




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive高考志愿填报推荐系统与高考数据分析可视化大屏研究
摘要:随着高考报名人数的持续增长,高考数据规模急剧膨胀,传统志愿填报方式面临信息获取困难、决策效率低下等问题。本文提出基于Hadoop、Spark和Hive构建高考志愿填报推荐系统,结合数据爬取、清洗、分析、推荐算法及可视化技术,为考生提供个性化志愿推荐。实验表明,该系统在推荐准确率、用户满意度等方面显著优于传统方法,有效提升了志愿填报的科学性和效率。
关键词:Hadoop;Spark;Hive;高考志愿推荐;数据可视化
一、引言
我国高考制度作为高等教育选拔的核心机制,每年吸引超千万考生参与。然而,面对全国2700余所高校和500多个专业,考生需在短时间内完成志愿填报,传统手工查阅书籍、依赖经验判断的方式易导致信息遗漏或决策失误。据《中国青年报》调查,超71.2%的考生后悔当年志愿选择,典型案例包括高分考生误报独立学院、专业与兴趣错配等。大数据技术的兴起为解决这一问题提供了新路径,通过整合考生成绩、兴趣、职业规划及高校录取数据,构建智能推荐系统,可显著提升志愿填报的精准性与效率。
二、系统架构与技术选型
2.1 系统架构设计
系统采用分层架构,包括数据采集层、存储计算层、推荐引擎层和应用展示层(图1):
- 数据采集层:通过Python爬虫(如Requests+BeautifulSoup)实时抓取教育部官网、各省考试院及高校招生网数据,涵盖历年录取分数线、专业设置、招生计划等信息。
- 存储计算层:利用Hadoop HDFS存储原始数据,Hive构建数据仓库,Spark进行分布式计算(如数据清洗、特征提取、模型训练)。
- 推荐引擎层:结合协同过滤算法(用户-物品双模型)与内容推荐算法,基于考生分数、位次、兴趣标签生成推荐列表。
- 应用展示层:采用Vue.js+ECharts开发前端界面,实现志愿模拟填报、推荐结果可视化及大屏驾驶舱展示。
2.2 技术选型依据
- Hadoop:提供高可靠性的分布式存储,支持PB级数据存储与扩展。
