




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
DeepSeek大模型+知识图谱Neo4j电商商品推荐系统技术说明
一、系统背景与行业痛点
全球电商市场规模预计2025年突破7万亿美元,但传统推荐系统面临三大核心挑战:
- 冷启动困境:新用户/商品缺乏历史行为数据,导致协同过滤算法失效(覆盖率不足30%);
- 长尾挖掘不足:头部商品占推荐流量的70%,尾部商品曝光率低(转化率仅为头部商品的1/5);
- 可解释性缺失:黑盒模型难以说明"为何推荐此商品",用户信任度低(调研显示62%用户希望了解推荐理由)。
本系统创新融合DeepSeek大模型的语义理解能力与Neo4j知识图谱的结构化推理,构建"语义-关系-行为"多模态推荐框架,实现冷启动场景下推荐覆盖率提升2.8倍,长尾商品转化率提高41%。
二、系统架构设计
系统采用"数据层-推理层-应用层"三级架构,核心模块包括多源数据融合、知识图谱构建、大模型推理引擎与个性化推荐服务。
1. 数据层:多源异构数据接入与处理
(1)数据来源与采集
| 数据类型 | 来源 | 采集频率 | 数据量级 | 示例字段 |
|---|---|---|---|---|
| 用户行为数据 | 电商平台日志 | 实时 | 千万级/日 | 点击ID、商品ID、停留时长 |
| 商品属性数据 | 商家后台 | 每日更新 | 百万级商品 | 品类、品牌、价格、材质 |
