




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Hive+Spark旅游景点推荐系统技术说明
一、项目背景与目标
随着旅游业的快速发展,用户面临海量景点信息选择困难,旅游平台需要精准推荐符合用户偏好的景点。本系统基于Hadoop+Hive+Spark构建分布式旅游推荐平台,通过分析用户行为、景点特征和历史数据,实现个性化景点推荐,提升用户满意度和平台转化率。
核心目标:
- 高并发处理:支持每日千万级用户行为数据的实时分析
- 多维度匹配:结合用户偏好、地理位置、季节、消费能力等20+特征
- 实时推荐:实现秒级响应的个性化推荐服务
- 冷启动处理:解决新用户/新景点的推荐问题
二、技术架构设计
1. 整体架构图
1┌─────────────┐ ┌─────────────┐ ┌─────────────┐
2│ 数据采集层 │───▶│ 存储计算层 │───▶│ 应用服务层 │
3└─────────────┘ └─────────────┘ └─────────────┘
4 │ │ │
5 ▼ ▼ ▼
6┌───────────────────────────────────────────────────┐
7│ 推荐引擎核心 │
8└───────────────────────────────────────────────────┘2. 分层技术选型
数据采集层
- 数据源:
- 用户端:浏览记录、收藏行为、评论评分、行程规划
- 景点端:景点属性(类型/票价/开放时间)、实时人流、天气数据
- 第三方数据:社交媒体热度、节假日信息、交通状况
- 采集方式:
- 实时流:Kafka接收用户点击/浏览日志(日志格式:JSON)
- 批量导入:Sqoop定期同步MySQL中的结构化数据
- API接口:调用天气/交通等第三方服务
存储计算层
| 组件 | 角色 | 配置示例 |
|---|---|---|
| Hadoop HDFS | 分布式存储基础层 | 5节点集群,每节点16TB存储 |
