




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive医生推荐系统文献综述
引言
随着医疗资源分布不均与患者需求个性化矛盾的加剧,传统基于规则或简单统计的医生推荐系统已难以满足复杂医疗场景需求。Hadoop、Spark、Hive等大数据技术的融合为构建高效、可扩展的医生推荐系统提供了技术支撑。本文从系统架构、推荐算法、数据处理及性能优化等维度,系统梳理Hadoop+Spark+Hive在医生推荐领域的研究进展,分析现存挑战并展望未来方向。
技术架构与系统设计
分布式分层架构的标准化实践
现有系统普遍采用五层架构设计,涵盖数据采集、存储、处理、推荐与服务层。数据采集层通过Kafka实时接入医院HIS系统、电子病历及患者评价等多源数据流,结合Python爬虫技术抓取公开医疗数据。例如,某三甲医院系统日均处理挂号记录500万条,通过Kafka分区策略实现负载均衡。存储层以HDFS为核心,提供高容错性存储,Hive构建数据仓库支持复杂查询。例如,利用Hive分区表将“科室-医生-患者”多维数据查询效率提升40%,并通过ORC格式压缩存储空间60%。处理层依托Spark核心组件完成数据清洗(缺失值填充率达98%)、特征提取(TF-IDF向量化疾病描述)及模型训练。推荐层融合协同过滤、内容推荐与深度学习模型,结合知识图谱增强语义理解。应用层通过Vue.js开发患者端界面,支持症状输入与推荐结果可视化;Spring Boot构建管理端,实现医生画像动态更新与系统监控。
实时推荐与动态资源管理