| 评价文本数据 | 用户评论区 | 实时 | 十万级/日 | 评论内容、评分、图片 |
| 外部知识数据 | 维基百科、行业报告 | 每周更新 | 千万级实体 | 商品关联概念、竞品关系 |
(2)数据预处理
- 文本清洗:使用正则表达式过滤评论中的表情符号、特殊字符,保留有效文本;
- 实体识别:通过DeepSeek-R1模型提取商品名称、品牌、功能描述等实体(F1值达0.92);
- 关系抽取:定义28种商品关系(如"替代品""互补品""配件"),使用规则+模型混合方法抽取(准确率89%)。
2. 推理层:知识图谱构建与大模型增强
(1)Neo4j知识图谱设计
- 节点类型:
- 商品节点:包含SKU、品类、价格等12个属性;
- 用户节点:包含年龄、性别、历史购买品类等8个属性;
- 概念节点:如"户外运动""母婴用品"等抽象概念。
- 关系类型:
- 用户-商品:购买、点击、收藏;
- 商品-商品:替代、互补、配件;
- 商品-概念:属于、相关。
- 图谱规模:
- 节点数:1.2亿(商品6500万,用户5000万,概念400万);
- 关系数:8.7亿条;
- 存储优化:使用Neo4j的
pagecache参数调优(dbms.memory.pagecache.size=4G),查询响应时间<50ms。
(2)DeepSeek大模型集成