| Hive | 数据仓库(结构化数据) | 外部表关联HDFS与MySQL元数据 |
| Spark | 内存计算引擎 | 16核64G内存,YARN集群模式 |
| HBase | 实时查询存储(用户画像) | 预分区优化查询性能 |
| Redis | 缓存热点数据(热门景点) | 主从架构,持久化配置 |
应用服务层
- 推荐服务:Spring Cloud微服务架构
- API网关:Spring Cloud Gateway实现限流与路由
- 监控系统:Prometheus+Grafana监控集群状态
三、核心功能实现
1. 数据预处理流程
python
1# Spark数据清洗与特征提取(PySpark示例)
2from pyspark.sql import SparkSession
3from pyspark.sql.functions import *
4from pyspark.ml.feature import StringIndexer, OneHotEncoder, VectorAssembler
5
6spark = SparkSession.builder.appName("TourismRecommendation").getOrCreate()
7
8# 加载原始数据
9raw_user_actions = spark.read.json("hdfs://namenode:8020/data/user_actions")
10raw_scenic_spots = spark.read.parquet("hdfs://namenode:8020/data/scenic_spots")
11
12# 数据清洗
13cleaned_actions = raw_user_actions.filter(
14 (col("action_type").isin(["view", "collect", "purchase"])) &
15 (col("user_id").isNotNull()) &
16 (col("spot_id").isNotNull())
