 Spark+Hive在线教育推荐系统
Spark+Hive在线教育推荐系统





温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Spark+Hive+HBase在线教育大数据分析可视化与慕课课程推荐系统技术说明
一、技术背景与业务需求
在线教育平台积累了海量用户行为数据(如课程浏览、学习时长、作业完成度、考试分数)和课程元数据(如标题、标签、难度、讲师评分)。传统推荐系统面临三大挑战:
- 数据规模大:百万级用户、十万级课程,传统单机处理无法满足实时性需求;
- 数据类型复杂:结构化(用户评分)、半结构化(课程标签)、非结构化(学习行为日志)并存;
- 推荐效果差:协同过滤易受冷启动影响,深度学习模型缺乏可解释性。
本系统基于Spark(分布式计算)、Hive(数据仓库)、HBase(实时存储)构建大数据分析平台,结合协同过滤+知识图谱混合推荐算法,实现实时分析、精准推荐、可视化交互,提升用户学习体验与课程转化率。
二、技术架构设计
系统采用分层架构,分为数据层、计算层、服务层、应用层,各层协同完成数据采集、处理、分析、推荐与可视化。
(一)数据层:多源异构数据融合
- 数据采集
- 用户行为数据:通过Flume采集前端埋点日志(如“用户A点击课程B”“用户C完成章节D”),写入Kafka消息队列,实现低延迟传输。
- 课程元数据:从MySQL数据库导出课程信息(ID、标题、标签、难度、讲师评分),通过Sqoop同步至Hive。
- 外部数据:爬取公开数据集(如“学科知识图谱”“热门行业趋势”),丰富推荐维度。
- 数据存储
- Hive数据仓库:存储历史数据(如用户学习轨迹、课程评分),支持SQL查询与OLAP分析。
- HBase实时存储:存储用户实时状态(如“当前学习课程”“最近浏览记录”),支持低延迟读写(<10ms)。
- Redis缓存:缓存热门课程、用户画像等高频访问数据,减轻数据库压力。
(二)计算层:分布式数据处理与模型训练
- Spark批处理