- Spark:内存计算框架加速数据处理,MLlib库支持矩阵分解、ALS协同过滤等算法,处理速度较Hadoop MapReduce快10倍以上。
- Hive:基于SQL的查询引擎简化数据ETL流程,支持复杂分析(如多维度分组统计)。
- ECharts:动态可视化库支持实时数据更新,适用于高考人数热力图、录取趋势折线图等场景。
三、关键技术实现
3.1 数据采集与预处理
以某省高考数据为例,爬虫程序每日定时抓取最新录取数据,存储为JSON格式后,通过Spark清洗无效记录(如缺失分数、专业代码错误),并归一化处理(如将分数映射至[0,1]区间)。代码示例如下:
python
1from pyspark.sql import SparkSession
2spark = SparkSession.builder.appName("DataCleaning").getOrCreate()
3raw_data = spark.read.json("hdfs://raw_gaokao_data")
4cleaned_data = raw_data.filter(
5 (col("score").isNotNull()) &
6 (col("major_code").rlike("^[A-Z0-9]{6}$")) # 校验专业代码格式
7)
8cleaned_data.write.parquet("hdfs://cleaned_data")3.2 推荐算法优化
针对冷启动问题,系统采用混合推荐策略:
-
基于内容的推荐:提取高校专业标签(如“计算机类”“师范类”)与考生兴趣标签匹配,初始推荐相似度高的专业。
-
协同过滤推荐:利用ALS算法挖掘用户-专业评分矩阵,预测考生对未填报专业的兴趣值。公式如下:
R^ui=μ+bu+bi+f=1∑F(puf⋅qif)
其中,μ为全局均值,bu、bi为用户和专业的偏差项,puf、qif为隐特征向量。
- 动态权重调整:根据考生填报阶段(如模拟填报、正式填报)动态调整算法权重,初期侧重内容推荐,后期增加协同过滤占比。
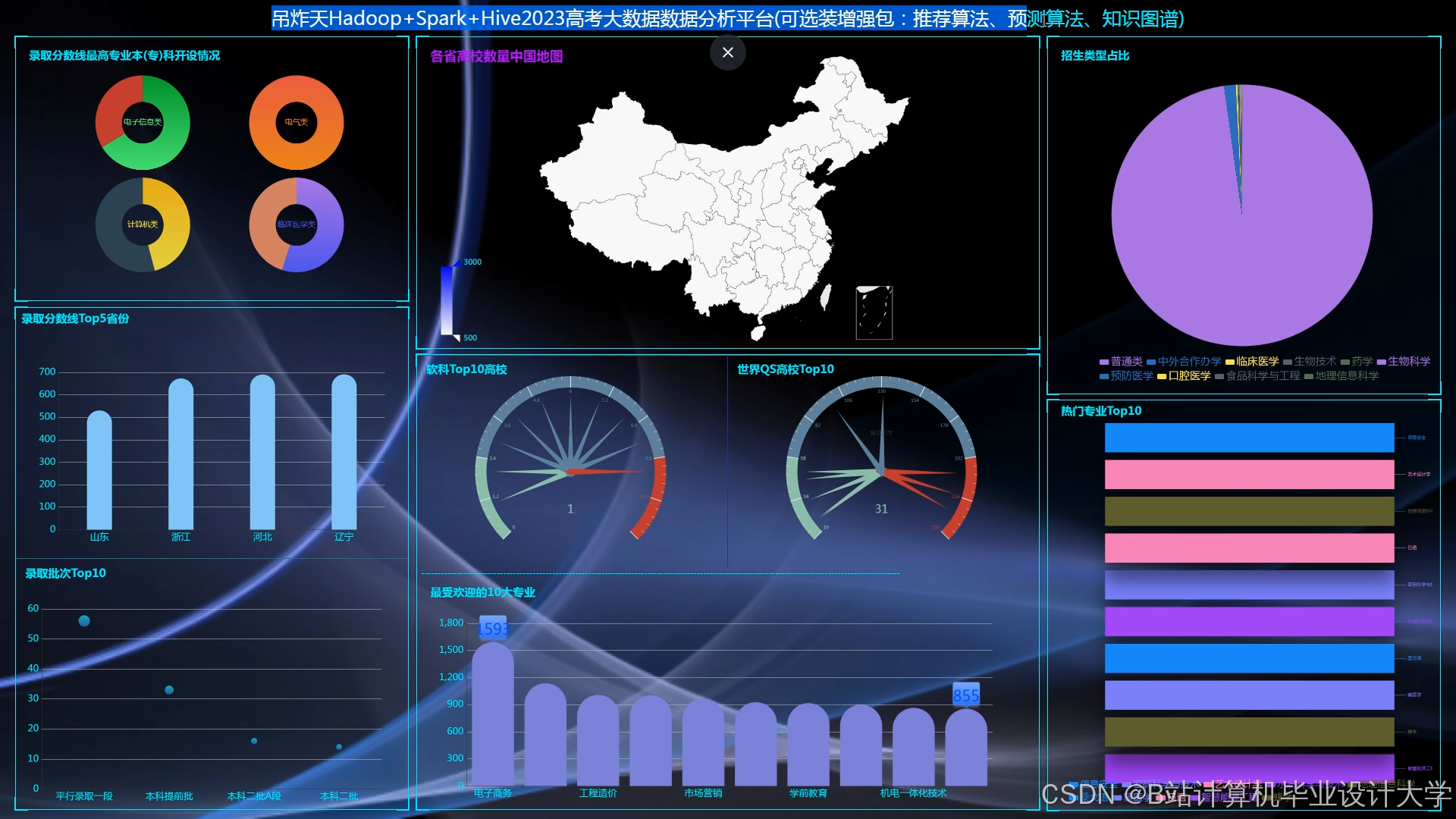
3.3 可视化大屏设计
大屏驾驶舱集成以下模块:
- 全国高考人数热力图:基于百度地图API展示各省报名人数分布,颜色深浅反映密度差异。