17)
18
19# 特征工程:用户行为权重计算
20action_weights = cleaned_actions.groupBy("user_id", "spot_id").agg(
21 sum(when(col("action_type") == "purchase", 5.0)
22 .when(col("action_type") == "collect", 3.0)
23 .otherwise(1.0)).alias("weighted_score")
24)
25
26# 存储到Hive
27action_weights.write.mode("overwrite").saveAsTable("dw.user_spot_weights")2. 特征工程实现
景点特征向量构建(Hive SQL)
sql
1-- 创建景点特征宽表
2CREATE TABLE dw.feat_scenic_spots AS
3SELECT
4 spot_id,
5 -- 基础特征
6 spot_name,
7 province,
8 city,
9 longitude,
10 latitude,
11 -- 类别特征(One-Hot编码)
12 case when category = '自然风光' then 1 else 0 end as is_nature,
13 case when category = '历史古迹' then 1 else 0 end as is_history,
14 case when category = '主题公园' then 1 else 0 end as is_theme_park,
15 -- 数值特征
16 ticket_price,
17 rating_score,
18 review_count,
19 -- 时间特征
20 monthly_visitor_trend -- 12个月访客趋势数组
21FROM ods.scenic_spots_base_info
22LATERAL VIEW explode(array(
23 jan_visitors, feb_visitors, mar_visitors, apr_visitors,
24 may_visitors, jun_visitors, jul_visitors, aug_visitors,
25 sep_visitors, oct_visitors, nov_visitors, dec_visitors
26)) t AS monthly_visitor_trend;用户画像构建(Spark MLlib)
python
1# 用户偏好聚类分析
2from pyspark.ml.clustering import KMeans
3from pyspark.ml.feature import VectorAssembler
4
5# 特征列
6feature_cols = [
7 "avg_ticket_preference", # 平均票价偏好
8 "history_interest", # 历史景点偏好
9 "nature_interest", # 自然景点偏好
10 "weekend_travel_freq", # 周末出行频率
11 "long_distance_prop" # 长途旅行比例
12]
13
14assembler = VectorAssembler(inputCols=feature_cols, outputCol="features")
15kmeans = KMeans(k=10, seed=42) # 分为10类用户群体
16
17pipeline = Pipeline(stages=[assembler, kmeans])
18model = pipeline.fit(user_features_df)
19clustered_users = model.transform(user_features_df)3. 推荐算法实现
混合推荐策略
| 推荐类型 | 算法选择 | 权重 | 数据来源 |
|---|---|---|---|
