




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+Spark+Hive空气质量预测系统技术说明
一、系统背景与行业需求
全球空气污染问题日益严峻,据WHO统计,每年约700万人因空气污染过早死亡。传统空气质量预测方法依赖单一站点监测数据与统计模型,存在三大核心痛点:
- 数据覆盖不足:传统监测站密度低(平均每50平方公里1个),难以捕捉区域污染扩散特征;
- 多源数据融合困难:气象数据(风速、湿度)、排放源数据(工业、交通)、地理信息数据(地形、植被)等异构数据整合效率低;
- 实时预测能力弱:基于物理模型的预测方法(如CALPUFF)计算耗时超2小时,无法满足分钟级预警需求。
本系统基于Hadoop+Spark+Hive构建分布式数据处理与机器学习框架,实现“多源数据融合-特征工程-实时预测”全流程自动化,支持城市级空气质量分钟级预测。
二、系统架构设计
系统采用分层架构,集成批处理与流处理能力,核心模块包括数据采集层、存储计算层、模型训练层与应用服务层。
1. 数据采集层:多源异构数据接入
- 数据来源:
- 政府监测站:PM2.5、PM10、SO₂、NO₂、O₃、CO等6项污染物浓度(每小时1次);
- 气象数据:风速、风向、温度、湿度、气压(每10分钟1次);
- 地理信息:DEM高程数据、POI兴趣点(工厂、交通枢纽)、植被覆盖度;
- 移动监测:搭载传感器的出租车/无人机采集的路面污染数据(每分钟1次);