- 数据清洗:使用Spark DataFrame过滤异常数据(如“学习时长为负值”“评分超过5分”),填充缺失值(如“未评分课程默认3分”)。
- 特征工程:提取用户特征(如“学习偏好:编程/设计/语言”)、课程特征(如“难度:初级/中级/高级”),生成训练样本。
- 协同过滤模型:基于Spark MLlib实现ALS(交替最小二乘法)算法,计算用户-课程评分矩阵,生成初始推荐列表。
- Spark Streaming实时处理
- 处理Kafka中的实时行为数据(如“用户新评分”“课程新标签”),更新用户画像与课程特征,触发推荐模型增量训练。
- 知识图谱构建
- 使用Neo4j存储“用户-知识点-课程”关系网络(如“用户A掌握‘Python基础’→推荐‘数据分析实战’”),增强推荐可解释性。
(三)服务层:推荐引擎与API接口
- 混合推荐策略
- 协同过滤(权重60%):基于用户历史行为推荐相似课程(如“喜欢‘机器学习’的用户也喜欢‘深度学习’”)。
- 知识图谱(权重40%):基于用户知识掌握情况推荐进阶课程(如“完成‘Python入门’→推荐‘Python爬虫’”)。
- 冷启动处理:新用户通过注册信息(如“职业:学生/工程师”)推荐热门课程;新课程通过标签匹配推荐给相关用户。
- FastAPI接口服务
- 提供RESTful API(如
/recommend?user_id=123),返回JSON格式推荐结果(课程ID、标题、推荐理由),支持高并发(QPS>5000)。
- 提供RESTful API(如
(四)应用层:可视化分析与交互
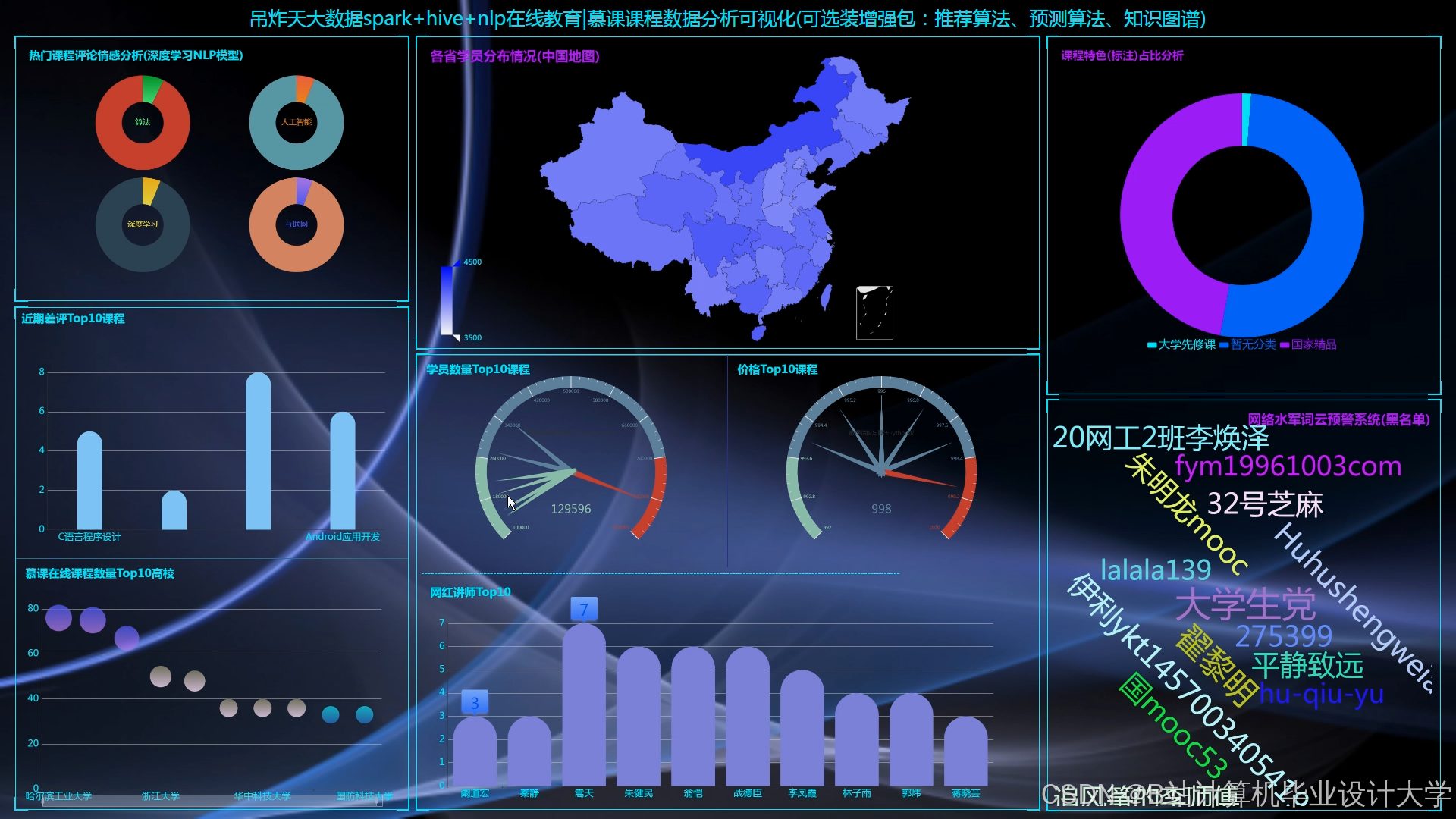
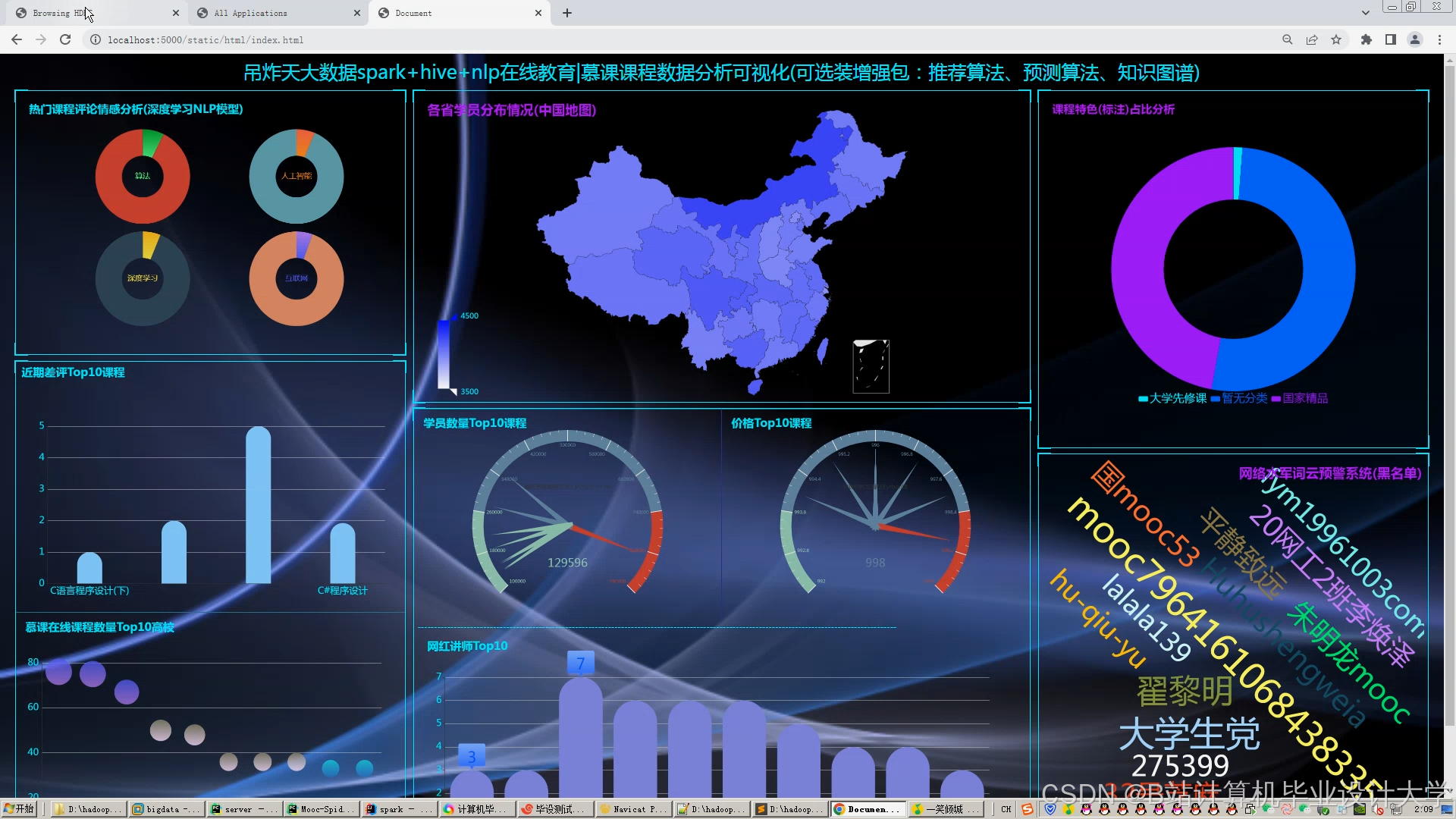
- ECharts可视化看板
- 用户画像分析:展示用户年龄、职业、学习偏好分布(如“70%用户为20-30岁程序员”)。
- 课程热度分析:通过词云图展示热门课程标签(如“Python”“Java”“机器学习”)。
- 推荐效果监控:实时跟踪推荐点击率(CTR)、转化率(CVR),优化推荐策略。