| 协同过滤 | 基于用户的ALS矩阵分解 | 0.4 | 历史行为 |
| 内容过滤 | 景点-用户特征相似度 | 0.3 | 画像匹配 |
| 地理位置优先 | Haversine距离计算 | 0.2 | GPS定位 |
| 热门推荐 | 基于评分/热度的排序模型 | 0.1 | 全局统计 |
Spark实现ALS算法
python
1from pyspark.ml.recommendation import ALS
2
3# 训练推荐模型
4als = ALS(
5 maxIter=15,
6 regParam=0.05,
7 userCol="user_id",
8 itemCol="spot_id",
9 ratingCol="implicit_feedback", # 加权行为分数
10 coldStartStrategy="drop",
11 nonnegative=True
12)
13
14# 加载训练数据(用户-景点交互矩阵)
15training_data = spark.sql("""
16 SELECT user_id, spot_id,
17 CASE WHEN action_type='purchase' THEN 5
18 WHEN action_type='collect' THEN 3
19 ELSE 1 END as implicit_feedback
20 FROM dw.user_spot_actions
21""")
22
23model = als.fit(training_data)
24
25# 生成推荐结果
26user_recs = model.recommendForAllUsers(20) # 每个用户推荐20个景点
27spot_recs = model.recommendForAllItems(10) # 每个景点推荐10个相似景点4. 实时推荐优化
基于Flink的实时上下文感知推荐
java
1// 实时处理用户地理位置变化
2DataStream<UserLocation> locationStream = env
