




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
任务书:Hadoop+Spark+Hive游戏推荐系统
一、项目背景与目标
-
背景
游戏行业用户规模庞大,但用户留存率低(平均30天留存率不足25%)。传统推荐系统依赖简单标签匹配(如游戏类型、评分),难以捕捉用户动态行为(如游戏时长、社交互动、付费习惯)。本项目基于Hadoop(分布式存储)、Spark(内存计算)与Hive(数据仓库)构建实时游戏推荐系统,通过多维度用户行为分析(显式反馈+隐式反馈)与混合推荐算法(协同过滤+内容过滤+实时兴趣),实现个性化游戏推荐,提升用户留存与付费转化。 -
目标
- 构建基于Hadoop+Spark+Hive的分布式游戏推荐系统,支持PB级数据处理。
- 实现混合推荐算法(用户协同过滤+游戏内容相似度+实时行为加权)。
- 开发实时推荐接口(延迟≤500ms),支持每日千万级推荐请求。
- 提升推荐点击率(CTR)≥15%,用户30日留存率提升10%。
二、系统架构设计
- 技术栈
- 分布式存储:Hadoop HDFS(存储用户行为日志、游戏元数据)。
- 数据仓库:Hive(结构化数据ETL与查询)。
- 计算引擎:Spark(批处理推荐计算)、Spark Streaming(实时行为处理)。
- 机器学习库:Spark MLlib(协同过滤、矩阵分解)、TensorFlow(深度学习模型,可选)。
