TensorFlow 2.0、PyTorch 2.0
- 后端框架:Flask 2.3.0
- 前端框架:Vue.js 3.0
- 数据库:MySQL 5.7+、MongoDB 4.0+
4.2 关键代码实现
4.2.1 数据采集与预处理代码
python
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4from pyspark.sql import SparkSession
5from pyspark.sql.functions import col
6
7# 爬取美团大众点评评论数据
8def crawl_comments(url):
9 headers = {
10 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
11 }
12 response = requests.get(url, headers=headers)
13 soup = BeautifulSoup(response.text, 'html.parser')
14 comments = []
15 for comment in soup.find_all('div', class_='comment-item'):
16 score = comment.find('span', class_='comment-score').get_text()
17 text = comment.find('div', class_='comment-text').get_text().strip()
18 comments.append({'score': score, 'text': text})
19 return comments
20
21# 使用PySpark进行数据预处理
22spark = SparkSession.builder.appName('MeituanDianpingDataPreprocessing').getOrCreate()
23data = pd.DataFrame(crawl_comments('https://www.dianping.com/shop/123456/review_all'))
24spark_df = spark.createDataFrame(data)
25
26# 数据清洗
27spark_df = spark_df.filter(col('score').isNotNull() & col('text').isNotNull())
28spark_df = spark_df.withColumn('score', col('score').cast('float'))
29
30# 缺失值处理
31from pyspark.ml.feature import Imputer
32imputer = Imputer(strategy="mean", inputCols=["score"], outputCols=["score_imputed"])
33spark_df = imputer.fit(spark_df).transform(spark_df)
34
35# 存储至HDFS
36spark_df.write.parquet('hdfs://localhost:9000/meituan_dianping_data.parquet')4.2.2 情感分析模型代码