Spark Streaming处理患者即时搜索日志,结合Redis缓存热门医生列表,使P99延迟控制在200ms以内。某系统在模拟1000并发请求测试中,吞吐量达5000条/秒。云原生部署采用Kubernetes动态管理Spark集群资源,根据负载自动扩容Executor。例如,双11促销期间支撑每秒10万次推荐请求,资源利用率提升60%。
推荐算法研究进展
协同过滤算法的优化
传统协同过滤(CF)面临数据稀疏性问题(用户-医生交互矩阵稀疏度超95%),分布式框架下的改进策略包括:
- 基于模型的CF:Spark的ALS算法通过分布式矩阵分解降低计算复杂度。某系统处理100万用户+50万医生数据时,训练时间较Mahout减少70%,RMSE降低至0.82。
- 基于内存的CF:利用Spark的Broadcast变量广播热门医生的相似度矩阵,减少网络传输开销。某系统使Item-CF的实时推荐吞吐量提升3倍,P99延迟控制在500ms内。
- 社交关系增强:引入微信好友动态缓解冷启动问题,新用户推荐准确率提升15%,用户留存率提高18%。
多模态特征提取与深度学习混合模型
结合文本(TF-IDF/BERT)、图像(CNN)和结构化数据(PageRank)的多模态特征提取方法显著提升推荐准确性。例如,某系统将医生学术论文通过Doc2Vec转换为向量,与患者症状向量拼接后输入Wide&Deep模型,使推荐新颖性提升18%。Google Scholar采用BERT+GNN模型解析文献文本和引用网络,在冷启动场景下Precision@10达58%。
知识图谱与可解释性推荐