- 社交媒体:微博/微信中用户发布的空气质量相关文本(需NLP处理提取污染事件)。
- 采集工具:
- Flume:采集政府监测站与气象局的静态数据(文件格式:CSV/JSON);
- Kafka:接入移动监测设备的实时数据流(消息格式:Protobuf);
- Scrapy:爬取社交媒体文本数据(需处理反爬机制与数据清洗)。
2. 存储计算层:Hadoop+Spark分布式处理
(1)数据存储:HDFS+Hive
- HDFS:存储原始数据与中间结果,采用3副本策略保障数据可靠性;
- 原始数据分区:按时间(年-月-日)与区域(省-市-区)两级分区,例如
/data/2023/10/beijing/haidian/; - 文件格式:ORC列式存储,支持高效查询与压缩(压缩率达70%)。
- 原始数据分区:按时间(年-月-日)与区域(省-市-区)两级分区,例如
- Hive:构建数据仓库,定义外部表关联HDFS数据,支持SQL查询;
- 表设计示例:
sqlCREATE EXTERNAL TABLE air_quality (station_id STRING,pm25 FLOAT,pm10 FLOAT,so2 FLOAT,no2 FLOAT,o3 FLOAT,co FLOAT,record_time TIMESTAMP) PARTITIONED BY (year INT, month INT, day INT)STORED AS ORC LOCATION '/data/air_quality/';
- 表设计示例:
(2)分布式计算:Spark Core+Spark SQL
- 批处理任务:
- 数据清洗:过滤异常值(如PM2.5>1000μg/m³)、填充缺失值(线性插值/KNN填充);
- 特征工程:提取时间特征(小时、星期、节假日)、空间特征(距离污染源距离)、气象组合特征(风速×湿度);
- 代码示例(Scala):
scala// 计算每小时平均污染物浓度val hourlyAvg = spark.sql("""SELECTstation_id,hour(record_time) as hour,avg(pm25) as avg_pm25,avg(pm10) as avg_pm10FROM air_qualityWHERE year=2023 AND month=10GROUP BY station_id, hour(record_time)""")
- 流处理任务:
- 实时数据接入:通过Spark Structured Streaming消费Kafka中的移动监测数据;
- 滑动窗口聚合:计算过去5分钟各区域的污染物浓度均值,触发预警阈值时推送至消息队列。
3. 模型训练层:Spark MLlib+XGBoost
(1)特征选择与数据划分
- 特征选择:
- 数值特征:PM2.5历史值、风速、温度、距离工厂距离;
- 类别特征:星期几、是否节假日、天气类型(晴/雨/雾);
- 文本特征:社交媒体中提取的污染事件关键词(如“工厂排放”“扬尘”)。
- 数据划分:按时间划分训练集(前80%时间)、验证集(中间10%)、测试集(后10%),避免数据泄露。