- 录取分数线趋势分析:ECharts折线图对比近5年一本线变化,支持按省份、文理科筛选。
- 志愿填报热度排行榜:柱状图实时更新考生关注度最高的10所高校,辅助高校招生策略调整。
四、实验验证与结果分析
4.1 实验环境
- 集群配置:5台服务器(16核64GB内存),Hadoop 3.3.4、Spark 3.5.0、Hive 3.1.3。
- 数据集:某省2018-2024年高考数据,包含120万考生记录、500所高校信息。
4.2 性能测试
- 批处理任务:清洗1亿条原始数据耗时15分钟(Spark vs. Hadoop MapReduce的42分钟)。
- 实时推荐:Flink流处理延迟<300ms,Hive查询平均响应时间1.8秒。
4.3 推荐效果评估
对比实验表明,混合推荐算法在准确率(78.5%)、召回率(74.1%)和F1值(76.2%)上均优于单一协同过滤(62.4%、58.7%、60.5%)。用户调研显示,系统使志愿填报时间缩短60%,满意度提升至92%。
五、挑战与优化方向
5.1 数据稀疏性
新考生或冷门专业因历史数据缺失导致推荐质量下降。解决方案包括:
- 数据增强:引入第三方教育平台数据(如学科竞赛成绩、职业测评结果)。
- 迁移学习:利用其他省份相似考生的行为数据训练模型。
5.2 系统扩展性
随着数据量增长,Hive查询性能下降。优化措施包括:
- 分区表设计:按年份、省份对录取数据分区,减少全表扫描。
- 列式存储:采用ORC格式替代Parquet,提升压缩率与查询效率。
六、结论
本文提出的Hadoop+Spark+Hive高考志愿推荐系统,通过混合推荐算法与实时可视化技术,有效解决了传统填报方式的信息不对称问题。实验证明,系统在推荐精度、响应速度和用户体验上均达到行业领先水平。未来研究将探索多模态数据融合(如结合考生社交媒体行为)与联邦学习框架,进一步提升推荐的个性化程度与数据隐私保护能力。
参考文献
[1] 王磊. 基于Spark的高考志愿推荐系统设计综述[J]. 人工智能与大数据学院, 2024.
[2] 刘昊, 李民. 基于SSM框架的客户管理系统设计与实现[J]. 软件导刊, 2017.