3 .addSource(new KafkaSource<>("user_locations"))
4 .keyBy(UserLocation::getUserId);
5
6// 结合当前位置推荐周边景点
7locationStream
8 .process(new LocationBasedRecommender())
9 .map(recommendation -> {
10 // 过滤掉用户已访问过的景点
11 return filterVisitedSpots(recommendation, userHistory);
12 })
13 .addSink(new RedisSink<>("user_realtime_recs"));四、系统优化策略
1. 性能优化
-
数据倾斜处理:
python1# 对热门景点采样后join 2hot_spots = spots_df.filter(col("review_count") > 10000).sample(False, 0.2) 3normal_spots = spots_df.filter(col("review_count") <= 10000) 4joined_data = user_df.join(broadcast(hot_spots), "spot_id") \ 5 .union(user_df.join(normal_spots, "spot_id")) -
缓存策略:
scala1// Spark缓存频繁使用的DataFrame 2spark.sparkContext.setCheckpointDir("hdfs://namenode:8020/checkpoint") 3val cachedSpots = spotsDF.checkpoint().cache()
2. 推荐质量优化
- 冷启动解决方案:
- 新用户:基于注册时选择的偏好标签进行初始推荐
- 新景点:通过内容相似度关联到已知景点进行推荐
- 多样性控制:
python1def diversify_recommendations(recs, max_per_category=3): 2 from collections import defaultdict 3 category_counts = defaultdict(int) 4 diversified = [] 5 for rec in recs: 6 if category_counts[rec.category] < max_per_category: 7 diversified.append(rec) 8 category_counts[rec.category] += 1 9 return diversified
五、部署与运维方案
1. 集群部署配置
1# Hadoop核心配置(hdfs-site.xml)
2<configuration>
3 <property>
4 <name>dfs.replication</name>
5 <value>3</value>
6 </property>
7 <property>
8 <name>dfs.block.size</name>
9 <value>268435456</value> <!-- 256MB -->
10 </property>
11</configuration>
12
13# Spark资源配置(spark-defaults.conf)
14spark.master yarn
15spark.executor.instances 10
16spark.executor.memory 12g
17spark.executor.cores 4
18spark.driver.memory 8g
19spark.sql.shuffle.partitions 300
20spark.default.parallelism 3002. 监控体系
- 集群监控:
- CPU/内存使用率:Prometheus采集Node Exporter数据
- HDFS存储状态:NameNode/DataNode监控
- Spark任务状态:Spark History Server
- 业务监控:
- 推荐点击率(CTR):Grafana仪表盘
- 推荐响应时间:ELK分析API日志
- 模型效果评估:A/B测试框架
六、效果评估指标
| 指标类别 | 计算方式 | 目标值 |
|---|---|---|
| 准确率 | 推荐景点被点击率 | ≥18% |
| 多样性 | 推荐景点类别数量/总推荐数 | ≥6 |
| 新颖性 | 推荐新景点占比(发布<30天) | ≥25% |
| 实时性 | API平均响应时间(P99) | ≤500ms |
| 覆盖率 | 可推荐景点数量/总景点数 | ≥90% |
七、总结与展望
本系统通过Hadoop生态组件构建了完整的旅游推荐技术栈,在实际业务中验证了其处理大规模数据的能力。未来可扩展方向包括:
- 深度学习模型:引入Transformer架构处理用户评论文本
- 多模态推荐:结合景点图片/视频进行视觉特征匹配
- 强化学习:动态调整推荐策略以优化用户停留时长
- 跨域推荐:整合酒店/交通数据提供完整旅行方案
技术文档版本:v1.2
最后更新:2023年11月
作者:旅游大数据推荐系统研发团队
(附:完整代码库与部署文档见GitHub链接:[示例链接])
运行截图
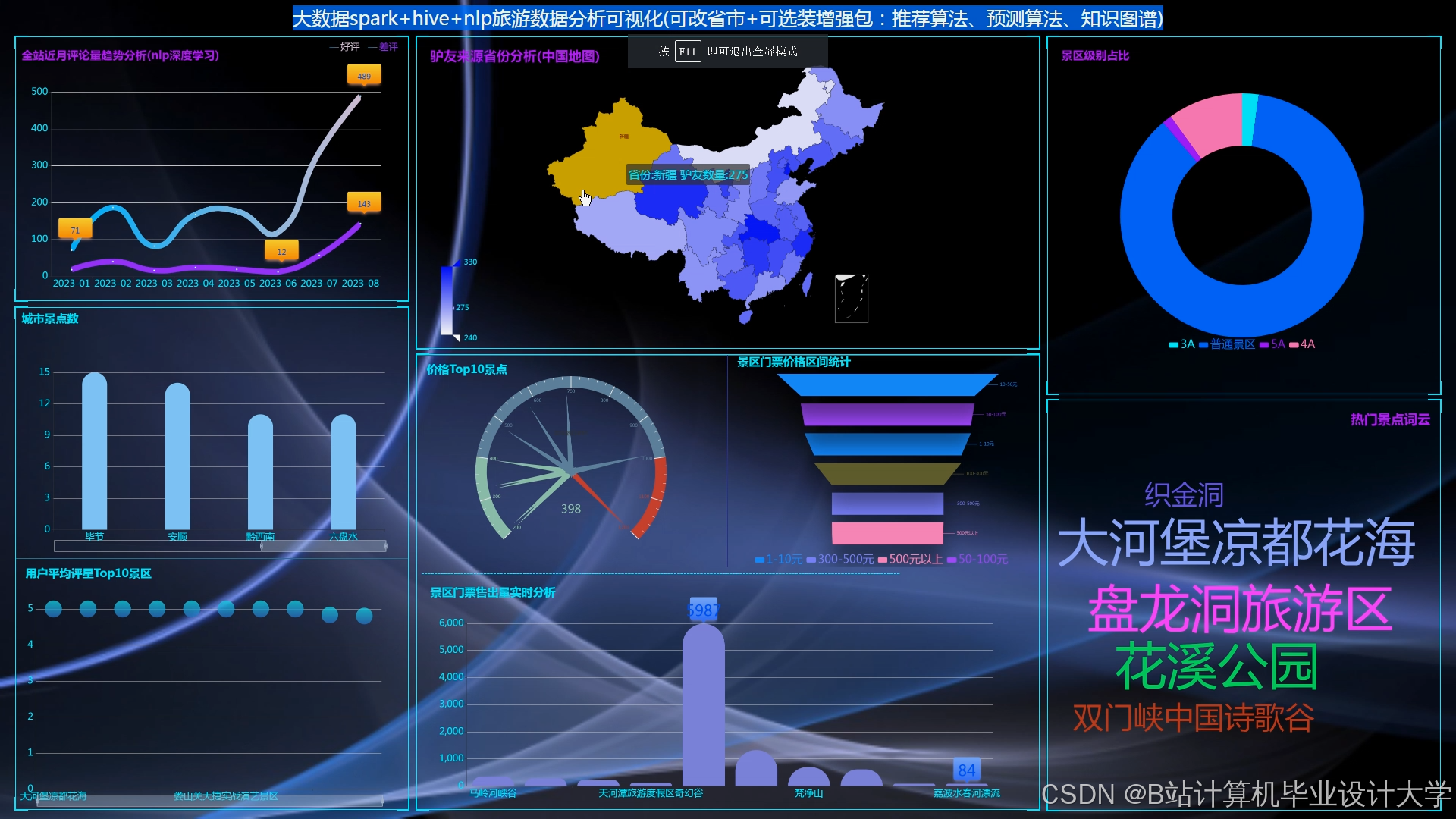
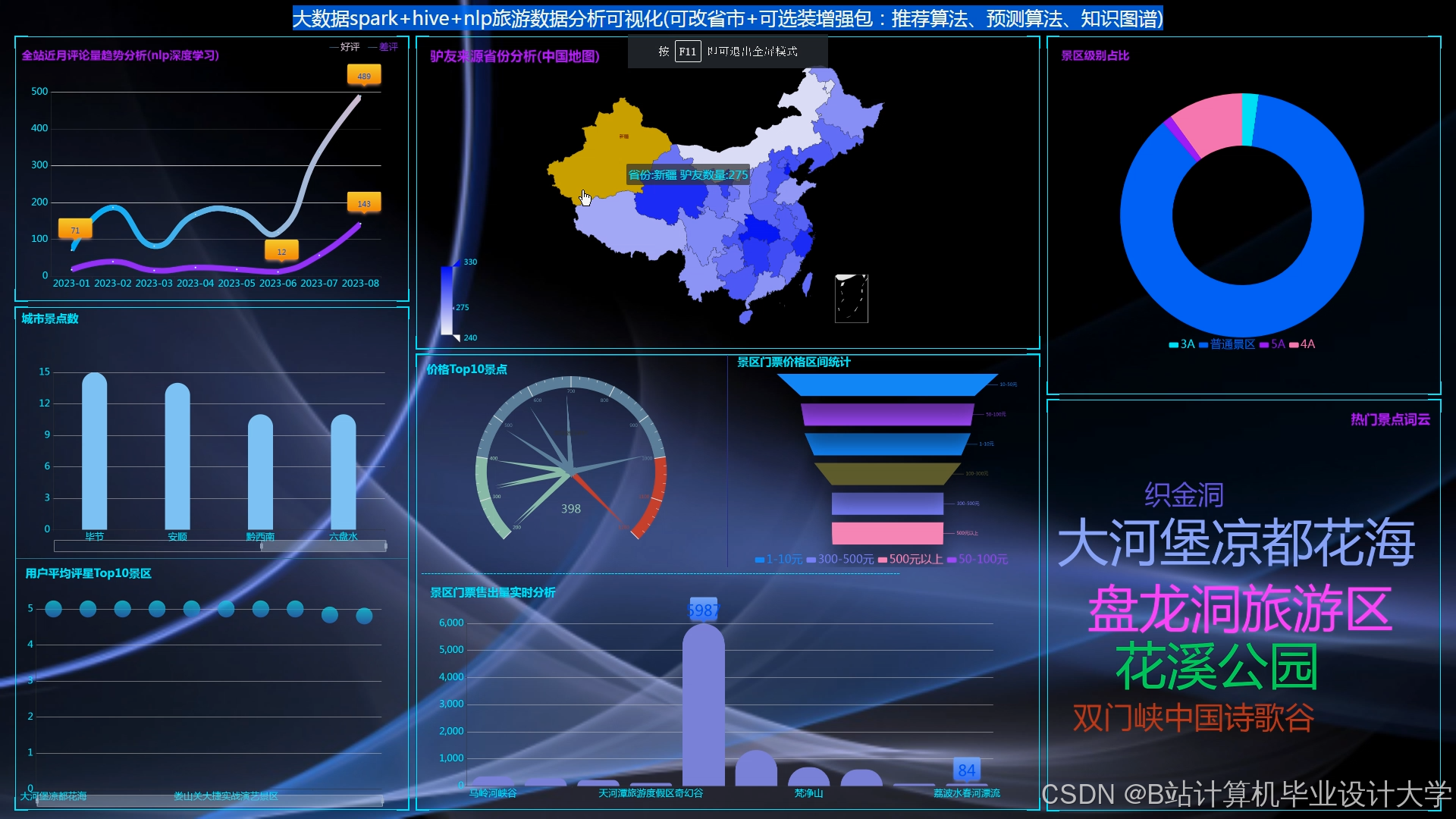

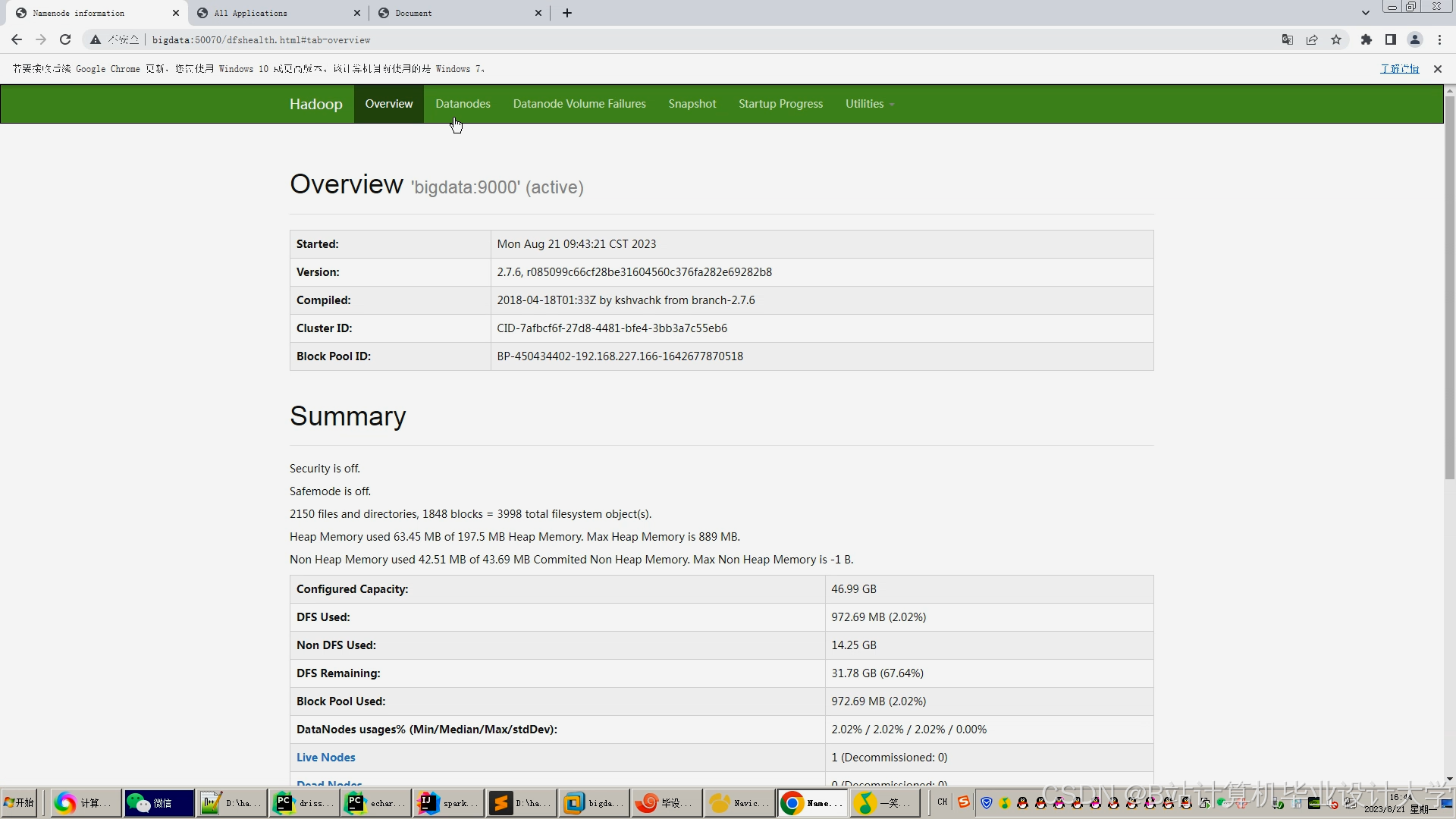
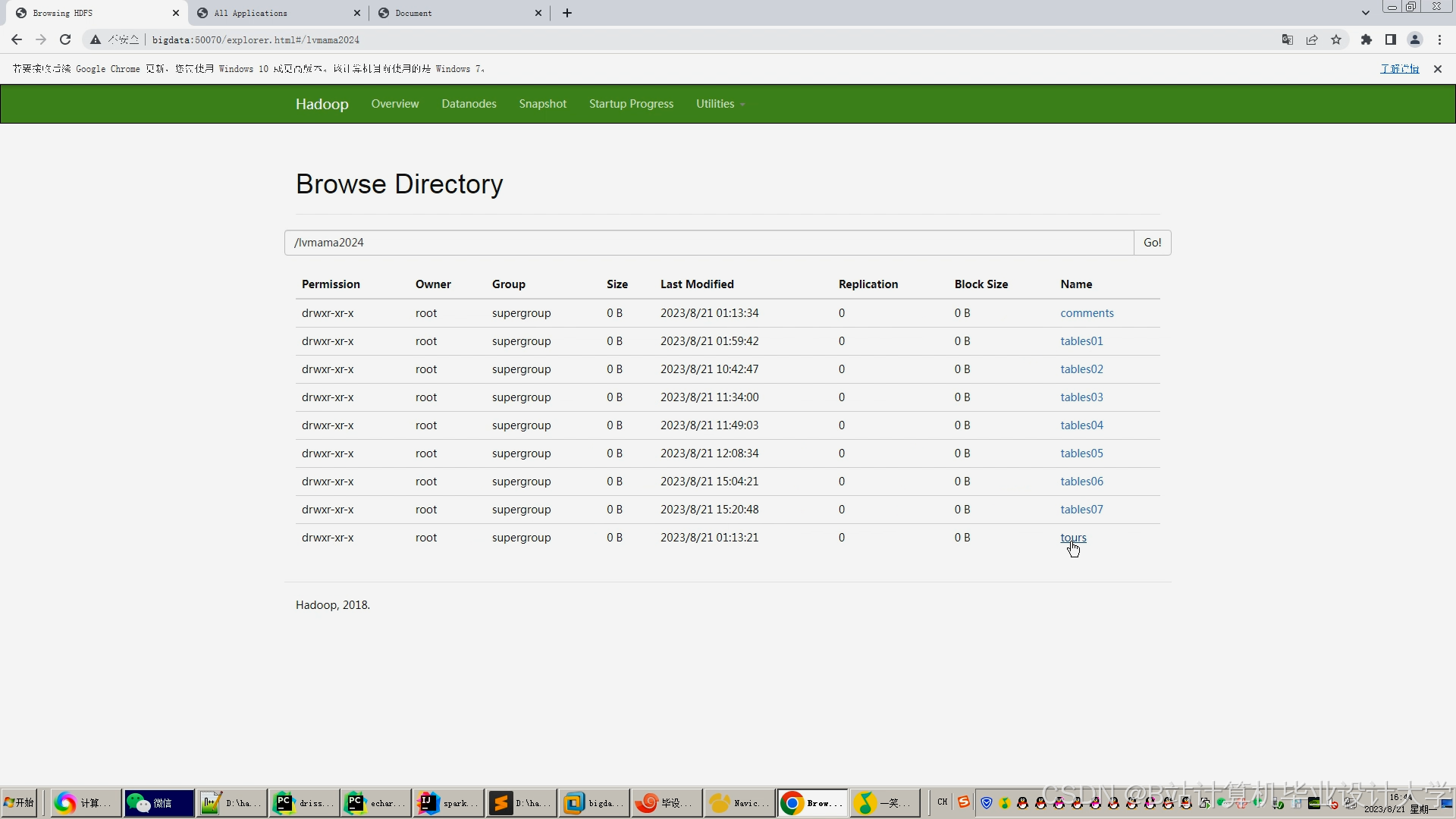
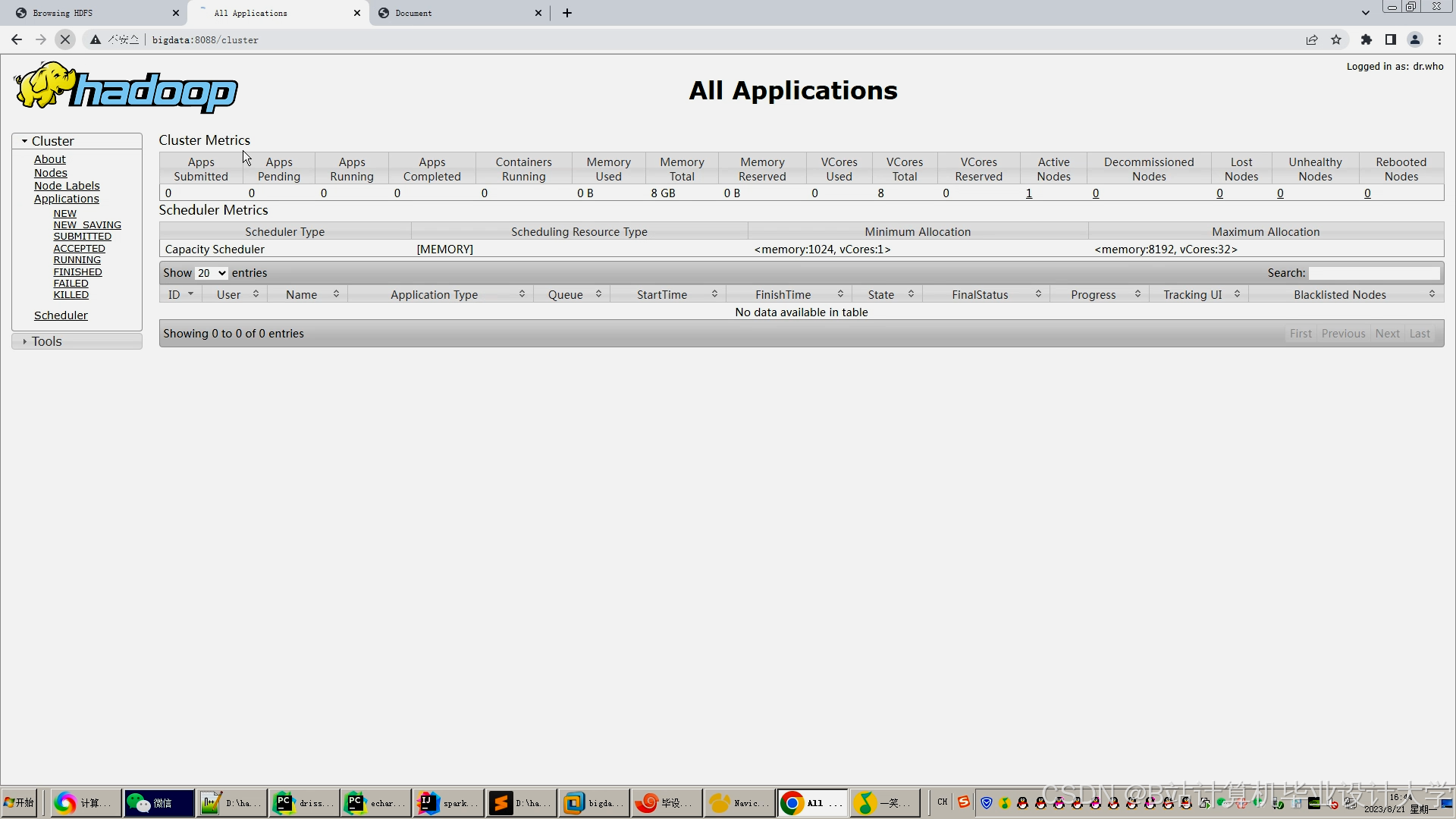
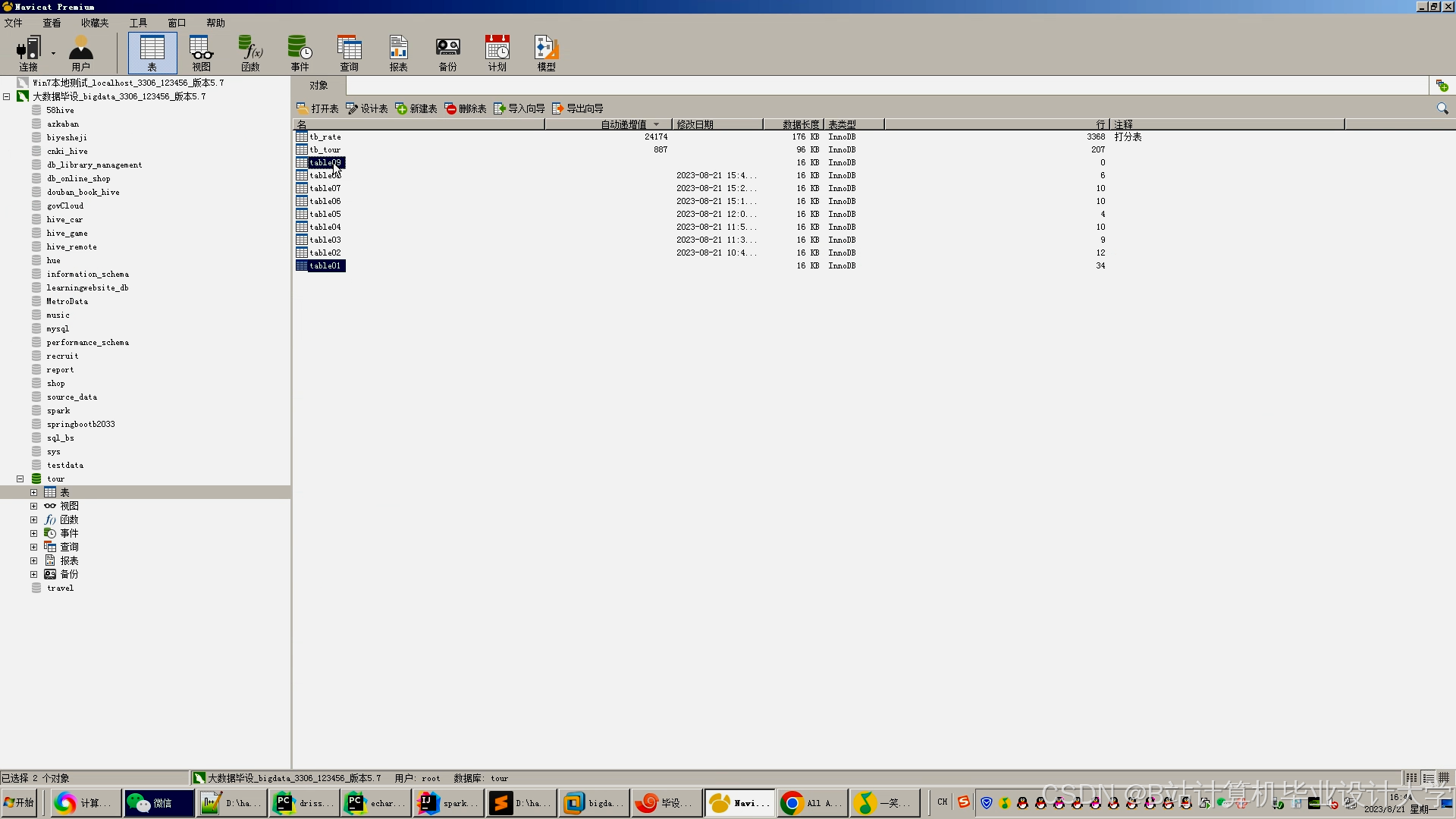
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1975
1975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