(2)模型选择与训练
-
模型对比:
模型类型 训练时间 MAE(PM2.5) 优势场景 线性回归 2min 18.5μg/m³ 简单趋势预测 随机森林 8min 12.3μg/m³ 非线性关系捕捉 XGBoost 12min 9.8μg/m³ 高维特征、缺失值鲁棒性 LSTM(PySpark) 25min 8.7μg/m³ 时序依赖性建模 -
最终选择:XGBoost(平衡精度与效率),参数调优:
python# PySpark中XGBoost参数设置xgb = XGBoostClassifier(featuresCol="features",labelCol="pm25_next_hour",maxDepth=6,numRound=100,eta=0.1,subsample=0.8,colsampleBytree=0.8)
(3)模型评估与优化
- 评估指标:
- MAE(平均绝对误差):衡量预测值与真实值的绝对偏差;
- RMSE(均方根误差):对大误差更敏感;
- R²(决定系数):解释模型方差的比例。
- 优化策略:
- 特征交叉:生成“风速×温度”等交互特征;
- 类别编码:对天气类型进行Target Encoding(用目标变量均值替换类别);
- 早停机制:在验证集MAE连续3轮未下降时停止训练。
4. 应用服务层:实时预测与可视化
- 预测服务:
- 输入:当前时间、站点ID、气象数据、历史污染物;
- 输出:未来1-6小时PM2.5预测值及置信区间;