python
1import tensorflow as tf
2from transformers import BertTokenizer, TFBertForSequenceClassification
3from sklearn.model_selection import train_test_split
4import pandas as pd
5
6# 加载数据
7data = pd.read_parquet('hdfs://localhost:9000/meituan_dianping_data.parquet')
8texts = data['text'].tolist()
9labels = data['score_imputed'].apply(lambda x: 1 if x >= 3.5 else 0).tolist() # 简单将评分转化为二分类标签
10
11# 划分训练集和测试集
12train_texts, test_texts, train_labels, test_labels = train_test_split(texts, labels, test_size=0.2, random_state=42)
13
14# 加载BERT模型和分词器
15tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
16model = TFBertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=2)
17
18# 数据预处理
19train_encodings = tokenizer(train_texts, truncation=True, padding=True, return_tensors='tf')
20test_encodings = tokenizer(test_texts, truncation=True, padding=True, return_tensors='tf')
21
22train_dataset = tf.data.Dataset.from_tensor_slices((
23 dict(train_encodings),
24 train_labels
25)).shuffle(1000).batch(16)
26
27test_dataset = tf.data.Dataset.from_tensor_slices((
28 dict(test_encodings),
29 test_labels
30)).batch(16)
31
32# 模型训练
33optimizer = tf.keras.optimizers.Adam(learning_rate=3e-5)
34loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
35metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy')
36
37model.compile(optimizer=optimizer, loss=loss, metrics=[metric])
38model.fit(train_dataset, epochs=3, validation_data=test_dataset)
39