- 缓存与接口:Redis(存储实时推荐结果)、Kafka(消息队列传递用户行为)。
- 推荐服务:Flask/Django(提供RESTful API供游戏平台调用)。
- 系统模块
- 数据采集层:
- 用户行为日志(游戏启动、关卡完成、道具购买、社交互动)。
- 游戏元数据(类型、标签、画面风格、开发商、付费模式)。
- 数据处理层:
- Hive ETL:清洗、聚合用户行为数据(如按用户ID统计游戏时长)。
- Spark特征工程:提取用户画像(偏好类型、付费能力、社交活跃度)与游戏特征(热度、难度)。
- 推荐引擎层:
- 离线推荐:每日批量计算用户-游戏相似度(基于Spark ALS算法)。
- 实时推荐:通过Spark Streaming处理用户即时行为(如刚完成一款RPG,推荐同类高评分游戏)。
- 服务接口层:Redis缓存推荐结果,Flask提供API供游戏客户端调用。
- 数据采集层:
三、功能需求
- 数据处理功能
- 用户行为采集:通过游戏客户端SDK或服务器日志采集用户操作(点击、付费、停留时长)。
- 数据清洗与存储:
- 使用Hive SQL过滤无效数据(如重复日志、异常值)。
- 存储至HDFS分区表(按日期分区,如
/user/hive/warehouse/logs/dt=20231001)。
- 特征提取:
- 用户特征:历史游戏记录(游戏ID、时长、付费金额)、社交关系(好友推荐游戏)。
- 游戏特征:类型(RPG/MOBA/SLG)、标签(高画质/休闲)、热度指数(DAU/MAU)。
- 推荐算法功能
- 协同过滤推荐:
- 基于用户的协同过滤(UserCF):找到相似用户喜欢的游戏。
- 基于物品的协同过滤(ItemCF):找到与用户历史游戏相似的游戏。
- 内容过滤推荐:
- 计算游戏特征向量(如类型、标签的TF-IDF值)与用户偏好向量的余弦相似度。
- 实时兴趣挖掘:
- 通过Spark Streaming分析用户最近1小时行为(如连续玩3款MOBA游戏,临时提升MOBA类权重)。
- 混合推荐策略:
- 加权融合:协同过滤(60%)+内容过滤(30%)+实时兴趣(10%)。
- 协同过滤推荐:
- 推荐服务功能
- 离线推荐服务:每日凌晨通过Spark生成用户推荐列表(Top-20),存储至Redis。
- 实时推荐服务:用户登录或完成游戏时,触发Spark Streaming更新推荐结果(如新增“您可能喜欢”模块)。
- A/B测试接口:支持多组推荐策略对比(如A组用协同过滤,B组用深度学习)。
四、技术实现步骤
- 环境搭建
- 部署Hadoop集群(3节点,HDFS+YARN)。
- 配置Hive Metastore(MySQL存储元数据)。
- 安装Spark on YARN(内存分配:Executor 4G,Driver 8G)。