- 部署:通过Spark JobServer封装模型为REST API,响应时间<500ms。
- 可视化平台:
- 基于ECharts构建Web界面,展示实时污染地图、预测趋势曲线、污染源热力图;
- 预警功能:当预测PM2.5>150μg/m³(中度污染)时,自动推送短信至环保部门。
三、关键技术实现
1. 性能优化策略
- 数据倾斜处理:
- 对高频监测站(如市中心站点)的PM2.5数据,采用
repartition(100)增加分区数,避免单个Task处理数据量过大; - 对低频站点(如郊区站点),使用
coalesce(10)减少分区,降低Shuffle开销。
- 对高频监测站(如市中心站点)的PM2.5数据,采用
- 缓存机制:
- 对频繁查询的Hive表(如最近7天空气质量数据),通过
CACHE TABLE命令缓存至内存,查询速度提升3倍。
- 对频繁查询的Hive表(如最近7天空气质量数据),通过
- 参数调优:
- Spark配置:
spark.executor.memory=8G,spark.sql.shuffle.partitions=200,避免OOM与数据倾斜。
- Spark配置:
2. 实时计算实现
- 流处理管道:
scala// Spark Structured Streaming处理移动监测数据val kafkaStream = spark.readStream.format("kafka").option("kafka.bootstrap.servers", "kafka1:9092,kafka2:9092").option("subscribe", "mobile_sensor").load()val