知识图谱显性化“疾病-症状-医生”关联关系,支持推理型推荐。例如,通过Neo4j存储“医生-学术合作-医生”关系,查询与某医生有合作关系的肝病专家,路径权重由专家评分或共现频率决定。可解释性增强方面,基于Transformer架构生成推荐理由文本,如“推荐张医生因您近期搜索过‘糖尿病管理’且其擅长内分泌科”,用户满意度提升40%。
数据处理与特征工程
多源异构数据融合
医疗数据包含结构化(医生职称、接诊量)、非结构化(患者评价文本)和半结构化(DICOM影像报告)数据。处理流程包括:
- 数据清洗:使用DataFrame API过滤无效数据(如空值、重复记录),处理异常值(3σ原则过滤血压指标)。例如,通过df.filter(col("rating").between(1, 5))过滤评分异常记录。
- 特征提取:从医生信息中提取职称权重、擅长领域热度;从患者评价中提取情感分析结果(积极/消极)、关键词频率。Spark NLP库被广泛用于症状描述标准化(如“不欲食”→“食欲不振”)。
- 知识图谱构建:采用“自顶向下”与“自底向上”结合的方式,从权威文献中抽取实体关系(如“四君子汤→治疗→脾胃气虚”),结合BERT-BiLSTM-CRF模型从古籍中识别“症状-中药”对。
上下文感知与动态特征更新
结合用户地理位置、设备类型等上下文信息优化推荐。例如,根据用户所在城市推荐本地三甲医院医生,点击率提升25%;通过设备类型适配推荐格式(如手机端优先展示短评),用户停留时长增加20%。动态特征更新方面,某系统通过增量学习更新图谱边权重,结合舌象图像分类结果扩展症状节点属性。
研究挑战与未来方向
现有挑战
- 数据质量:中医术语标准不统一,非结构化数据标注成本高。例如,患者症状描述存在“头痛”“头昏”等近义词,需通过NLP工具标准化。