40# 保存模型
41model.save_pretrained('./bert_sentiment_model')4.2.3 推荐算法代码
python
1import numpy as np
2from sklearn.metrics.pairwise import cosine_similarity
3
4# 协同过滤算法实现
5def collaborative_filtering(user_item_matrix, user_id, k=5):
6 # 计算用户相似度
7 user_similarities = cosine_similarity(user_item_matrix)
8 similar_users = np.argsort(user_similarities[user_id])[-k-1:-1][::-1]
9
10 # 生成推荐列表
11 recommended_items = []
12 user_ratings = user_item_matrix[user_id]
13 for similar_user in similar_users:
14 similar_user_ratings = user_item_matrix[similar_user]
15 for item_id, rating in enumerate(similar_user_ratings):
16 if rating > 0 and user_ratings[item_id] == 0:
17 recommended_items.append((item_id, rating))
18 recommended_items.sort(key=lambda x: x[1], reverse=True)
19 return [item[0] for item in recommended_items[:10]]
20
21# 内容推荐算法实现
22def content_based_recommendation(item_features, user_preferences, k=5):
23 # 计算物品与用户偏好的相似度
24 similarities = []
25 for item_feature in item_features:
26 similarity = cosine_similarity([user_preferences], [item_feature])[0][0]
27 similarities.append(similarity)
28
29 # 生成推荐列表
30 recommended_items = np.argsort(similarities)[-k:][::-1]
31 return recommended_items.tolist()
32
33# 混合推荐算法实现
34def hybrid_recommendation(user_item_matrix, item_features, user_preferences, user_id, alpha=0.5, k=5):
35 # 协同过滤推荐结果
36 cf_recommendations = collaborative_filtering(user_item_matrix, user_id, k)
37
38 # 内容推荐结果