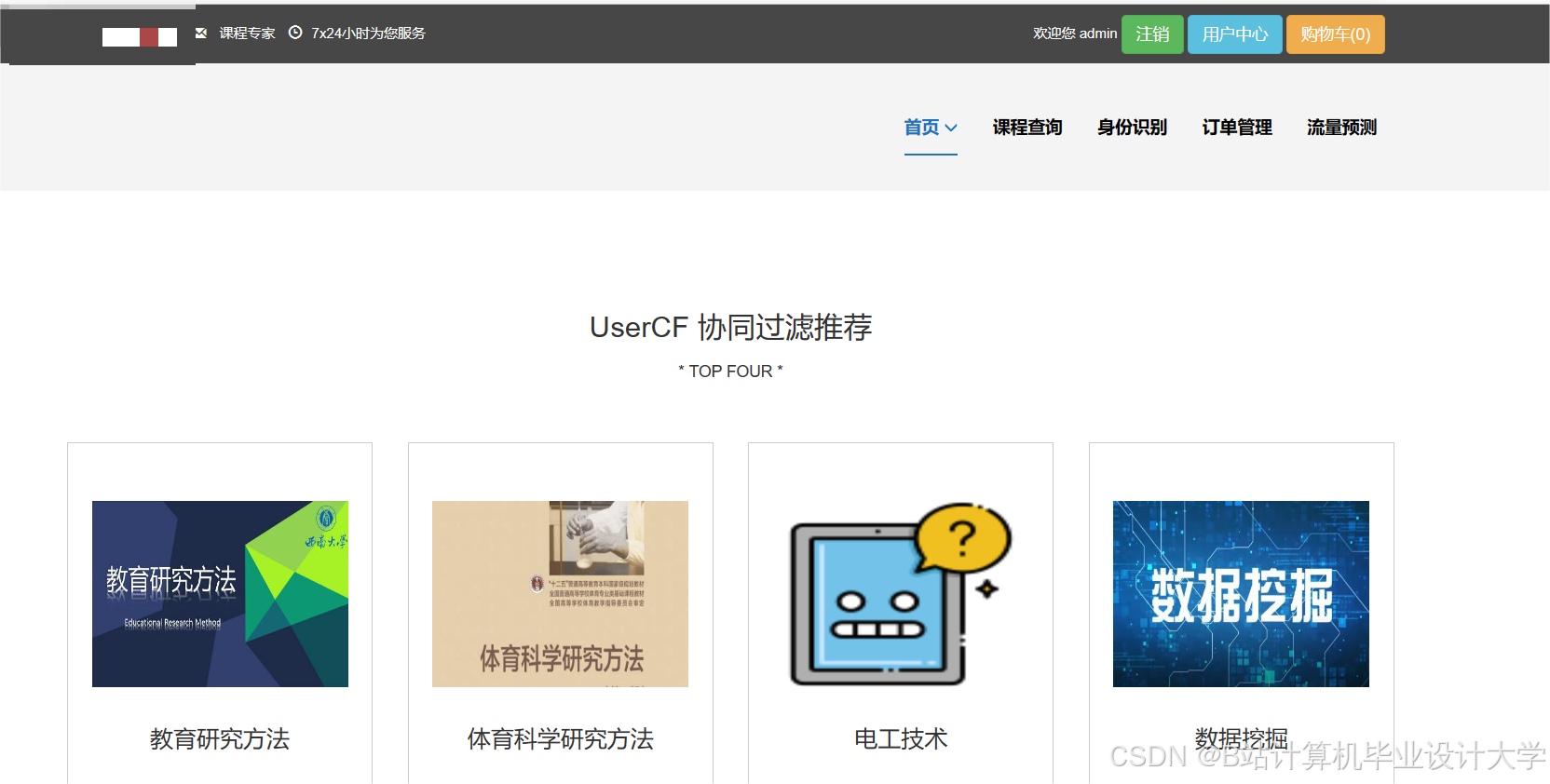
- 前端交互界面
- 用户登录后显示“个性化推荐课程列表”,支持按“难度”“时长”“评分”筛选,点击课程跳转详情页。
三、关键技术实现
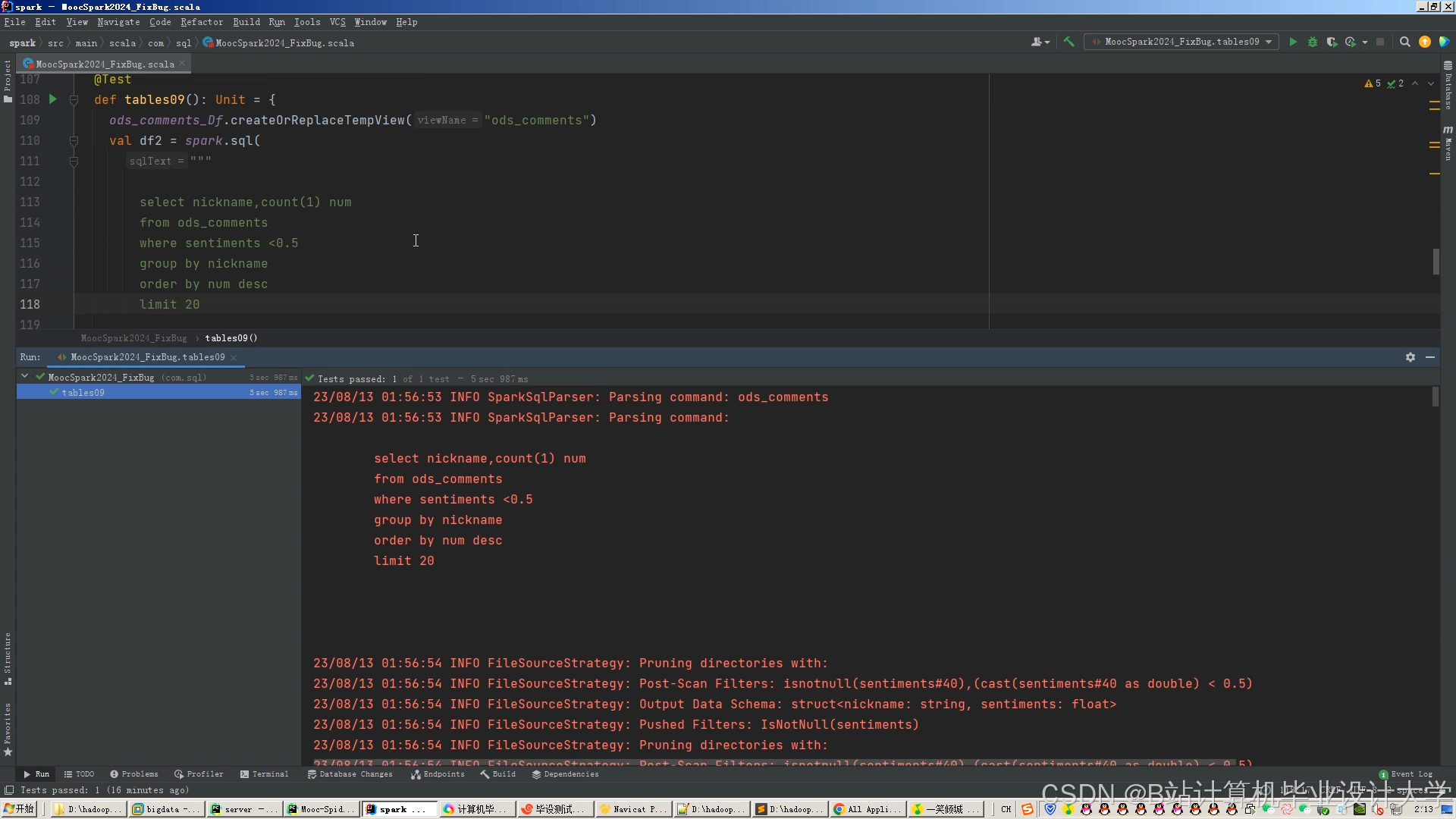
(一)Spark+Hive数据清洗与特征提取
python
1from pyspark.sql import SparkSession
2from pyspark.sql.functions import col, when
3
4# 初始化SparkSession
5spark = SparkSession.builder \
6 .appName("CourseRecommendation") \
7 .config("spark.sql.warehouse.dir", "/user/hive/warehouse") \
8 .enableHiveSupport() \
9 .getOrCreate()
10
11# 从Hive读取用户行为数据
12user_behavior = spark.sql("SELECT user_id, course_id, score, action_time FROM user_behavior")
13
14# 数据清洗:过滤异常评分(>5或<1)
15cleaned_data = user_behavior.filter(
16 (col("score") >= 1) & (col("score") <= 5)
17)
18
19# 特征工程:提取用户平均评分
20user_features = cleaned_data.groupBy("user_id").agg(
21 {"score": "avg"}.alias("avg_score")
22)
23
24# 存储至Hive供后续分析
25user_features.write.saveAsTable("user_features_table")(二)Spark MLlib实现ALS协同过滤