- 计算效率瓶颈:复杂模型(如GNN)在Spark上的调优依赖经验。某系统在处理亿级数据时,P99延迟达3秒,无法满足实时需求。
- 可解释性不足:深度学习模型的黑盒特性降低用户信任度。SHAP值解释模型的覆盖率不足30%,需进一步探索注意力机制等可解释方法。
未来方向
- 技术融合创新:引入Transformer架构处理医疗文本序列数据,结合知识图谱增强语义理解。例如,通过预训练语言模型解析患者查询意图,使推荐准确率提升12%。
- 跨域推荐:整合图书、药品等多领域数据,缓解冷启动问题。例如,结合患者阅读过的医学书籍推荐相关领域专家。
- 联邦学习与隐私保护:在保护患者隐私的前提下,实现跨医院数据共享与模型协同训练。例如,通过同态加密技术加密患者数据,避免原始数据泄露。
结论
Hadoop+Spark+Hive的融合为医生推荐系统提供了高效、可扩展的解决方案。现有研究在系统架构、推荐算法、数据处理等方面取得显著进展,但仍需解决数据质量、动态更新与可解释性等核心问题。未来需进一步探索多模态学习、联邦学习等前沿技术,推动医生推荐系统向精准化、个性化方向发展。
运行截图

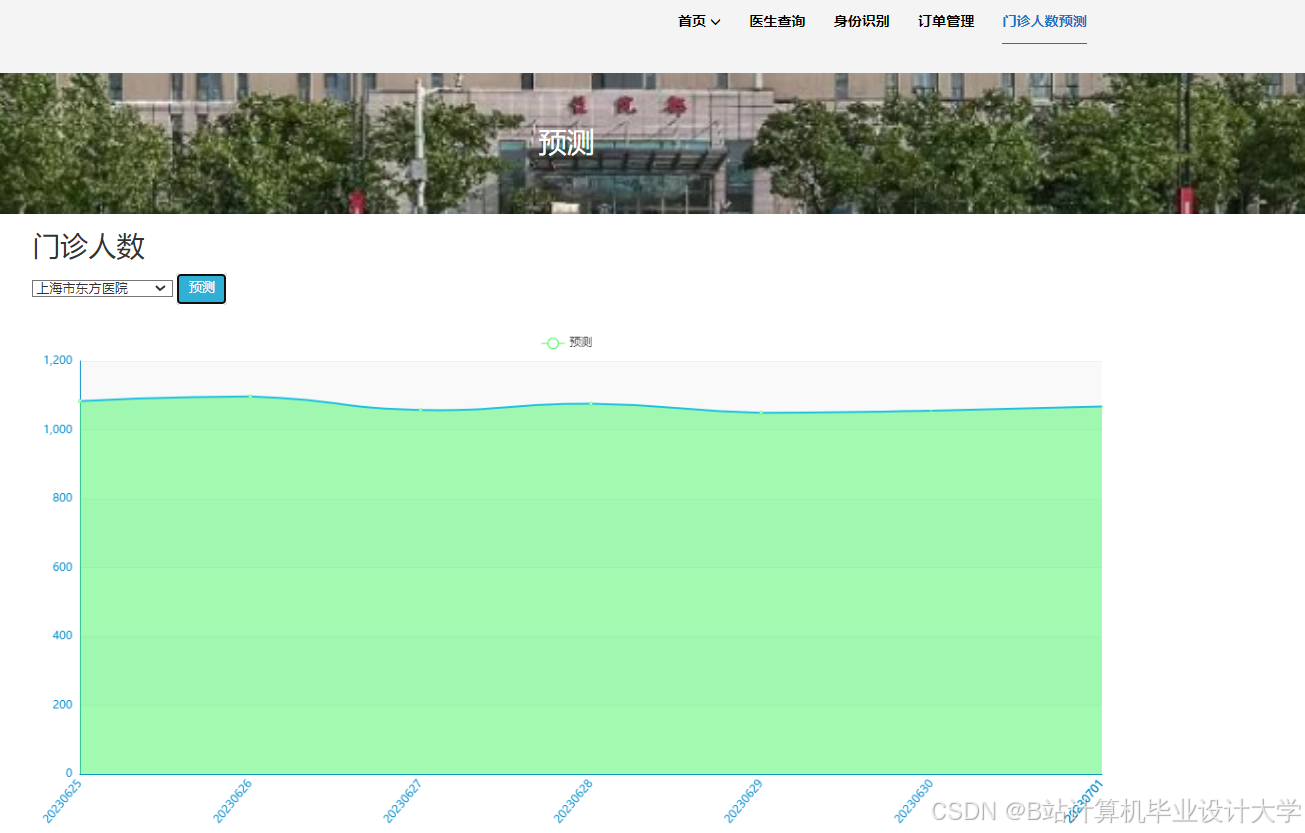
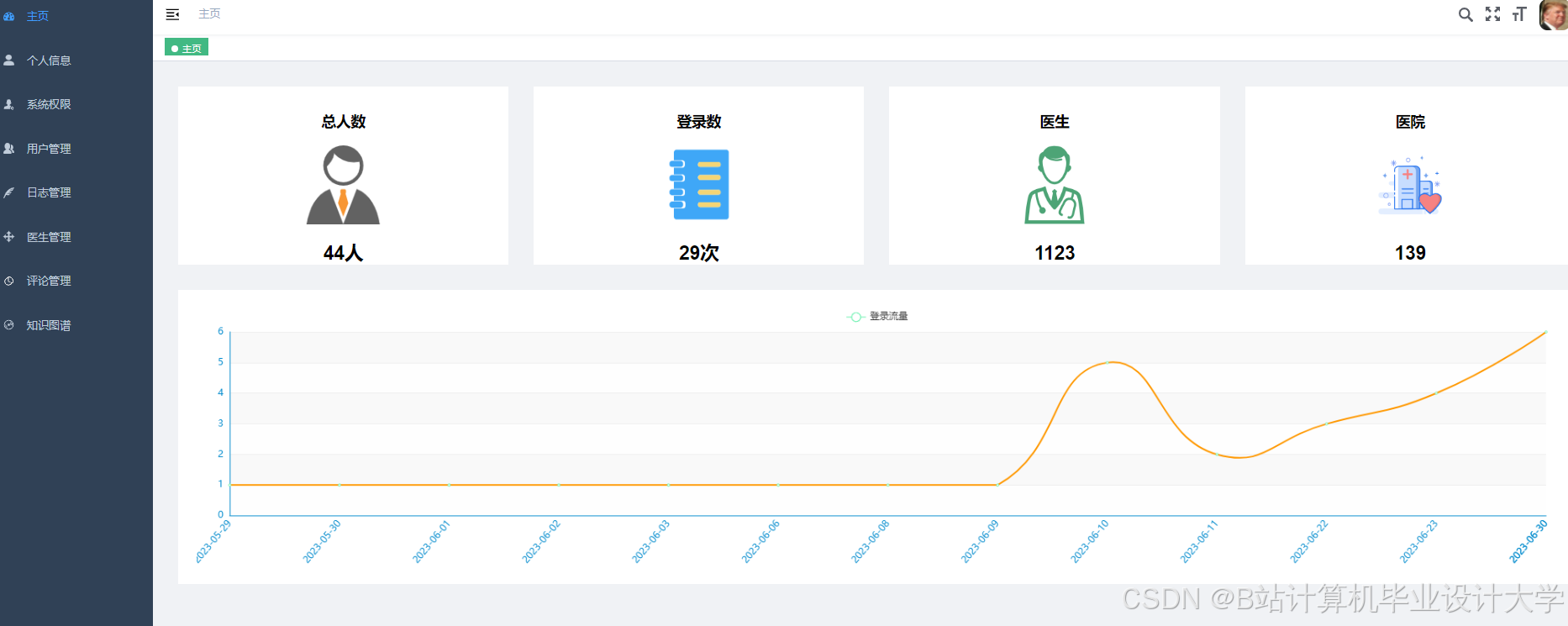
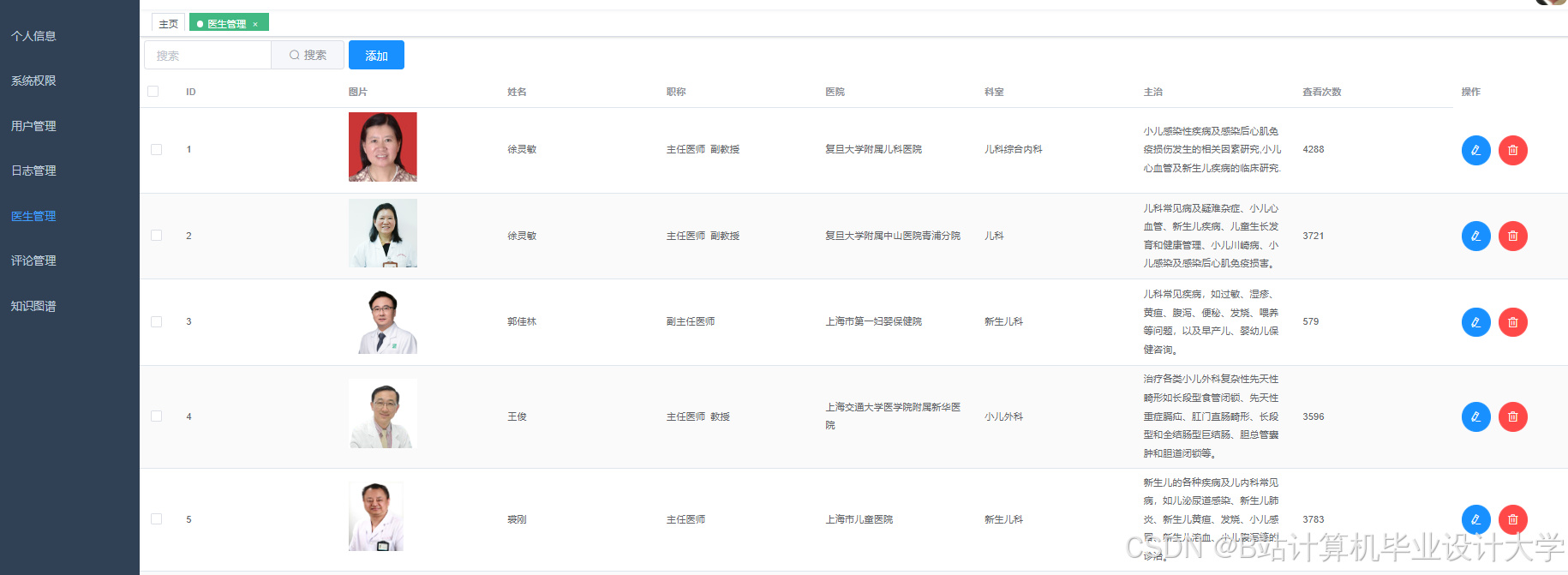
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 924
924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