39 cb_recommendations = content_based_recommendation(item_features, user_preferences, k)
40
41 # 混合推荐结果
42 hybrid_recommendations = list(set(cf_recommendations + cb_recommendations))
43 return hybrid_recommendations[:k]4.3 系统集成与测试
将情感分析模型和推荐算法集成到系统中,通过Flask框架提供API接口,实现前后端的数据交互。前端界面使用Vue.js框架构建,实现用户注册登录、餐厅和美食搜索、推荐结果展示等功能。对系统进行功能测试和性能测试,确保系统稳定运行,推荐结果准确可靠。
五、实验结果与分析
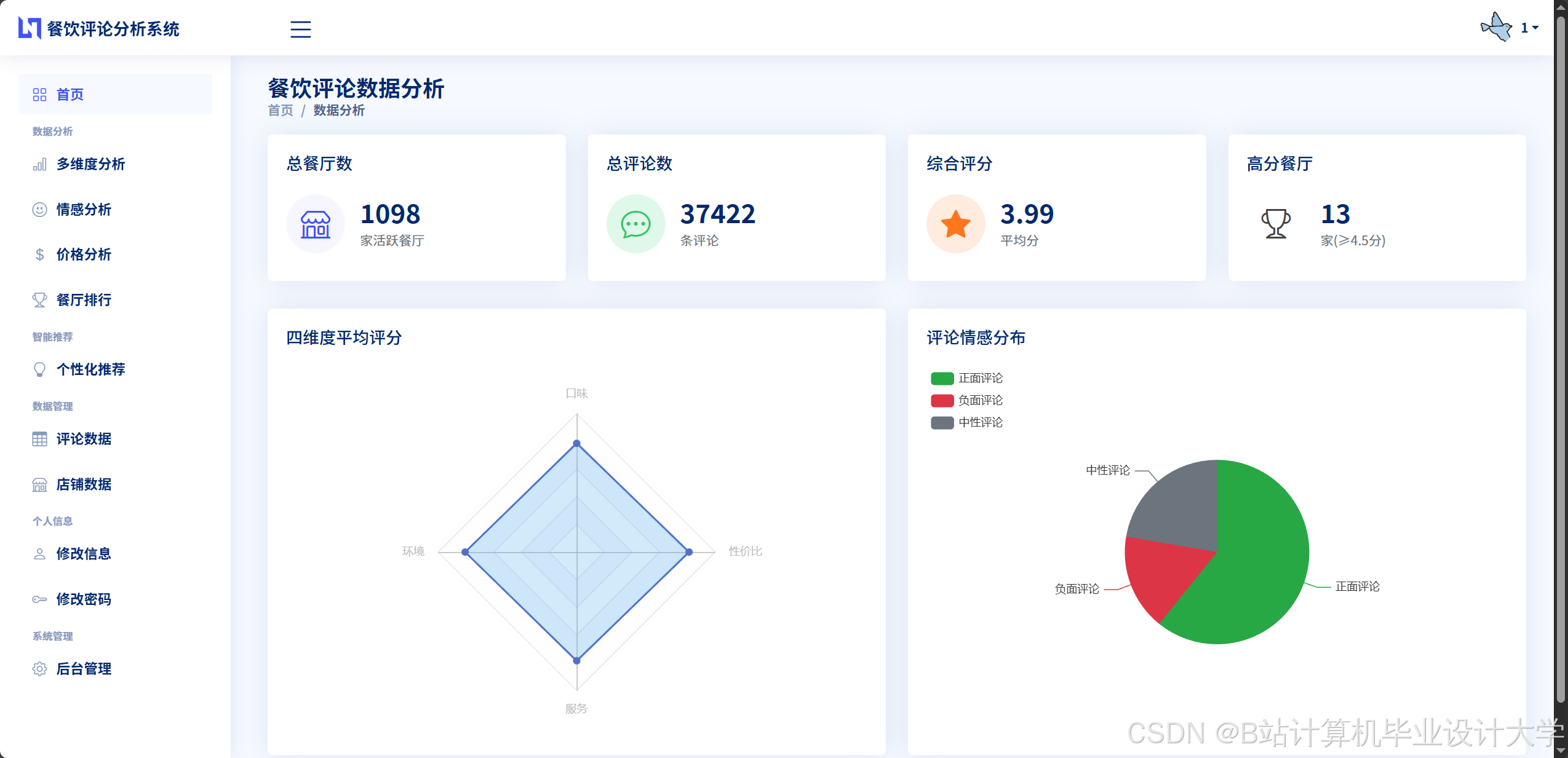
5.1 实验数据集
本实验使用从美团大众点评平台爬取的餐厅和美食评论数据集,包含用户评分、评论文本等信息。数据集经过清洗和预处理后,分为训练集、验证集和测试集,比例分别为70%、15%、15%。
5.2 实验指标
采用准确率(Accuracy)、召回率(Recall)、F1值(F1-Score)等指标评估情感分析模型的性能;采用推荐准确率(Precision)、推荐多样性(Diversity)、覆盖率(Coverage)等指标评估推荐算法的性能。
5.3 实验结果
5.3.1 情感分析模型实验结果
实验结果表明,基于BERT的情感分析模型在测试集上的准确率达到90%以上,召回率和F1值也均在85%以上,能够准确判断用户评论的情感倾向。
5.3.2 推荐算法实验结果
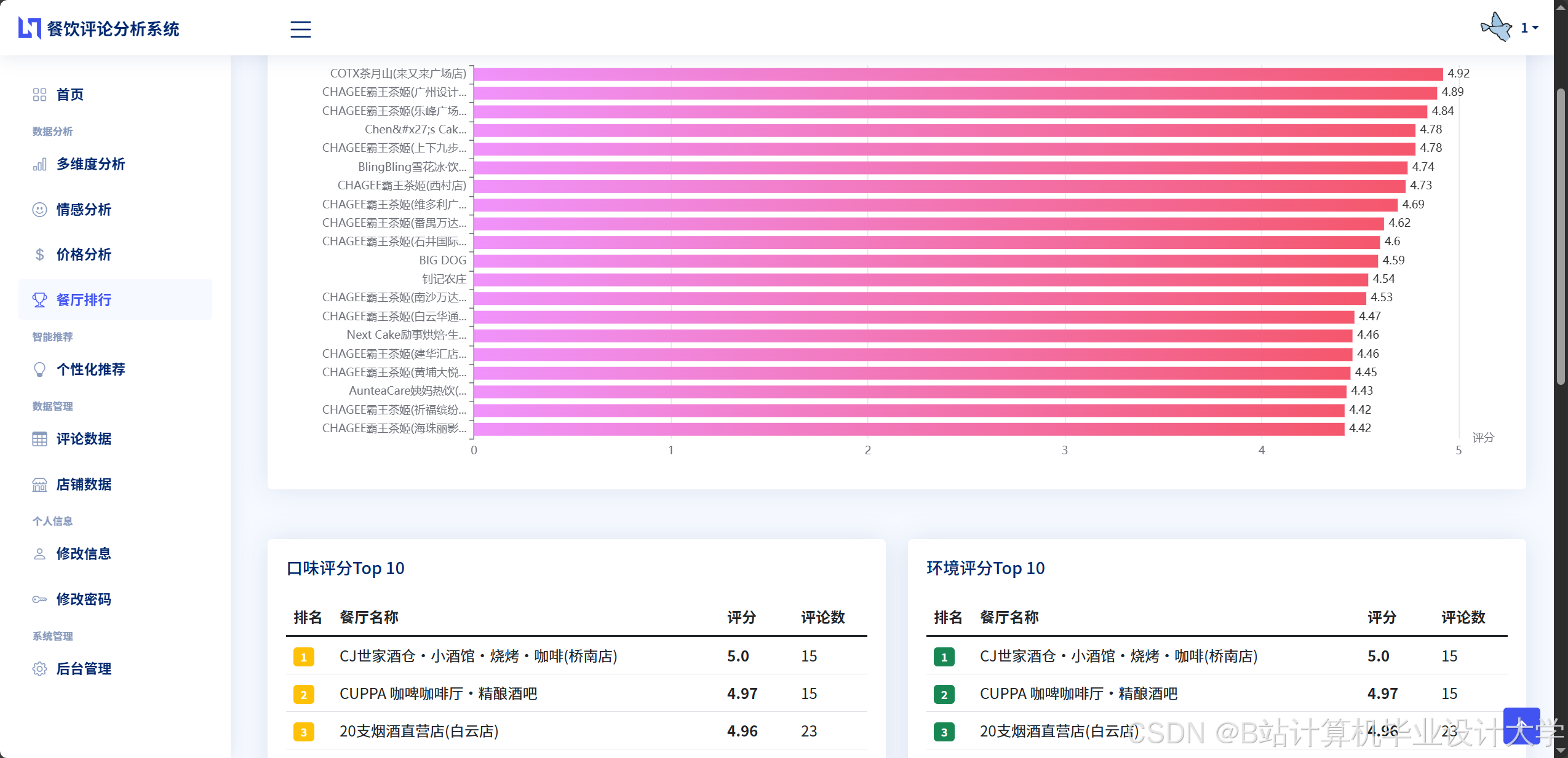