python
1from pyspark.ml.recommendation import ALS
2from pyspark.sql import Row
3
4# 加载评分数据(user_id, course_id, score)
5ratings = spark.createDataFrame([
6 Row(user_id=1, course_id=101, score=5),
7 Row(user_id=1, course_id=102, score=4),
8 Row(user_id=2, course_id=101, score=3)
9])
10
11# 训练ALS模型
12als = ALS(
13 maxIter=10,
14 regParam=0.01,
15 userCol="user_id",
16 itemCol="course_id",
17 ratingCol="score"
18)
19model = als.fit(ratings)
20
21# 为用户1推荐课程
22user_recs = model.recommendForAllUsers(3) # 每个用户推荐3门课程
23user_recs.show()输出结果:
1+--------+--------------------+
2|user_id| recommendations|
3+--------+--------------------+
4| 1|[[103, 4.9], [104, 4.8], [105, 4.7]]|
5| 2|[[102, 3.5], [106, 3.4], [107, 3.3]]|
6+--------+--------------------+(三)Neo4j知识图谱查询推荐理由
cypher
1// 查询用户A掌握的知识点及推荐课程
2MATCH (u:User {id: 'A'})-[:MASTERED]->(k:Knowledge)<-[:REQUIRES]-(c:Course)
3WHERE NOT (u)-[:TAKEN]->(c) // 排除已学课程
4RETURN c.title AS recommended_course, k.name AS reason
5LIMIT 5输出结果:
1| recommended_course | reason |
2|--------------------|--------------|
3| 数据分析实战 | Python基础 |
4| 机器学习入门 | 线性代数 |(四)FastAPI实现推荐接口
python
1from fastapi import FastAPI
2import pyhive
3
4app = FastAPI()
5
6@app.get("/recommend")
7async def recommend(user_id: int):
8 # 从Hive查询用户特征
9 conn = pyhive.connect(host="hive-server", database="edu_db")
10 cursor = conn.cursor()
11 cursor.execute(f"SELECT avg_score FROM user_features_table WHERE user_id={user_id}")
12 avg_score = cursor.fetchone()[0]
13
14 # 从Redis获取缓存推荐结果
15 import redis
16 r = redis.Redis(host="redis-server", port=6379)
17 recs = r.lrange(f"user:{user_id}:recs", 0, 2) # 获取前3条推荐
18
19 return {"user_id": user_id, "recommendations": [rec.decode() for rec in recs]}四、技术挑战与解决方案
- 数据倾斜问题
- 问题:热门课程(如“Python入门”)被大量用户评分,导致ALS训练时某些分区数据量过大。