- 初始化Redis集群(主从模式,存储推荐结果)。
- 数据处理流程
- 数据采集:
- 游戏服务器通过Flume将日志写入HDFS。
- 示例日志格式:
user_id=1001,game_id=2001,action=play,duration=3600,timestamp=20231001120000。
- Hive ETL:
sqlCREATE TABLE user_game_logs (user_id STRING,game_id STRING,action STRING,duration INT,timestamp BIGINT) PARTITIONED BY (dt STRING);INSERT OVERWRITE TABLE user_game_logs PARTITION (dt='20231001')SELECT * FROM raw_logs WHERE dt='20231001'; - Spark特征工程:
- 统计用户历史游戏时长:
pythonfrom pyspark.sql import functions as Fuser_duration = spark.sql("SELECT user_id, game_id, SUM(duration) as total_duration FROM user_game_logs GROUP BY user_id, game_id")
- 统计用户历史游戏时长:
- 数据采集:
- 推荐算法开发
- 协同过滤(Spark ALS):
pythonfrom pyspark.ml.recommendation import ALSals = ALS(maxIter=10, regParam=0.1, userCol="user_id", itemCol="game_id", ratingCol="rating")model = als.fit(train_data) # train_data包含用户-游戏-评分(评分=时长/1000)recommendations = model.recommendForAllUsers(20) - 内容过滤(游戏特征相似度):
- 将游戏类型/标签编码为向量,计算余弦相似度。
- 实时推荐(Spark Streaming):
pythonfrom pyspark.streaming import StreamingContextssc = StreamingContext(spark.sparkContext, batchDuration=60) # 每分钟处理一次def process_stream(rdd):if not rdd.isEmpty():recent_actions = rdd.map(lambda x: (x['user_id'], x['game_id'])).collect()# 触发实时推荐逻辑ssc.socketTextStream("localhost", 9999).map(parse_log).foreachRDD(process_stream)