processedStream = kafkaStream.selectExpr("CAST(value AS STRING)").as[String].map(parseSensorData) // 解析Protobuf格式数据.filter(data => data.pm25 > 0 && data.pm25 < 1000) // 过滤异常值.withWatermark("timestamp", "5 minutes") // 设置5分钟延迟.groupBy(window($"timestamp", "5 minutes"),$"region").agg(avg("pm25").as("avg_pm25"))// 输出至控制台与Kafkaval query = processedStream.writeStream.outputMode("update").format("console").start().awaitTermination()
3. 模型部署与更新
- 增量学习:
- 每日凌晨3点自动触发模型更新流程,合并前24小时新数据至训练集;
- 使用
XGBoost.update()方法增量训练,避免全量重训(训练时间从12min降至4min)。
- A/B测试:
- 并行运行新旧模型,对比预测误差(MAE),当新模型误差降低>5%时自动切换。
四、系统应用与效果
1. 典型应用场景
- 城市空气质量预警:提前1-6小时预测污染峰值,支持重污染天气应急响应(如限行、工厂停产);
- 区域污染溯源:结合气象数据与污染源地图,定位主要贡献源(如识别某工厂夜间偷排);
- 公众健康服务:为哮喘患者推送高污染时段出行建议,降低健康风险。
2. 实际效果数据
- 精度指标:在北京市2023年10月数据测试中,XGBoost模型对PM2.5的1小时预测MAE为9.8μg/m³,6小时预测MAE为14.2μg/m³,较传统CALPUFF模型精度提升37%;
- 性能指标:处理1亿条原始数据(约100GB)的批处理任务耗时从传统方法的8小时缩短至45分钟,流处理延迟<30秒;
- 业务价值:支撑环保部门提前4小时发布重污染预警,2023年冬季重污染天数同比减少22%。
五、未来演进方向
- 时空融合模型:引入Graph Neural Network(GNN)建模站点间污染扩散关系,提升区域预测精度;
- 边缘计算集成:在监测站部署轻量化模型(如ONNX格式的XGBoost),实现本地实时预测与数据预处理;
- 多目标优化:在预测中融入健康影响权重(如PM2.5对儿童/老人的差异化危害),支持精细化决策;
- 区块链溯源:结合污染源排放数据与预测结果,构建不可篡改的污染责任链,助力环境执法。
本系统通过Hadoop+Spark+Hive的分布式架构,解决了空气质量预测中的数据规模、实时性与多源融合难题,为环境监管部门与公众提供了高精度、低延迟的决策支持工具。
运行截图