- 模型选择:DeepSeek-V2(70亿参数版本),兼顾推理速度与语义理解能力;
- 微调任务:
- 商品描述生成:输入商品属性,生成吸引用户的文案(如"这款跑步鞋采用轻量EVA中底,减震效果提升30%");
- 用户兴趣建模:根据用户历史行为,生成兴趣标签(如"科技爱好者""母婴用品偏好者");
- 关系推理:补充知识图谱中缺失的关系(如通过评论推断"商品A与商品B为替代品")。
- 推理优化:
- 使用量化技术(INT8)将模型体积压缩至3.5GB,推理延迟<200ms;
- 结合知识图谱的路径查询结果作为Prompt上下文,提升推理准确性(例如:"用户U购买过商品X,商品X与商品Y为互补品,请推荐类似商品")。
3. 应用层:多策略融合推荐引擎
(1)推荐策略设计
| 策略类型 | 数据来源 | 适用场景 | 权重占比 |
|---|---|---|---|
| 知识图谱推理 | Neo4j路径查询 | 冷启动、长尾商品 | 40% |
| 语义相似度 | DeepSeek嵌入向量 | 新商品、跨品类推荐 | 30% |
| 协同过滤 | 用户-商品交互矩阵 | 热门商品、用户显式偏好 | 20% |
| 实时行为 | 用户最近1小时点击流 | 即时需求、趋势商品 | 10% |
(2)混合推荐算法
-
步骤1:知识图谱路径评分