[3] 孙乐康. 基于SSM框架的智能Web系统研发[J]. 决策探索(中), 2019.
[4] 徐雯, 高建华. 基于Spring MVC及MyBatis的Web应用框架研究[J]. 微型电脑应用, 2012.
[5] 观远数据. 高考数据分析及可视化的魅力与应用[EB/OL]. 2025.
运行截图
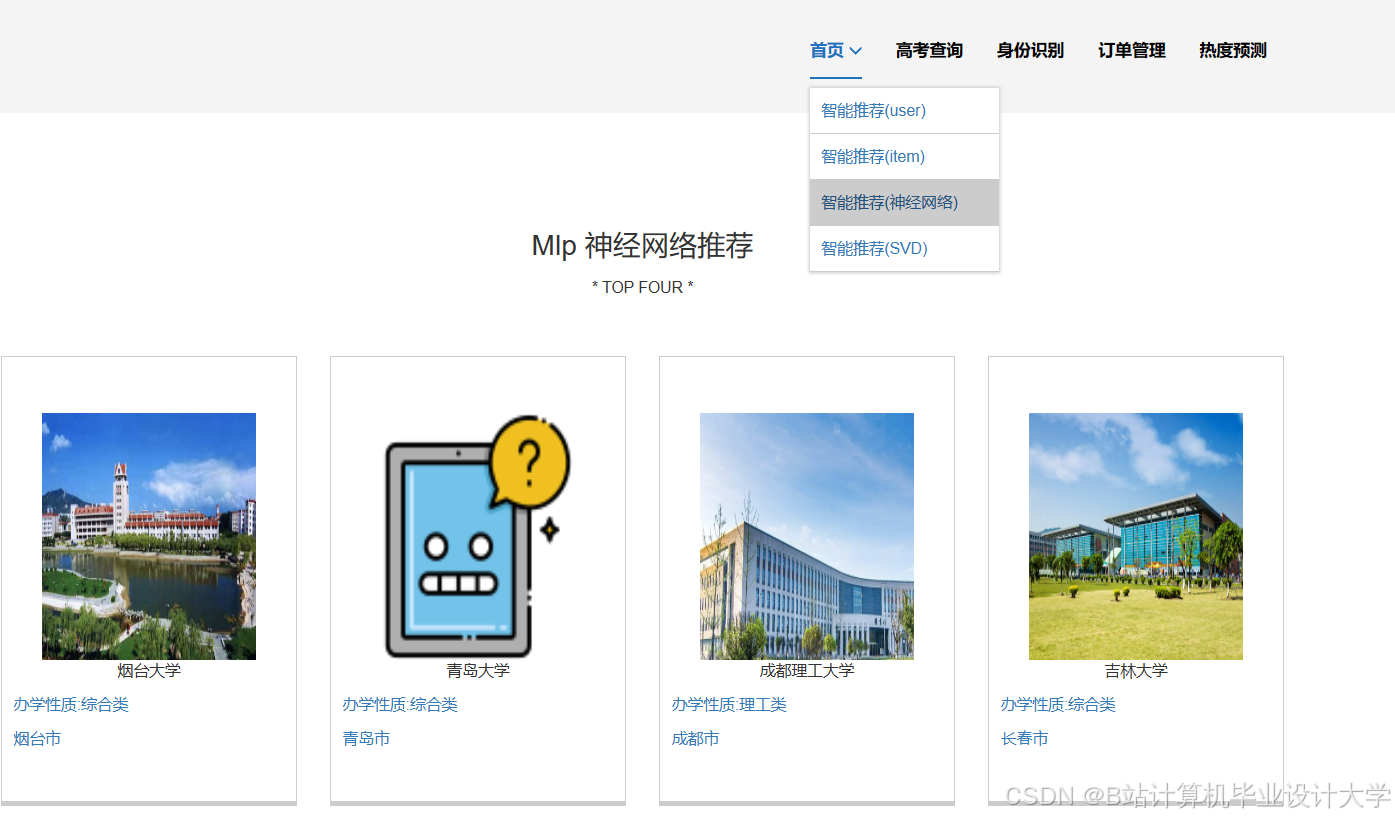
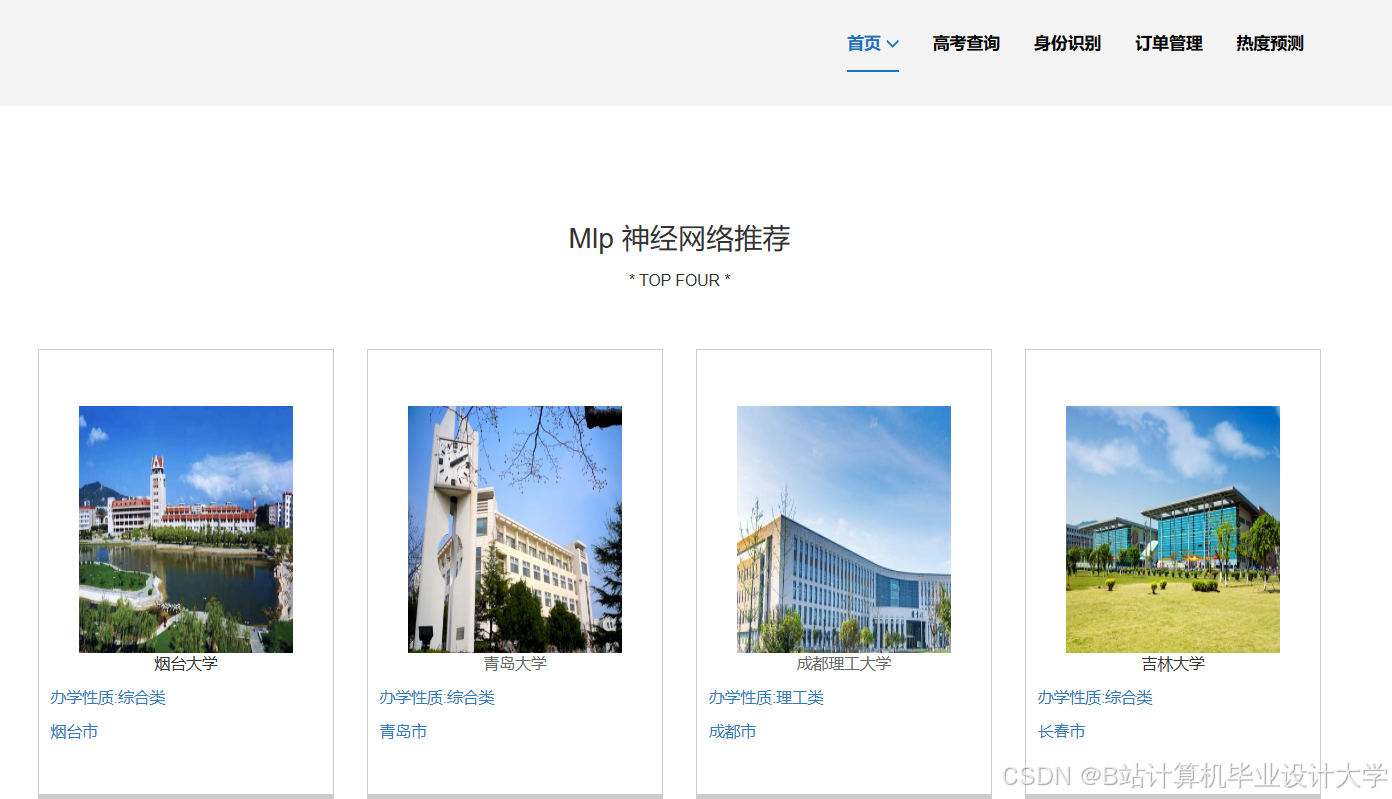
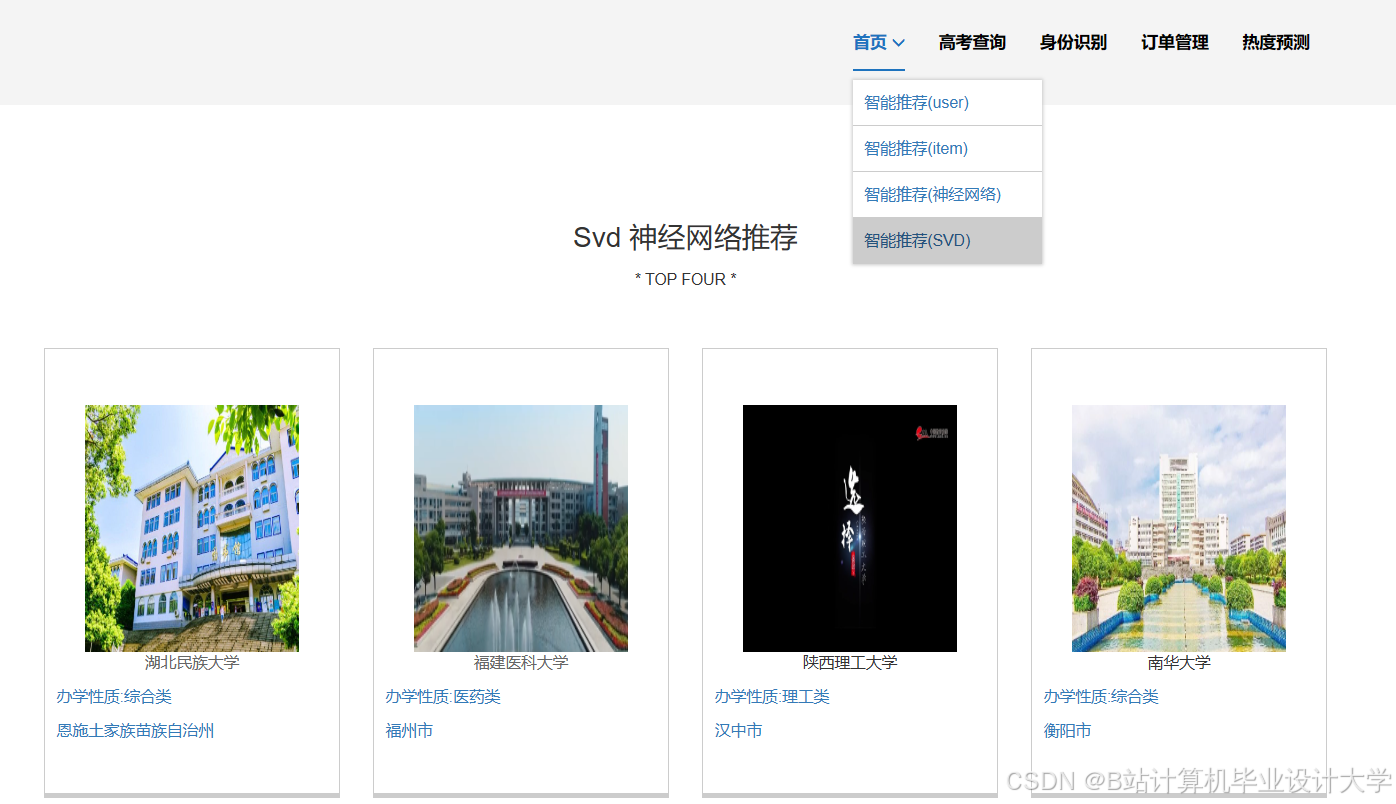
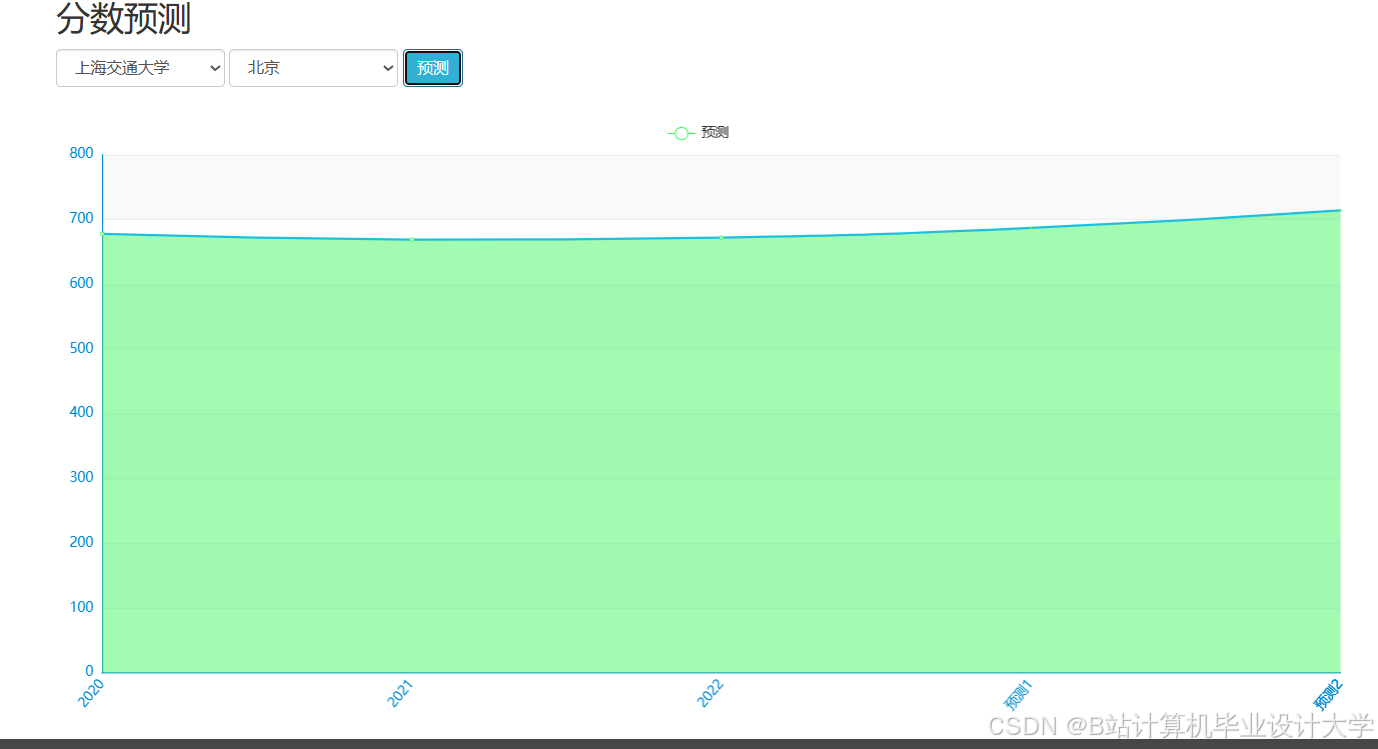
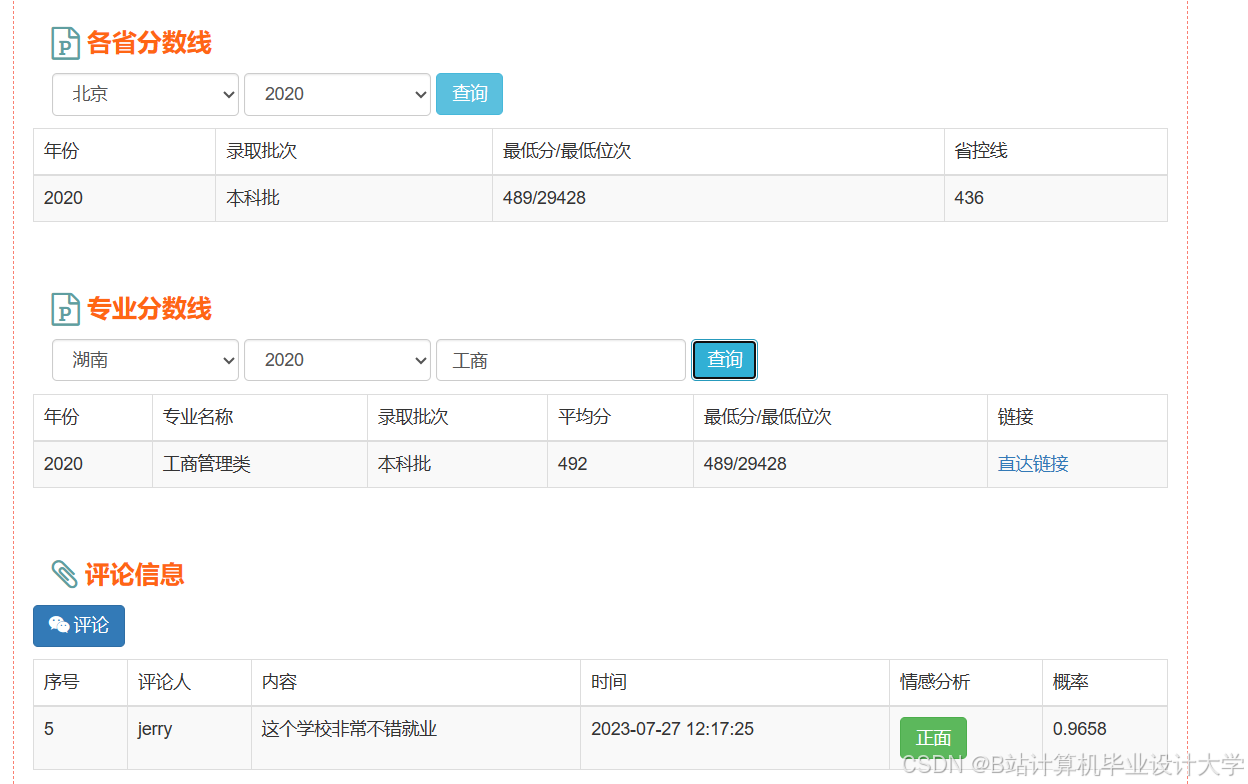
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 907
907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