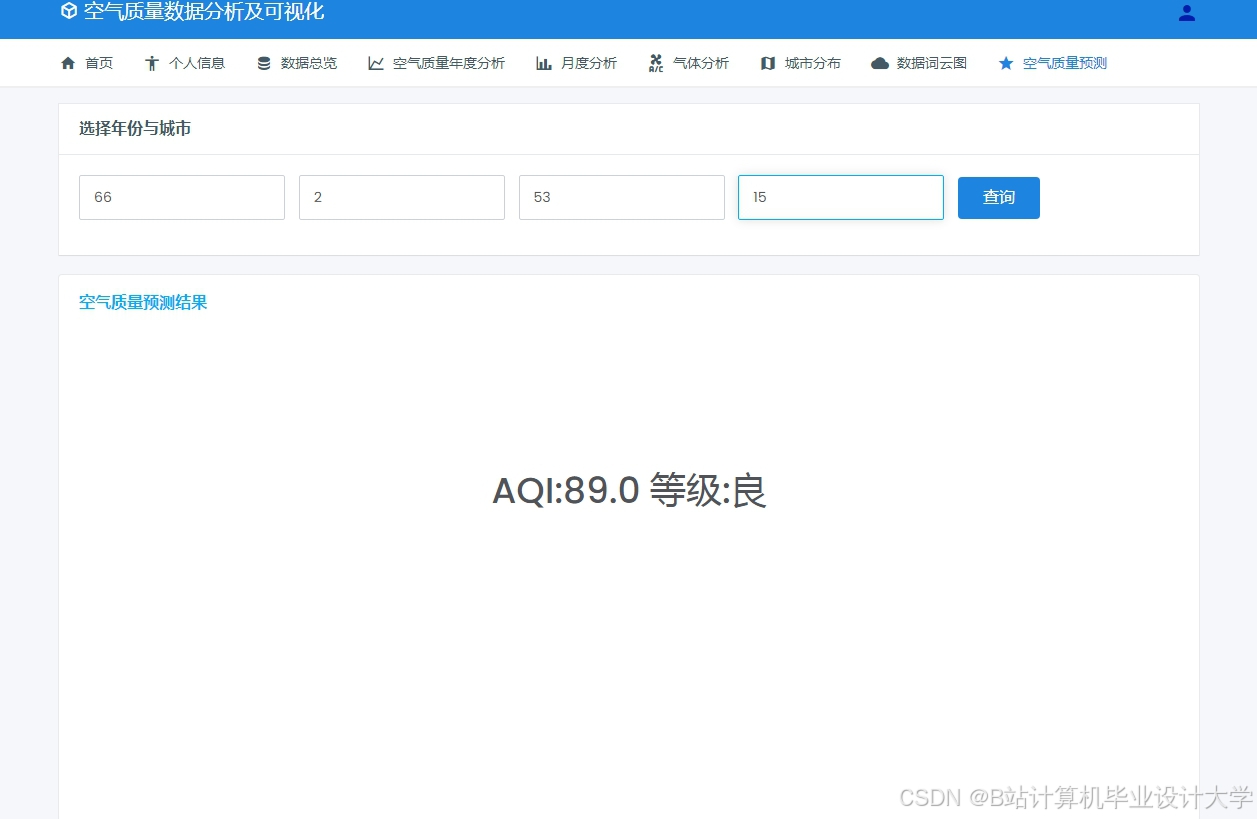
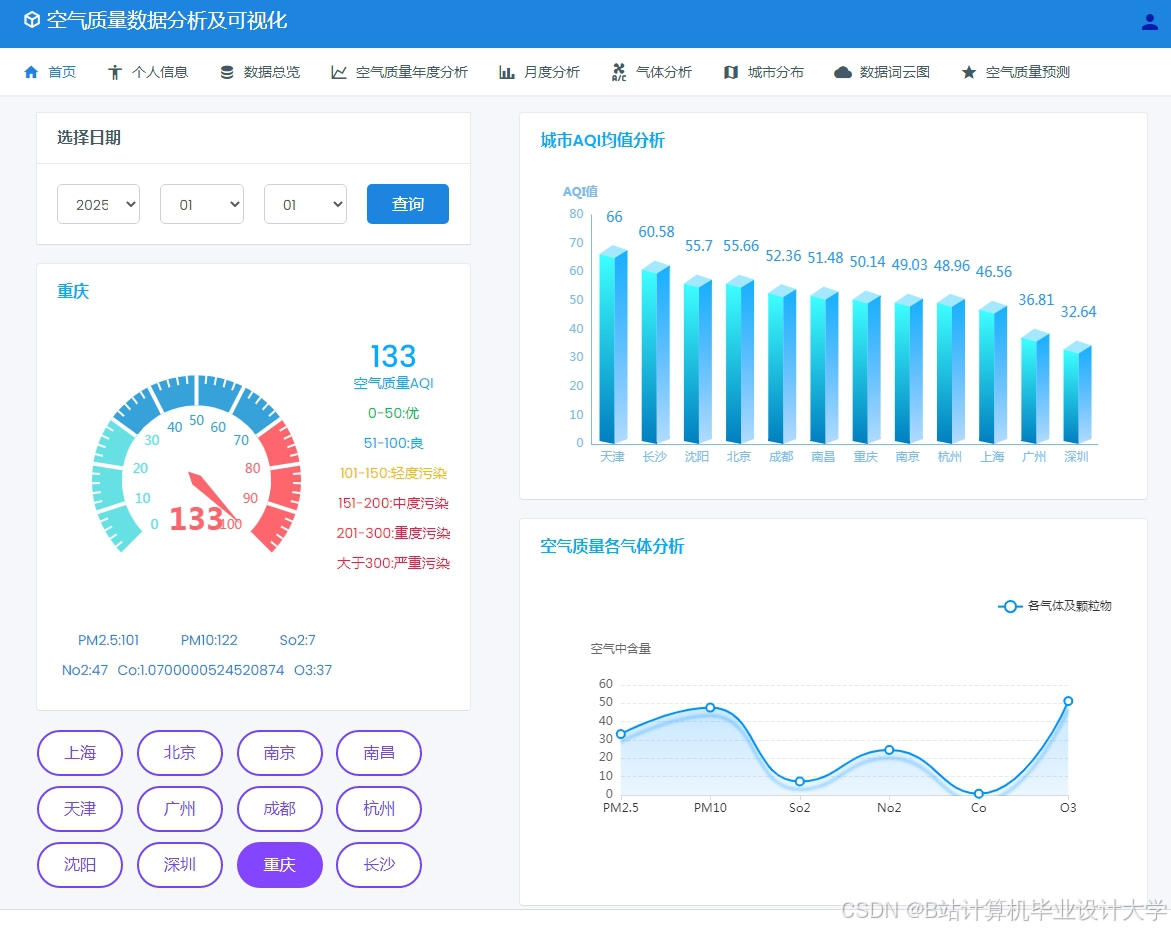
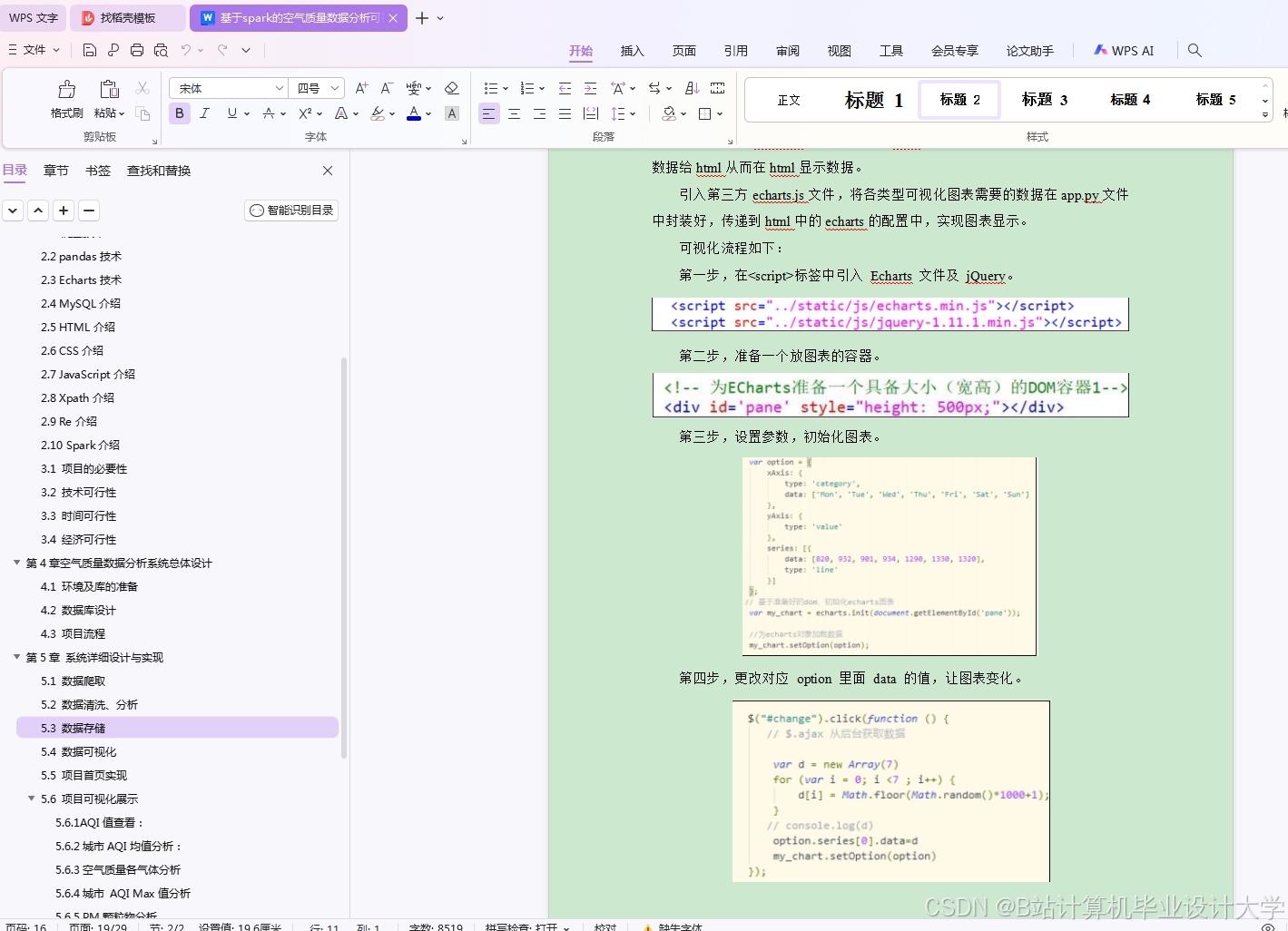
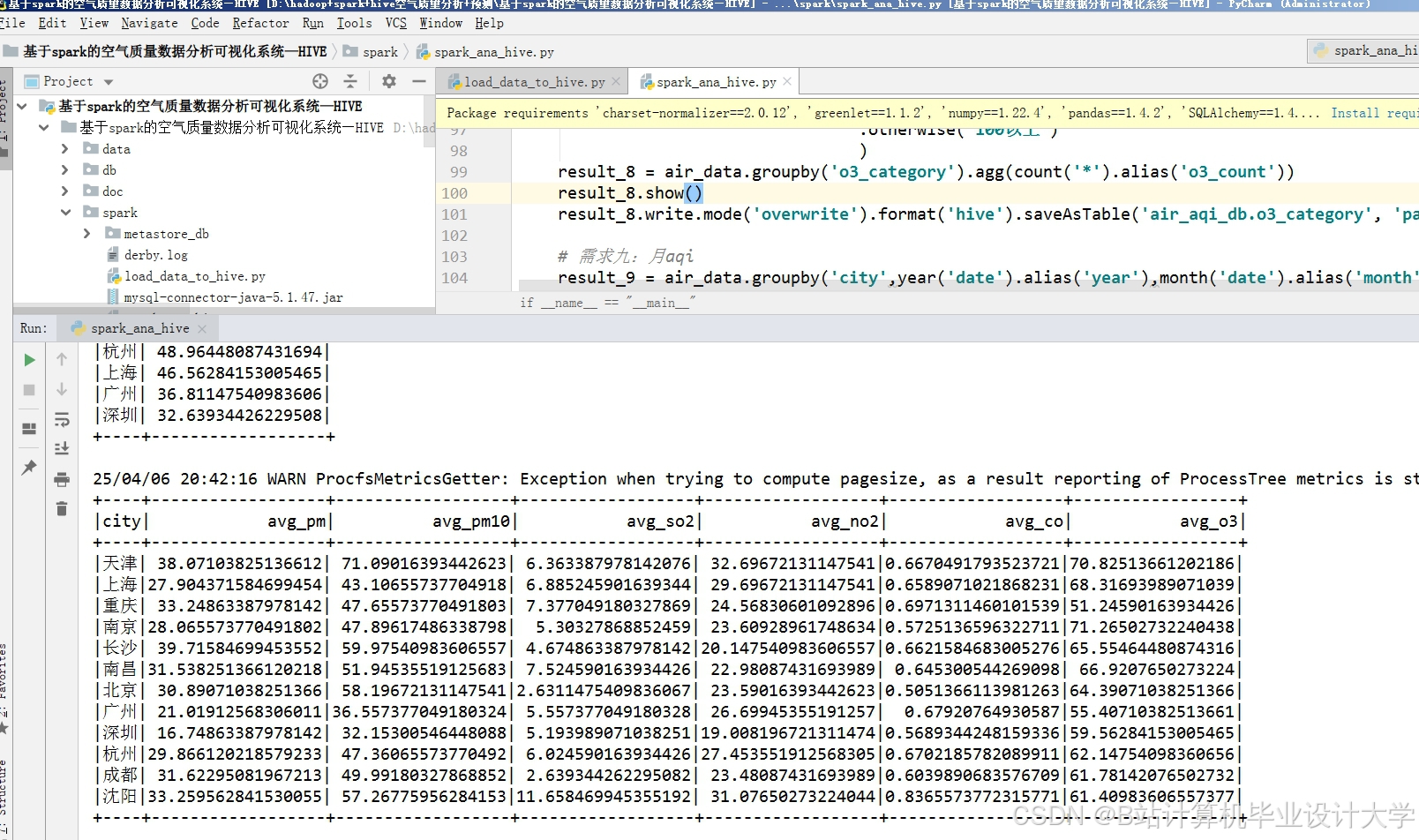
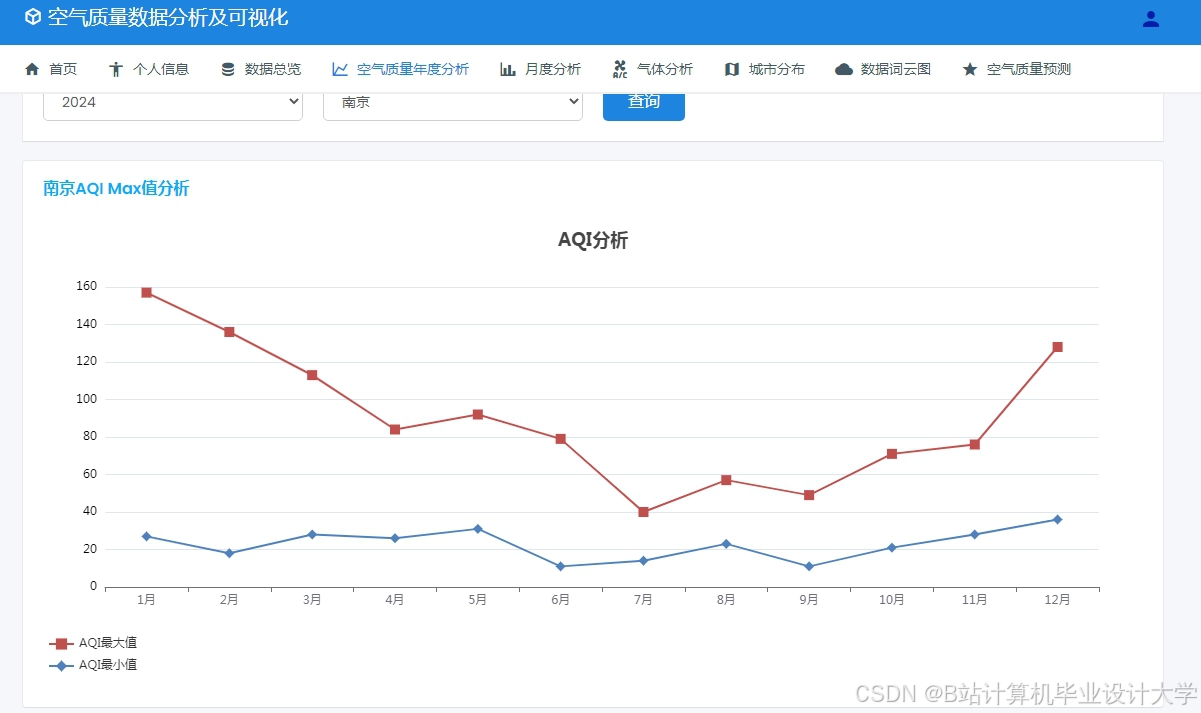
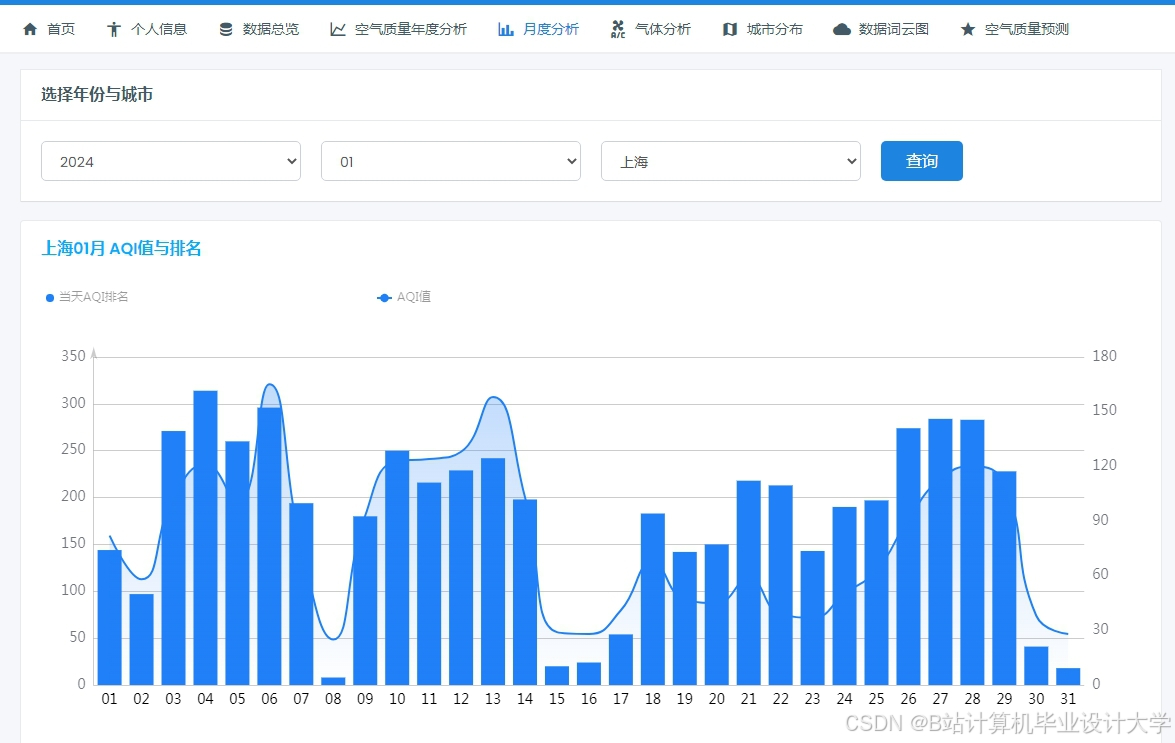
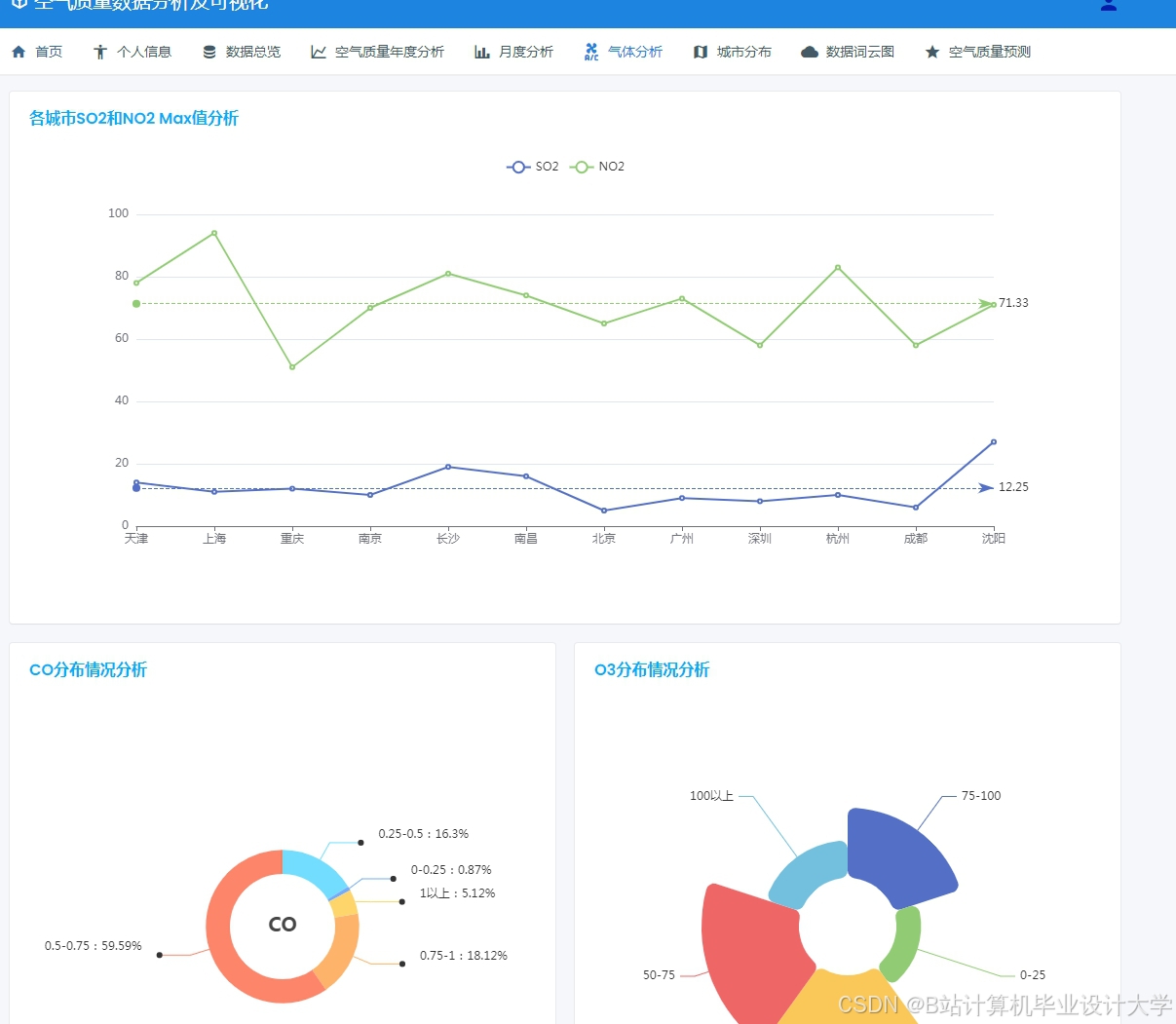
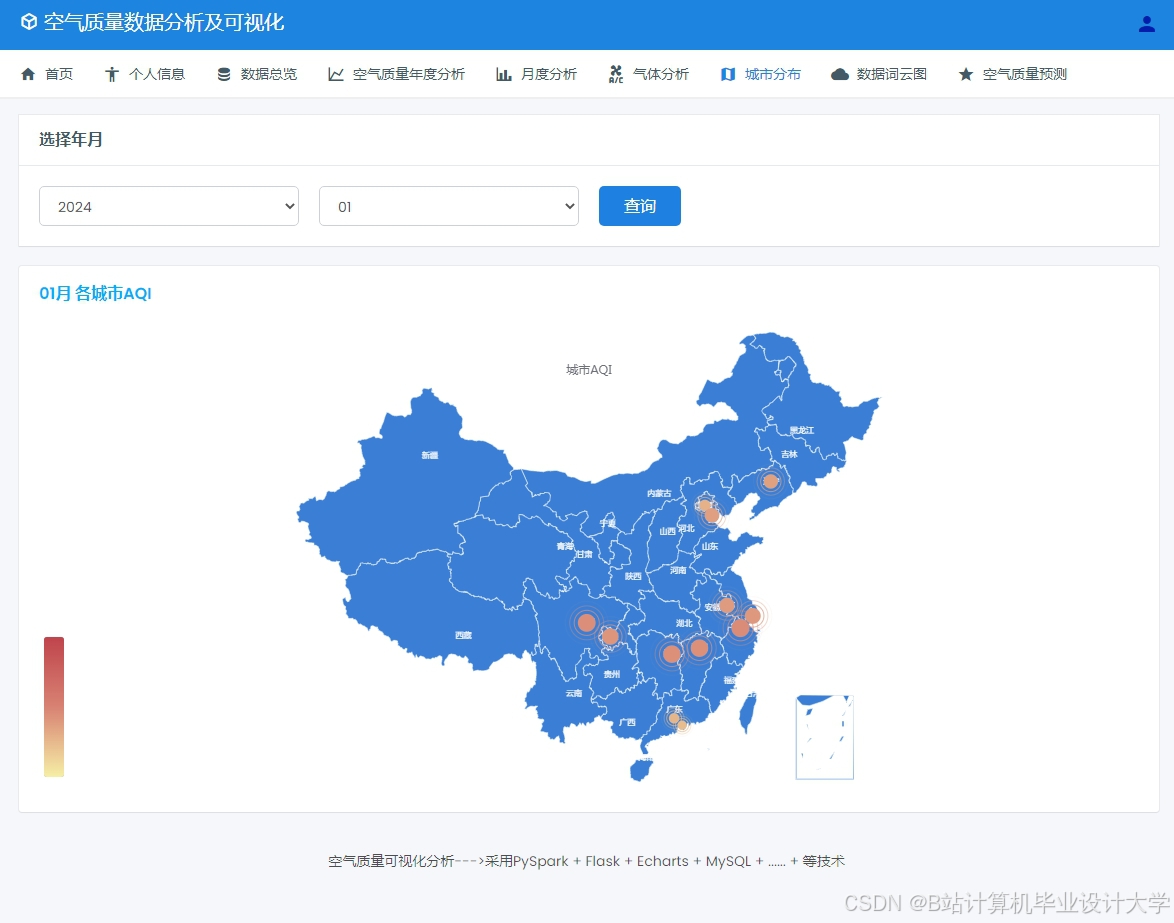
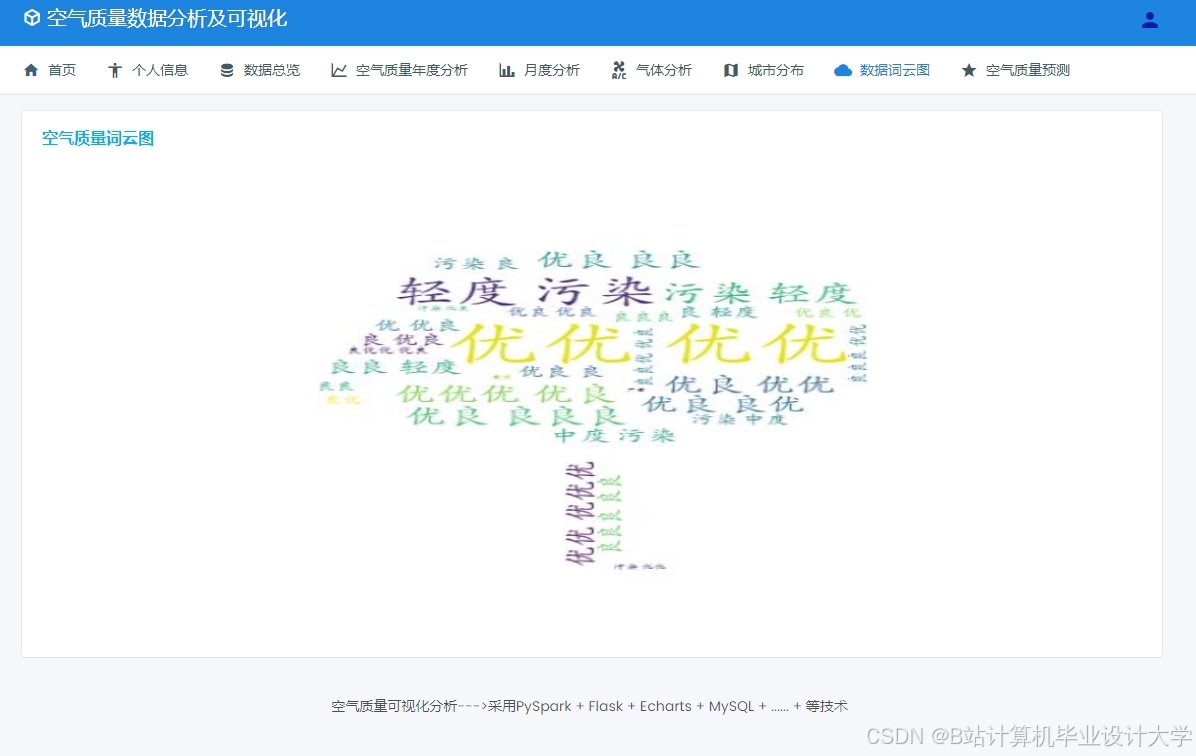
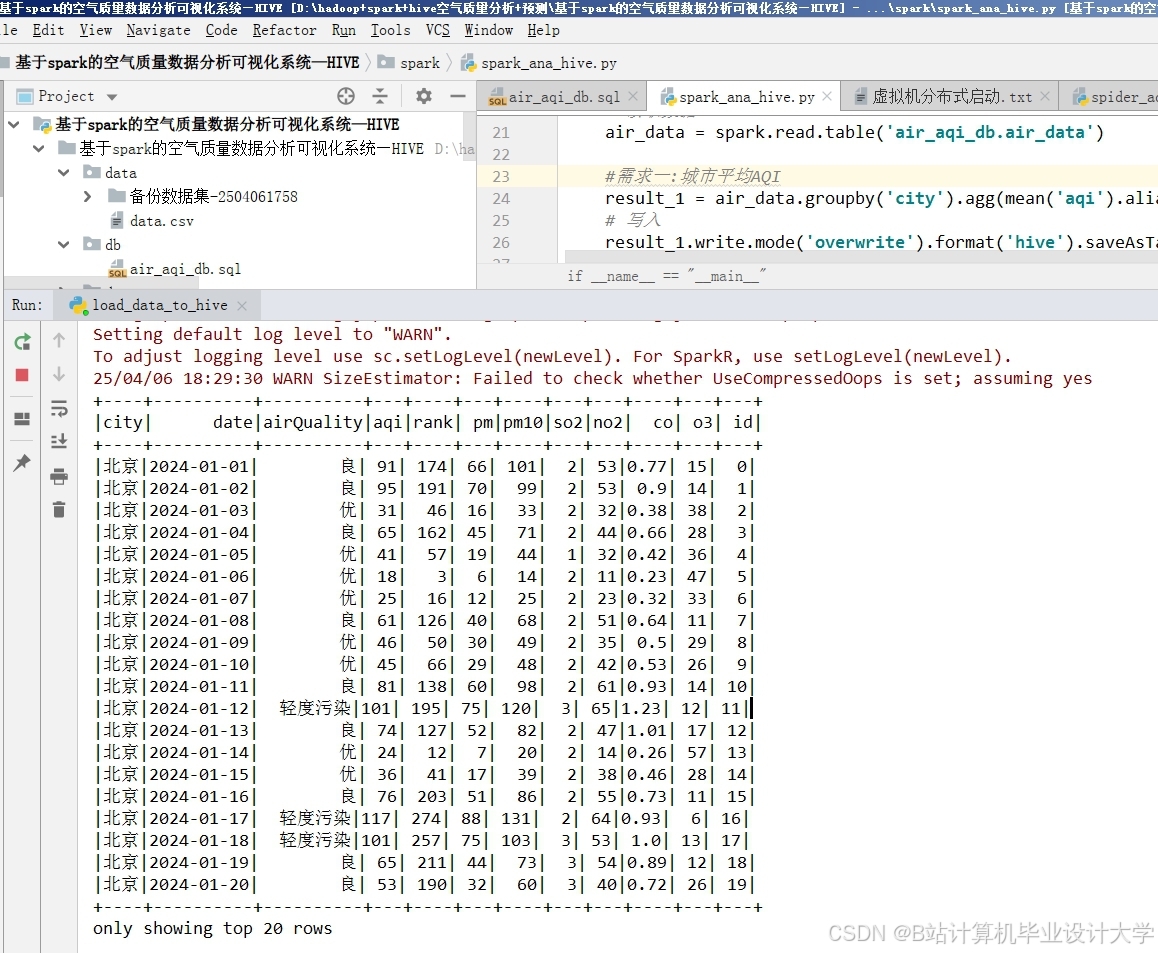
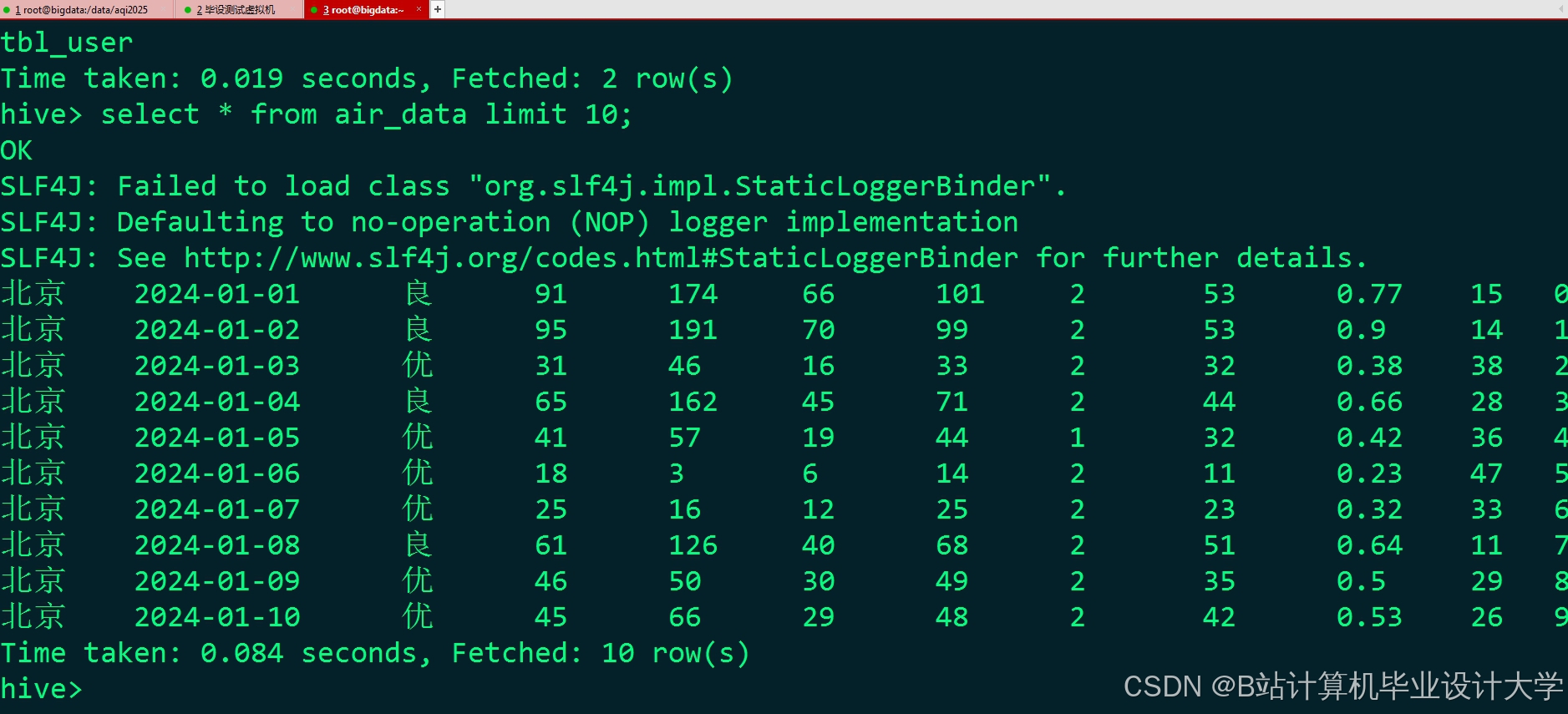
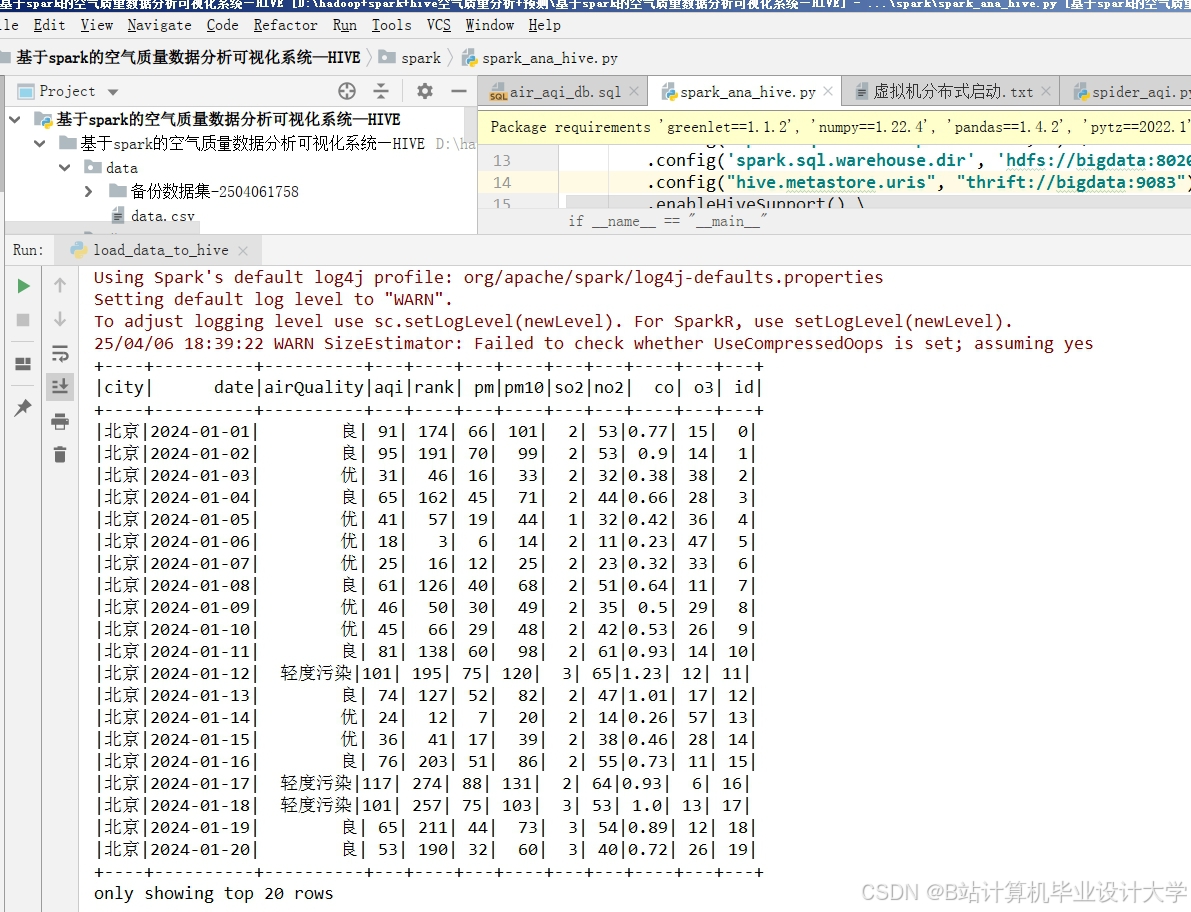
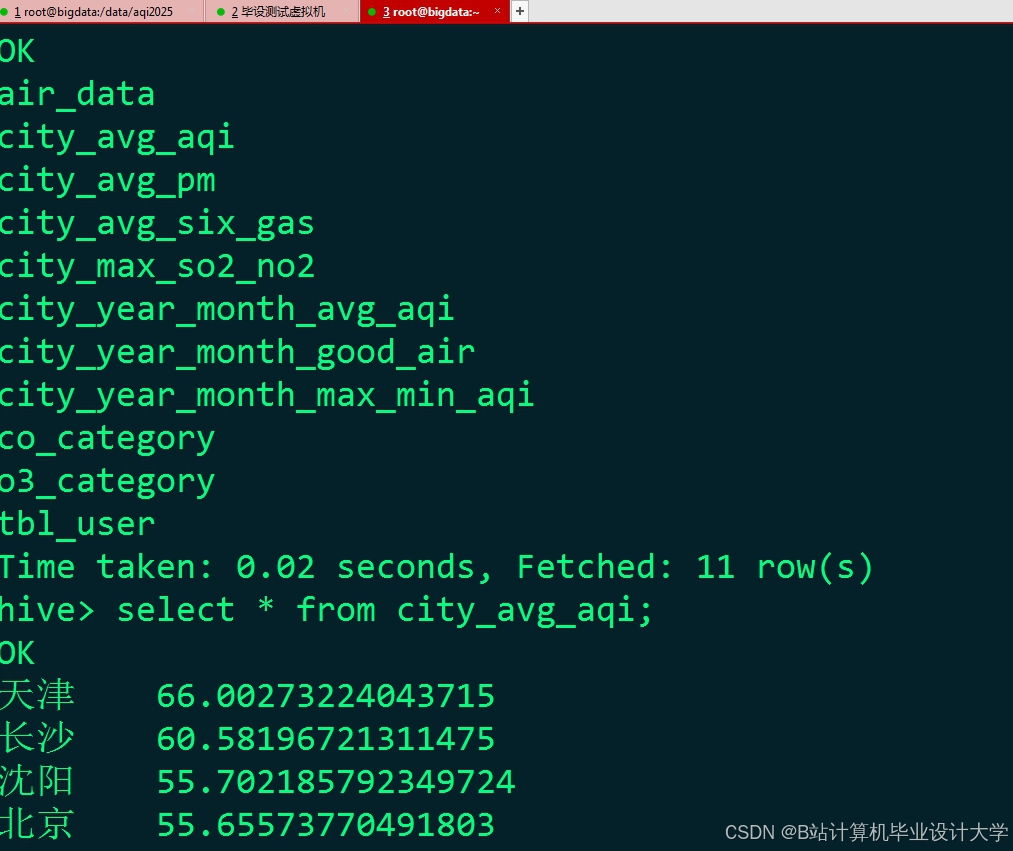

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻



















 942
942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