- 协同过滤(Spark ALS):
- 服务接口开发
- Redis缓存:
pythonimport redisr = redis.Redis(host='localhost', port=6379)r.set(f"user:{user_id}:recommendations", json.dumps(recommendations)) - Flask API:
pythonfrom flask import Flask, jsonifyapp = Flask(__name__)@app.route('/recommend/<user_id>')def get_recommendations(user_id):recommendations = json.loads(r.get(f"user:{user_id}:recommendations"))return jsonify(recommendations)
- Redis缓存:
五、项目计划
| 阶段 | 时间 | 任务 |
|---|---|---|
| 需求分析 | 第1周 | 确定功能需求、技术选型、数据来源(如Steam公开数据、自有游戏日志)。 |
| 环境搭建 | 第2周 | 部署Hadoop/Spark/Hive集群,配置Redis与Kafka。 |
| 数据采集与ETL | 第3周 | 开发日志采集模块,完成Hive表设计与数据清洗。 |
| 推荐算法开发 | 第4-5周 | 实现协同过滤、内容过滤、实时推荐逻辑,优化参数(如ALS的rank=50)。 |
| 服务接口开发 | 第6周 | 开发Flask API,集成Redis缓存,实现A/B测试接口。 |
| 系统测试与优化 | 第7周 | 压力测试(QPS≥1000)、推荐准确率评估(离线AUC≥0.7)、延迟优化(≤500ms)。 |
| 部署与上线 | 第8周 | 打包部署至生产环境,编写监控脚本(如Prometheus+Grafana)。 |
六、预期成果
- 完成Hadoop+Spark+Hive分布式游戏推荐系统,支持每日千万级用户行为处理。
- 实现混合推荐算法,Top-20推荐点击率(CTR)≥15%(基于A/B测试)。
- 开发实时推荐接口,平均延迟≤400ms(90%请求)。
- 提交项目文档(架构设计、算法说明、测试报告、API文档)。
七、风险评估与应对
- 数据倾斜风险:热门游戏可能导致协同过滤计算资源不均。
- 应对:对热门游戏采样(如随机抽取10%用户行为),或使用加权ALS。
- 冷启动风险:新用户/新游戏缺乏历史数据。
- 应对:新用户推荐热门游戏(基于ItemCF),新游戏通过内容过滤推荐给相似用户。