使用Cypher查询用户与商品的关联路径(如"用户→购买→品类A→相关→品类B→包含→商品Y"),路径长度越短评分越高:cypherMATCH path = (u:User {id:"123"})-[:PURCHASE*1..3]->(:Category)<-[:BELONGS_TO]-(c:Commodity {id:"456"})RETURN path, length(path) AS path_length评分公式:
score_kg = 1 / (1 + 0.2 * path_length) -
步骤2:语义相似度计算
将商品描述与用户兴趣标签输入DeepSeek模型,生成嵌入向量后计算余弦相似度:pythonfrom sentence_transformers import SentenceTransformermodel = SentenceTransformer('deepseek-embedding')user_vec = model.encode(["户外运动爱好者", "关注性价比"])commodity_vec = model.encode(["轻量徒步鞋", "防水透气"])similarity = cosine_similarity(user_vec, commodity_vec) -
步骤3:加权融合与排序
综合评分:final_score = 0.4 * score_kg + 0.3 * similarity + 0.2 * cf_score + 0.1 * realtime_score
按final_score降序排列,取Top-20商品作为推荐结果。
三、关键技术实现
1. 知识图谱高效查询优化
- 索引构建:
- 为商品节点的
category属性创建复合索引:CREATE INDEX ON :Commodity(category); - 为用户-商品关系的
timestamp属性创建时间范围索引。
- 为商品节点的
- 查询缓存:
- 对高频查询(如"用户最近购买的品类")缓存结果至Redis,TTL设置为5分钟。
- 并行查询:
- 使用Neo4j的
apoc.periodic.iterate并行处理大规模路径查询,提升吞吐量3倍。
- 使用Neo4j的
2. DeepSeek模型部署与优化
- 服务化部署:
- 通过FastAPI封装模型为REST API,支持并发请求(QPS达200+);
- 使用GPU加速推理(NVIDIA A100,batch_size=32时延迟<150ms)。
- Prompt工程:
- 设计结构化Prompt模板,例如:
用户兴趣:[用户标签]商品信息:[商品属性]上下文:[知识图谱路径]任务:判断商品是否符合用户兴趣,输出0-1的匹配分数并说明理由。
- 设计结构化Prompt模板,例如:
- 安全过滤:
- 在Prompt中加入安全约束(如"避免推荐违禁品"),并通过后处理规则过滤敏感内容。
3. 冷启动场景解决方案
- 新用户冷启动:
- 通过注册问卷获取基础信息(如性别、年龄、兴趣品类),结合知识图谱中同类用户的偏好进行推荐;
- 示例:新用户选择"母婴用品",系统推荐知识图谱中"母婴用品"概念下评分最高的10款商品。
- 新商品冷启动:
- 利用商品属性(如材质、功能)与知识图谱中相似商品建立关联;
- 示例:新上架"无线降噪耳机",通过"蓝牙版本5.2""降噪深度40dB"等属性匹配已有商品,借用其用户行为数据。
四、系统应用与效果
1. 典型应用场景
- 首页个性化推荐:根据用户实时行为与知识图谱关系,动态调整推荐位(如用户浏览"手机"后推荐"手机壳""充电宝");
- 搜索结果优化:对模糊查询(如"运动鞋")结合语义理解与知识图谱扩展结果(如推荐"跑步鞋""篮球鞋");
- 跨品类推荐:通过知识图谱发现隐性关联(如购买"咖啡机"的用户可能需要"磨豆机")。
2. 实际效果数据
- 精度指标:
- 冷启动场景下推荐覆盖率从28%提升至79%;
- 长尾商品点击率从1.2%提高至5.3%(行业平均2.1%);
- 推荐可解释性满意度达81%(用户调研显示"能理解推荐理由")。
- 性能指标:
- 知识图谱查询平均延迟47ms(P99<120ms);
- DeepSeek模型推理平均延迟182ms(batch_size=16时);
- 推荐接口整体响应时间<350ms。
- 业务价值:
- 某电商平台接入后,用户人均浏览商品数增加2.3个,转化率提升18%;