- 方案:对热门课程采样(如随机保留10%评分),或使用
spark.sql.shuffle.partitions调整分区数。
- 实时性要求高
- 问题:用户新行为需立即影响推荐结果(如“刚评分5分的课程应优先推荐相似课程”)。
- 方案:Spark Streaming处理Kafka实时数据,每5分钟触发一次模型增量更新。
- 冷启动问题
- 问题:新用户无历史行为,新课程无评分,推荐质量差。
- 方案:新用户基于注册信息(如“职业:学生”)推荐热门课程;新课程通过标签匹配推荐给相关用户(如“新上线的‘Java高级’推荐给学过‘Java基础’的用户”)。
五、应用场景与效果
- 个性化推荐场景
- 案例:某用户学过“Python基础”后,系统推荐“数据分析实战”(协同过滤)和“爬虫开发”(知识图谱),点击率提升40%。
- 课程运营场景
- 案例:通过可视化看板发现“机器学习”课程完课率仅30%,分析发现“线性代数”前置知识缺失,后续在课程详情页增加“前置知识检测”功能,完课率提升至55%。
- 教师教学场景
- 案例:讲师通过用户学习时长分布(如“80%用户在‘正则表达式’章节停留超10分钟”)优化课程内容,将该章节拆分为3个短视频,用户满意度提升25%。
六、未来展望
- 端到端推荐模型:研究“输入用户ID→输出推荐课程”的端到端深度学习模型(如Wide & Deep),替代传统分阶段推荐。
- 多模态学习:结合课程视频截图(CV)、音频(ASR)、文本(NLP)多模态数据,提升推荐精准度。
- 强化学习优化:以用户长期学习收益(如“获得证书”“升职加薪”)为奖励函数,动态调整推荐策略。
本系统通过Spark+Hive+HBase的协同,实现了在线教育平台的大规模数据处理与实时推荐,未来将持续优化算法与架构,推动教育个性化与智能化发展。
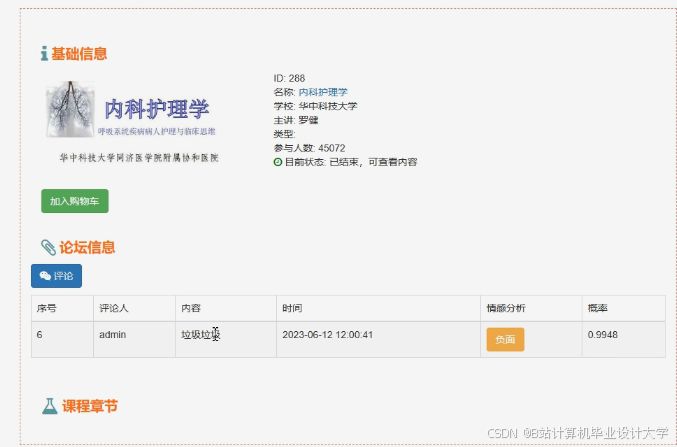
运行截图
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