- 实时性风险:Spark Streaming处理延迟可能超过500ms。
- 应对:优化批处理间隔(如从60秒降至30秒),或改用Flink流处理。
项目负责人:XXX
日期:XXXX年XX月XX日
备注:本任务书可根据实际需求扩展功能(如加入深度学习模型、支持多平台游戏推荐),或调整技术栈(如替换Hive为ClickHouse提升查询性能)。
运行截图
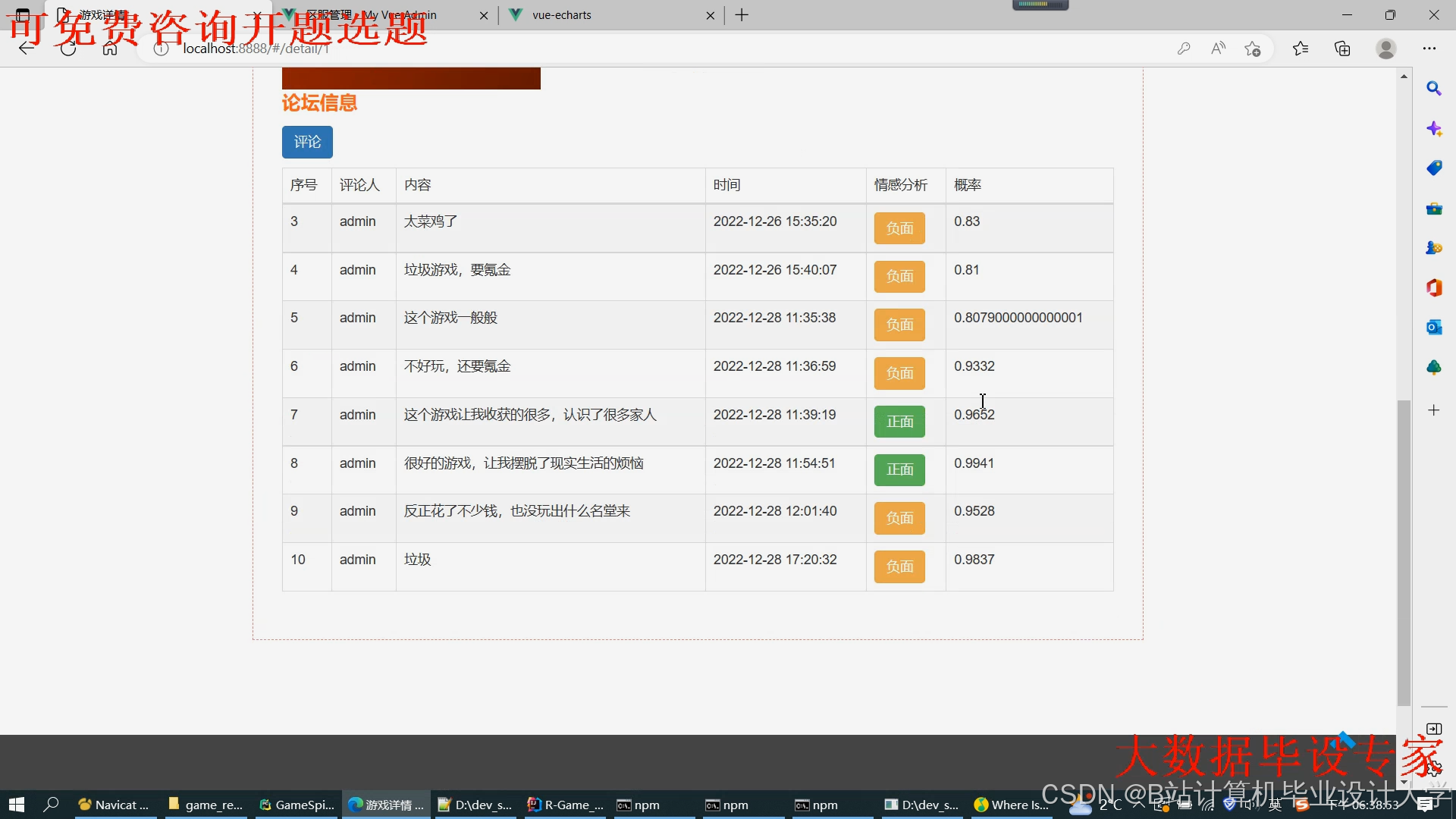
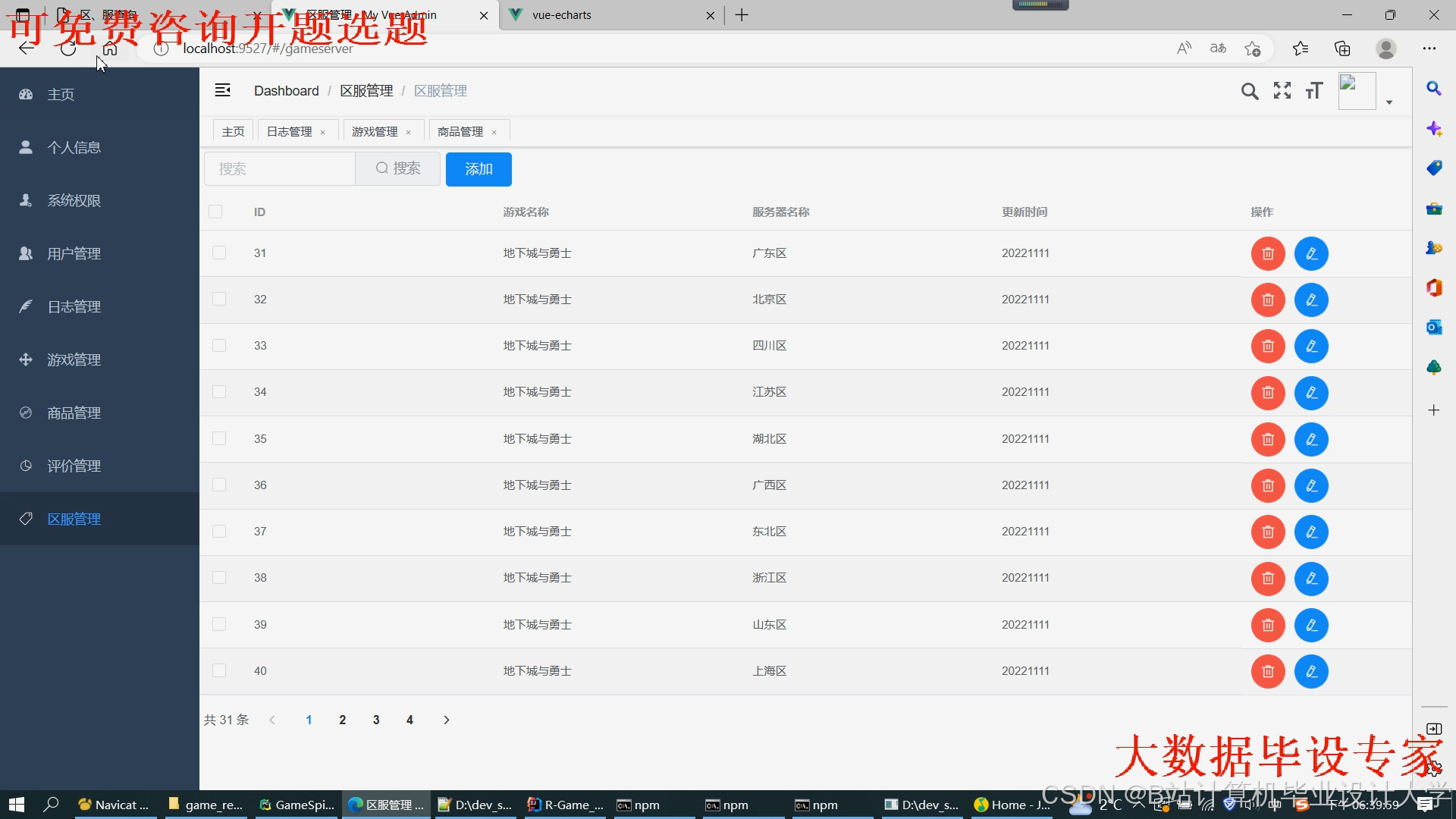
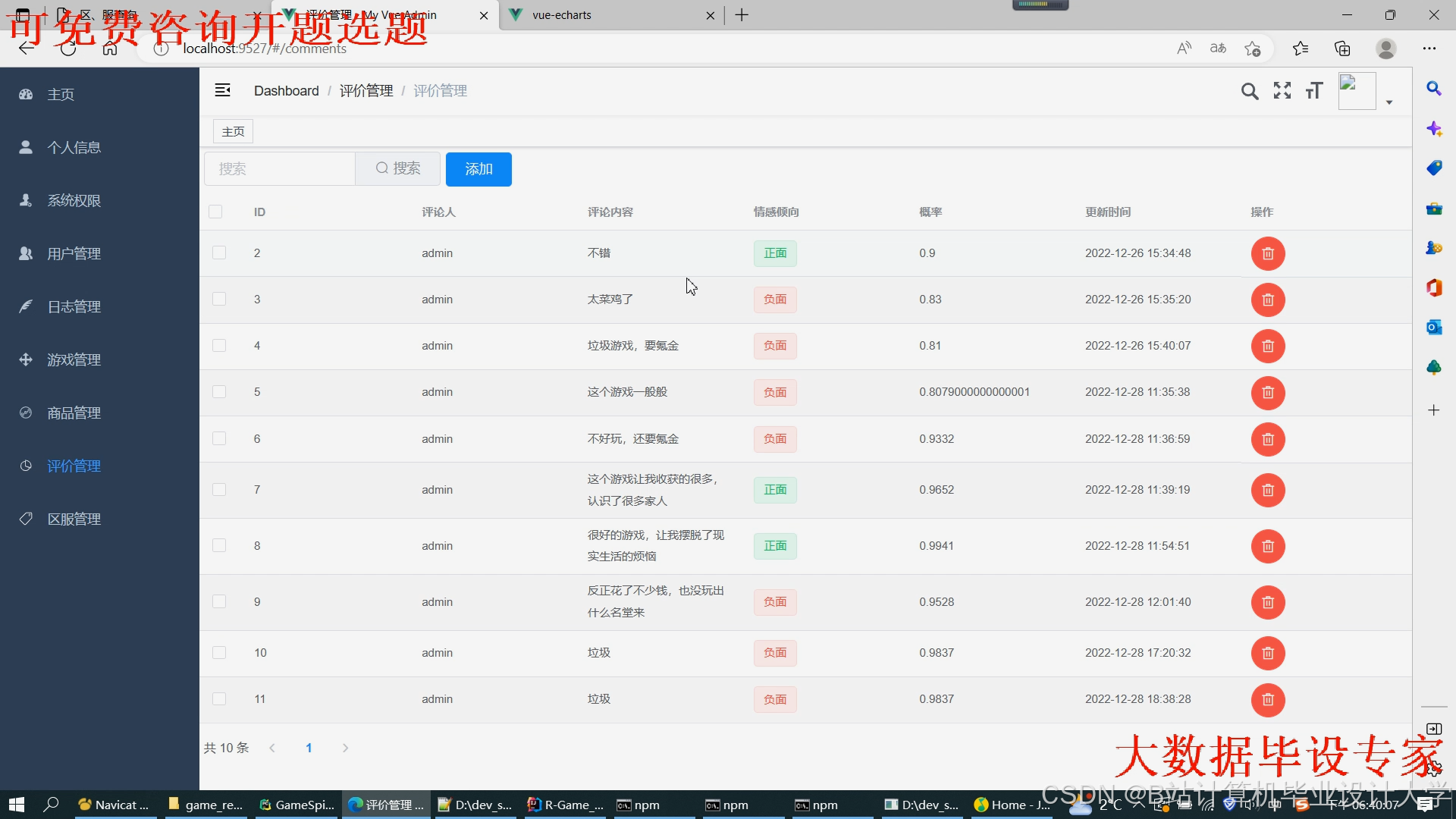
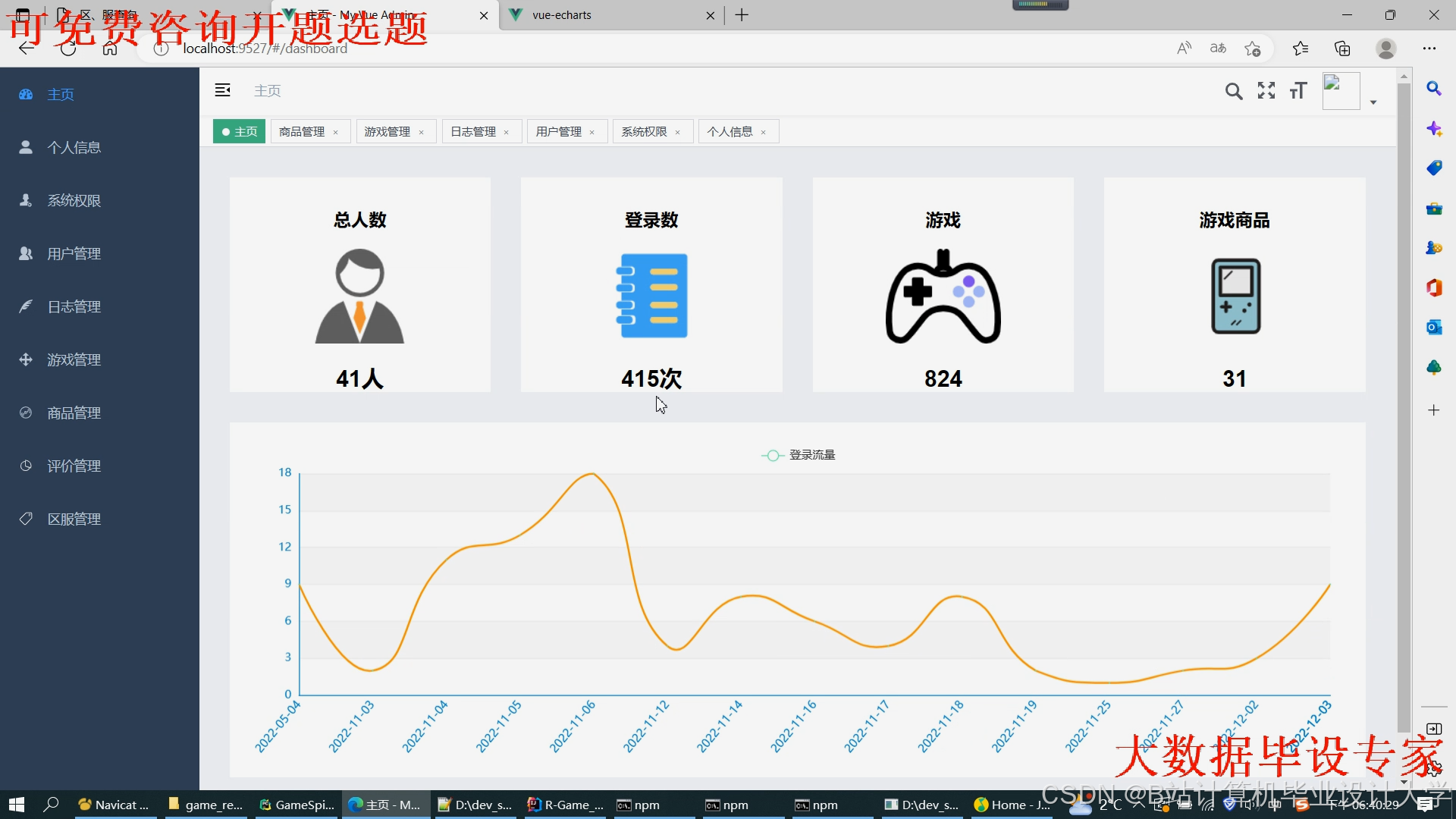

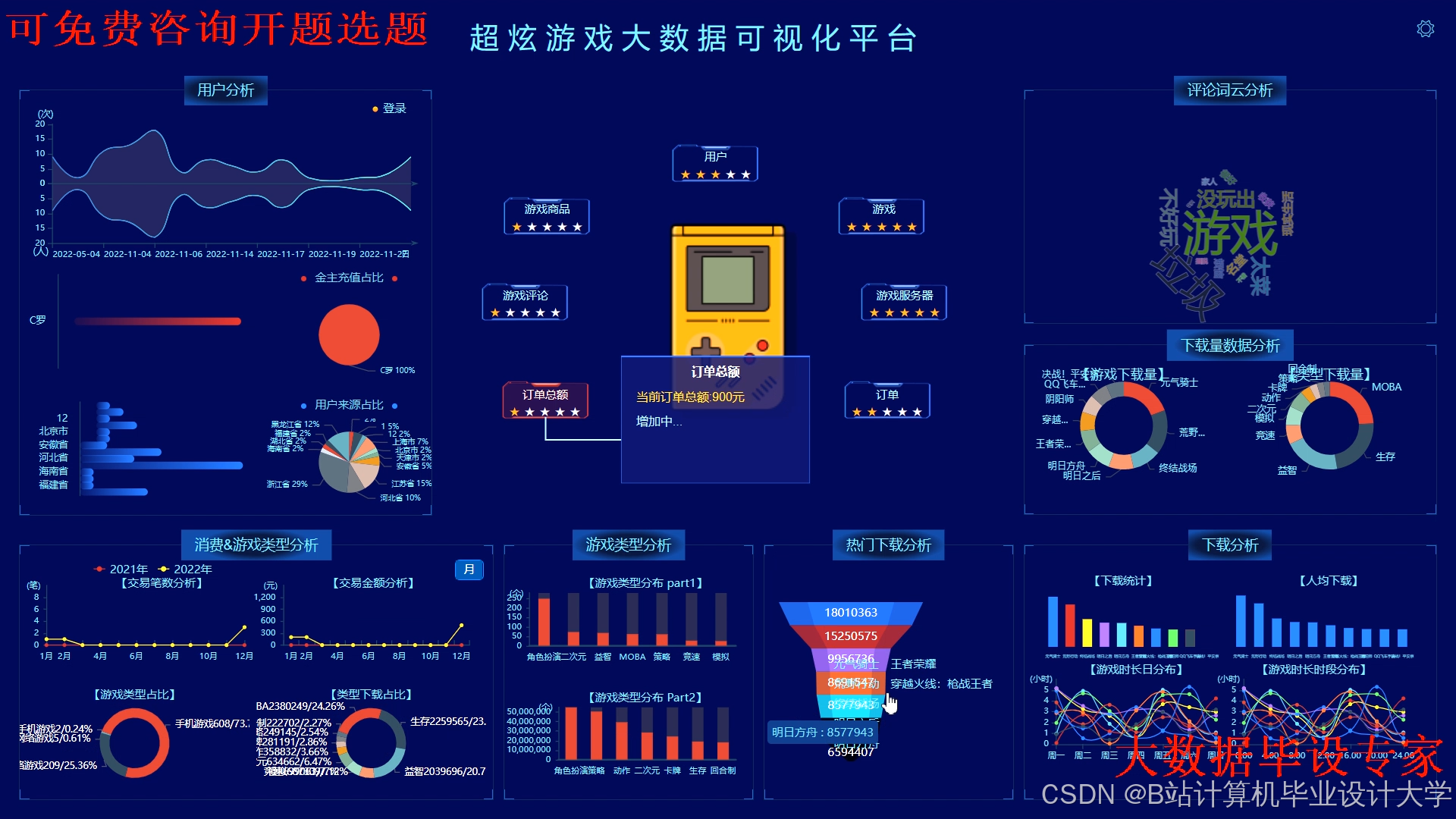
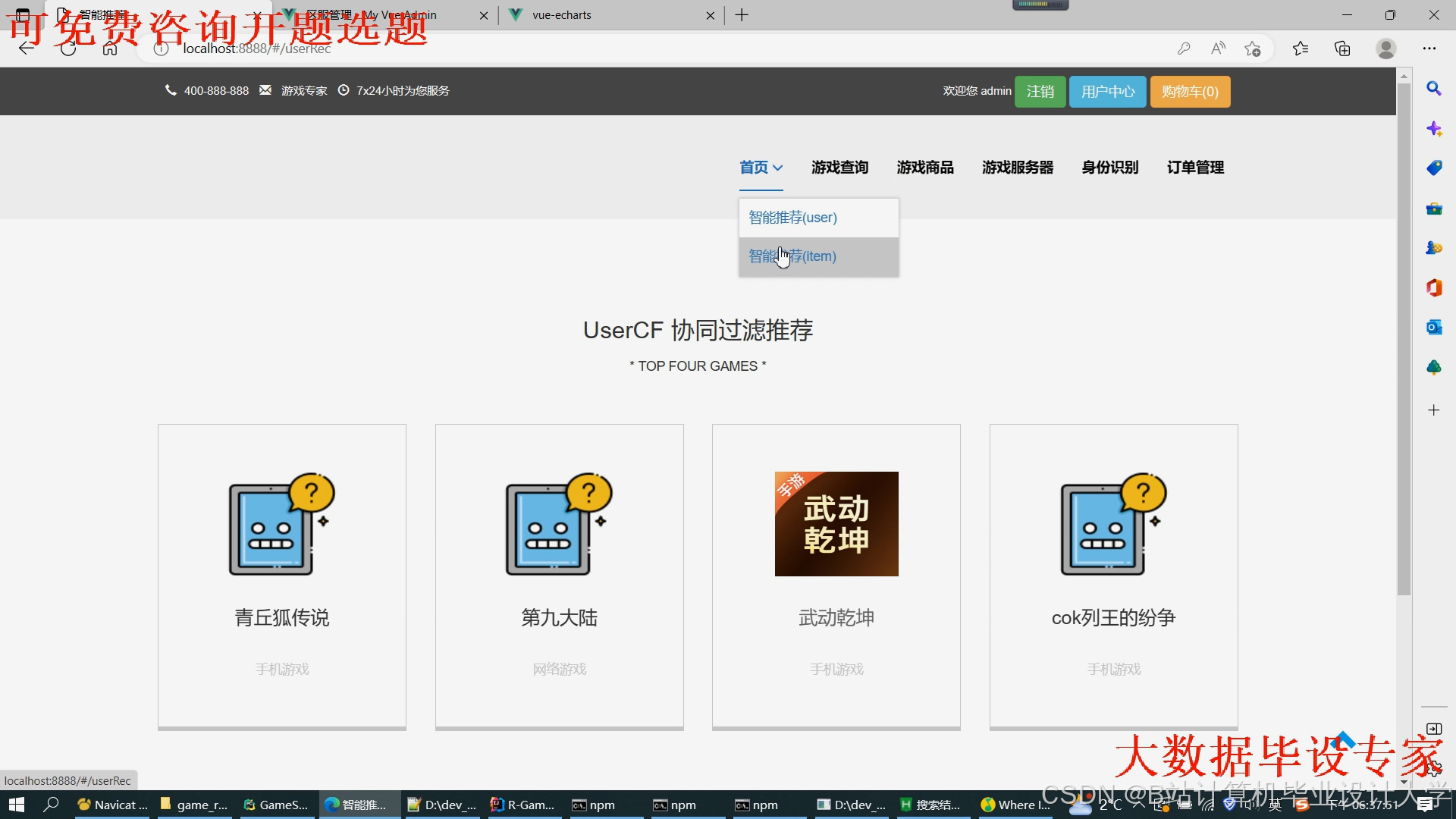
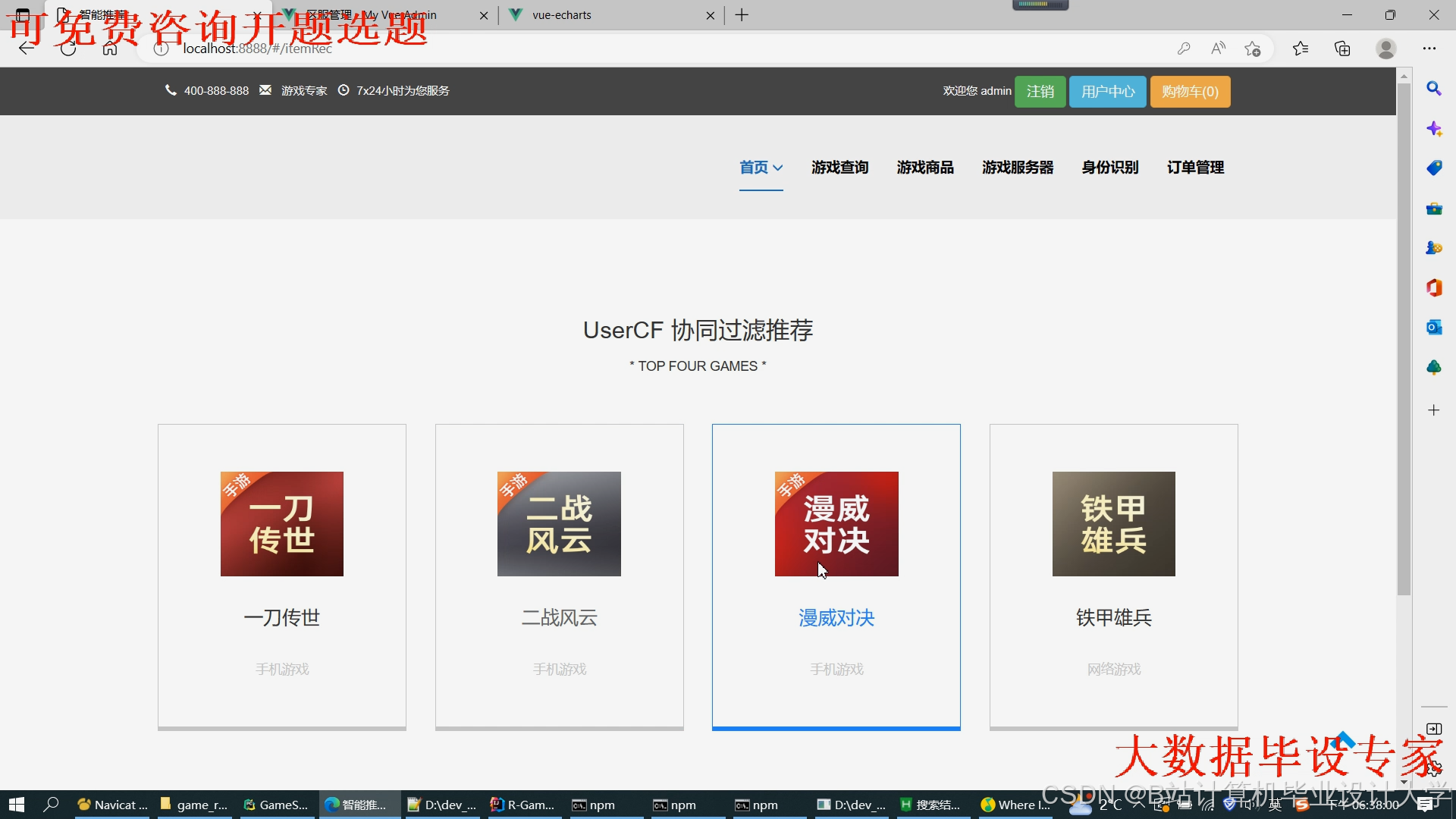
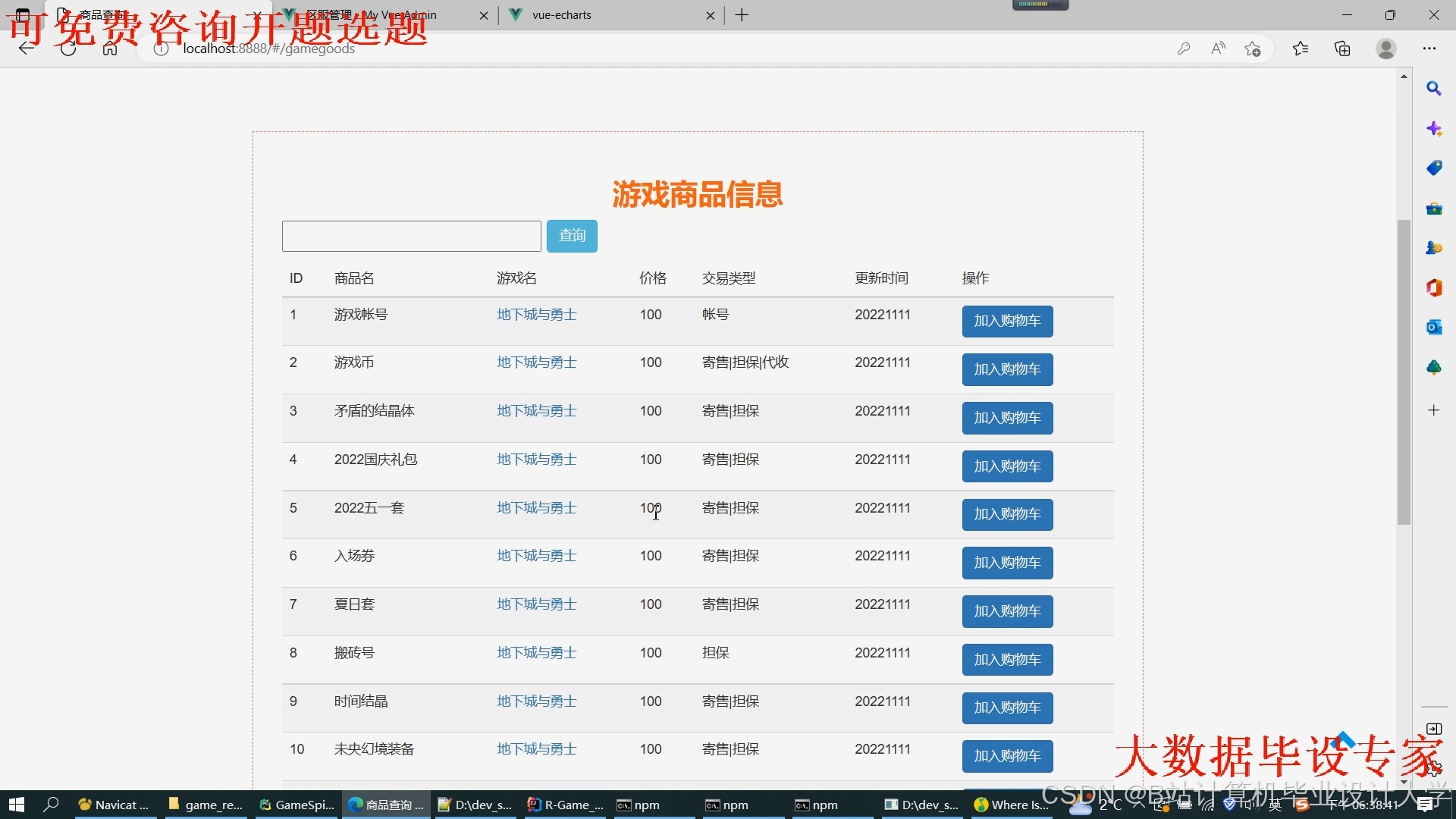
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 413
413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