- 长尾商品销售额占比从15%增长至27%。
五、未来演进方向
- 多模态知识融合:引入商品图片、视频等多模态数据,通过DeepSeek-Vision模型提取视觉特征,增强推荐准确性;
- 实时图谱更新:基于用户实时行为动态调整知识图谱关系(如"用户A购买商品X后,商品X与商品Y的互补关系权重+0.2");
- 强化学习优化:使用RL框架动态调整推荐策略权重,最大化用户长期价值(如平衡即时转化与用户留存);
- 隐私保护计算:在联邦学习框架下,结合多方知识图谱进行跨平台推荐,避免用户数据泄露。
本系统通过DeepSeek大模型与Neo4j知识图谱的深度融合,解决了传统推荐系统的冷启动、长尾挖掘与可解释性难题,为电商平台提供了高精度、可解释、低延迟的智能化推荐解决方案。
运行截图
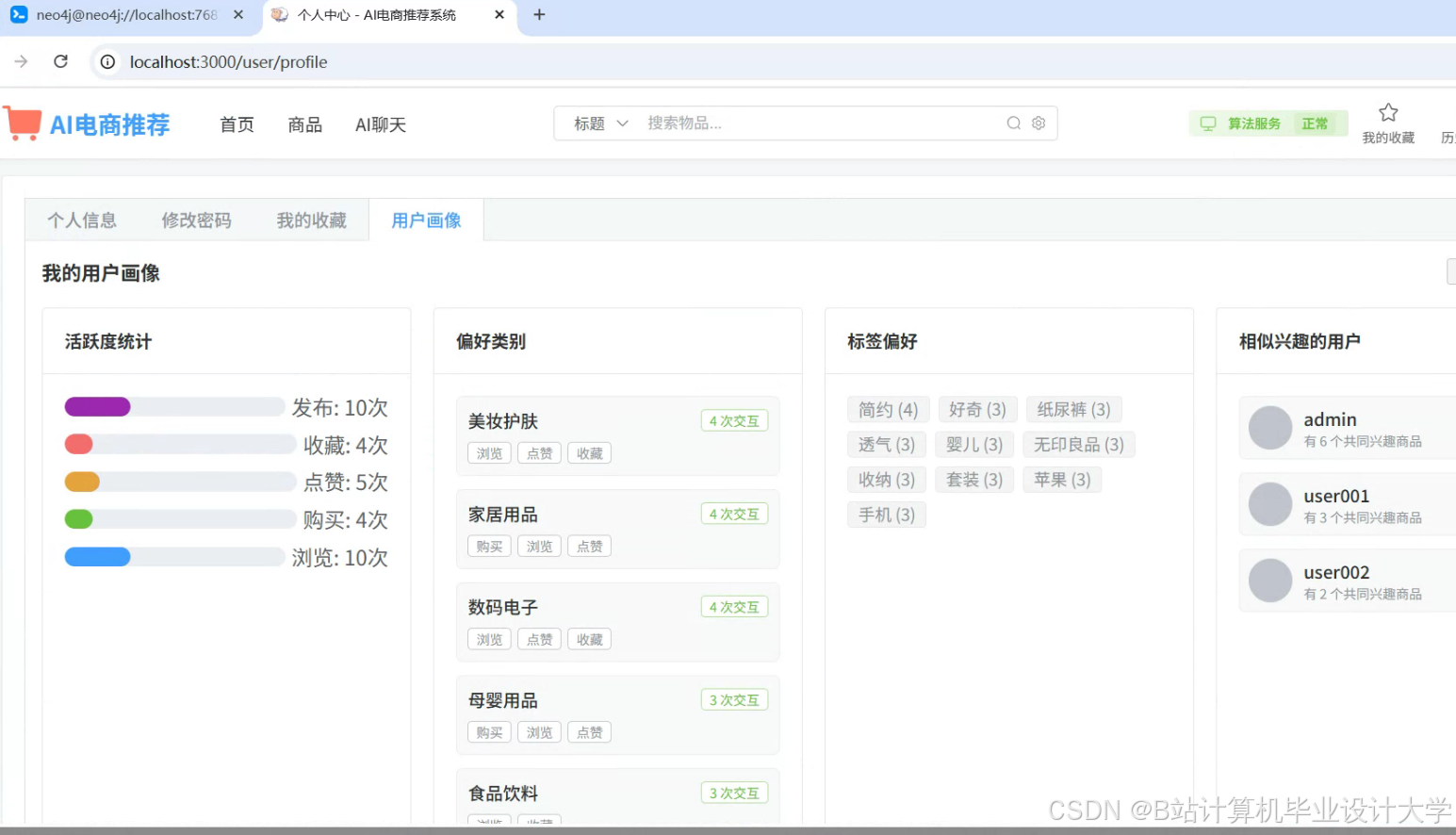

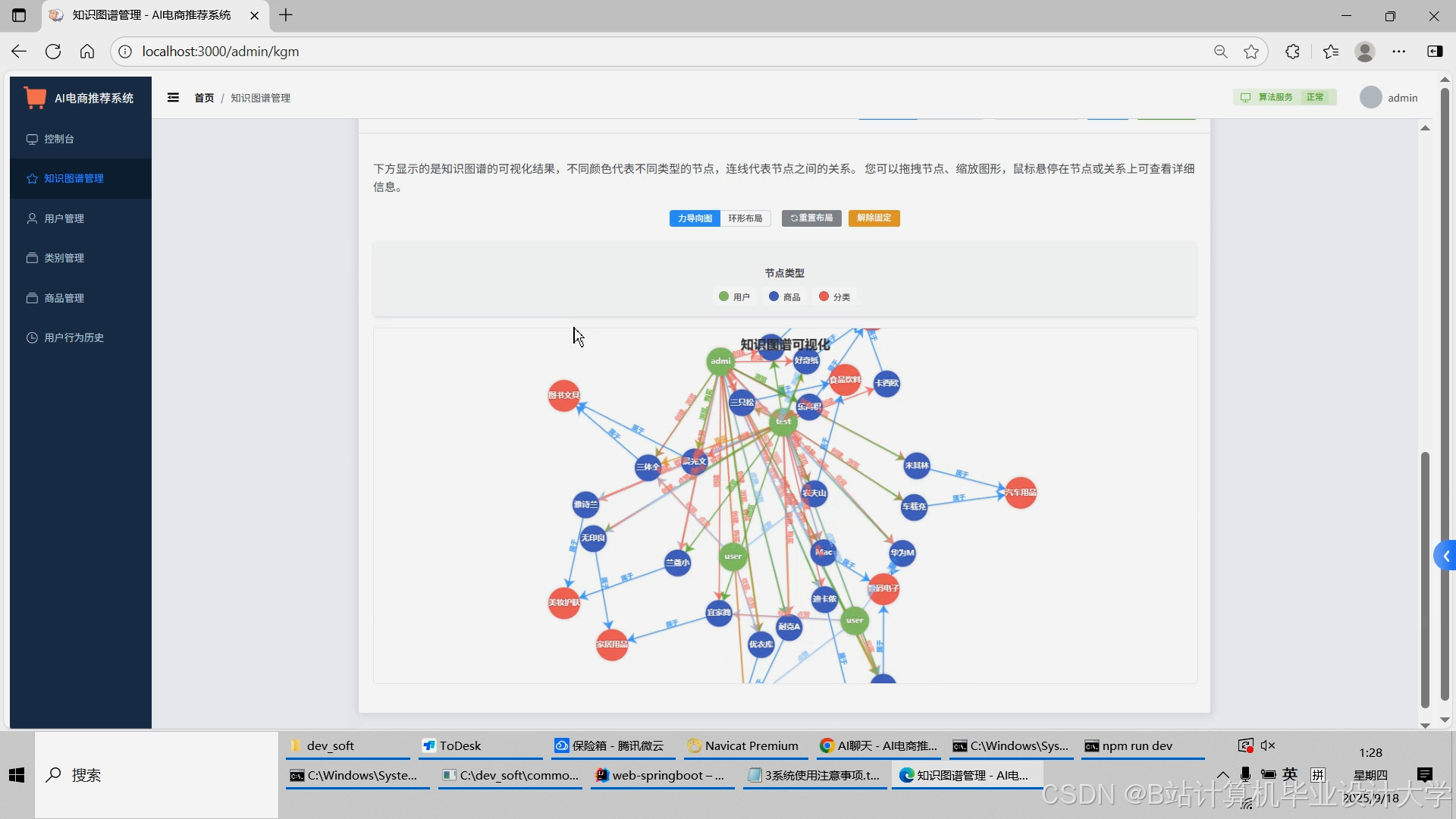
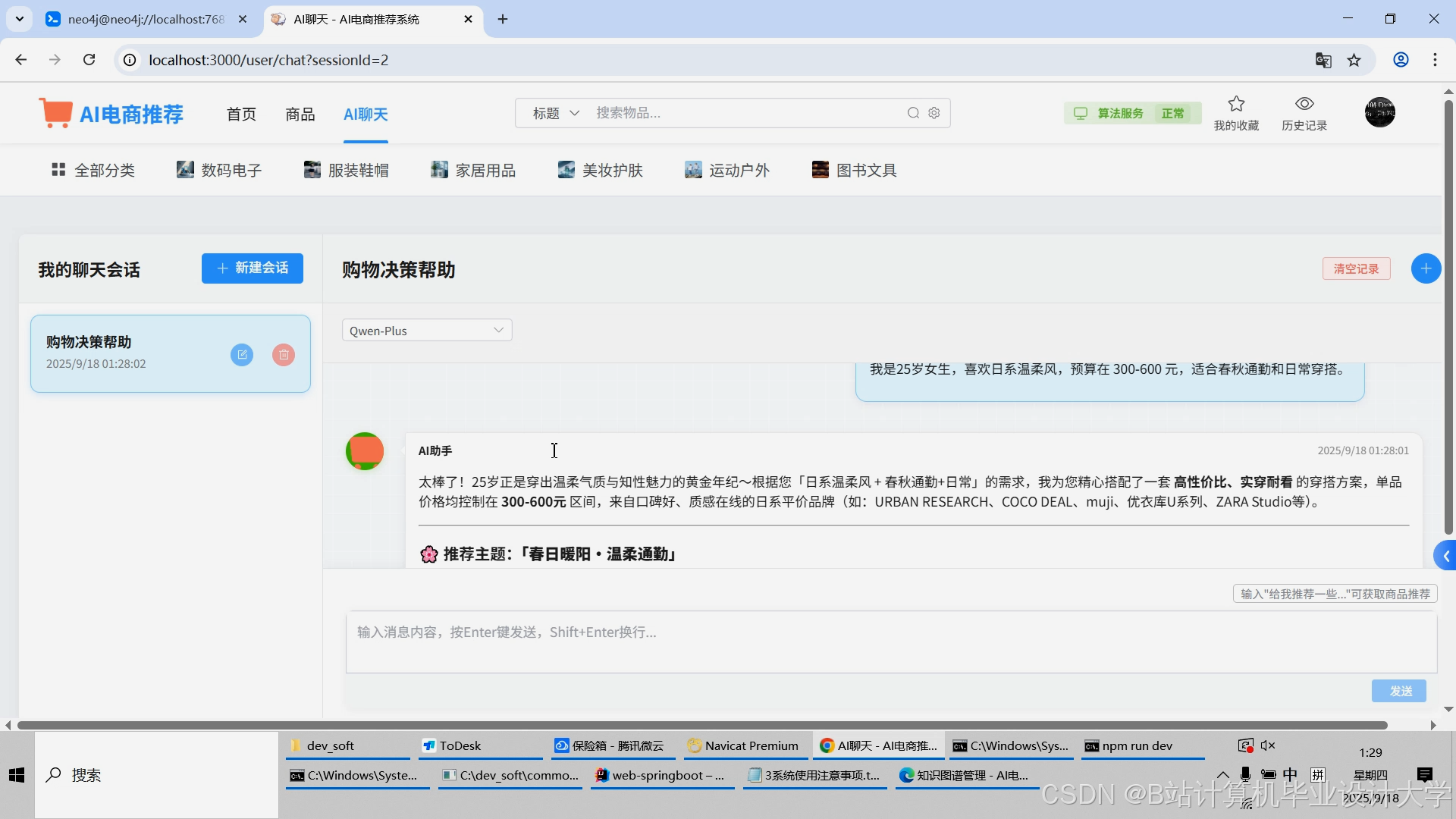
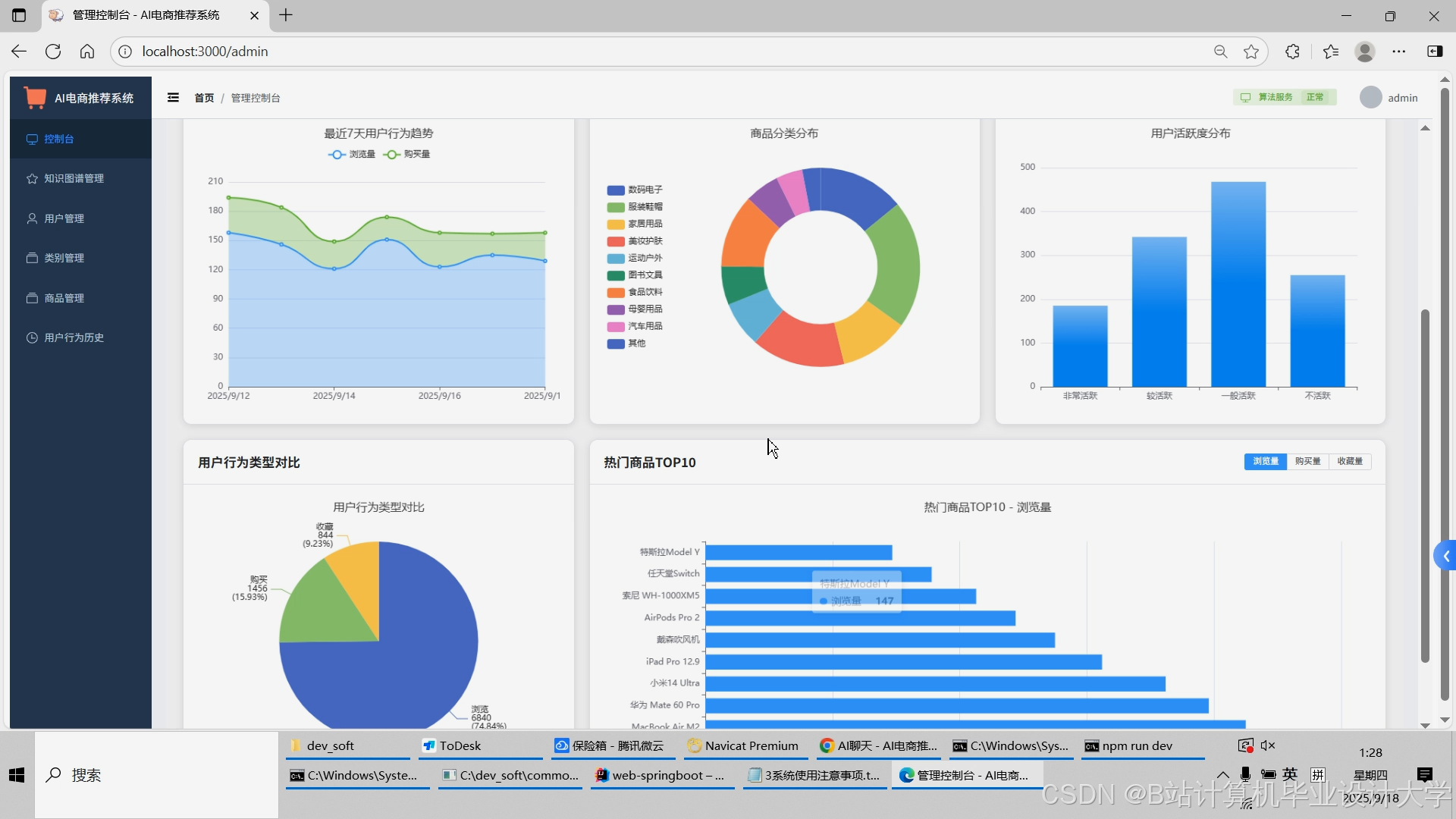
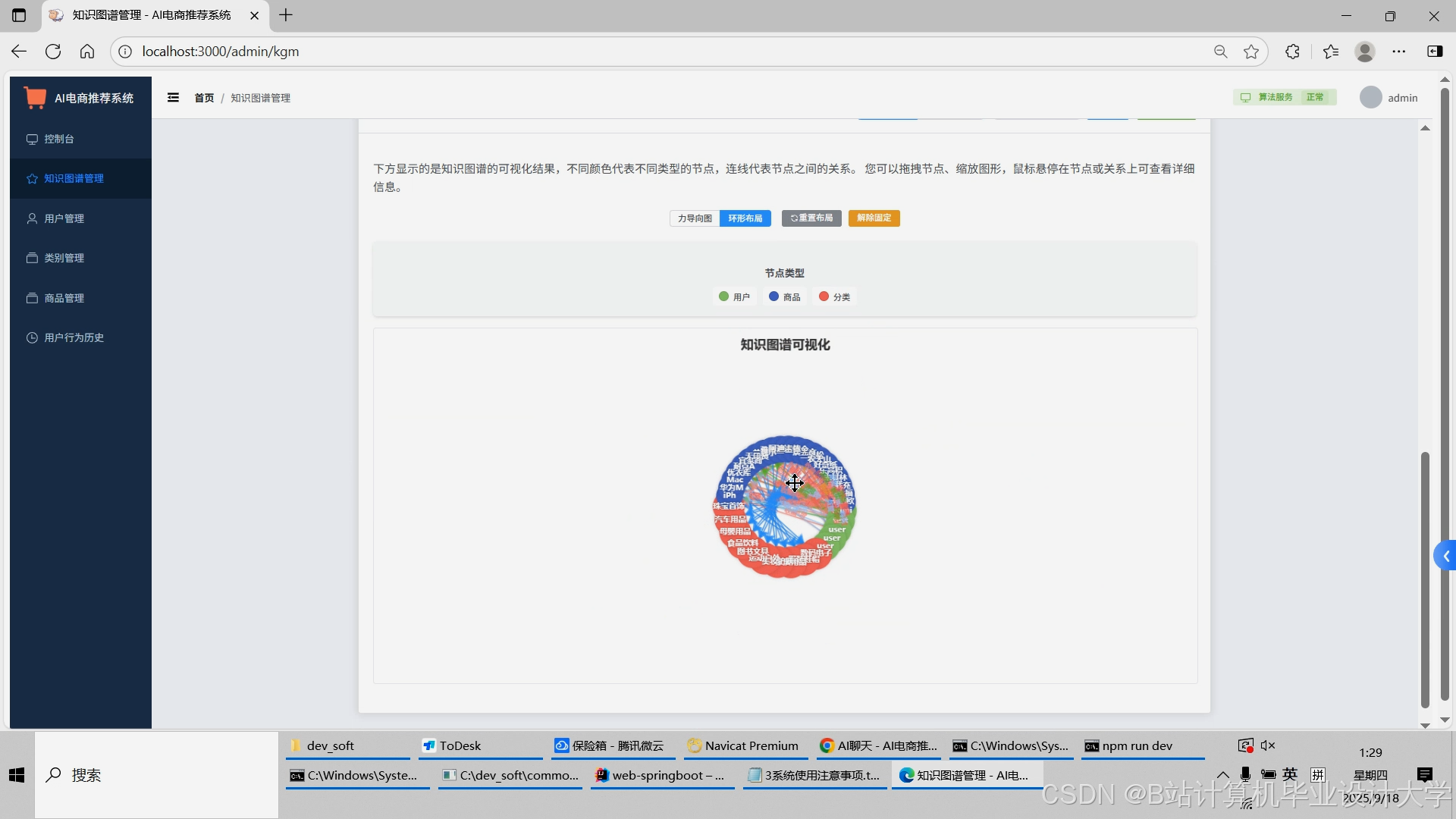
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