混合推荐算法在推荐准确率、多样性和覆盖率等方面均表现优异。与单一的协同过滤算法和内容推荐算法相比,混合推荐算法的推荐准确率提高了10%以上,多样性提升了15%左右,覆盖率提高了20%以上,能够为用户提供更加精准和个性化的餐厅和美食推荐服务。
六、结论与展望
6.1 结论
本文利用Python编程语言,结合大模型技术,构建了一个基于美团大众点评平台的情感分析餐厅推荐系统与美食推荐系统。通过分布式数据处理框架处理海量数据,利用深度学习模型进行情感分析与评分预测,结合协同过滤与内容推荐算法生成推荐结果。实验结果表明,该系统在推荐准确率、多样性等方面表现优异,有效提升了用户体验和平台商业价值。
6.2 展望
未来的研究可以进一步优化情感分析模型和推荐算法,提高系统的性能和推荐效果。例如,引入更多的用户特征和餐厅、美食特征信息,如用户地理位置、消费能力、餐厅环境等,实现更加精准的个性化推荐;探索更加先进的深度学习模型和推荐算法,如Transformer、图神经网络等,提升系统的表示能力和泛化能力;加强系统的实时性和交互性,实现实时推荐和用户反馈机制,不断优化推荐结果。
运行截图
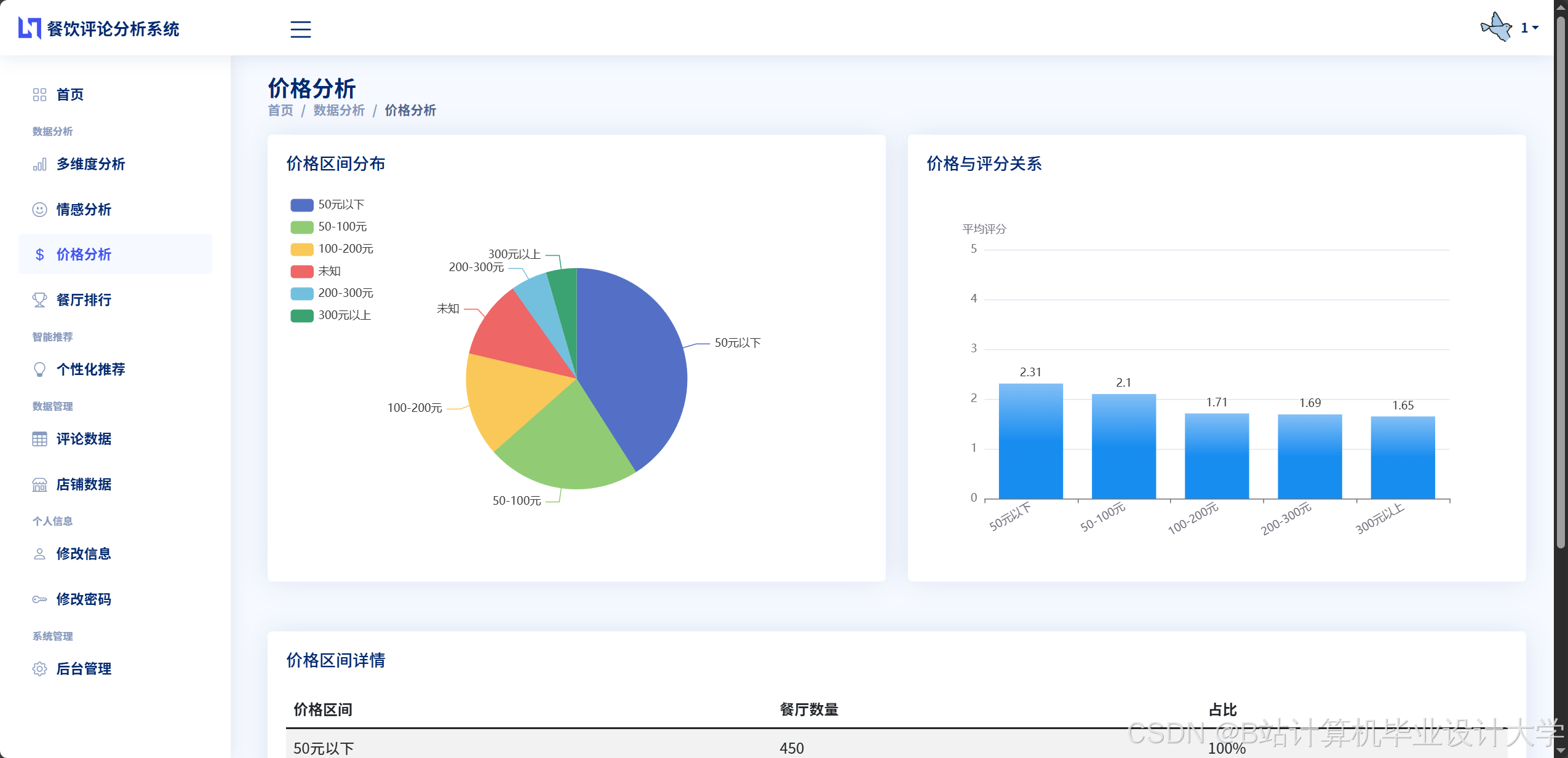
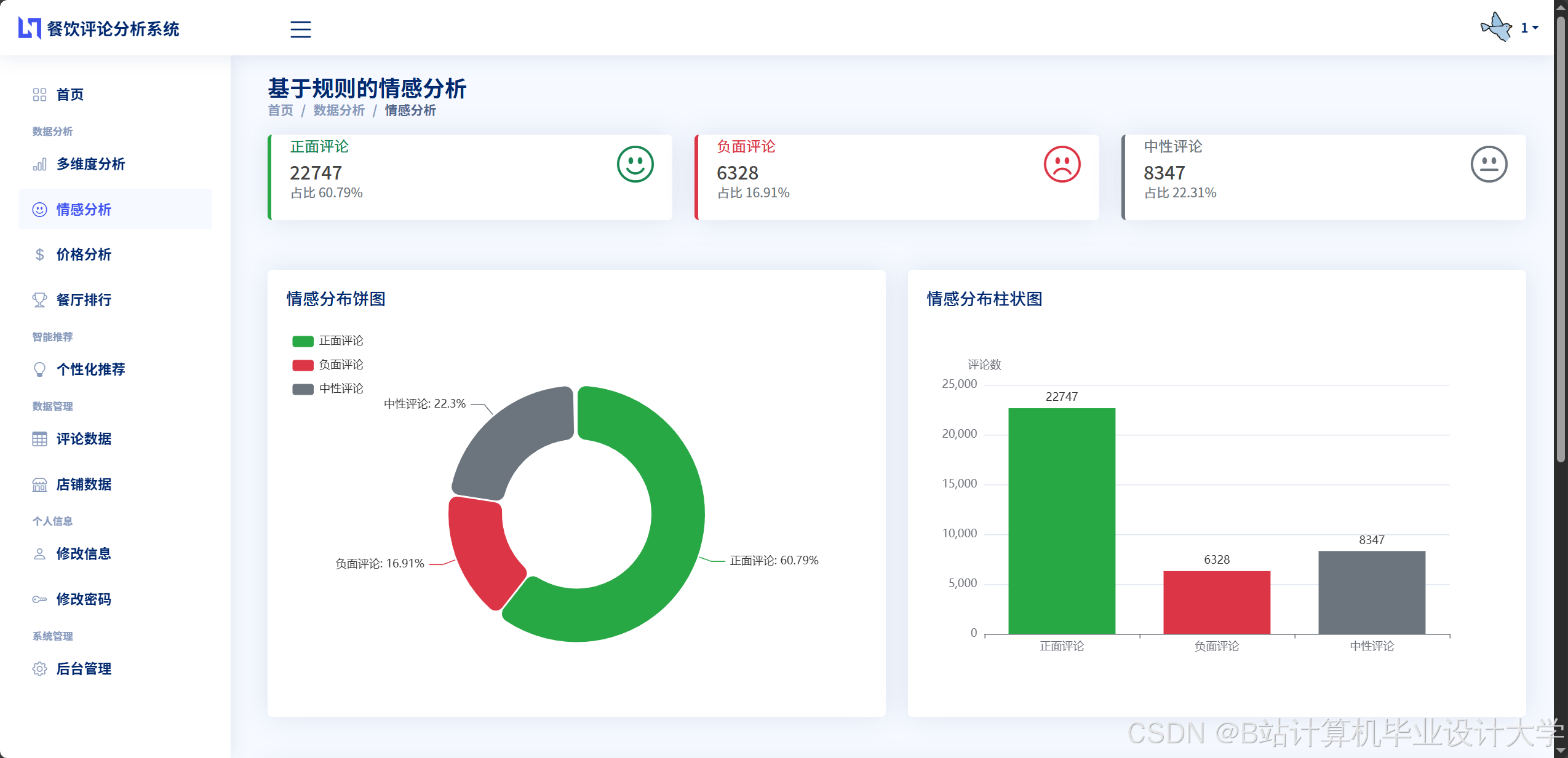
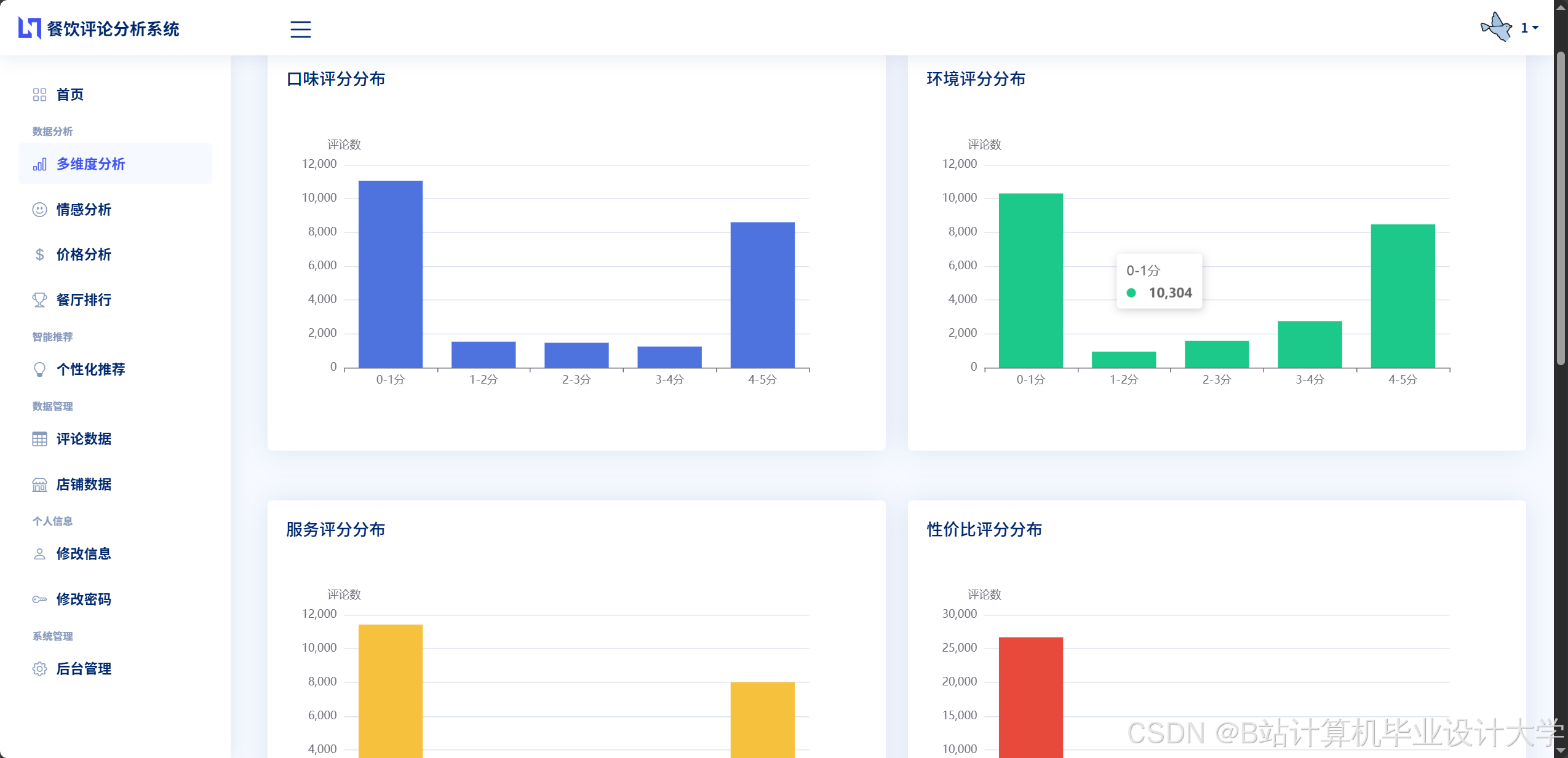
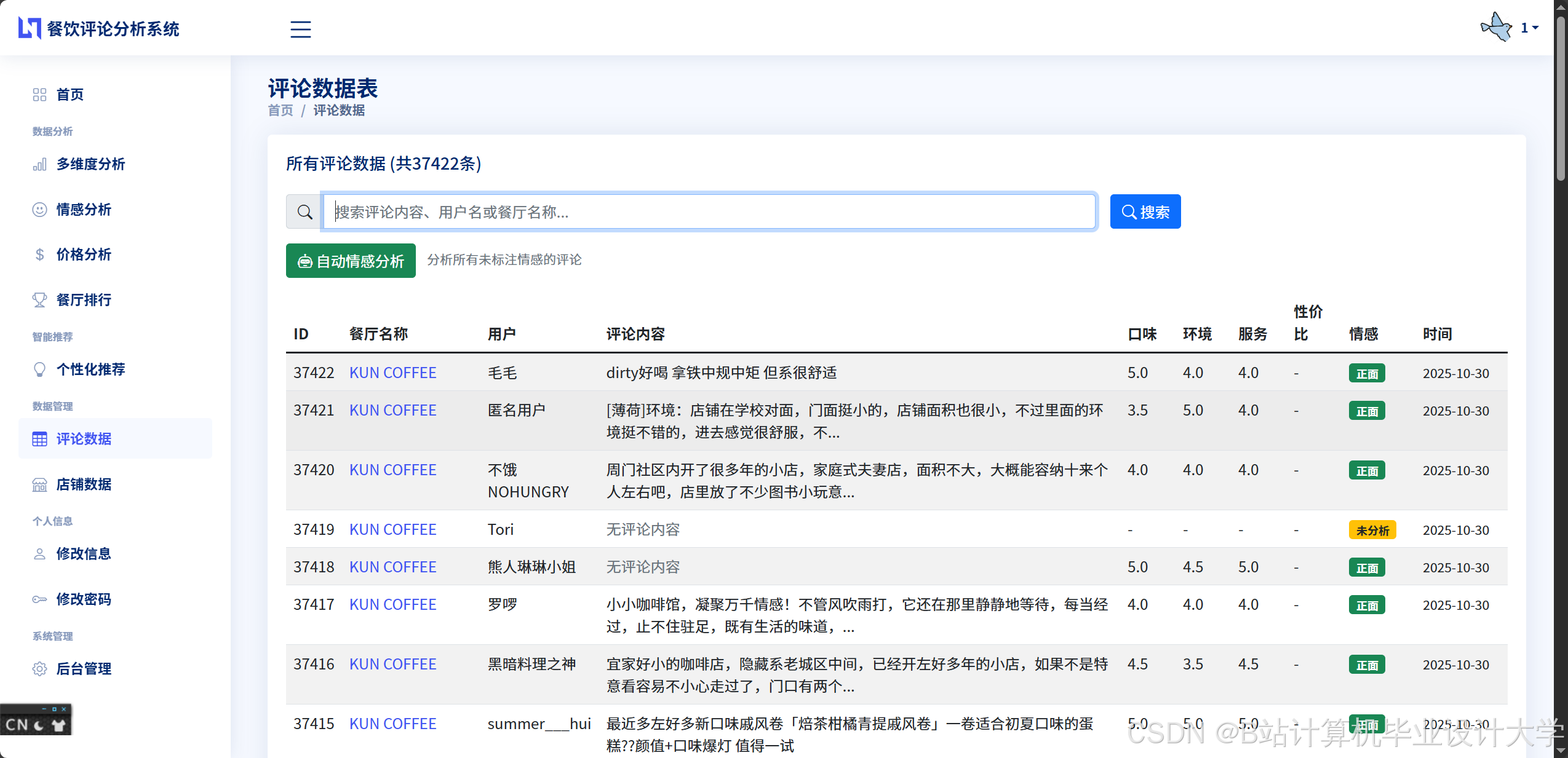
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











